라이브러리 호출
# 데이터 분석 및 조작을 위한 라이브러리
import numpy as np
import pandas as pd
import os
# PyTorch 관련 라이브러리
import torch
import torch.nn as nn
import cv2
import matplotlib.pyplot as plt
import torchvision
import time
import copy
from torch.utils.data import Dataset, DataLoader, ConcatDataset
from torchsummary import summary
from torch.utils.tensorboard import SummaryWriter
from torchvision import datasets, transforms, models
import torch.optim as optim
import torch.nn.functional as F
from tqdm import tqdm_notebook as tqdm
from PIL import Image
# CUDA 사용 가능 여부 확인 및 디바이스 설정
torch.cuda.is_available() # CUDA 사용 가능 여부 확인
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # CUDA 사용 가능하면 cuda로 설정, 아니면 cpu로 설정Kaggle's Cats vs Dogs 이미지 다운
!gdown --id 1Dvw0UpvItjig0JbnzbTgYKB-ibMrXdxk
!unzip -q dogs-vs-cats.zip
!unzip -q train.zip
!unzip -q test1.zip 
이미지 파일 불러오기
# 파일에 대한 디렉터리 경로 설정
train_dir = './train'
test_dir = './test1'
# 디렉토리에서 파일 가져오기
train_files = os.listdir(train_dir)
test_files = os.listdir(test_dir)
print(f'Number of images in {train_dir} is {len(train_files)}')
print(f'Number of images in {test_dir} is {len(test_files)}')
출력 결과를 보면
train 데이터 셋은 25000개,
test 데이터 셋은 12500개
트레인 데이터셋의 첫번째 사진을 가져와보자
imgpath = os.path.join(train_dir, train_files[0])
print(imgpath)첫번째 사진은 강아지 사진이다.
이미지 데이터 전처리
이미지 데이터를 전처리하기 위해 변환(transformation)들을 연쇄적으로 적용하는 transforms.Compose를 사용
# 이미지 데이터를 전처리하기 위한 변환을 정의
transformations = transforms.Compose([
transforms.Resize((60, 60)), # 이미지를 (60, 60) 크기로 조정
transforms.ToTensor() # 이미지를 Tensor 형식으로 변환하고 픽셀 값을 [0, 1] 범위로 정규화
])
PyTorch 모델이 학습할 수 있도록 이미지를 텐서 형식으로 변환
이 작업의 목적은 데이터의 일관성을 유지하고 모델 학습의 효율성을 높이는 것에 있다.
데이터셋 정보(경로, 레이블 및 변환)를 저장하는 데이터셋 클래스 생성
torch.utils.data.random_splithttps://pytorch.org/docs/stable/data.html#torch.utils.data.Dataset
Dataset 클래스 정의
class Dataset():
def __init__(self, filelist, filepath, transform=None):
self.filelist = filelist # 파일 리스트 (이미지 파일 이름들의 리스트)
self.filepath = filepath # 파일 경로 (이미지 파일이 저장된 디렉토리)
self.transform = transform # 변환 (이미지 전처리에 사용할 변환 함수들)
def __len__(self):
return int(len(self.filelist)) # 데이터셋의 크기 (이미지 파일의 개수)
def __getitem__(self, index):
imgpath = os.path.join(self.filepath, self.filelist[index]) # 인덱스에 해당하는 이미지 파일 경로
img = Image.open(imgpath) # 이미지 파일 열기
# 파일 경로에 'dog' 문자열이 포함되어 있으면 레이블을 1로, 그렇지 않으면 0으로 설정
if "dog" in imgpath:
label = 1
else:
label = 0
# 변환이 정의되어 있으면 이미지를 변환
if self.transform is not None:
img = self.transform(img)
return (img, label) # 이미지와 레이블을 반환
훈련 및 검증 데이터셋 객체 생성
# 훈련 및 검증 데이터셋 객체 생성
train = Dataset(train_files, train_dir, transformations) # 훈련 데이터셋
val = Dataset(test_files, test_dir, transformations) # 검증 데이터셋
생성된 데이터셋 객체는 PyTorch의 DataLoader와 함께 사용되어 모델 훈련 및 검증에 필요한 배치(batch) 데이터를 제공
데이터 세트 개체 사용
train 데이터셋 객체의 첫 번째 항목을 가져와 그 결과를 출력
#데이터 항목 가져오기
train.__getitem__(0)
튜플 형태로, 첫 번째 항목은 이미지 텐서,
두 번째 항목은 해당 이미지의 레이블
1. 이미지 텐서:
텐서는 3차원 형태로, 크기는 (채널, 높이, 너비)
예를 들어, tensor([[[0.3294, 0.3294, 0.3294, ..., 0.1765, 0.1765, 0.1686], ...]])는 3개의 채널(RGB)의 픽셀 값을 나타낸다.
2. 레이블:
레이블 1은 이미지가 'dog' 클래스에 속함을 나타낸다.
이미지 텐서와 레이블을 사용해서 모델의 입력과 출력으로 활용할 수 있다.
