1. Setup and Install Lightning
먼저 PyTorch Lightning 및 Torch Metrics를 설치
!pip install pytorch-lightning --quiet
!pip install torchmetrics그리고 사용할 라이브러리를 호출
import os
import torch
import torchmetrics
import torch.nn.functional as F
from torch import nn
from torchvision import transforms
from torch.utils.data import DataLoader, random_split
import pytorch_lightning as pl
from pytorch_lightning.loggers import TensorBoardLogger
from PIL import Image데이터셋 다운로드
!gdown --id 1Dvw0UpvItjig0JbnzbTgYKB-ibMrXdxk
!unzip -q dogs-vs-cats.zip
!unzip -q train.zip
!unzip -q test1.zip 데이터는 kaggle의 dog vs cat 이미지를 다운로드했다.
Dataloaders 셋업
데이터 로더(DataLoader)는 딥러닝 모델을 훈련시키거나 평가할 때 데이터를 효과적으로 공급하기 위해 사용하기에 만들어줘야한다.
특징으로는 셔플링(Shuffle),병렬 처리, 데이터 전처리 통합 등 전에 배웠던 내용들
import os
from PIL import Image
import torch
from torchvision import transforms
class Dataset():
def __init__(self, filelist, filepath, transform=None):
self.filelist = filelist
self.filepath = filepath
self.transform = transform
def __len__(self):
return int(len(self.filelist))
def __getitem__(self, index):
imgpath = os.path.join(self.filepath, self.filelist[index])
img = Image.open(imgpath)
# 이미지 경로에 "dog"가 포함되어 있으면 레이블을 1로 설정, 그렇지 않으면 0으로 설정
if "dog" in imgpath:
label = 1
else:
label = 0
# 변환(transform)이 존재하면 이미지를 변환
if self.transform is not None:
img = self.transform(img)
return (img, label)
# 학습 데이터와 테스트 데이터 경로 설정
train_dir = './train'
test_dir = './test1'
# 디렉토리 내 파일 목록 가져오기
train_files = os.listdir(train_dir)
test_files = os.listdir(test_dir)
# 변환(transform) 설정
transformations = transforms.Compose([transforms.Resize((60,60)),transforms.ToTensor()])
# 학습 및 테스트 데이터셋 객체 생성
train = Dataset(train_files, train_dir, transformations)
val = Dataset(test_files, test_dir, transformations)
# 학습 데이터셋과 검증 데이터셋으로 분할 (학습: 20000, 검증: 5000)
train, val = torch.utils.data.random_split(train, [20000, 5000])
# 데이터 로더 설정
# 학습 데이터 로더: 배치 크기 32, 셔플 사용
train_loader = torch.utils.data.DataLoader(dataset=train, batch_size=32, shuffle=True)
# 검증 데이터 로더: 배치 크기 32, 셔플 사용 안 함
val_loader = torch.utils.data.DataLoader(dataset=val, batch_size=32, shuffle=False)
2. 코드를 Lightning 구조/설계 철학에 맞게 구성
PyTorch Lightning의 주요 기능들(데이터 로더, 훈련 단계, 검증 단계, 최적화 설정)을 사용하여 모델 훈련 및 평가를 간소화한 코드
import torch
import torch.nn as nn
import torch.nn.functional as F
import pytorch_lightning as pl
class LitModel(pl.LightningModule): # PyTorch Lightning 모듈을 상속받음
def __init__(self, batch_size):
super().__init__()
self.batch_size = batch_size
# 첫 번째 합성곱 층
self.conv1 = nn.Sequential(nn.Conv2d(3, 16, 3), nn.ReLU(), nn.MaxPool2d(2, 2))
# 두 번째 합성곱 층
self.conv2 = nn.Sequential(nn.Conv2d(16, 32, 3), nn.ReLU(), nn.MaxPool2d(2, 2))
# 세 번째 합성곱 층
self.conv3 = nn.Sequential(nn.Conv2d(32, 64, 3), nn.ReLU(), nn.MaxPool2d(2, 2))
# 첫 번째 완전 연결 층
self.fc1 = nn.Sequential(nn.Flatten(), nn.Linear(64*5*5, 256), nn.ReLU(), nn.Linear(256, 128), nn.ReLU())
# 두 번째 완전 연결 층
self.fc2 = nn.Sequential(nn.Linear(128, 2),)
# PyTorch Lightning의 데이터 로더 설정
def train_dataloader(self): # PyTorch Lightning 데이터 로더
# 학습 데이터 로더 반환
return torch.utils.data.DataLoader(dataset=train, batch_size=32, shuffle=True)
def val_dataloader(self): # PyTorch Lightning 데이터 로더
