SSD는 "Single Shot MultiBox Detector"의 약자
이는 객체 탐지(Object Detection) 알고리즘 중 하나로, 한 번의 신경망 패스만으로 여러 객체의 위치와 종류를 동시에 예측할 수 있는 모델이다.
SSD는 빠른 속도와 비교적 높은 정확도로 인해 다양한 실시간 애플리케이션에서 널리 사용됩니다. 이 알고리즘은 자율 주행 차량, 실시간 비디오 분석, 보안 시스템 등에 사용된다.
- 이미지 로드
# 이미지 로드
# frame = cv2.imread('./images/elephant.jpg')
# frame = cv2.imread('./images/Volleyball.jpeg')
# frame = cv2.imread('./images/coffee.jpg')
# frame = cv2.imread('./images/hilton.jpeg')
frame = cv2.imread('./images/tommys_beers.jpeg')
imshow("original", frame)
2. 이미지 전처리 및 네트워크 설정
이미지를 네트워크에 입력하기 전에 필요한 전처리를 수행하고, 네트워크 모델을 로드
print("Running our Single Shot Detector on our image...")
# 로드한 이미지의 복사본을 만듭니다.
image = frame.copy()
# 모델 입력에 필요한 너비와 높이 설정
inWidth = 300
inHeight = 300
WHRatio = inWidth / float(inHeight)
# 이미지 전처리에 필요한 변수들 설정
inScaleFactor = 0.007843
meanVal = 127.5
# 모델의 가중치와 구조 파일 경로 설정
prototxt = "SSDs/ssd_mobilenet_v1_coco.pbtxt"
weights = "SSDs/frozen_inference_graph.pb"
# 클래스의 수
num_classes = 90
# 신뢰도 임계값
thr = 0.5
# TensorFlow 모델 로드
net = cv2.dnn.readNetFromTensorflow(weights, prototxt)
swapRB = True
classNames = { 0: 'background',
1: 'person', 2: 'bicycle', 3: 'car', 4: 'motorcycle', 5: 'airplane', 6: 'bus',
7: 'train', 8: 'truck', 9: 'boat', 10: 'traffic light', 11: 'fire hydrant',
13: 'stop sign', 14: 'parking meter', 15: 'bench', 16: 'bird', 17: 'cat',
18: 'dog', 19: 'horse', 20: 'sheep', 21: 'cow', 22: 'elephant', 23: 'bear',
24: 'zebra', 25: 'giraffe', 27: 'backpack', 28: 'umbrella', 31: 'handbag',
32: 'tie', 33: 'suitcase', 34: 'frisbee', 35: 'skis', 36: 'snowboard',
37: 'sports ball', 38: 'kite', 39: 'baseball bat', 40: 'baseball glove',
41: 'skateboard', 42: 'surfboard', 43: 'tennis racket', 44: 'bottle',
46: 'wine glass', 47: 'cup', 48: 'fork', 49: 'knife', 50: 'spoon',
51: 'bowl', 52: 'banana', 53: 'apple', 54: 'sandwich', 55: 'orange',
56: 'broccoli', 57: 'carrot', 58: 'hot dog', 59: 'pizza', 60: 'donut',
61: 'cake', 62: 'chair', 63: 'couch', 64: 'potted plant', 65: 'bed',
67: 'dining table', 70: 'toilet', 72: 'tv', 73: 'laptop', 74: 'mouse',
75: 'remote', 76: 'keyboard', 77: 'cell phone', 78: 'microwave', 79: 'oven',
80: 'toaster', 81: 'sink', 82: 'refrigerator', 84: 'book', 85: 'clock',
