전이 학습은 대부분의 사람들이 CNN을 처음부터 끝까지 훈련하지 않는 이유와 관련이 있다.
즉, 랜덤 초기화 대신에 대규모 데이터셋으로 사전 훈련된 네트워크를 활용하여 훈련 시간을 줄이고 성능을 향상시키는 기법이기 때문이다.
전이 학습의 필요성
전이 학습의 필요성
대규모 네트워크를 훈련하기에 충분한 크기의 데이터셋을 찾기 어려움.
ImageNet과 같은 대규모 데이터셋으로 사전 훈련된 네트워크의 가중치를 사용.
전이 학습의 주요 시나리오
1. 특징 추출 (Feature Extraction)
2. 미세 조정 (Fine Tuning)
3. 고정된 특징 추출기로 사용 (Using as a Fixed Feature Extractor)
전이 학습의 개념 및 원리
특징 추출 (Feature Extraction)
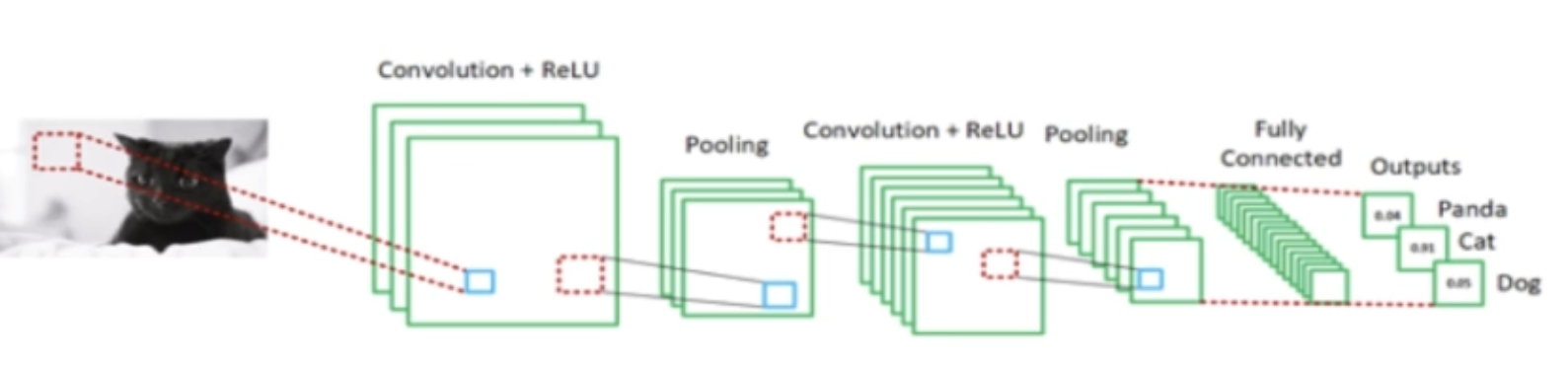
사전 훈련된 네트워크의 하위 층 가중치를 고정 (freeze)하고 상위 층만 재훈련.