데이터 형태 출력
# 검증 데이터셋의 첫 번째 이미지의 형태를 출력
print(val.__getitem__(0)[0].shape)
# 훈련 데이터셋의 첫 번째 이미지의 형태를 출력
print(train.__getitem__(0)[0].shape)

60x60의 3차원, 3채널 이미지
60x60은 위에서 transforms.Resize((60, 60))으로 크기를
60x60으로 조정했고
transforms.ToTensor() 변환을 통해 이미지가 텐서로 변환되었음을 알 수 있다.
텐서로 변환됐다는걸 아는방법은
일반적인 이미지 데이터의 shape, 형태는 (높이, 너비, 채널 수)
ToTensor()를 통해 (채널 수, 높이, 너비) 형태로 변환된다.
출력값은 3, 60, 60으로 채널이 먼저 앞에 있는것을 보아
텐서로 변환되었음을 확인할 수 있다.
데이터 세트 개체를 사용하여 기차, 검증 분할을 생성
torch.utils.data.random_split 함수를 사용하여
train 데이터셋을 훈련 및 검증 데이터셋으로 무작위로 분할하고,
각 데이터셋의 크기를 출력
1. 데이터셋 분할
train, val = torch.utils.data.random_split(train,[20000,5000]) train 데이터셋을 훈련 데이터셋과 검증 데이터셋으로 무작위로 분할
[20000, 5000]는 분할할 데이터셋의 크기를 나타내며,
train 데이터셋에서 20000개의 샘플을 훈련 데이터셋으로,
5000개의 샘플을 검증 데이터셋으로 분할한다는 뜻이다.
random_split 함수는 데이터셋을 무작위로 분할하므로,
훈련과 검증에 사용되는 데이터가 무작위로 선택
2. 데이터셋 크기 확인
# 사이즈 확인
print(len(train))
print(len(val))25000개중 5000개는 검증으로 뺏으니까 각 20000, 5000개가 나와야한다.

검증 데이터셋(val)의 레이블 분포를 확인
# 레이블의 배열 생성
val_set_class_count = [val.__getitem__(x)[1] for x in range(len(val)) ]
import seaborn as sns
sns.countplot(val_set_class_count)해당코드는 검증 데이터엔 5000개를 0,1로 분류한것이다.
1이 개 이므로 나머지 파란색은 고양이다.
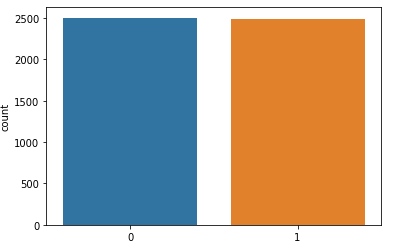
자세히 보면 파란색이 조금더 많다
즉 5000개는 개와 고양이 이미지가 고루 분포해있다.
x축 (Class):
클래스(레이블)를 나타낸다.
y축 (Count): 개수
두 막대의 높이가 비슷해 보이므로, 클래스 0과 클래스 1의 샘플 개수가 거의 동일하다는 것을 의미
데이터로더 생성
train_dataset = torch.utils.data.DataLoader(dataset = train, batch_size = 32, shuffle=True)
val_dataset = torch.utils.data.DataLoader(dataset = val, batch_size = 32, shuffle=False)샘플 이미지를 가져오는 데 사용
samples, labels = iter(train_dataset).next()
plt.figure(figsize=(16,24))
grid_imgs = torchvision.utils.make_grid(samples[:24])
np_grid_imgs = grid_imgs.numpy()
