패키지 호출
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import random
import os
# 이미지 데이터 증강 및 전처리를 위한 라이브러리
# ImageDataGenerator: 이미지 증강을 위한 클래스
# load_img: 파일에서 이미지를 로드하는 함수
# img_to_array: 이미지를 배열로 변환하는 함수
from tensorflow.keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array
# 클래스 벡터를 바이너리 클래스 매트릭스로 변환하는 함수
from tensorflow.keras.utils import to_categorical
# 데이터를 학습 세트와 테스트 세트로 분할하는 함수
from sklearn.model_selection import train_test_split1. 데이터 다운로드 및 탐색

이미지를 다운로드해주고,
# 이미지 사이즈 정의
IMAGE_WIDTH = 60
IMAGE_HEIGHT = 60
IMAGE_SIZE = (IMAGE_WIDTH, IMAGE_HEIGHT)
IMAGE_CHANNELS = 3이미지의 사이즈를 정의해준다.
데이터 로드시, 데이터 프레임에 레이블(개, 식별 표) 표시
import os
import pandas as pd
# './train' 디렉토리의 모든 파일 이름을 가져옴
filenames = os.listdir("./train")
# 파일 이름에서 카테고리를 저장할 리스트 초기화
categories = []
# 파일 이름을 순회하면서 카테고리 분류
for filename in filenames:
# 파일 이름을 '.'로 분할하여 첫 번째 부분을 카테고리로 사용
category = filename.split('.')[0]
# 카테고리가 'dog'이면 1, 아니면 0을 추가
if category == 'dog':
categories.append(1)
else:
categories.append(0)
# 파일 이름과 카테고리를 데이터프레임으로 생성
df = pd.DataFrame({
'filename': filenames,
'class': categories
})
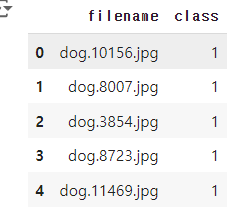
# 데이터프레임의 처음 다섯 행을 출력
df.head()
데이터 분포 그래프 확인
df['class'].value_counts().plot.bar()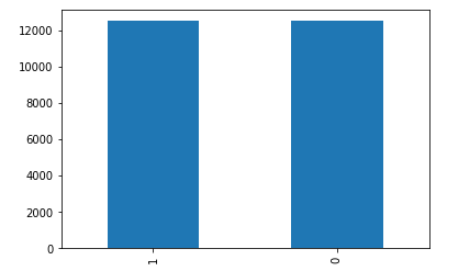
1(강아지),0(고양이) 각각 약 12000 개씩 24000개가 있음
이미지 샘플 출력
랜덤으로 이미지를 출력
sample = random.choice(filenames)
image = load_img("./train/" + sample)
plt.imshow(image)
2. 모델 구성

max pooling 3번, 컨볼루션 1,2,3 FC 3개로 이루어진 CNN
from keras.models import Sequential
from tensorflow import keras
from keras.layers import Conv2D, MaxPooling2D, Dropout, Flatten, Dense, Activation
model = Sequential()
model.add(Conv2D(16, (3, 3), activation='relu', input_shape=(IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(2, activation='softmax')) # 2 because we have cat and dog classes
opt = keras.optimizers.Adam(learning_rate=0.0005)
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
model.summary()3. 데이터 생성기 생성
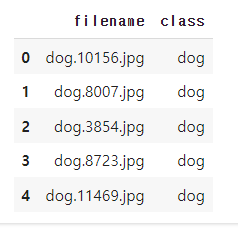
df["class"] = df["class"].replace({0: 'cat', 1: 'dog'})
df.head()
트레이닝 데이터 정규화
batch_size = 32
train_datagen = ImageDataGenerator(rescale = 1./255)
train_generator = train_datagen.flow_from_dataframe(
train_df,
"./train/",
x_col = 'filename',
y_col = 'class',
target_size = IMAGE_SIZE,
class_mode = 'categorical',
batch_size = batch_size
)
검증 데이터 정규화
validation_datagen = ImageDataGenerator(rescale=1./255)
validation_generator = validation_datagen.flow_from_dataframe(
validate_df,
"./train/",
x_col='filename',
y_col='class',
target_size=IMAGE_SIZE,
class_mode='categorical',
batch_size=batch_size
)
단일 이미지만 로드하도록 예제 Data Generator 만들기
example_df = train_df.sample(n=1).reset_index(drop=True)
example_generator = train_datagen.flow_from_dataframe(
example_df,
"./train/",
x_col='filename',
y_col='class',
target_size=IMAGE_SIZE,
class_mode='categorical'
)
plt.figure(figsize=(6, 6))
for X_batch, Y_batch in example_generator:
image = X_batch[0]
plt.imshow(image)
break
plt.tight_layout()
plt.show()
4. 트레이닝 모델
에포크 10
epochs = 10
history = model.fit(
train_generator,
epochs = epochs,
validation_data = validation_generator,
validation_steps = 5000//batch_size,
steps_per_epoch = 20000//batch_size,
)
에포크 수가 올라가면서 정확도가 증가하다가 에포크 6 부터 정확도가 내려가고 손실이 올라갔다.