# 검증 데이터 로더 반환
return torch.utils.data.DataLoader(dataset=val, batch_size=32, shuffle=False)
def cross_entropy_loss(self, logits, labels):
return F.nll_loss(logits, labels)
# PyTorch Lightning의 훈련 단계 정의
def training_step(self, batch, batch_idx): # PyTorch Lightning 훈련 단계
data, label = batch
output = self.forward(data)
loss = nn.CrossEntropyLoss()(output, label)
self.log('train_loss', loss) # 훈련 손실 로깅
return {'loss': loss, 'log': self.log}
# PyTorch Lightning의 검증 단계 정의
def validation_step(self, batch, batch_idx): # PyTorch Lightning 검증 단계
val_data, val_label = batch
val_output = self.forward(val_data)
val_loss = nn.CrossEntropyLoss()(val_output, val_label)
self.log('val_loss', val_loss) # 검증 손실 로깅
# PyTorch Lightning의 최적화 설정
def configure_optimizers(self): # PyTorch Lightning 최적화 설정
return torch.optim.Adam(self.parameters(), lr=0.02)
def forward(self, x):
# PyTorch Lightning에서 forward는 예측/추론 동작을 정의함
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.fc1(x)
x = self.fc2(x)
return F.softmax(x, dim=1) # 소프트맥스 함수로 확률 분포 반환
3. 자동 배치 선택
PyTorch Lightning의 배치 크기 자동 조정 기능을 사용하여 최적의 배치 크기를 찾고 이를 모델 훈련에 적용하는 과정
model = LitModel(batch_size = 32)
trainer = pl.Trainer(auto_scale_batch_size=True)
# trainer = pl.Trainer(auto_scale_batch_size='binsearch')
trainer.tune(model)PyTorch Lightning으로 trainer를 사용한 모습

출력해석
GPU available: True, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUsGPU가 사용 가능하지만 현재 사용되지 않고 있음을 나타낸다,
GPU를 사용하려면 Trainer(gpus=1) 또는 --gpus=1 플래그를 설정
Batch size 2 succeeded, trying batch size 4
Batch size 4 succeeded, trying batch size 8
Batch size 8 succeeded, trying batch size 16
Batch size 16 succeeded, trying batch size 32
Batch size 32 succeeded, trying batch size 64
Batch size 64 succeeded, trying batch size 128
Batch size 128 succeeded, trying batch size 256
Batch size 256 succeeded, trying batch size 512
Batch size 512 succeeded, trying batch size 1024
Batch size 1024 succeeded, trying batch size 2048
Batch size 2048 succeeded, trying batch size 4096
Batch size 4096 succeeded, trying batch size 8192
Batch size 8192 succeeded, trying batch size 16384
Batch size 16384 succeeded, trying batch size 32768
Batch size 20000 succeeded, trying batch size 40000
Finished batch size finder, will continue with full run using batch size 20000
배치 크기를 점차적으로 증가시키면서 모델이 성공적으로 실행되는지 확인과정이며
최종적으로 배치 크기 20000까지 성공하여 이를 사용할 것을 결정한다
Restoring states from the checkpoint path at /content/scale_batch_size_temp_model_87b083fb-4895-48df-a05b-9820d2339e9e.ckpt
{'scale_batch_size': 20000}체크포인트에서 상태를 복원하고, 최적 배치 크기가 20000임을 나타냄
4. 자동 학습률 선택 기능
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchmetrics
import pytorch_lightning as pl
# PyTorch Lightning 모듈 클래스 정의
class LitModel(pl.LightningModule):
def __init__(self, learning_rate, batch_size):
super().__init__()
self.batch_size = batch_size
self.learning_rate = learning_rate # 학습률 설정
self.accuracy = torchmetrics.Accuracy() # 정확도 측정을 위한 객체 생성
self.train_acc = torchmetrics.Accuracy() # 훈련 정확도 측정을 위한 객체 생성
self.valid_acc = torchmetrics.Accuracy() # 검증 정확도 측정을 위한 객체 생성
# 첫 번째 합성곱 층
self.conv1 = nn.Sequential(nn.Conv2d(3, 16, 3), nn.ReLU(), nn.MaxPool2d(2, 2))
