paper: https://arxiv.org/pdf/2312.03863
1. Introduction
3가지로 분류:
- Model Centric: 알고리즘 & 시스템 수준에 초점
- Model compression
- efficient pre-training
- efficient fine-tuning
- efficient inference
- efficient architecture design
-- 여기까지 살펴볼 예정--
- Data-Centric: 데이터의 퀄리티 & 구조
- Data selection
- Prompt engineering
- LLM framework:
- Unique features
- Underlying libraries
- specializations
2. Model-Centric Methods
2.1 Model Compression
설명: 모델의 사이즈 감소 and 계산량 감소
요즘 대부분의 LLM compression은 post-training setting 하에서 설계됨 → 학습이 다 된 모델에 compression 진행 (리소스가 많이 드는 재학습을 피하기 위해)
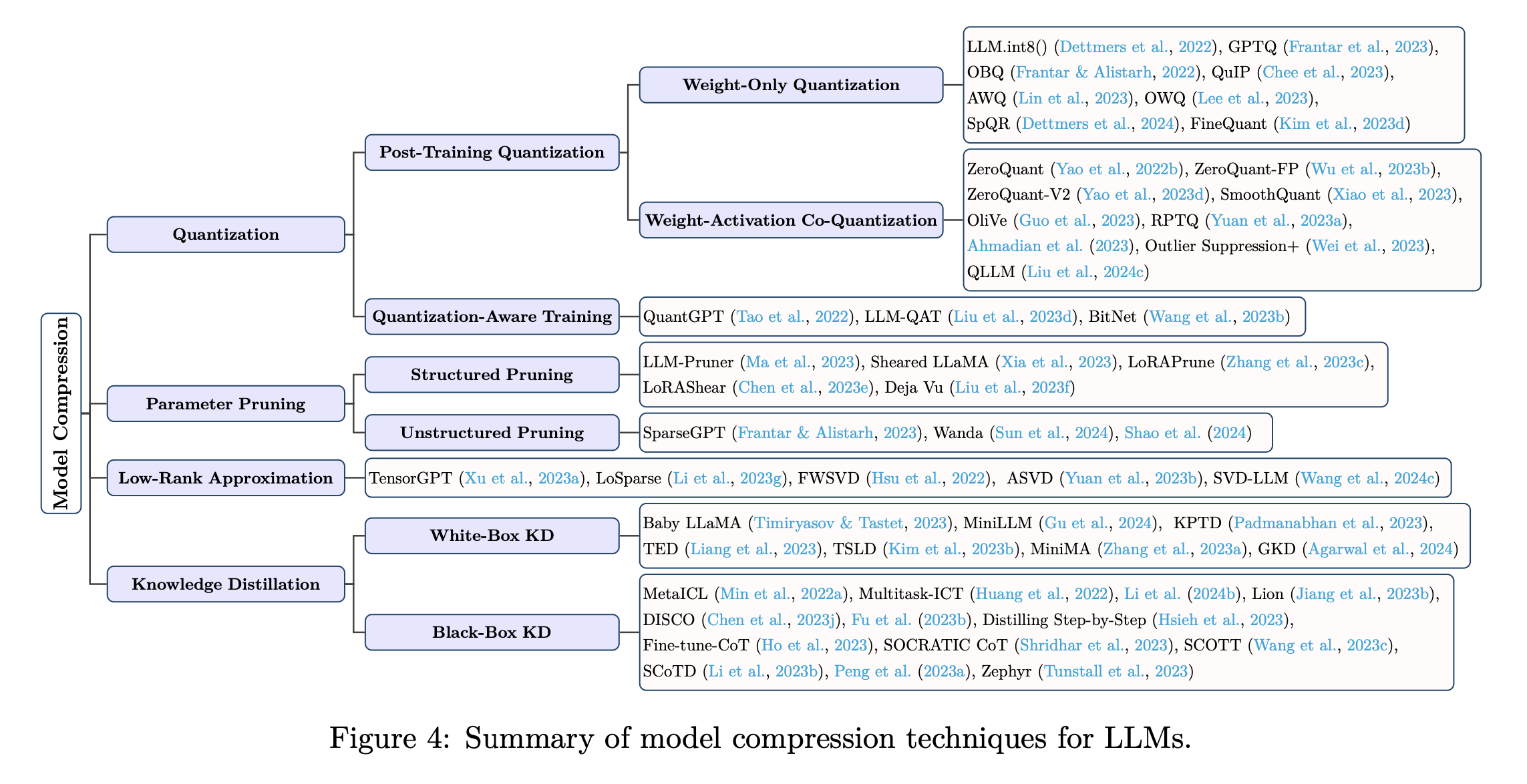
위 그림을 보면 알 수 있듯, 4가지로 나눌 수 있음
2.1.1 Quantization
⇒ Model weight and/or activations를 높은 precision 데이터 유형(e.g. FP32)에서 낮은 precision 데이터 유형(e.g. int8)으로 바꾸는 방법
‘Post-Training Quantizaiton(PTQ)’, ‘Quantization-aware training(QAT)’으로 분류
- PTQ(Post-Training Quantization)
- 설명: 학습이 완료된 모델에 quantization 진행. 정확도 하락을 보완하기 위해, 작은 데이터셋(a small calibration dataset)으로 양자화 된 weight/activations를 update! → 작은 데이터셋을 통해서 최소한의 손실을 얻을 수 있는 “양자화 상수” 같은 값들을 찾아주는 것! (Clipping도 사용할 수 있음) → 손실 측정 방법: FP32로 했을 때의 확률 분포와 양자화 했을 때의 확률 분포의 차이. KL divergence를 통해서 차이를 표현
- 종류
- Weight-Only Quantization: Model의 weight에만 quantization
- Weight-Activation Co-Quantization: Model weight + Activations에 quantization
- QAT(Quantization-aware training)
- 설명: 학습 process에서 LLM을 quantization! → LLM이 quantization 표현을 학습하게 함. 학습을 진행해야 하기 때문에 PTQ보다 더 비싸고, 시간이 소요됨
