paper : https://arxiv.org/abs/2004.04906
Abstract
본 논문에서 dense representation만을 이용해서 retrieval을 실질적으로 구현할 수 있음을 보였다. 여기서 embeddings는 간단한 dual-encoder framework를 사용해 적은 수의 questions과 passages로 학습되었다.
여기서 잠깐 Dual-encoder framework란?
Dual-encoder와 Cross-encoder가 있다.
- Dual-encoder
유사도를 측정할 때 question과 passage를 각각 dense representation으로 만든 후, 유사도를 평가한다. 두 개의 encoder 사용 (question을 위한 encoder, passage를 위한 encoder)
즉, QuestionEncoder(question) = question_dense_representation
PassageEncoder(passage) = passage_dense_representation
를 계산해서, question과 passage의 유사도를 평가.
ex) If 유사도 평가 방법 = 코사인 유사도
question_dense_representation과 passage_dense_representation의 코사인 유사도를 이용해 question과 passage의 유사도를 측정해주는 방법
- Cross-encoder
Question과 Passage를 “하나의 encoder”에 넣고, 유사도를 평가한다.
[SEP] 토큰을 이용해 Question과 Passage를 구분해주고, [CLS] 토큰을 이용해 question과 passage의 유사도를 평가한다.
1. Introduction
기존의 QA는 복잡하고 여러 구성 요소로 이루어지지만, 독해 모델의 발전으로 훨씬 단순해진 2단계 프레임을 제시한다:
- Retriever : 답을 포함하고 있는 passage들을 몇 개 뽑아오는 역할
- Reader : retreiver가 뽑아온 passage를 context로 답을 냄
ODQA를 machine reading으로 줄이는 것은 매우 합리적인 전략이지만, 실제로는 엄청난 기술 저하가 종종 발견되고 이는 retrieval 개선의 필요성을 나타낸다.
ODQA에서 retrieval은 대게 TF-IDF or BM25를 통해서 구현되었다. 이는 keywords를 효율적으로 inverted index와 매치시키고 높은 차원의 sparse vectors(with weighting)로 question과 context를 표현하는 것으로 볼 수 있다. 반대로 dense representation은 sparse representation과 상호보완적이다. Dense retrieval system은 같은 의미를 다르게 표현하는 것을 잡아낼 수 있고, dense encoding은 task-specific representation을 가지기 위해 추가적인 유연성을 제공하는 embedding functions를 조정함으로써 학습될 수 있다. Special in-memory data structure과 indexing schemes를 이용하여, Maximum Inner Product Search(MIP) 알고리즘을 사용하여 retrieval이 효율적으로 수행될 수 있다.
하지만 좋은 dense vector representation을 학습시키기 위해선 많은 question - contexts 쌍이 필요하다고 여겨졌다. 따라서 dense retrieval 방법은 ORQA 이전에 ODQA에 대해 TF-IDF/BM25를 절대 능가할 수 없었다. ORQA ⇒ 추가적인 pretraining을 위해, masked된 문장을 포함하는 블록들을 예측하는 정교한 inverse cloze task(ICT) 목표를 제안.
Inverse Cloze Task, ICT 추가 설명
출처 : ”Latent Retrieval for Weakly Supervised Open Domain Question Answering” 논문
설명하면, 원래 cloze task는 [mask]를 예측하는 것.
하지만 inverse cloze task는 [mask]가 자신이 있어야 할 문단을 예측하는 것!
즉, 이 예시에서 볼 수 있는 것은 원래의 문장은 “~~ Zebras have four gatis: walks, trots, canter and gallop. They are generally slower than horses, but their great stamina helps them outrun predators. When chased, a zebra will zig-zag from side to side ~~” 이다. 근데 여기서 “They are generally slower than horses, but their great stamina helps them outrun predators.” 이 문장이 빠진 block이 0번째에 있고, 해당 query가 어느 문단에 들어가는 것이 적절한지 예측하는 task!