# 두 번째 합성곱 층
self.conv2 = nn.Sequential(nn.Conv2d(16, 32, 3), nn.ReLU(), nn.MaxPool2d(2, 2))
# 세 번째 합성곱 층
self.conv3 = nn.Sequential(nn.Conv2d(32, 64, 3), nn.ReLU(), nn.MaxPool2d(2, 2))
# 첫 번째 완전 연결 층
self.fc1 = nn.Sequential(nn.Flatten(), nn.Linear(64*5*5, 256), nn.ReLU(), nn.Linear(256, 128), nn.ReLU())
# 두 번째 완전 연결 층
self.fc2 = nn.Sequential(nn.Linear(128, 2),)
# PyTorch Lightning의 데이터 로더 설정
def train_dataloader(self):
# 학습 데이터 로더 반환
return torch.utils.data.DataLoader(dataset=train, batch_size=32, shuffle=True)
def val_dataloader(self):
# 검증 데이터 로더 반환
return torch.utils.data.DataLoader(dataset=val, batch_size=32, shuffle=False)
def cross_entropy_loss(self, logits, labels):
return F.nll_loss(logits, labels)
# PyTorch Lightning의 훈련 단계 정의
def training_step(self, batch, batch_idx):
data, label = batch
output = self.forward(data)
loss = nn.CrossEntropyLoss()(output, label)
self.log('train_loss', loss) # 훈련 손실 로깅
self.log('train_acc_step', self.accuracy(output, label)) # 훈련 정확도 로깅
return {'loss': loss, 'log': self.log}
def training_epoch_end(self, outs):
# 에폭 종료 시 훈련 정확도 로깅
self.log('train_acc_epoch', self.accuracy.compute())
# PyTorch Lightning의 검증 단계 정의
def validation_step(self, batch, batch_idx):
val_data, val_label = batch
val_output = self.forward(val_data)
val_loss = nn.CrossEntropyLoss()(val_output, val_label)
self.log('val_acc_step', self.accuracy(val_output, val_label)) # 검증 정확도 로깅
self.log('val_loss', val_loss) # 검증 손실 로깅
def validation_epoch_end(self, outs):
# 에폭 종료 시 검증 정확도 로깅
self.log('val_acc_epoch', self.accuracy.compute())
# PyTorch Lightning의 최적화 설정
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=self.learning_rate) # Adam 옵티마이저 설정
return optimizer
def forward(self, x):
# PyTorch Lightning에서 forward는 예측/추론 동작을 정의함
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.fc1(x)
x = self.fc2(x)
return F.softmax(x, dim=1) # 소프트맥스 함수로 확률 분포 반환
train_dataloader와 val_dataloader 함수는 학습 및 검증 데이터 로더를 반환
자동 학습 속도 튜너 구현
from pytorch_lightning.callbacks import ModelCheckpoint
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
# 모델 초기화: 배치 크기와 학습률 설정
model = LitModel(batch_size=32, learning_rate=0.001)
# 학습률 로거 설정
trainer = pl.Trainer(gpus=1, auto_lr_find=True) # GPU 사용 설정 및 자동 학습률 찾기 설정
# 모델 튜닝 (학습률 찾기 포함)
# 결과는 tune 메서드 실행 후 확인 가능
trainer.tune(model)

GPU 사용 가능 여부: GPU가 사용 가능하며, 실제로 사용되고 있음을 나타냅니다.
TPU 및 IPU 사용 여부: TPU와 IPU는 사용되지 않음을 나타냅니다.
LOCAL_RANK 및 CUDA_VISIBLE_DEVICES: 로컬 순위와 사용 중인 CUDA 장치를 나타냅니다.
Finding best initial lr: 최적의 초기 학습률을 찾는 과정을 나타냅니다.
진행 상태: 100% 완료되었음을 나타내며, 100번의 반복(iteration)을 통해 최적의 학습률을 찾았습니다.
소요 시간: 약 51초가 소요되었고, 초당 약 9.47번의 반복이 이루어졌음을 나타
설정된 학습률: 최적의 학습률이 0.19054607179632482로 설정
학습률 vs 손실 플롯 시각화
PyTorch Lightning의 학습률 찾기 기능을 사용
- trainer.tuner.lr_find(model)을 통해 학습률을 탐색
- lr_finder.plot(suggest=True)을 사용하여 학습률과 손실 간의 관계를 시각화
- 빨간 점은 lr_finder.suggestion()이 제안하는 최적의 학습률
# PyTorch Lightning의 학습률 찾기 기능 사용
lr_finder = trainer.tuner.lr_find(model)
# 플롯 생성 및 시각화 (suggest=True는 최적의 학습률을 제안함)
fig = lr_finder.plot(suggest=True)
fig.show()
학습률(Learning rate)과 손실(Loss)의 관계를 나타내는 그래프
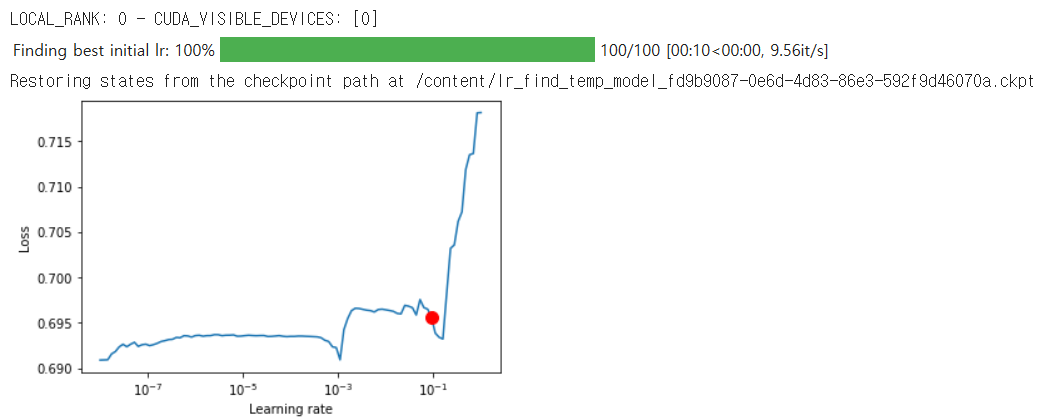
그래프에서 빨간 점은 lr_finder.suggestion()이 제안하는 최적의 학습률을 나타낸다.
그래프는 학습률이 증가함에 따라 손실 값이 어떻게 변화하는지 보여준다.