# 텐서에서 이미지는 (batch, 너비, 높이)이므로 표시하려면 numpy에서 (너비, 높이, 배치)로 전치해야 한다.
plt.imshow(np.transpose(np_grid_imgs, (1,2,0)))
모델 빌드
class CNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3,16,3),
nn.ReLU(),
nn.MaxPool2d(2,2)
)
self.conv2 = nn.Sequential(
nn.Conv2d(16,32,3),
nn.ReLU(),
nn.MaxPool2d(2,2)
)
self.conv3 = nn.Sequential(
nn.Conv2d(32,64,3),
nn.ReLU(),
nn.MaxPool2d(2,2)
)
self.fc1 = nn.Sequential(
nn.Flatten(),
nn.Linear(64*5*5,256),
nn.ReLU(),
nn.Linear(256,128),
nn.ReLU()
)
self.fc2 = nn.Sequential(
nn.Linear(128,2),
)
def forward(self,x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.fc1(x)
x = self.fc2(x)
return F.softmax(x,dim = 1) 손실 및 최적화 함수 정의
- 교차 엔트로피 손실을 사용
- Adam Optimization Descent Algorithm을 사용합니다. 학습률(LR)도 0.0005로 지정
- 우리의 시대를 50으로 설정
트레이닝 모델
criterion = nn.CrossEntropyLoss().to(device)
optimiser = optim.Adam(model.parameters(),lr=0.0005)
epochs = 10
type(train_dataset)
train_loss = []
train_accuracy = []
val_loss = []
val_accuracy = []
for epoch in range(epochs):
model.train()
total = 0
correct = 0
counter = 0
train_running_loss = 0
# Set our unit for tqdm and number of iterations i.e. len(train_dataset) no need for len as train_dataset is an iteratable
# tepoch becomes
with tqdm(train_dataset, unit="batch") as tepoch:
# our progress bar labels
tepoch.set_description(f'Epoch {epoch+1}/{epochs}')
for data,label in tepoch:
data,label = data.to(device), label.to(device)
optimiser.zero_grad()
output = model(data)
loss = criterion(output,label)
loss.backward()
optimiser.step()
train_running_loss += loss.item() * data.size(0)
_, pred = torch.max(output.data, 1)
# Keep track of how many images have been foward propagated
total += label.size(0)
# Keep track of how many were predicted to be correct
correct += (pred == label).sum().item()
train_accuracy.append(correct/total)
train_loss.append(train_running_loss/len(train_dataset))
print(f'Epoch {epoch+1} Training Accuracy = {correct/total}')
print(f'Epoch {epoch+1} Training Loss = {train_running_loss/len(train_dataset)}')
# Get our validation accuracy and loss scores
if epoch %1 == 0:
model.eval()
total = 0
correct = 0
val_running_loss = 0
# We don't need gradients for validation, so wrap in no_grad to save memory
with torch.no_grad():
for val_data, val_label in val_dataset:
val_data, val_label = val_data.to(device), val_label.to(device)
val_output = model(val_data)
loss_val = criterion(val_output, val_label)
# Calacuate the running loss by multiplying loss value by batch size
val_running_loss += loss_val.item() * val_data.size(0)
_, pred = torch.max(val_output.data, 1)
total += val_label.size(0)
correct += (pred == val_label).sum().item()
val_accuracy.append(correct/total)
# Calcuate loss per epoch by dividing runing loss by number of items in validation set
val_loss.append(val_running_loss/len(val_dataset))
#print(val_running_loss)
print(f'Epoch {epoch+1} Validation Accuracy = {correct/total}')
print(f'Epoch {epoch+1} Validation Loss = {val_running_loss/len(val_dataset)}')

로스 확인
train_loss
로그 확인
epoch_log = [*range(epochs)]
# To create a plot with secondary y-axis we need to create a subplot
fig, ax1 = plt.subplots()
# Set title and x-axis label rotation
plt.title("Accuracy & Loss vs Epoch")
plt.xticks(rotation=45)
# We use twinx to create a plot a secondary y axis
ax2 = ax1.twinx()
# Create plot for loss_log and accuracy_log
ax1.plot(epoch_log, train_loss, 'r-')
ax2.plot(epoch_log, train_accuracy, 'b-')
# Create plot for loss_log and accuracy_log
ax1.plot(epoch_log, val_loss, 'r-')
ax2.plot(epoch_log, val_accuarcy, 'b-')
# Set labels
ax1.set_xlabel('Epochs')
ax1.set_ylabel('Loss', color='r')
ax2.set_ylabel('Test Accuracy', color='b')
plt.show()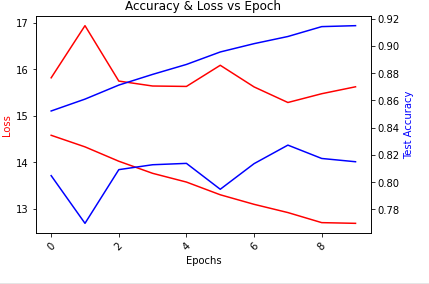
이미지 출력
# function to show an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# Loading one mini-batch
dataiter = iter(val_dataset)
images, labels = dataiter.next()
# Display images using torchvision's utils.make_grid()
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ',''.join('%1s' % labels[j].numpy() for j in range(32)))
이미지를 보면 왼쪽 위에서 부터 0
이미지위에 레이블 붙이기
samples, _ = iter(val_dataset).next()
samples = samples.to(device)
fig = plt.figure(figsize=(12, 8))
fig.tight_layout()
output = model(samples[:24])
pred = torch.argmax(output, dim=1)
pred = [p.item() for p in pred]
ad = {0:'cat', 1:'dog'}
for num, sample in enumerate(samples[:24]):
plt.subplot(4,6,num+1)
plt.title(ad[pred[num]])
plt.axis('off')
sample = sample.cpu().numpy()
plt.imshow(np.transpose(sample, (1,2,0)))

안녕하세요!
검증 데이터셋(val)의 표시 군을 확인합니다
레이블의 배열 생성
val_set_class_count = [val.getitem(x)[1] for x in range(len(val)) ]
import seaborn as sns
sns.countplot(val_set_class_count)
이 부분을 계속 해보고 있는데, 커넬 충돌 / 커넬이 죽어 재시작
계속 이 에러 응답을 받고 있습니다ㅠㅠ 왜 그런걸까요...?ㅠㅠ