2.1.2 Parameter Pruning
⇒ 중복되거나 덜 중요한 가중치 제거
‘Structured pruning’, ‘Unstructured pruning’으로 분류
-
Structured Pruning
구조적인 패턴을 제거 (e.g. 연속적인 parameters의 group, LLM 가중치 매트릭스의 row, columns or sub-blocks와 같은 계층적 구조) -
Unstructured Pruning
- 모델 가중치를 개별적으로 제거 → structured pruning 보다 pruning 유연성이 있기에 정확도 저하가 더 적다
- 불규칙한 sparsification 유발 → Pruning 된 모델을 Hardware에 배포하기 힘들다
2.1.3 Low-Rank Approximation
LLM의 matrix 를 low-rank matrices()로 근사 → where (여기서 r은 m,n과 비교했을 때 매우 작다)
2.1.4 Knowledge Distillation
⇒ 큰 모델의 지식을 작은 모델에게 전달하는 방법. 큰 모델을 teacher model이라 하고, 작은 모델을 student model이라고 한다.
효과적이지만, 다른 방법들에 비해 자원을 많이 필요로 하는 ‘distillation-process’가 발생
‘White box methods’와 ‘Black box methods’로 분류
-
White-Box Knowledge Distillation
- 설명: Distillation process에서 Teacher LLM의 parameters or logits을 사용하는 방법
-
Black-Box Knowledge Distillation
- 설명: Distillation process에서 오직 teacher LLM이 생성한 outputs만을 사용하는 방법 (Open-source가 아닌 LLM을 teacher model로 사용하면 해당 모델의 parameters나 logits을 확인할 수 없음 → 그 경우는 White-box KD를 사용할 수 없음. 오직 Black-box KD만 사용 가능)
2.2 Efficient Pre-Training
4가지 측면에서 비용 절감을 목표
- 컴퓨팅 리소스
- 학습 시간
- 메모리
- 에너지 소비

Mixed Precision Training
Forward & Backward propagation에 Low-precision model 사용
방법
- Low precision gradients 계산
- 계산된 low-precision gradients를 high-precision gradients로 전환 (weights는 high-precision data type이니까 low-precision gradients의 data type을 이에 맞춰줘야 하기에)