학습된 배치 크기와 학습률로 모델 훈련하기
PyTorch Lightning을 사용하여 모델을 훈련하는 과정
이전에 찾은 최적의 배치 크기와 학습률을 사용하여 모델을 초기화하고, GPU를 사용하여 최대 10 에폭 동안 훈련
# 모델 초기화: 배치 크기와 학습률 설정
model = LitModel(batch_size=32, learning_rate=0.001)
# 트레이너 초기화: GPU 사용, 최대 에폭 수 설정, 진행 상황 표시 빈도 설정
trainer = pl.Trainer(gpus=1, max_epochs=10, progress_bar_refresh_rate=10)
# 모델 훈련 ⚡
trainer.fit(model)
모델요약
| Name | Type | Params
-------------------------------------
0 | conv1 | Sequential | 448
1 | conv2 | Sequential | 4.6 K
2 | conv3 | Sequential | 18.5 K
3 | fc1 | Sequential | 442 K
4 | fc2 | Sequential | 258
-------------------------------------
466 K Trainable params
0 Non-trainable params
466 K Total params
1.866 Total estimated model params size (MB)
각 레이어(층)의 이름과 유형, 파라미터 수
총 훈련 가능한 파라미터 수는 466K
훈련 불가능한 파라미터는 없다
모델의 총 파라미터 수는 466K
총 모델 파라미터 크기(메모리 추정)는 약 1.866MB
Epoch 9: 100%
782/782 [1:48:58<00:00, 8.36s/it, loss=0.471, v_num=0]
Validating: 100%
157/157 [00:17<00:00, 9.31it/s]
Validating: 100%
157/157 [00:17<00:00, 9.32it/s]
Validating: 100%
157/157 [00:17<00:00, 9.26it/s]
Validating: 100%
157/157 [00:17<00:00, 9.47it/s]
Validating: 100%
157/157 [00:17<00:00, 9.35it/s]
Validating: 100%
157/157 [00:17<00:00, 9.45it/s]
Validating: 100%
157/157 [00:17<00:00, 9.42it/s]
Validating: 100%
157/157 [00:17<00:00, 9.36it/s]
Validating: 100%
157/157 [00:17<00:00, 9.41it/s]
Validating: 100%
157/157 [00:17<00:00, 9.51it/s]
에폭 진행 상황: 9번째 에폭에서 손실 값이 0.471로 훈련이 완료
Tensorboard logs
TensorBoard를 사용하여 PyTorch Lightning 훈련 과정에서 생성된 로그를 시각화
# TensorBoard 확장 로드
%load_ext tensorboard
# TensorBoard 실행, 로그 디렉토리 설정
%tensorboard --logdir lightning_logs/
위 코드를 실행하면 아래와 같이 출력된다.


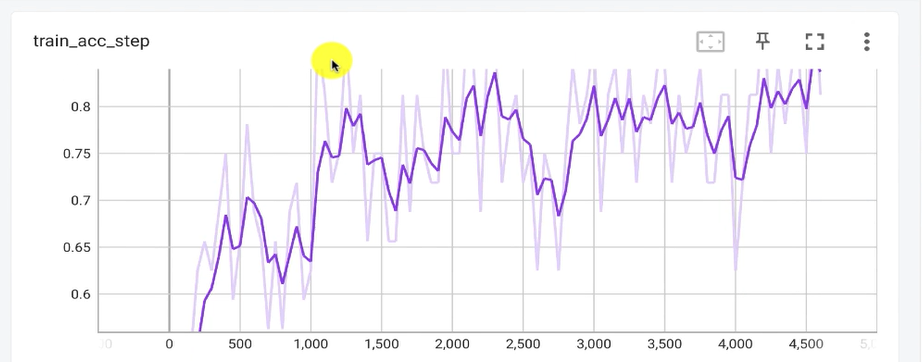
애포크가 깊어짐에따라 값이 바뀌는 로그들을 Tensorboard UI를 통해 실시간으로 모니터링이 가능하다.
6. 콜백 사용하기 - 조기 중지 및 체크포인트 저장
PyTorch Lightning에서 조기 중지(Early Stopping)와 모델 체크포인트(Model Checkpoint)를 설정하는 방법
# 조기 중지 설정
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
early_stop = EarlyStopping(
monitor='val_loss', # 모니터할 지표 설정
patience=3, # 몇 번의 에폭 동안 개선되지 않으면 중지
strict=False, # 엄격한 모드 비활성화
verbose=False, # 로그 출력 비활성화
mode='min' # 손실이 최소화될 때 중지
)
# 모델 체크포인트 설정
from pytorch_lightning.callbacks import ModelCheckpoint
checkpoint_callback = ModelCheckpoint(
monitor='val_loss', # 모니터할 지표 설정
dirpath='models/', # 체크포인트 저장 경로
filename='sample-catsvsdogs-{epoch:02d}-{val_loss:.2f}', # 체크포인트 파일 이름 형식
save_top_k=3, # 상위 3개의 모델 저장
mode='min' # 손실이 최소화될 때 저장
)
# 사용자 정의 콜백 정의
class MyPrintingCallback(pl.callbacks.base.Callback):
def on_init_start(self, trainer):
print('Starting to init trainer!')
def on_init_end(self, trainer):
print('trainer is init now')
def on_train_end(self, trainer, pl_module):
print('do something when training ends')1. 조기 중지 (Early Stopping):
조기 중지는 모델이 일정 횟수 동안 성능 향상이 없을 때 훈련을 중지시키는 정규화 방법입니다. 이는 과적합을 방지하기 위해 사용됩니다.