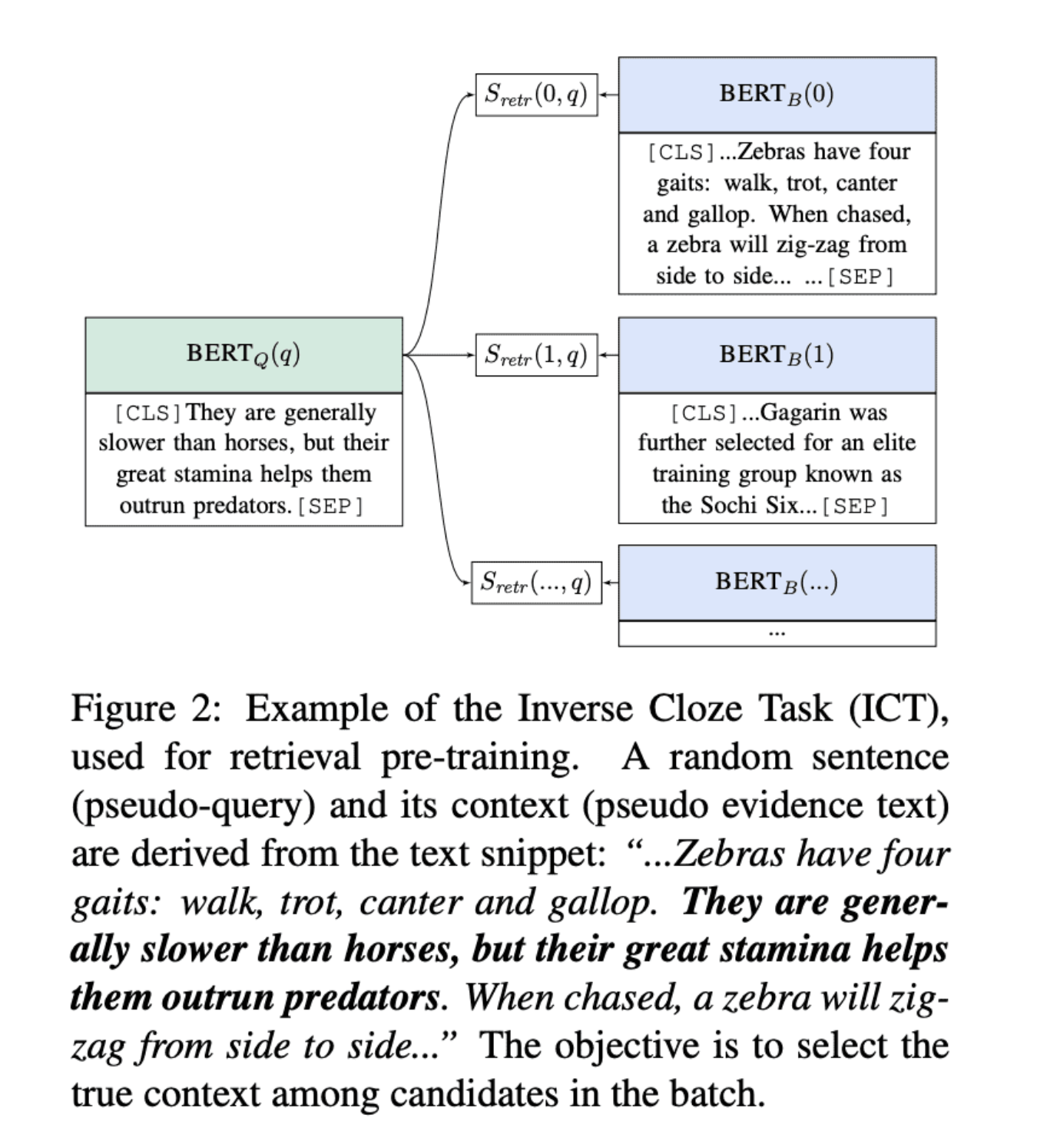
Question encoder와 reader model은 questions - answers 쌍을 이용해서 함께 fine-tuning된다. Dense retrieval가 BM25를 능가할 수 있다는 것을 ORQA가 성공적으로 입증하여 여러 ODQA 데이터셋에 대해 새로운 SOTA 결과를 설정했음에도, ORQA 또한 2가지 약점이있다.