- Original high-precision weights 업데이트
Scaling Models
방법: 더 작은 모델의 가중치를 활용해 더 큰 모델로 upscaling! (작은 모델을 활용해 점진적으로 모델의 크기나 구조 확장)
의의: Pretraining 수렴 가속화 & 학습 비용 줄임
Initialization Techniques
의의: 좋은 Initialization → 모델의 수렴이 가속화 → pre-training 효율 향상
Training Optimizers
많은 좋은 모델들(e.g. GPT-3, OPT, BLOOM, …)은 Adam 또는 AdamW를 사용해서 학습을 진행
Adam & AdamW는 메모리가 많이 필요하고, 계산적으로 비싸다 → 몇몇 연구들은 LLM pretraining을 가속화 하기 위해 새로운 optimizers를 제안
System-Level Pre-training Efficiency Optimization
높은 메모리 요구량과 계산 리소스로 인해, LLM은 대게 분산화 방식으로 pre-train 된다 → System-Level Optimization 기술은 큰 규모의 분산화 학습 환경에서 설계됨
e.g.) ZeRO
2.3 Efficient Fine-Tuning
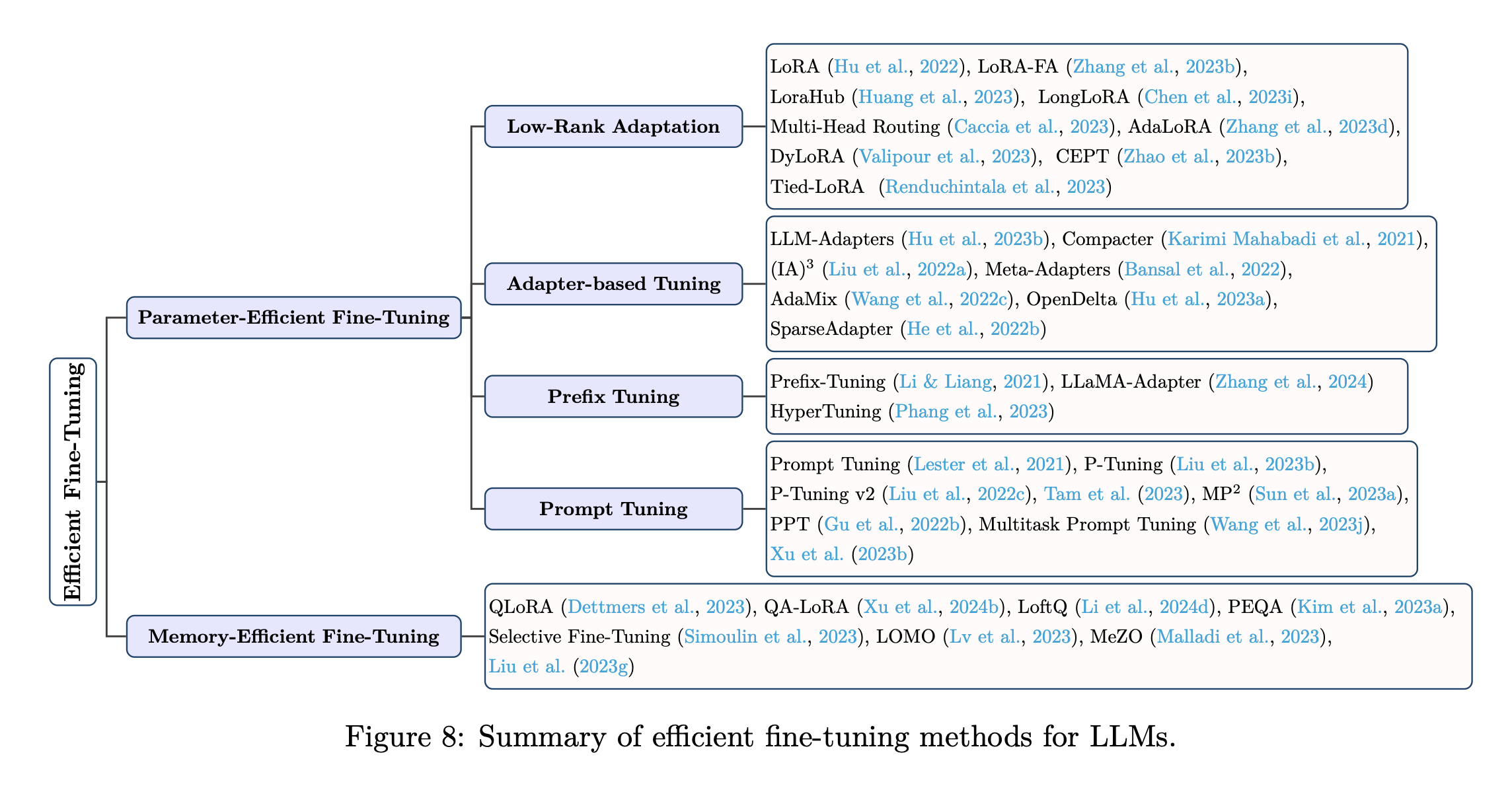
분류: PEFT(Parameter-Efficient Fine-Tuning), MEFT(Memory-Efficient Fine-Tuning)
2.3.1 Parameter-Efficient Fine-Tuning
- Low-Rank Adaptation(LoRA)
- 배경: Model Adaptation 중 가중치 변화()가 낮은 ‘intrinsic rank’를 가지고 있다는 가설
- 방법
- 학습되는 부분을 작은 matrix로 matrix decomposition하여 표현
- where
- 학습되는 부분:
- 의의:
- Matrix decomposition을 사용해, 학습되는 parameter의 수를 줄임
- 기존의 weight말고 추가적인 parameters를 사용해 finetuning에서 학습시켰지만, inference 시에 추가적인 latency가 발생하지 않는다 → 추가적인 parameter를 사용하기에 모델이 커졌다고 생각할 수 있지만, 를 에 더해주면 모델의 크기는 기존의 모델과 같아진다 → Inference 시 추가적인 latency가 발생하지 않음
- Adapter-based Tuning
Adapter: 학습 가능한 모듈으로 구성은 다음과 같음. Down projection → Non-linear → Up projection
기존에 pre-trained 모델의 가중치는 freeze 하고, 추가된 adapter만 학습에 사용됨 ⇒ 학습에 사용되는 parameter 수가 줄어듦!