EarlyStopping 콜백을 사용하여 검증 손실(val_loss)을 모니터링하고, 3번의 에폭 동안 개선이 없으면 훈련을 중지하도록 설정했습니다.
2. 모델 체크포인트 (Model Checkpoint):
모델 체크포인트는 일정 간격으로 모델 또는 가중치를 저장하여 나중에 다시 로드할 수 있도록 하는 콜백입니다.
ModelCheckpoint 콜백을 사용하여 검증 손실(val_loss)을 모니터링하고, 상위 3개의 모델을 저장하도록 설정했습니다. 저장 경로와 파일 이름 형식도 지정했습니다.
3. 사용자 정의 콜백 (Custom Callback):
사용자 정의 콜백을 통해 특정 이벤트가 발생할 때 사용자 정의 동작을 수행할 수 있습니다.
MyPrintingCallback 클래스는 트레이너 초기화 시작, 초기화 완료, 훈련 종료 시에 메시지를 출력하도록 정의되었습니다.
콜백을 사용하여 모델 훈련하기
PyTorch Lightning을 사용하여 이전에 설정한 조기 중지(Early Stopping)와 모델 체크포인트(Model Checkpoint), 사용자 정의 콜백(Custom Callback)을 포함하여 모델을 훈련
# 모델 초기화: 배치 크기와 학습률 설정
model = LitModel(batch_size=32, learning_rate=0.001)
# 트레이너 초기화: GPU 사용, 최대 에폭 수 설정, 진행 상황 표시 빈도 설정, 콜백 포함
trainer = pl.Trainer(
gpus=1,
max_epochs=10,
progress_bar_refresh_rate=10,
callbacks=[EarlyStopping('val_loss'), checkpoint_callback, MyPrintingCallback()]
)
# 모델 훈련
trainer.fit(model)
| Name | Type | Params
-----------------------------------------
0 | accuracy | Accuracy | 0
1 | train_acc | Accuracy | 0
2 | valid_acc | Accuracy | 0
3 | conv1 | Sequential | 448
4 | conv2 | Sequential | 4.6 K
5 | conv3 | Sequential | 18.5 K
6 | fc1 | Sequential | 442 K
7 | fc2 | Sequential | 258
-----------------------------------------
466 K Trainable params
0 Non-trainable params
466 K Total params
1.866 Total estimated model params size (MB)
Epoch 9: 100%
782/782 [12:29:13<00:00, 57.48s/it, loss=0.448, v_num=3]
Validating: 100%
157/157 [00:17<00:00, 9.05it/s]
Validating: 100%
157/157 [00:17<00:00, 9.01it/s]
Validating: 100%
157/157 [00:17<00:00, 9.07it/s]
Validating: 100%
157/157 [00:17<00:00, 9.08it/s]
Validating: 100%
157/157 [00:17<00:00, 9.13it/s]
Validating: 100%
157/157 [00:17<00:00, 8.94it/s]
Validating: 100%
157/157 [00:17<00:00, 9.05it/s]
Validating: 100%
157/157 [00:17<00:00, 8.98it/s]
Validating: 100%
157/157 [00:17<00:00, 8.89it/s]
Validating: 100%
157/157 [00:17<00:00, 9.01it/s]
9번째 에폭에서 손실 값이 0.448로 훈련이 완료
똑같이 텐서보드로 로그를 확인할 수 있다.
%load_ext tensorboard
%tensorboard --logdir lightning_logs/체크포인트에서 모델 복원하기
훈련 중 저장된 최고의 체크포인트에서 모델을 복원하고, 이를 사용하여 추론(inference)을 수행하는 방법
# 최고의 모델 체크포인트 경로 가져오기
best_model_path = checkpoint_callback.best_model_path
print(best_model_path)
# 예시 출력: /content/models/sample-catsvsdogs-epoch=09-val_loss=0.50.ckpt
# 최고의 체크포인트에서 모델 로드
pretrained_model = LitModel.load_from_checkpoint(
batch_size=32,
learning_rate=0.001,
checkpoint_path=best_model_path
)
# 모델을 CUDA로 이동
pretrained_model = pretrained_model.to("cuda")
# 모델을 평가 모드로 설정
pretrained_model.eval()
# 모델의 파라미터를 고정 (훈련 중 업데이트 방지)
pretrained_model.freeze()
체크포인트에서 모델을 로드한 후, 모델을 GPU로 이동시키고 평가 모드로 설정한 뒤, 파라미터를 고정하여 모델의 상태를 유지
이를 통해 최적화된 모델로 추론을 수행한다.