- ICT pretraining이 계산량이 많이 들고, objective function에서 일반적인 문장들이 questions의 좋은 대용인지 확실하지 않다.
- Context encoder가 questions-answers 쌍을 이용해 fine-tuning되지 않기 때문에, 해당하는 표현이 최선이 아닐 수 있다.
본 논문에서는 “추가적인 pretraining 없이 오직 questions - passages(or answers)쌍만을 이용해서 더 나은 dense embedding model을 학습시킬 수 있을까?" 라는 질문을 해결한다.
현재 기본 BERT pretrained model과 dual-encoder 구조를 활용하여, 비교적 적은 수의 question-passage 쌍을 사용해 올바른 훈련 체계를 발전시키는데 집중한다.
최종적인 솔루션은 놀랍게도 간단하다 : 모든 questions와 passages 쌍을 하나의 배치에서 비교하는 목적을 이용해, question vectors와 연관있는 passage vectors의 내적을 최대화하여 embedding 을 최적화한다.
우리의 기여들은 이중이다.
- 적절한 훈련 셋업을 이용해, 간단히 기존의 question-passage쌍에 대한 question & passage encoders를 fine-tuning 하는 것이 BM25를 크게 능가하기에 충분하다는 것을 보여주었다. 우리의 경험적 결과들은 추가적인 pretraining이 필요하지 않을 수 있음을 시사한다.
- ODQA에서 높은 retrieval 정확도는 높은 end-to-end QA 정확도로 해석할 수 있음을 확인한다.
⇒ Retrieval 정확도 ↑ → 전체 QA 정확도(end-to-end)
최신의 reader model을 retrieved된 상위 문서에 적용함으로써, 여러 훨씬 복잡한 시스템들과 비교해 Open-retrieval setting에서 다수의 QA 데이터셋에 대해 유사하거나 더 나은 결과를 달성했다.
2. Background
다양한 도메인을 커버하기 위해서는 여러 다양한 문서들을 다뤄야하고, 그렇기에 다양한 문서 속 연관이 되는 문서들을 적은 수로 잘 골라오는 retriever가 필요하다.
3. Dense Passage Retriever (DPR)
ODQA에서 retrieval 부분의 개선에 초점을 둔다. 주어진 M개의 text 문단들이 주어졌을 때, DPR의 목적은 실행 중에 입력 question과 연관이 있는 상위 k개의 문단들을 retrieve할 수 있게 하기 위해, 모든 문단들을 연속적인 낮은 차원(low-dimensional and continuous space)으로 인덱싱하는 것이다. M은 매우 커질 수 있고(e.g., section 4.1에서 설명된 실험에서는 21 million passages), k는 대게 작은 수(20-100과 같이)이다.
3.1 Overview
Dense Encoder : passage를 차원의 실수 벡터로 연결시키고, retrieval에 이용되기 위해 M개의 passages를 indexing한다.
실행 중에 DPR은 입력 question을 차원 벡터로 연결시키는 다른 encoder 를 적용하고, question 벡터와 가장 유사한 벡터를 가지고 있는 k개의 passages를 retrieve한다.
Question과 passage의 유사도는 해당 vector들의 dot product를 사용해서 정의한다:
Eq(1)
question과 passage의 유사도를 측정하는 더 표현적인 형태가 있을 수 있지만, 유사도 함수는 Passage들의 representation이 미리 계산될 수 있게 분해가능(decomposable)해야한다. ⇒ Query가 올 때마다 passage들의 Representation을 다시 계산해주는 것이 아니라, passage representation을 미리 계산해놓고 query가 올 때마다 비교할 수 있게 decomposable 해야한다.
대부분의 분해 가능한 유사도 함수는 유클리드 거리(L2)의 일부 변형이다. Inner product(내적) search와 코사인 유사도, L2 거리의 연관성이 연구 되고 사용되었을 뿐만 아니라, Inner product search 자체도 널리 사용되고 연구되어 왔다. 다른 유사도 함수들도 유사하게 수행되는 것을 발견했기에(Section 5.2; Appendix B), 우리는 더 간단한 inner product function을 선택하고 더 나은 encoders를 학습함으로써 dense passage retriever를 개선한다.