대체로 LLM의 각 layer에 두 개의 adapters가 추가됨- Series Adapters: Attention 뒤 & Feed-forward 뒤
- Parellel Adapters: Attention과 Feed-forward 모듈에 병렬적으로 adapter 추가
- Prefix Tuning
“Prefix Token”: 학습 가능한 벡터들의 시리즈
LLM의 각 layer 앞에 prefix 추가. Prefix token은 특정 task에 맞게 학습이 되고, 가상의 단어 임베딩으로 여겨질 수도 있음 → Task에 따라 prefix를 갈아끼우면 됨!
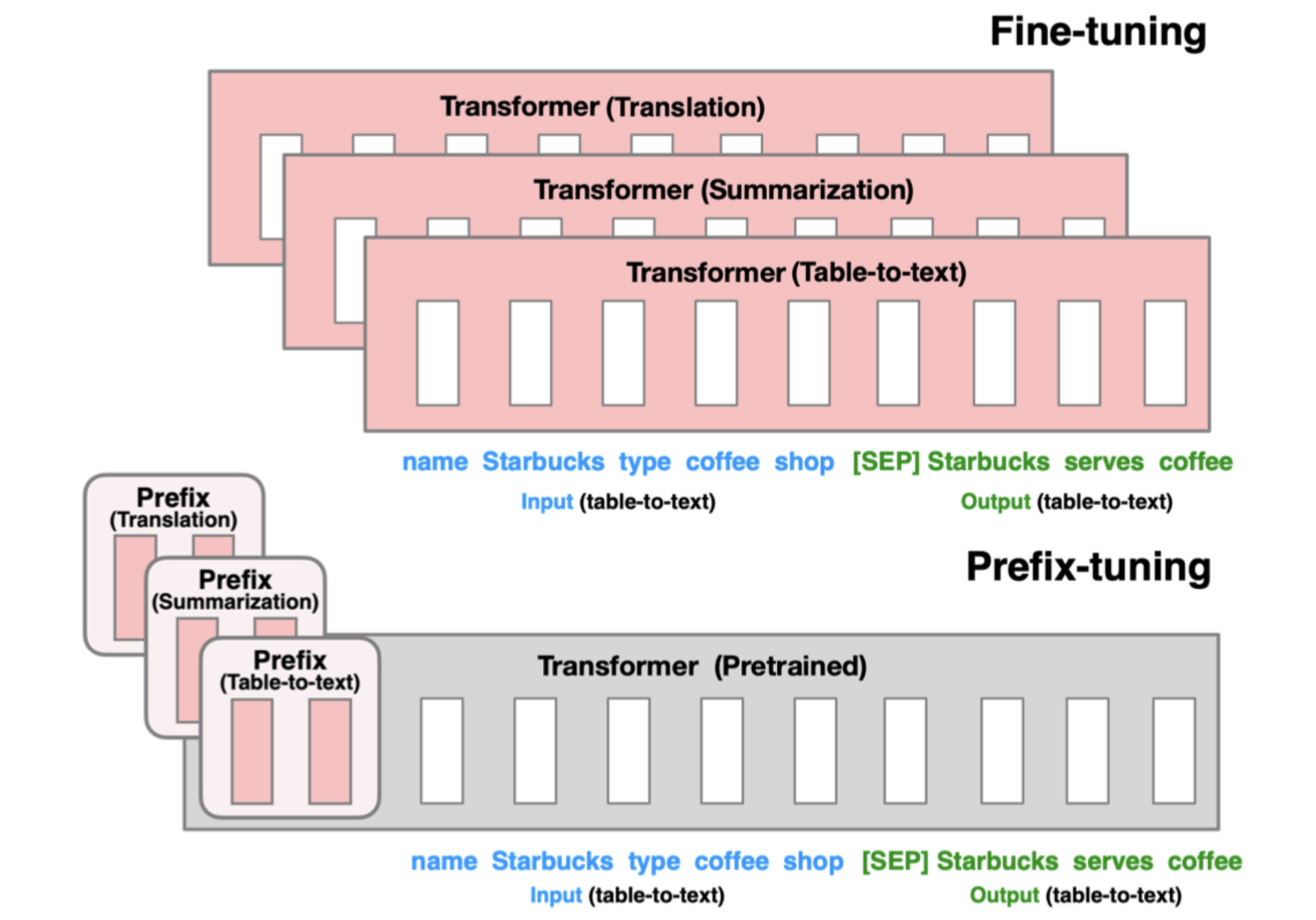 <그림 출처: prefix tuning paper>
<그림 출처: prefix tuning paper>
빨간색 부분을 학습 하는 것인데, finetuning은 모든 부분을 학습하지만 prefix tuning은 prefix만 학습을 진행 → 학습되는 parameter 수가 적어짐
- Prompt Tuning
Prefix tuning과 유사하지만 다른점: “학습 가능한 프롬프트 토큰을 입력 층에만 추가”
이렇게 추가되는 토큰은 앞에 prefix 처럼 추가되어도 되지만, 입력 토큰의 어디에나 추가되어도 된다
2.3.2 Memory-Efficient Fine-Tuning
“Memory saving에 초점!”