9. 모델을 프로덕션 배포를 위해 저장하기
훈련된 모델을 TorchScript로 변환하고, 이를 프로덕션 환경에서 사용할 수 있도록 저장하는 방법
TorchScript는 모델을 직렬화하여 비-Python 환경에서도 사용할 수 있게 해주는 도구이다.
# 최고의 체크포인트에서 모델 로드
model = LitModel.load_from_checkpoint(
batch_size=32,
learning_rate=0.001,
checkpoint_path=checkpoint_callback.best_model_path
)
# 모델을 TorchScript로 변환
script = model.to_torchscript()
# 프로덕션 환경에서 사용하기 위해 모델 저장
torch.jit.save(script, "model.pt")
10. 테스트 데이터 로더에서 32개 이미지에 대한 추론 실행
테스트 데이터 로더에서 가져온 샘플 이미지를 사용하여 훈련된 모델을 통해 추론을 수행하고, 그 결과를 시각화
각 이미지에 대해 모델이 예측한 라벨(고양이 또는 개)을 그래프에 표시하여 시각적으로 확인할 수 있다.
import torchvision
import matplotlib.pyplot as plt
import numpy as np
import torch
# 디바이스 설정 (GPU 사용 가능 시 GPU로 설정)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 검증 데이터 로더에서 샘플 가져오기
samples, _ = iter(val_loader).next()
samples = samples.to('cuda')
# 그래프 설정
fig = plt.figure(figsize=(12, 8))
fig.tight_layout()
# 모델을 통해 추론 실행
output = pretrained_model(samples[:24])
pred = torch.argmax(output, dim=1)
pred = [p.item() for p in pred]
ad = {0: 'cat', 1: 'dog'}
# 추론 결과 시각화
for num, sample in enumerate(samples[:24]):
plt.subplot(4, 6, num+1)
plt.title(ad[pred[num]])
plt.axis('off')
sample = sample.cpu().numpy()
plt.imshow(np.transpose(sample, (1, 2, 0)))
plt.show()
나쁘진 않지만 높은 정확도를 갖는 모델은 아니다.
11. 멀티-GPU 훈련하기
PyTorch Lightning을 사용하여 멀티-GPU 환경에서 모델을 훈련하는 방법을 보여준다.
- 콜백 설정: 조기 중지(Early Stopping), 모델 체크포인트(Model Checkpoint), 사용자 정의 콜백을 설정
- 멀티-GPU 설정: sync_dist=True 옵션을 사용하여 검증 및 테스트 단계의 로깅을 동기화
- 트레이너 초기화: gpus 파라미터를 사용하여 멀티-GPU를 설정
- 모델 훈련: 트레이너를 사용하여 모델을 훈련
각 GPU 작업자 간의 동기화를 보장하여 일관된 모델 상태를 유지할 수 있다.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchmetrics
import pytorch_lightning as pl
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
from pytorch_lightning.callbacks import ModelCheckpoint
# 조기 중지 설정
early_stop = EarlyStopping(
monitor='val_loss', # 모니터할 지표 설정
patience=3, # 개선되지 않는 에폭 수 설정
strict=False, # 엄격 모드 비활성화
verbose=False, # 상세 정보 출력 비활성화
mode='min' # 최소값을 기준으로 모니터링
)
# 모델 체크포인트 설정
checkpoint_callback = ModelCheckpoint(
monitor='val_loss', # 모니터할 지표 설정
dirpath='models/', # 체크포인트 저장 경로 설정
filename='sample-catsvsdogs-{epoch:02d}-{val_loss:.2f}', # 체크포인트 파일 이름 형식 설정
save_top_k=3, # 상위 3개의 체크포인트 저장
mode='min' # 최소값을 기준으로 모니터링
)
# 사용자 정의 콜백 정의
class MyPrintingCallback(pl.callbacks.base.Callback):
def on_init_start(self, trainer):
print('Starting to init trainer!')