Encoders
원칙적으로는 question encoder, passage encoder는 어느 neural networks를 이용해서라도 구현될 수 있지만, 여기서는 두 개의 독립적인 BERT networks(base, uncased)를 사용한다. 그리고 출력으로써 [CLS] 토큰의 representation을 사용하므로, d = 768 이다.
Inference
Inference 중에, 모든 passages에 passage encoder 를 적용하고, FAISS를 이용해 indexing한다. FAISS는 billions의 벡터들에 쉽게 적용할 수 있는, dense 벡터의 유사성 검색과 clustering을 위한 매우 효율적인 open-source 라이브러리다. 런타임에 question q가 주어지면, q의 embedding인 를 도출하고 에 가장 가까운 embedding을 가진 상위 k개의 passages를 retrieve한다.
3.2 Training
Dot-product 유사도(Eq. 1)가 retrieval을 위한 좋은 ranking 함수가 되게 하기 위해 encoders를 훈련하는 것은 본질적으로 metric 학습 문제이다. 목표는 더 나은 embedding 함수를 배움으로써, 유관한(relevant) questions-passages 쌍이 무관한(irrelevant) questions-passages 쌍보다 더 작은 거리를 가지게 될 vector space를 만드는 것이다.
이 m개의 예시들로 구성된 훈련 데이터라고 해보자. 각 예시는 n개의 무관한 (negative) passages 과 함께, 1개의 question 와 1 개의 관련된(positive) passage 을 포함한다. 다음과 같이 Positive passage의 negative log likelihood로 loss function을 최적화한다:
Positive and negative passages
Retrieval 문제에서 positive examples들은 명백히 이용가능하지만, negative examples는 매우 큰 풀에서 선택될 필요가 있는 경우가 종종 있다. 예를 들어, question에 연관된(relevant) 문단들은 QA 데이터세에서 주어질 수 있거나 답을 이용해서 찾을 수 있다. 명백히 특정되진 않았지만, collection 안의 다른 모든 문단들은 기본적으로 무관하다(irrelevant)고 보여질 수 있다(→ 즉, 기본적으로 positive가 하나 있으면 나머지 문단들은 negative passages라고 볼 수 있다). 실제로 부정적인 예들을 선택하는 방법은 종종 간과되는데, 높은 퀄리티의 encoder를 학습시키는데 결정적일 수 있다. 3가지 다른 유형의 negatives를 고려한다:
- Random : 말뭉치로부터의 아무 random passage
- BM25 : 답을 가지고 있진 않지만 대부분의 question 토큰들에 일치하는, BM25에 의해 반환되는 상위 passages
- Gold : Training set에 나타난 다른 questions과 쌍을 이루는 positive passages
Negative passages의 다른 유형에 대한 영향과 훈련 체계를 section 5.2에서 다룰 것이다. 우리의 베스트 모델은 “같은 mini-batch에서의 gold passages”와 “BM25 negative passage 1개”를 이용한다. 특히, 같은 배치의 gold passages를 재사용하는 것은 좋은 성능을 달성하면서 계산도 효율적이게 만들 수 있다. 이 방법을 아래에서 다룬다.
In-batch negatives
하나의 mini-batch에 B개의 questions를 가지고 있고, 각각은 관련된 passage에 연관되어(associated) 있다고 가정하자. 와 가 크기가 B인 하나의 배치에서 question embedding과 passage embedding의 matrix라고 하자. 는 유사도 점수의 (B x B) matrix이다. 여기서 각 row는 하나의 질문에 해당하며, B개의 passages과 쌍을 이룬다. 이 방법으로 계산을 재사용하고, 각 배치안의 question/passage 쌍들 에 대해 효과적으로 훈련한다. 인 어느 쌍은 positive example이고, 그렇지 않은 것들은 negative이다. 이는 각 batch에서 각 question에 대해 B-1개의 negative passages가 있는 B개의 training 예시를 만든다.
In-batch negative의 트릭은 full batch setting에서 사용되었으며, 최근에는 mini-batch에서 사용되었다. 이는 훈련 예제 수를 증가시키는 dual-encoder 모델을 학습시키데 효과적인 전략인 것으로 나타났다.