LoRA와 quantization 결합 방법론들
- QLoRA → QA LoRA
- LoftQ
- PEQA : two-stage quantization-aware finetuning
- etc
Gradient Optimization 기반 MEFT methods
- Selective Fine-tuning
- LOMO
- MeZO
- etc
2.4 Efficient Inference
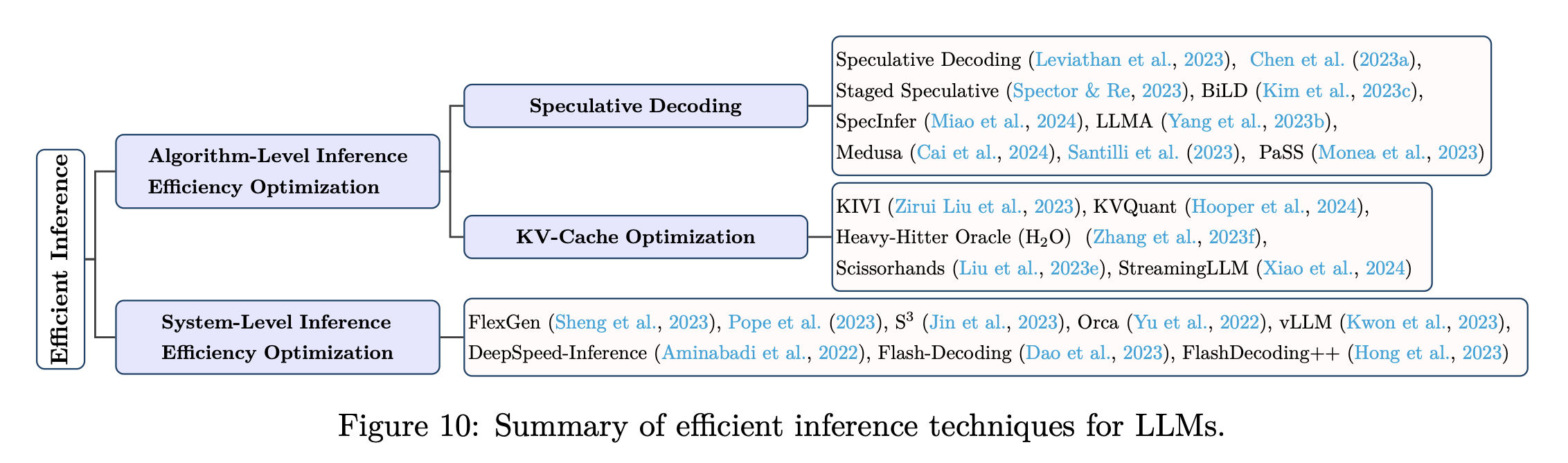
분류: “algorithm level”, “system level”
Algorithm-Level Inference Efficiency Optimization
- Speculative Decoding
AutoRegressive Model의 Sampling process 속도를 높이며, Inference Efficiency Optimization
- KV cache Optimization
Inference 시에, 예전 토큰의 Key-Value 쌍을 저장한다 (토큰 하나하나를 생성하는 autoregressive model의 성격상 이전 토큰의 KV 값들이 사용되는데, 같은 값을 매번 계산하는 것이 아니라 저장해두면 inference 속도가 빨라지기 때문).
따라서 생성되는 토큰의 길이가 길어질수록 KV cache size가 늘어남! → KV cache size를 줄이는 것이 inference efficiency 향상에 주요하다.
방법 2가지- KV cache 압축 (i.e., KV cache quantization)
- KV cache에서 일부 제거
System-Level Inference Efficiency Optimization
특정 hardware 하에 system level에서 최적화 될 수 있음
