사전 교육된 YOLOV3 모델을 로드하고 OpenCV를 사용하여
몇 개의 이미지에 대한 추론을 실행하는 방법을 배운다.

Colab에서 yolo 모델파일을 다운로드 받으면,
images 와 yolo 안에 3개의 파일이 존재한다.
-
coco.names
YOLO 모델이 식별하고자 하는 객체의 클래스 레이블을 포함
예를 들어, "사람", "자동차", "개" 등과 같이 식별하려는 객체의 종류에 대한 레이블이 coco.names 파일에 포함
이 파일은 각 클래스 레이블을 정의하고 YOLO 알고리즘이 객체를 식별하는 데 사용 -
yolov3.cfg
YOLO 모델의 네트워크 아키텍처를 정의하는 구성 파일
YOLO 네트워크의 레이어, 각 레이어의 구성 및 하이퍼파라미터 등이 정의돼 있다.
네트워크의 구조와 매개변수가 이 파일에 정의되어 있어야 YOLO 알고리즘이 올바르게 작동 -
yolov3.weights
사전 훈련된 YOLO 모델의 가중치(weight)를 포함
결론은 coco.names 파일은 클래스 레이블을 정의하고, yolov3.cfg 파일은 네트워크 아키텍처를 정의하며, yolov3.weights 파일은 사전 훈련된 모델의 가중치를 포함한다.
이 세 가지 파일이 함께 사용돼서 YOLO 알고리즘이 객체 감지를 수행하고 결과를 출력하는 것.
YoLo 개체 분석
print("감지 시작...")
# ./images 폴더에서 이미지 파일을 가져옴
mypath = "YOLO/images/"
file_names = [f for f in listdir(mypath) if isfile(join(mypath, f))]
# 이미지를 순회하면서 분류기를 실행
for file in file_names:
# 입력 이미지를 로드하고 공간 차원을 가져옴
image = cv2.imread(mypath + file)
(H, W) = image.shape[:2]
# YOLO에서 필요한 *출력* 레이어 이름만 가져오기
ln = net.getLayerNames()
ln = [ln[i - 1] for i in net.getUnconnectedOutLayers()]
# 입력 이미지에서 blob 객체를 생성
blob = cv2.dnn.blobFromImage(image, 1 / 255.0, (416, 416), swapRB=True, crop=False)
# 이미지 blob을 입력으로 설정
net.setInput(blob)
# 네트워크를 통해 순방향 전파 실행
layerOutputs = net.forward(ln)
# 감지된 경계 상자, 확신도 및 클래스 ID를 저장할 리스트 초기화
boxes = []
confidences = []
IDs = []
# 각 레이어 출력을 순회
for output in layerOutputs:
# 각 감지를 순회
for detection in output:
# 클래스 ID와 감지의 확률을 추출
scores = detection[5:]
classID = np.argmax(scores)
confidence = scores[classID]
# 가장 확률이 높은 예측만 선택
if confidence > 0.75:
# 경계 상자 좌표를 이미지에 상대적으로 스케일링
# 참고: YOLO는 실제로 경계 상자의 중심 (x, y) 다음에 상자의 너비와 높이를 반환
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height) = box.astype("int")
# 상자의 왼쪽 상단 모서리 얻기
# 이미 너비와 높이를 가지고 있음
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
# 경계 상자 좌표, 확신도 및 클래스 ID를 리스트에 추가
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
IDs.append(classID)
# 겹치는 경계 상자를 줄이기 위해 비 최대 억제 적용
idxs = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.3)
# 감지가 있을 때만 계속 진행
if len(idxs) > 0:
# 유지할 인덱스를 순회
for i in idxs.flatten():
# 경계 상자 좌표 가져오기
(x, y) = (boxes[i][0], boxes[i][1])
(w, h) = (boxes[i][2], boxes[i][3])
# 경계 상자를 그리고, 클래스 레이블과 확률을 이미지에 표시
color = [int(c) for c in COLORS[IDs[i]]]
cv2.rectangle(image, (x, y), (x + w, y + h), color, 3)
text = "{}: {:.4f}".format(LABELS[IDs[i]], confidences[i])
cv2.putText(image, text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
# 처리된 이미지 표시
imshow("YOLO 감지 결과", image, size=12)
-
mypath에서 이미지 파일을 가져와서
-
가져온 이미지 파일을 순회하면서 객체 감지를 수행
-
각 이미지를 처리하기 전에는 blob 객체로 변환
-
변횐된 blob 객체를 YOLO 네트워크에 입력으로 제공
-
네트워크의 출력을 받아 감지된 객체의 경계 상자, 확신도 및 클래스 ID를 추출
-
추출된 정보를 사용하여 확률이 높은 객체만 선택하고, 해당 객체들의 경계 상자 좌표를 스케일링하고 저장
-
비 최대 억제를 적용하여 겹치는 경계 상자 제거
-
남은 객체에 대해 경계 상자를 그리고, 확률과 클래스 레이블을 이미지에 표시
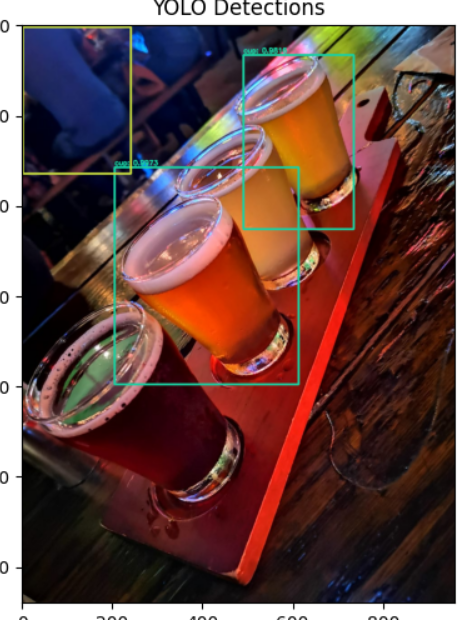
위 순서대로 코드를 실행시켰을때의 결과이다.
트럭과 컵을 테이블로 표시하고, 그 클래스의 이름과 신뢰도를 표시가 돼있다.
1에 가까울수록 믿을만한 정도라는 뜻이다.

이 사진에서는 술은 보이지만, 컵은 보지 못했었는데, 객체감지를 통해 있다는 사실을 알았다.