86: 'vase', 87: 'scissors', 88: 'teddy bear', 89: 'hair drier', 90: 'toothbrush' }
- 네트워크를 통한 객체 탐지
전처리된 이미지를 네트워크에 입력하고, 객체 탐지를 수행
# 네트워크에 입력할 이미지 블롭 생성
blob = cv2.dnn.blobFromImage(frame, inScaleFactor, (inWidth, inHeight), (meanVal, meanVal, meanVal), swapRB)
net.setInput(blob)
# 네트워크에 이미지 블롭을 전달하여 결과를 얻음
detections = net.forward()
# 입력 이미지를 크롭, 필요한 경우 크기를 조정
cols = frame.shape[1]
rows = frame.shape[0]
if cols / float(rows) > WHRatio:
cropSize = (int(rows * WHRatio), rows)
else:
cropSize = (cols, int(cols / WHRatio))
y1 = int((rows - cropSize[1]) / 2)
y2 = y1 + cropSize[1]
x1 = int((cols - cropSize[0]) / 2)
x2 = x1 + cropSize[0]
frame = frame[y1:y2, x1:x2]
cols = frame.shape[1]
rows = frame.shape[0]
- 검출 결과 표시 및 출력
탐지된 객체에 대한 경계 상자를 그림과 함께 이미지에 표시하고, 결과 이미지를 출력
# 탐지된 객체를 순회
for i in range(detections.shape[2]):
confidence = detections[0, 0, i, 2]
# 신뢰도가 임계값보다 큰 경우, 경계 상자 생성
if confidence > thr:
class_id = int(detections[0, 0, i, 1])
xLeftBottom = int(detections[0, 0, i, 3] * cols)
yLeftBottom = int(detections[0, 0, i, 4] * rows)
xRightTop = int(detections[0, 0, i, 5] * cols)
yRightTop = int(detections[0, 0, i, 6] * rows)
# 이미지에 경계 상자 그림
cv2.rectangle(frame, (xLeftBottom, yLeftBottom), (xRightTop, yRightTop),
(0, 255, 0), 3)
# 클래스 이름과 신뢰도를 이미지에 표시
if class_id in classNames:
label = classNames[class_id] + ": " + str(confidence)
labelSize, baseLine = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)
yLeftBottom = max(yLeftBottom, labelSize[1])
cv2.rectangle(frame, (xLeftBottom, yLeftBottom - labelSize[1]),
(xLeftBottom + labelSize[0], yLeftBottom + baseLine),
(255, 255, 255), cv2.FILLED)
cv2.putText(frame, label, (xLeftBottom, yLeftBottom),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0))
# 탐지 결과를 화면에 표시
imshow("detections", frame)
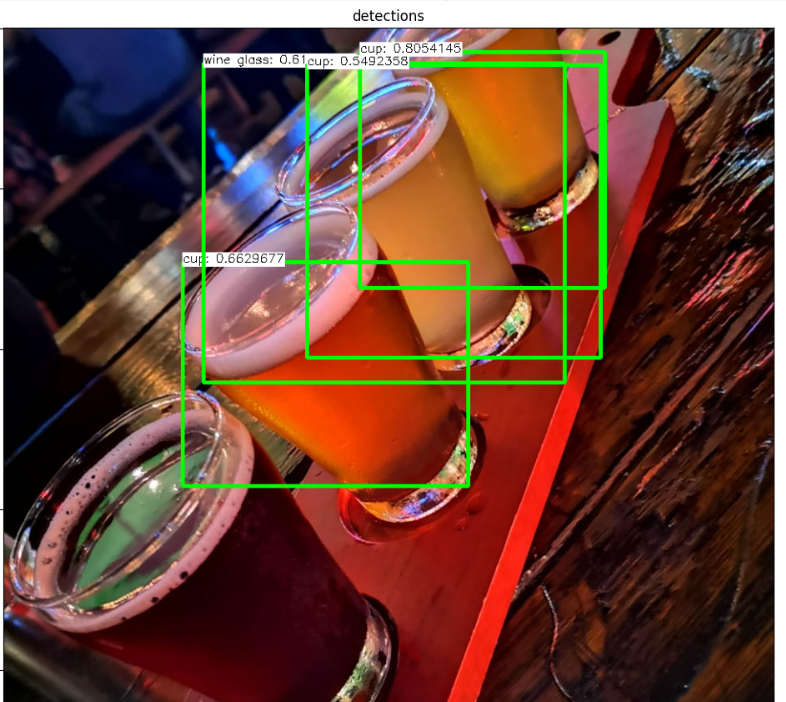
전체 코드
# 이미지를 로드합니다
#frame = cv2.imread('./images/elephant.jpg')
#frame = cv2.imread('./images/Volleyball.jpeg')
#frame = cv2.imread('./images/coffee.jpg')
#frame = cv2.imread('./images/hilton.jpeg')
frame = cv2.imread('./images/tommys_beers.jpeg')
imshow("original", frame)
print("Single Shot Detector를 이미지에서 실행합니다...")