2.5 Efficient Architecture design
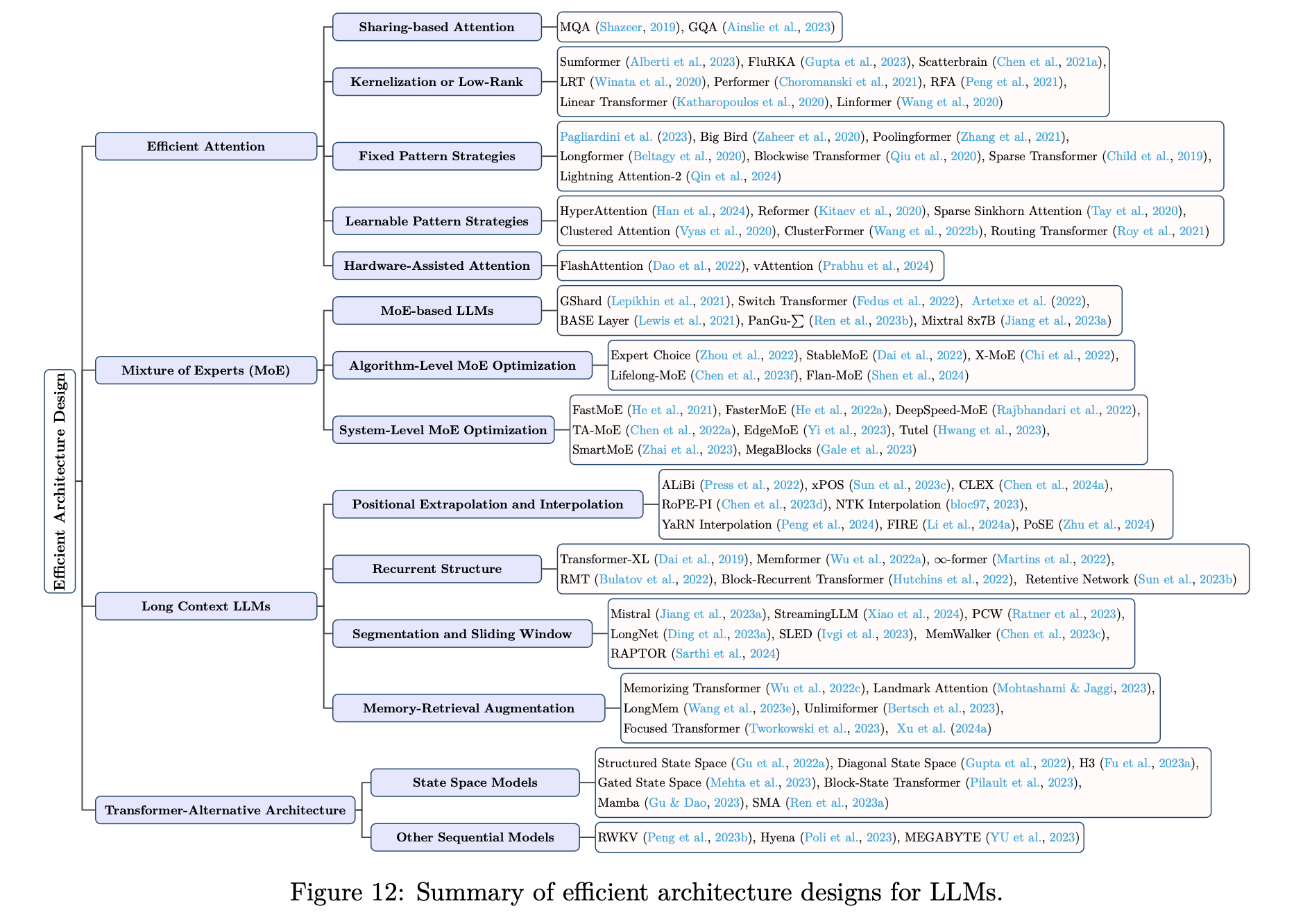
2.5.1 Efficient Attention
Attention module → Quadratic time & space complexity → 이 부분에서 속도가 상당히 늦어짐
- Sharing-based Attention
- 설명: KV head를 공유
- 방법들: Multi-Query Attention(MQA), Grouped-query Attention(GQA) 등
- 사용 모델: LLaMA 2 등
- Kernelization or Low-Rank
- 설명: Self-attention matrix에 low-rank representations 활용 or Attention Kernelization 기술 사용
- Low-rank representations: 하나의 matrix를 두 개의 작은 matrix로 matrix decomposition
- Kernelization: Attention을 직접적으로 구하지 않고, 해당 값을 근사화 or 효율적인 계산으로 구해줌. ex)
- 사용 모델: Sumformer, FluRKA, Low-Rank Transformer (LRT) 등
- 설명: Self-attention matrix에 low-rank representations 활용 or Attention Kernelization 기술 사용
- Fixed Pattern Strategies
- 설명: Attention matrix를 sparsifying 하며 efficiency 향상. Attention 범위를 미리 정해진 패턴으로 제한함으로써 달성(Local windows, fixed-stride block 등) → 즉, 모든 토큰에 대해 attention 하지 않음