def on_init_end(self, trainer):
print('trainer is init now')
def on_train_end(self, trainer, pl_module):
print('do something when training ends')
# 멀티-GPU용 모델 정의
class LitModel_mGPU(pl.LightningModule):
def __init__(self):
super().__init__()
self.accuracy = torchmetrics.Accuracy()
self.train_acc = torchmetrics.Accuracy()
self.valid_acc = torchmetrics.Accuracy()
self.conv1 = nn.Sequential(nn.Conv2d(3,16,3), nn.ReLU(), nn.MaxPool2d(2,2))
self.conv2 = nn.Sequential(nn.Conv2d(16,32,3), nn.ReLU(), nn.MaxPool2d(2,2))
self.conv3 = nn.Sequential(nn.Conv2d(32,64,3), nn.ReLU(), nn.MaxPool2d(2,2))
self.fc1 = nn.Sequential(nn.Flatten(), nn.Linear(64*5*5,256), nn.ReLU(), nn.Linear(256,128), nn.ReLU())
self.fc2 = nn.Sequential(nn.Linear(128,2),)
def train_dataloader(self):
return torch.utils.data.DataLoader(dataset=train, batch_size=32, shuffle=True)
def val_dataloader(self):
return torch.utils.data.DataLoader(dataset=val, batch_size=32, shuffle=False)
def cross_entropy_loss(self, logits, labels):
return F.nll_loss(logits, labels)
def training_step(self, batch, batch_idx):
data, label = batch
output = self.forward(data)
loss = nn.CrossEntropyLoss()(output, label)
self.log('train_loss', loss)
self.log('train_acc_step', self.accuracy(output, label))
return {'loss': loss, 'log': self.log}
def training_epoch_end(self, outs):
self.log('train_acc_epoch', self.accuracy.compute())
def validation_step(self, batch, batch_idx):
val_data, val_label = batch
val_output = self.forward(val_data)
val_loss = nn.CrossEntropyLoss()(val_output, val_label)
self.log('val_loss', val_loss, on_step=True, on_epoch=True, sync_dist=True)
def validation_epoch_end(self, outs):
self.log('val_acc_epoch', self.accuracy.compute())
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=0.0005)
return optimizer
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.fc1(x)
x = self.fc2(x)
return F.softmax(x, dim=1)
# 모델 초기화
model = LitModel_mGPU()
# 트레이너 초기화: GPU 사용, 최대 에폭 수 설정, 진행 상황 표시 빈도 설정, 콜백 포함
trainer = pl.Trainer(
gpus=1, # 사용할 GPU 수 설정 (멀티-GPU 사용 시에는 해당 값을 조정)
max_epochs=10,
progress_bar_refresh_rate=10,
callbacks=[early_stop, checkpoint_callback, MyPrintingCallback()]
)
# 모델 훈련
trainer.fit(model)
| Name | Type | Params
-----------------------------------------
0 | accuracy | Accuracy | 0
1 | train_acc | Accuracy | 0
2 | valid_acc | Accuracy | 0
3 | conv1 | Sequential | 448
4 | conv2 | Sequential | 4.6 K
5 | conv3 | Sequential | 18.5 K
6 | fc1 | Sequential | 442 K
7 | fc2 | Sequential | 258
-----------------------------------------
466 K Trainable params
0 Non-trainable params
466 K Total params
1.866 Total estimated model params size (MB)
12. 프로파일러 - 성능 및 병목 현상 프로파일러
PyTorch Lightning의 간단한 프로파일러를 사용하여 모델 훈련 중의 성능 및 병목 현상을 분석
프로파일러를 사용하면 모델 훈련 과정에서 시간 소모가 많은 부분을 식별할 수 있으며,
이를 통해 모델을 최적화할 수 있다.
설정된 파라미터에 따라 모델을 훈련하고, 프로파일러는 훈련 과정의 각 단계에서 소요된 시간을 기록,
이를 통해 성능 병목 현상을 파악하고 개선
# 모델 초기화
model = LitModel_mGPU()
# 트레이너 초기화: GPU 사용, 최대 에폭 수 설정, 진행 상황 표시 빈도 설정, 프로파일러 사용
trainer = pl.Trainer(
gpus=1, # 사용할 GPU 수 설정
max_epochs=1, # 최대 에폭 수 설정
progress_bar_refresh_rate=10, # 진행 상황 표시 빈도 설정
profiler="simple" # 간단한 프로파일러 사용
)
# 모델 훈련
trainer.fit(model)
결과 해석:
프로파일러 사용:
profiler="simple" 설정은 간단한 프로파일러를 사용하여 모델 훈련 중의 성능 및 병목 현상을 분석합니다.
프로파일러는 각 단계에서 소요된 시간을 기록하여, 가장 많은 시간이 소요되는 부분을 식별하고 최적화할 수 있도록 도와줍니다.
모델 훈련:
모델은 설정된 에폭 수만큼 훈련됩니다. 이 경우, 최대 1 에폭 동안 훈련
13. TPU에서 모델 훈련하기
PyTorch Lightning을 사용하여 TPU에서 모델을 훈련
TPU는 Google이 개발한 AI 가속기 전용 집적 회로로, 대규모 신경망 모델의 훈련 및 추론 속도를 크게 향상시킨다.
TPU 사용
GPU available: False, used: False
TPU available: True, using: 8 TPU cores
TPU 사용 가능 여부: TPU가 사용 가능하며, 8개의 TPU 코어가 사용되고 있음을 나타냄
모델요약
| Name | Type | Params
-----------------------------------------
0 | accuracy | Accuracy | 0
1 | train_acc | Accuracy | 0
2 | valid_acc | Accuracy | 0
3 | conv1 | Sequential | 448
4 | conv2 | Sequential | 4.6 K
5 | conv3 | Sequential | 18.5 K
6 | fc1 | Sequential | 442 K
7 | fc2 | Sequential | 258
-----------------------------------------
466 K Trainable params
0 Non-trainable params
466 K Total params
1.866 Total estimated model params size (MB)
Validation sanity check: 0%
0/2 [00:04<?, ?it/s]
/usr/local/lib/python3.7/dist-packages/torchmetrics/utilities/prints.py:36: UserWarning: The ``compute`` method of metric Accuracy was called before the ``update`` method which may lead to errors, as metric states have not yet been updated.
warnings.warn(*args, **kwargs)
Epoch 0: 100%
99/99 [01:56<00:00, 1.18s/it, loss=0.693, v_num=0]
Validating: 100%
20/20 [00:17<00:00, 1.09it/s]
첫 번째 에폭이 100% 완료되었고, 손실 값이 0.693
그냥 GPU 말고 TPU를 사용해서 효율적으로 모델을 개발하기 위함이다.