# 로드한 이미지의 복사본을 만듭니다
image = frame.copy()
# 모델에 입력될 때 필요한 너비와 높이를 설정합니다
inWidth = 300
inHeight = 300
WHRatio = inWidth / float(inHeight)
# 이미지 전처리에 필요한 값들입니다
inScaleFactor = 0.007843
meanVal = 127.5
# 가중치와 모델 아키텍처의 경로를 지정합니다 (프로토콜 버퍼)
prototxt = "SSDs/ssd_mobilenet_v1_coco.pbtxt"
weights = "SSDs/frozen_inference_graph.pb"
# 클래스의 수
num_classes = 90
# 신뢰도 임계값
thr = 0.5
# TensorFlow 모델을 로드합니다
net = cv2.dnn.readNetFromTensorflow(weights, prototxt)
swapRB = True
classNames = {
0: 'background', 1: 'person', 2: 'bicycle', 3: 'car', 4: 'motorcycle',
5: 'airplane', 6: 'bus', 7: 'train', 8: 'truck', 9: 'boat',
10: 'traffic light', 11: 'fire hydrant', 13: 'stop sign', 14: 'parking meter',
15: 'bench', 16: 'bird', 17: 'cat', 18: 'dog', 19: 'horse',
20: 'sheep', 21: 'cow', 22: 'elephant', 23: 'bear', 24: 'zebra',
25: 'giraffe', 27: 'backpack', 28: 'umbrella', 31: 'handbag',
32: 'tie', 33: 'suitcase', 34: 'frisbee', 35: 'skis', 36: 'snowboard',
37: 'sports ball', 38: 'kite', 39: 'baseball bat', 40: 'baseball glove',
41: 'skateboard', 42: 'surfboard', 43: 'tennis racket', 44: 'bottle',
46: 'wine glass', 47: 'cup', 48: 'fork', 49: 'knife', 50: 'spoon',
51: 'bowl', 52: 'banana', 53: 'apple', 54: 'sandwich', 55: 'orange',
56: 'broccoli', 57: 'carrot', 58: 'hot dog', 59: 'pizza', 60: 'donut',
61: 'cake', 62: 'chair', 63: 'couch', 64: 'potted plant', 65: 'bed',
67: 'dining table', 70: 'toilet', 72: 'tv', 73: 'laptop', 74: 'mouse',
75: 'remote', 76: 'keyboard', 77: 'cell phone', 78: 'microwave', 79: 'oven',
80: 'toaster', 81: 'sink', 82: 'refrigerator', 84: 'book', 85: 'clock',
86: 'vase', 87: 'scissors', 88: 'teddy bear', 89: 'hair drier', 90: 'toothbrush'
}
# 네트워크에 입력될 입력 이미지 blob을 생성합니다
blob = cv2.dnn.blobFromImage(frame, inScaleFactor, (inWidth, inHeight), (meanVal, meanVal, meanVal), swapRB)
net.setInput(blob)
# 입력 이미지/blob을 네트워크에 전달합니다
detections = net.forward()
# 입력을 재조정하지 않고 정사각형 입력을 취하기 때문에 프레임을 자릅니다
cols = frame.shape[1]
rows = frame.shape[0]
if cols / float(rows) > WHRatio:
cropSize = (int(rows * WHRatio), rows)
else:
cropSize = (cols, int(cols / WHRatio))
y1 = int((rows - cropSize[1]) / 2)
y2 = y1 + cropSize[1]
x1 = int((cols - cropSize[0]) / 2)
x2 = x1 + cropSize[0]
frame = frame[y1:y2, x1:x2]
cols = frame.shape[1]
rows = frame.shape[0]
# 각 검출 결과를 반복합니다
for i in range(detections.shape[2]):
confidence = detections[0, 0, i, 2]
# 신뢰도가 임계값을 넘으면 바운딩 박스를 얻습니다
if confidence > thr:
class_id = int(detections[0, 0, i, 1])
xLeftBottom = int(detections[0, 0, i, 3] * cols)
yLeftBottom = int(detections[0, 0, i, 4] * rows)
xRightTop = int(detections[0, 0, i, 5] * cols)
yRightTop = int(detections[0, 0, i, 6] * rows)
# 이미지 위에 바운딩 박스를 그립니다
cv2.rectangle(frame, (xLeftBottom, yLeftBottom), (xRightTop, yRightTop), (0, 255, 0), 3)
# 클래스 이름을 가져와 이미지에 추가합니다 (흰색 배경 사용)
if class_id in classNames:
label = classNames[class_id] + ": " + str(confidence)
labelSize, baseLine = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)
yLeftBottom = max(yLeftBottom, labelSize[1])
cv2.rectangle(frame, (xLeftBottom, yLeftBottom - labelSize[1]),
(xLeftBottom + labelSize[0], yLeftBottom + baseLine),
(255, 255, 255), cv2.FILLED)
cv2.putText(frame, label, (xLeftBottom, yLeftBottom),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0))
# 검출 결과를 보여줍니다
imshow("detections", frame)



결과를 보면 인식되지 않는것이나, 중복돼서 인식하는 부분의 출력이 안된다.
중복돼서 인식되는 부분은 따로 코드를 수정해주면 되지만,
인식자체가 되지않는 부분은 SSD 특징인 객체 중첩과 복잡한 배경에선 인식하기 힘든 특징을 갖고있어
측정되지 않다고 판단된다.
각 이미지의 특성에 맞게 올바른 알고리즘을 선택해서 이미지를 처리해야 해야겠다.

감사합니다. https://www.youtube.com/channel/UCxlkiu9_aWijoD7BannNM7w