- 사용 모델: Big Bird, Longformer 등
- Learnable Pattern Strategies
- 설명: 토큰 연관성을 학습 → 토큰을 buckets 또는 clusters로 그룹화 → 효율성 개선
- 사용 모델: HyperAttention, Reformer
- Hardware-Assisted Attention
- 설명: 하드웨어별 기술 개발에 중점을 둠
- 예시) FlashAttention
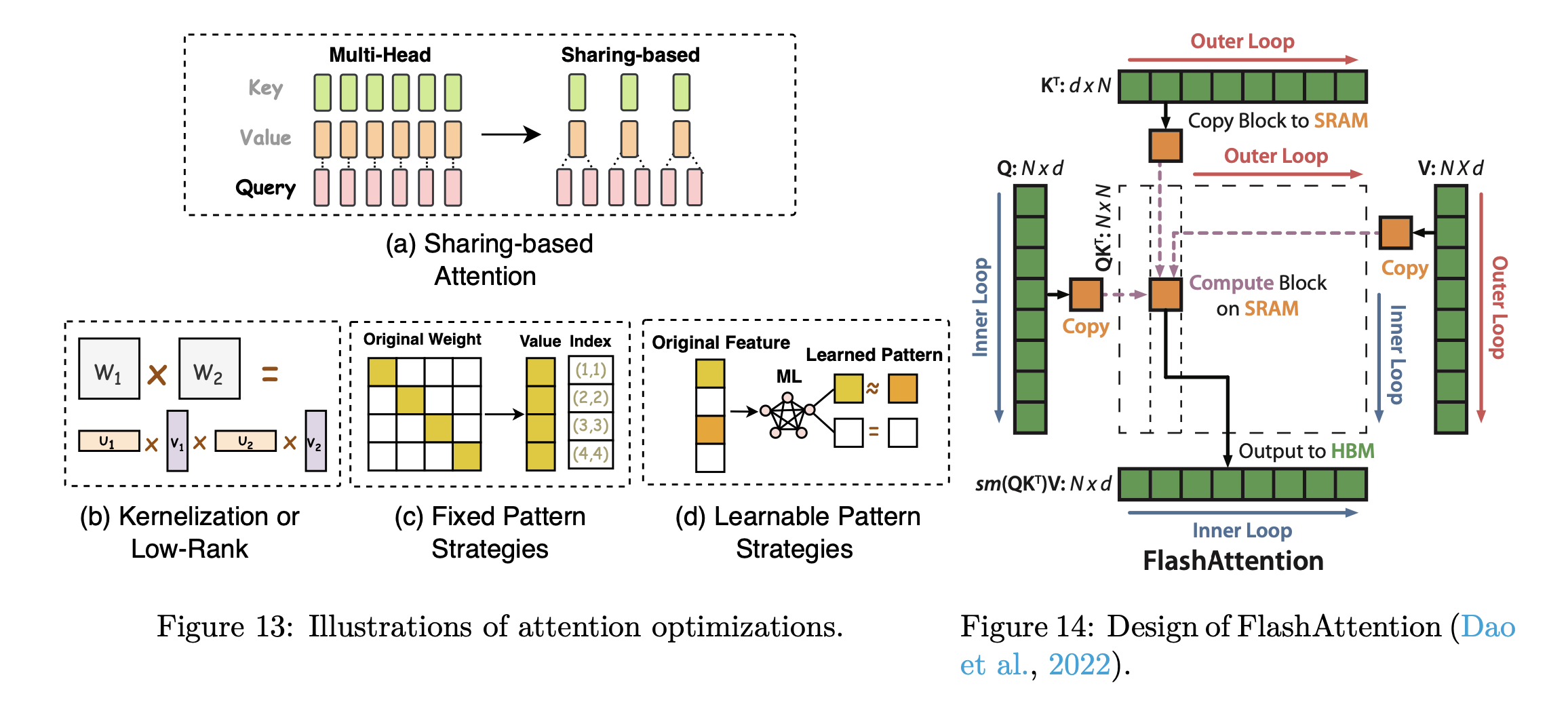
< Summary with Figure : 이해를 돕기 위한! >
2.5.2 Mixture of Experts (MoE)
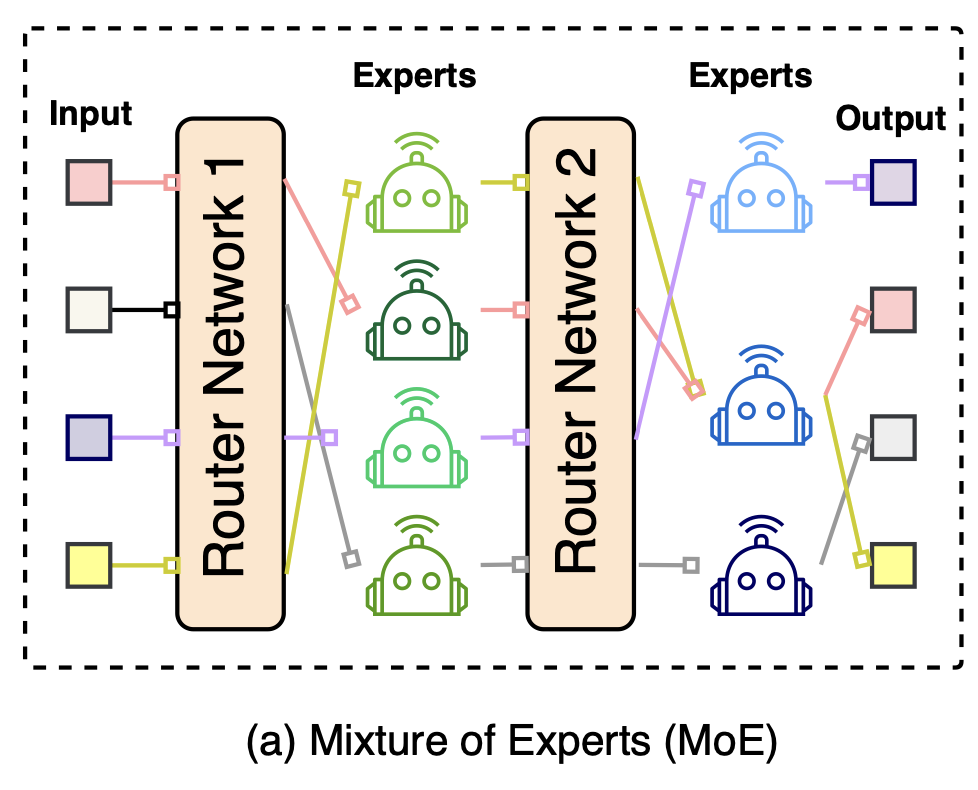
설명
1. FFN layer 개조 → FFN을 여러 개 만든다 (각각의 FFN을 expert 라고 한다)
2. Routing system을 만든다.
3. Routing sytem을 통해 각 토큰이 expert에 분배된다.
4. 그렇게 각 토큰은 자신에게 할당된 expert를 통해 forward, backward 진행
의의
Experts의 수를 늘림에 따라 모델의 크기는 커진다 → 모델의 크기가 커짐에 따라 성능 향상 (Scaling law)
하지만 forward/backward 시에는 모델의 모든 parameter를 사용는 것이 아니니(각 토큰은 해당 expert만 사용), 모델의 규모가 커졌지만 이에 따라 지연되는 시간은 미미하다
즉, 모델의 규모는 키웠지만 속도는 늘어나지 않았음(speed가 느려지지 않음)
- MoE-based LLMs
- GShard
- Switch Transformer
- Mixtral 8x7B
- etc
- Algorithm-Level MoE Optimization
- Expert Choice :
- 기존 방법: 토큰이 top-k개의 experts를 선택하는 방식 vs 방법론: experts가 top-k개의 tokens을 선택
- 이점: experts의 수는 고정되어 있지만, 토큰에 할당되는 experts가 가변적이다. Experts load imbalance 문제 해결
- 나의 의문점:
- AutoRegressive 한 과정 속, expert가 top k개의 토큰을 뽑는 과정을 모르겠음 (각 iteration마다 expert가 할당하는 토큰들이 달라지나…?)
- Top K개의 토큰을 각 Expert가 뽑는다면, 선택되지 않는 토큰이 있을 것인데 이 상황은 어떻게 해결할 수 있을지 궁금함
- 등등 방법론은 더 있음
- Expert Choice :
- System-Level MoE Optimization
- Fast MoE, Faster MoE
- Lina
- Deepspeed MoE
- etc
2.5.3 Long Context LLMs

4개의 카테고리로 분류:
- Extrapolation and interpolation