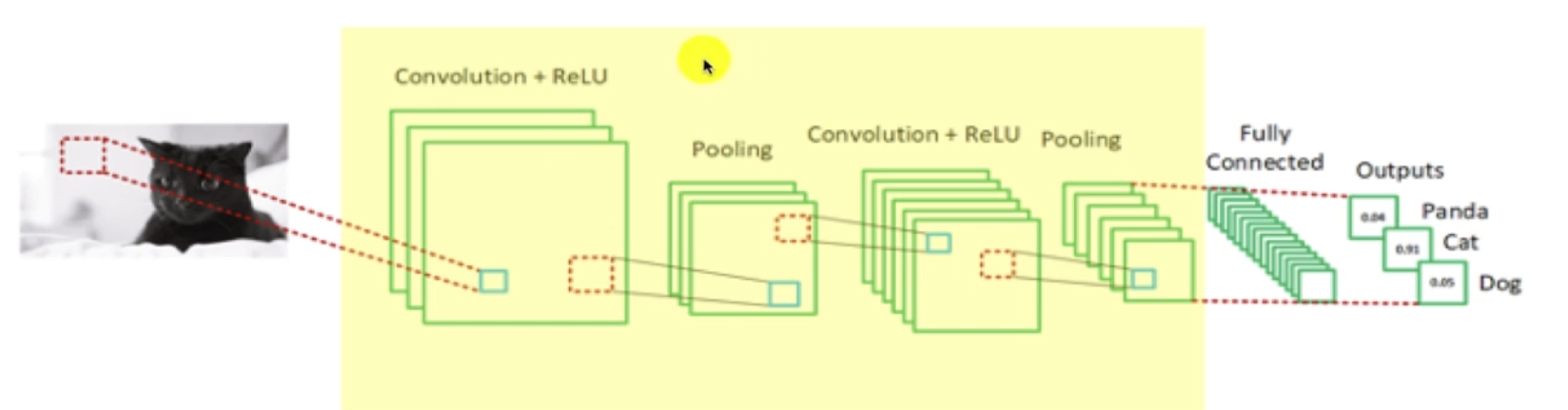
예를 들어, ImageNet으로 훈련된 네트워크를 사용하여 고양이, 개, 판다와 같은 새로운 클래스에 대해 상위 완전 연결 층을 재훈련.
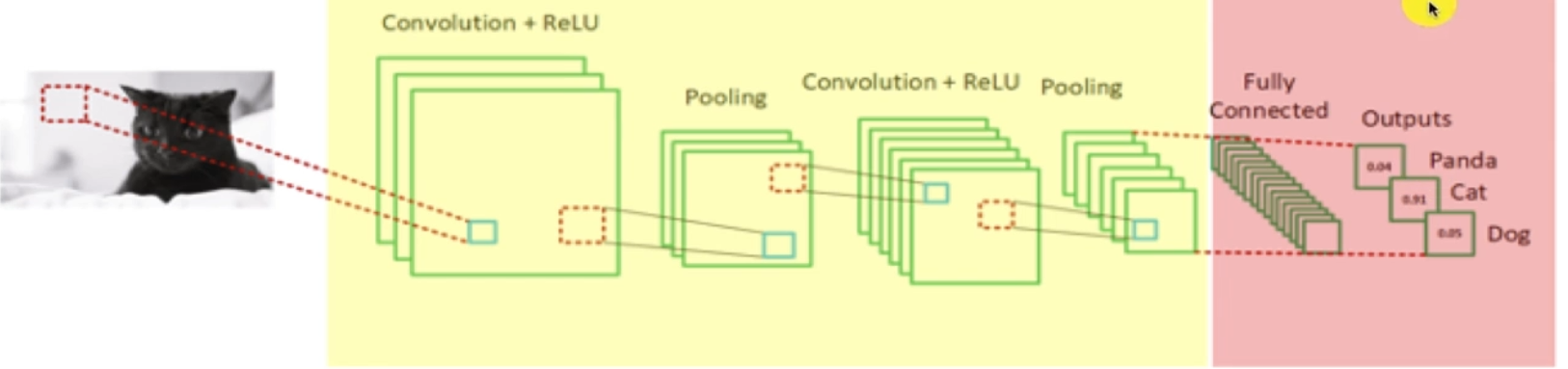
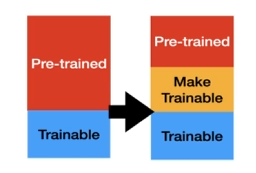
미세 조정 (Fine Tuning)
하위 층 가중치는 고정하고 상위 층 가중치는 학습 가능하게 하여 재훈련.

작은 학습률 (learning rate)을 사용하여 가중치를 조금씩 조정.
전이 학습의 활용 시점
이상적 시나리오:
새로운 데이터셋이 크고 기존의 데이터셋과 유사할 때.
덜 이상적이지만 추천되는 시나리오:
새로운 데이터셋이 크지만 기존 데이터셋과 약간 다를 때.
적합하지 않은 시나리오:
새로운 데이터셋이 작을 때.

감사합니다. https://www.youtube.com/channel/UCxlkiu9_aWijoD7BannNM7w