성능 확인
# Viewour for performance plots
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 12))
ax1.plot(history.history['loss'], color='b', label="Training loss")
ax1.plot(history.history['val_loss'], color='r', label="validation loss")
ax1.set_xticks(np.arange(1, epochs, 1))
ax1.set_yticks(np.arange(0, 1, 0.1))
ax2.plot(history.history['accuracy'], color='b', label="Training accuracy")
ax2.plot(history.history['val_accuracy'], color='r',label="Validation accuracy")
ax2.set_xticks(np.arange(1, epochs, 1))
legend = plt.legend(loc='best', shadow=True)
plt.tight_layout()
plt.show()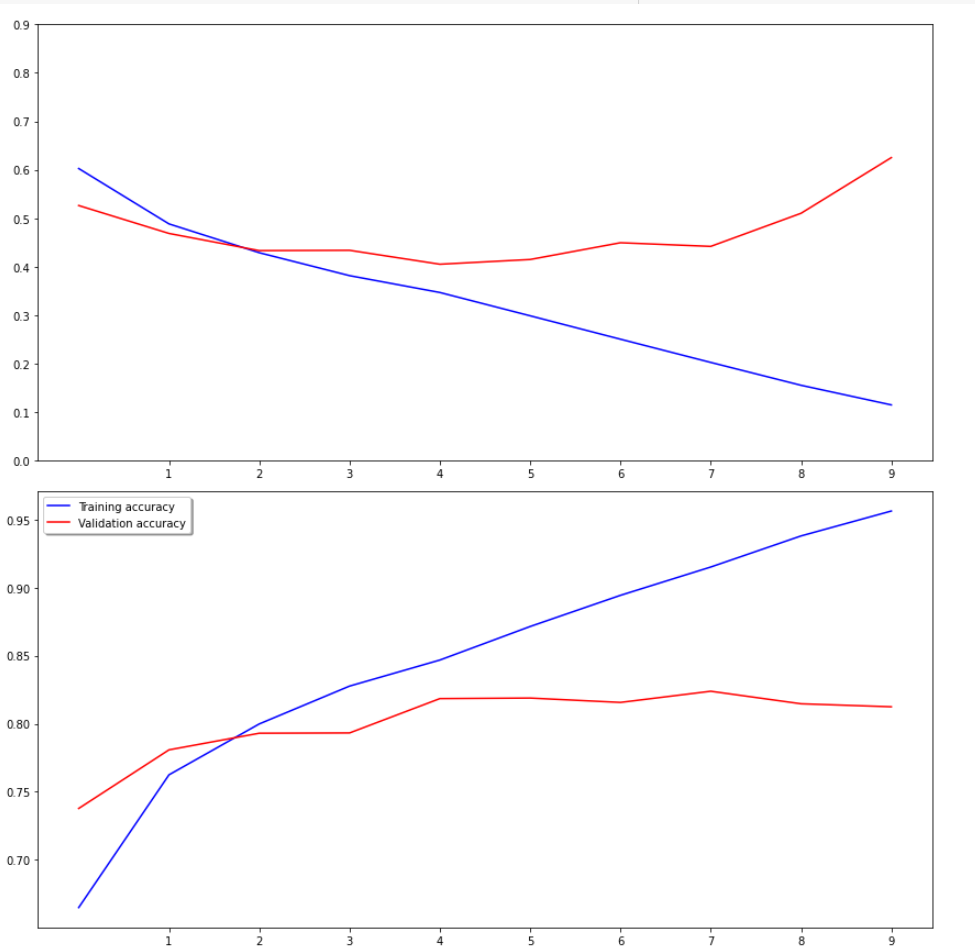
위에는 로스 plot
아래는 정확도 plot이다
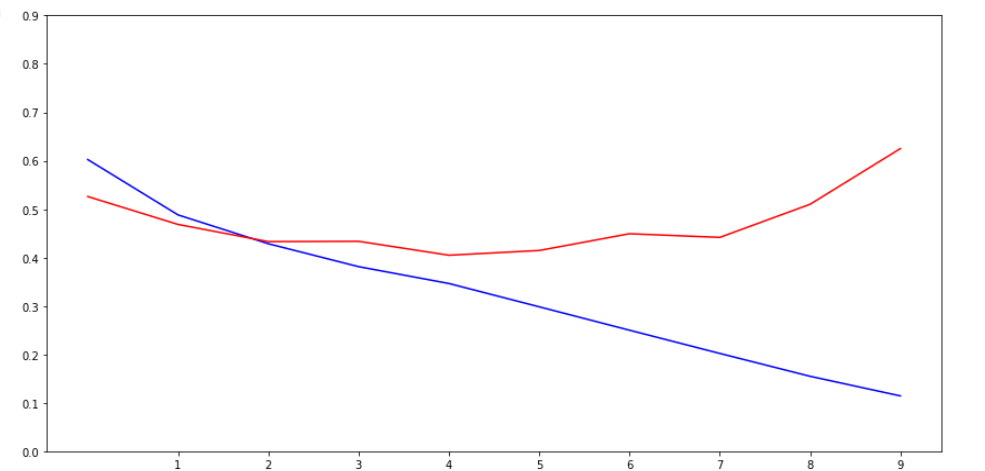
로스 그래프를 확인하면 트레인 로스는 에포크가 깊어질수록 내려가지만
검증 loss는 4회를 기점으로 오히려 증가하고있다.