- Recurrent structure
- Segmentation and sliding window
- Memory-retrieval augmentation.
Extrapolation and interpolation
표준 위치 인코딩 방법론들
- APE(Absolute Positional Embeddings)
- RPE(Relative Positional Embeddings)
- RoPE(Rotary Position Embeddings)
이러한 방법론들은 LLM에서 위치 정보의 통합을 발전시켜 왔지만, 제한된 max_length로 학습시킨 LLM이 추론 중 상당히 긴 시퀀스를 잘 일반화할 수 있다고 보장하긴 어렵다 → Extrapolation & Interpolation 제안
- Positional Extrapolation
- 설명: 학습 때 배운 길이 이상으로 위치 정보 인코딩을 확장
- ex) ALiBi, CLEX, etc
- Positional Interpolation
- 설명: 문장의 길이가 길어지면, 해당 위치 인덱스를 줄여버려서 긴 텍스트 효용성을 높인다 (길이가 1024인 문장이 있으면 인덱스를 [1, 2, …, 1024]으로 두는게 아니라, [1/2, 1, …, 512] 이런식으로 위치 인덱스의 범위를 줄여 학습 시에 사용했던 max_length에 맞춰주는 방법)
- ex) YaRN interpolation, FIRE, PoSE, etc.
Recurrent structure
반복 구조를 통해 long sequence를 관리하는 능력 향상
e.g., Transformer-XL, Memformer, etc.
Segmentation and Sliding Window
‘입력 데이터를 더 작은 부분(segments)으로 나누기(=segmentation)’ or ‘움직이는 window를 적용하여 긴 시퀀스 슬라이딩’ ⇒ long-context 처리!
e.g., Mistral(sliding window attention), StreamingLLM(attention sink 현상: 시퀀스 처음 부분의 KV를 보유하고 있는 것이 window attention의 성능을 크게 향상시킨다), MemWalker, RAPTOR, etc.
Memory-Retrieval Augmentation
목표: 매우 긴 텍스트의 inference 해결
e.g., Memorizing Transformer : 이전의 유사한 컨텍스트 임베딩을 가져오기 위해 KNN lookup을 활용하여 attention context size를 늘려줌 → 모든 context를 attend하지 않고, KNN을 사용해서 연관있는 context만 attend!
e.g., LongMem, Unlimiformer, etc.
여기까지 모델 측면에서 efficient LLM을 확인했다.
큰 틀을 이해할 수 있었다. 이제 여기서 나에게 필요한 부분을 더 찾아봐야겠다.