코드
# TPU 환경에서 필요한 패키지 설치
!pip install cloud-tpu-client==0.10 https://storage.googleapis.com/tpu-pytorch/wheels/torch_xla-1.8-cp37-cp37m-linux_x86_64.whl
!pip install pytorch-lightning --quiet
!pip install torchmetrics
# 필요한 패키지 임포트
import os
import torch
import torchmetrics
import torch.nn.functional as F
from torch import nn
from torchvision import transforms
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader, random_split
import pytorch_lightning as pl
from pytorch_lightning.loggers import TensorBoardLogger
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
from pytorch_lightning.callbacks import ModelCheckpoint
from PIL import Image
# 데이터셋 다운로드 및 압축 해제
!gdown --id 1Dvw0UpvItjig0JbnzbTgYKB-ibMrXdxk
!unzip -q dogs-vs-cats.zip
!unzip -q train.zip
!unzip -q test1.zip
# 데이터셋 클래스 정의
class Dataset():
def __init__(self, filelist, filepath, transform=None):
self.filelist = filelist
self.filepath = filepath
self.transform = transform
def __len__(self):
return int(len(self.filelist))
def __getitem__(self, index):
imgpath = os.path.join(self.filepath, self.filelist[index])
img = Image.open(imgpath)
if "dog" in imgpath:
label = 1
else:
label = 0
if self.transform is not None:
img = self.transform(img)
return (img, label)
# 디렉토리 경로 설정
train_dir = './train'
test_dir = './test1'
# 디렉토리 내 파일 목록 가져오기
train_files = os.listdir(train_dir)
test_files = os.listdir(test_dir)
# 변환 설정
transformations = transforms.Compose([transforms.Resize((60,60)), transforms.ToTensor()])
# 학습 및 테스트 데이터셋 객체 생성
train = Dataset(train_files, train_dir, transformations)
val = Dataset(test_files, test_dir, transformations)
train, val = torch.utils.data.random_split(train, [20000, 5000])
train_loader = torch.utils.data.DataLoader(dataset=train, batch_size=32, shuffle=True)
val_loader = torch.utils.data.DataLoader(dataset=val, batch_size=32, shuffle=False)
# 모델 정의
class LitModel_mGPU(pl.LightningModule):
def __init__(self):
super().__init__()
self.accuracy = torchmetrics.Accuracy()
self.train_acc = torchmetrics.Accuracy()
self.valid_acc = torchmetrics.Accuracy()
self.conv1 = nn.Sequential(nn.Conv2d(3, 16, 3), nn.ReLU(), nn.MaxPool2d(2, 2))
self.conv2 = nn.Sequential(nn.Conv2d(16, 32, 3), nn.ReLU(), nn.MaxPool2d(2, 2))
self.conv3 = nn.Sequential(nn.Conv2d(32, 64, 3), nn.ReLU(), nn.MaxPool2d(2, 2))
self.fc1 = nn.Sequential(nn.Flatten(), nn.Linear(64*5*5, 256), nn.ReLU(), nn.Linear(256, 128), nn.ReLU())
self.fc2 = nn.Sequential(nn.Linear(128, 2),)
def train_dataloader(self):
return torch.utils.data.DataLoader(dataset=train, batch_size=32, shuffle=True)
def val_dataloader(self):
return torch.utils.data.DataLoader(dataset=val, batch_size=32, shuffle=False)
def cross_entropy_loss(self, logits, labels):
return F.nll_loss(logits, labels)
def training_step(self, batch, batch_idx):
data, label = batch
output = self.forward(data)
loss = nn.CrossEntropyLoss()(output, label)
self.log('train_loss', loss)
self.log('train_acc_step', self.accuracy(output, label))
return {'loss': loss, 'log': self.log}
def training_epoch_end(self, outs):
self.log('train_acc_epoch', self.accuracy.compute())
def validation_step(self, batch, batch_idx):
val_data, val_label = batch
val_output = self.forward(val_data)
val_loss = nn.CrossEntropyLoss()(val_output, val_label)
self.log('val_loss', val_loss, on_step=True, on_epoch=True, sync_dist=True)
def validation_epoch_end(self, outs):
self.log('val_acc_epoch', self.accuracy.compute())
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=0.0005)
return optimizer
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.fc1(x)
x = self.fc2(x)
return F.softmax(x, dim=1)
# 모델 초기화
model = LitModel_mGPU()
# 트레이너 초기화: TPU 코어 사용, 최대 에폭 수 설정, 진행 상황 표시 빈도 설정
trainer = pl.Trainer(
tpu_cores=8,
max_epochs=1,
progress_bar_refresh_rate=10,
)
# 모델 훈련
trainer.fit(model)