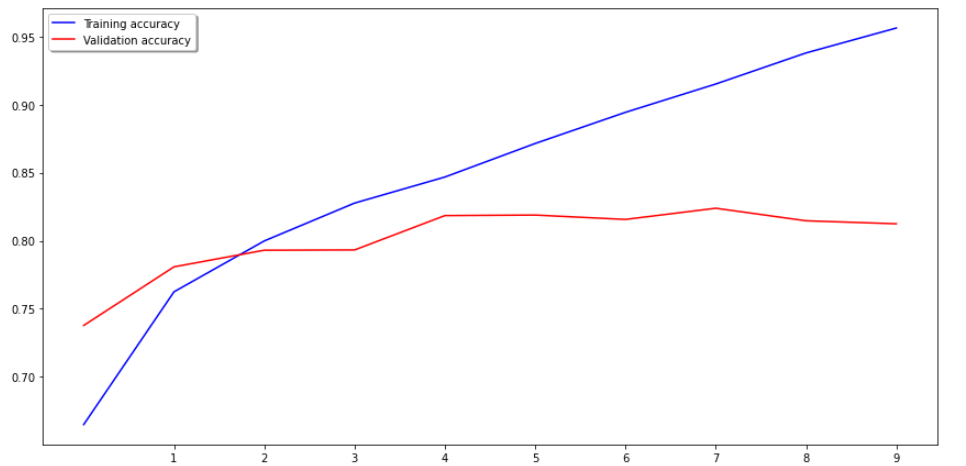
정확도를 확인하면 트레인 정확도는 계속 증가하지만
검증 정확도는 4부터 증가가 더디더니 7이후로 오히려 내려가고있다.
검증 데이터 확인
트레이닝 결과는 좋지만
검증 데이터의 값은 좋지 않다.
그러면 문제가 있는 검증 데이터를 확인해보자
predict = model.predict_generator(validation_generator, steps = np.ceil(5000/batch_size))보기 쉬운 데이터 프레임에 추가
validate_df['predicted'] = np.argmax(predict, axis=-1)
label_map = dict((v,k) for k,v in train_generator.class_indices.items())
validate_df['predicted'] = validate_df['predicted'].replace(label_map)
validate_df
검증 데이터 세트에서 이미지 배치에 대한 추론
sample_test = validate_df.head(18)
sample_test.head()
plt.figure(figsize=(12, 24))
for index, row in sample_test.iterrows():
filename = row['filename']
category = row['predicted']
img = load_img("./train/"+filename, target_size=IMAGE_SIZE)
plt.subplot(6, 3, index+1)
plt.imshow(img)
plt.xlabel(filename + '(' + "{}".format(category) + ')' )
plt.tight_layout()
plt.show()

얼리 스타핑 사용
저번에 공부하면서 알았던 얼리스탑 라이브러리를 이용해 에포크가 깊어지는데,
정확도나 loss값이 좋지않은 방향으로 가면 멈추게한다.
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
checkpoint = ModelCheckpoint("MNIST_Checkpoint.h5",
monitor="val_loss",
mode="min",
save_best_only = True,
verbose=1)
earlystop = EarlyStopping(monitor = 'val_loss', # value being monitored for improvement
min_delta = 0, #Abs value and is the min change required before we stop
patience = 5, #Number of epochs we wait before stopping
verbose = 1,
restore_best_weights = True) #keeps the best weigths once stopped

감사합니다. https://www.youtube.com/channel/UCxlkiu9_aWijoD7BannNM7w