5. Experiments : Passage Retrieval
DPR과 Sparse Retrieval 방법과의 차이를 보고, 서로 다른 훈련 체계와 런타임 효율성의 효과에 대한 분석
DPR main은 in-batch negative setting with batch 128 + one additional BM25 negative passage per question.
Question/Passage encoder 훈련 : 작은 데이터셋 100 epoch vs 큰 데이터셋 40 epoch
Retriever를 각 데이터셋에 잘 적응시키는 유연성을 가지는 것도 좋지만, 전반적으로 잘 작동하는 하나의 retriever를 얻는 것도 좋다. 이를 위해서 SQuAD를 제외한 모든 데이터셋으로부터 훈련 데이터셋을 다 합침으로써 multi-dataset encoder를 훈련한다.
DPR에 더해, DPR과 BM25 점수를 모두 이용하는 방법도 제안(각각의 점수를 Linear Combination시켜서 reranking). ex)
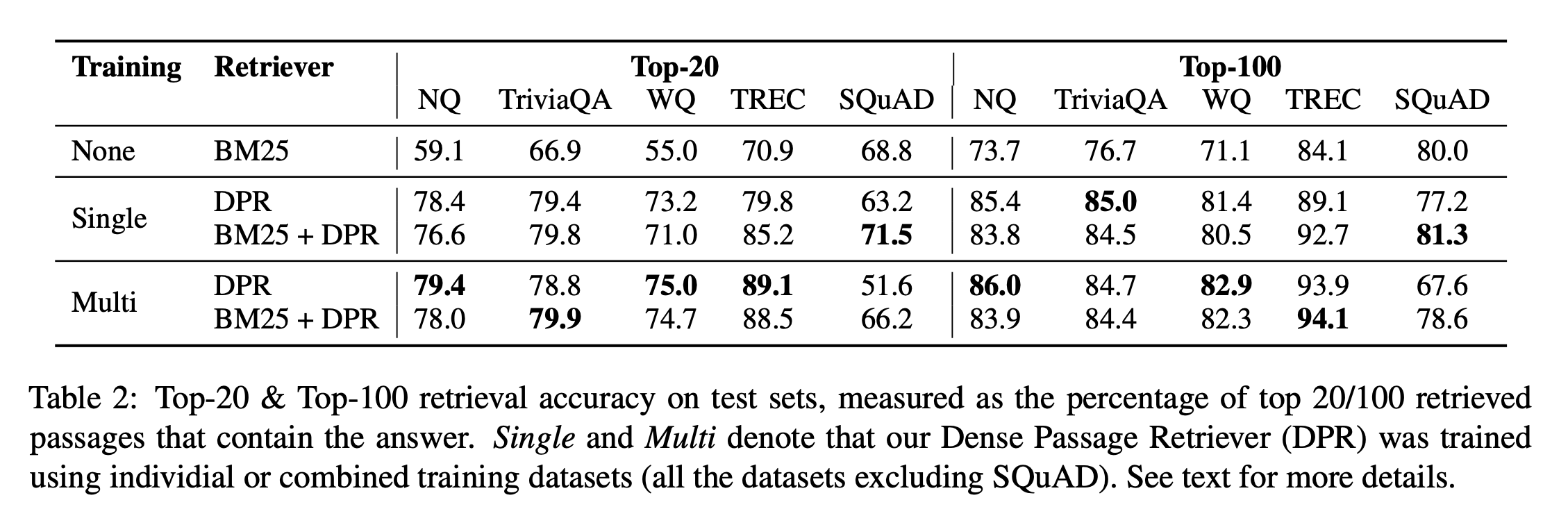
5.1 Main Results
5.2 Ablation Study on Model Training
모델 훈련 선택이 얼마나 결과에 어떤 영향을 주는지 이해하기 위해 몇몇 추가 실험을 수행하고 아래 결과에 대해 논의한다.
Sample efficiency
좋은 passage retrieval 성능을 달성하기 위해 몇 개의 training examples가 필요할지에 대해 연구한다.
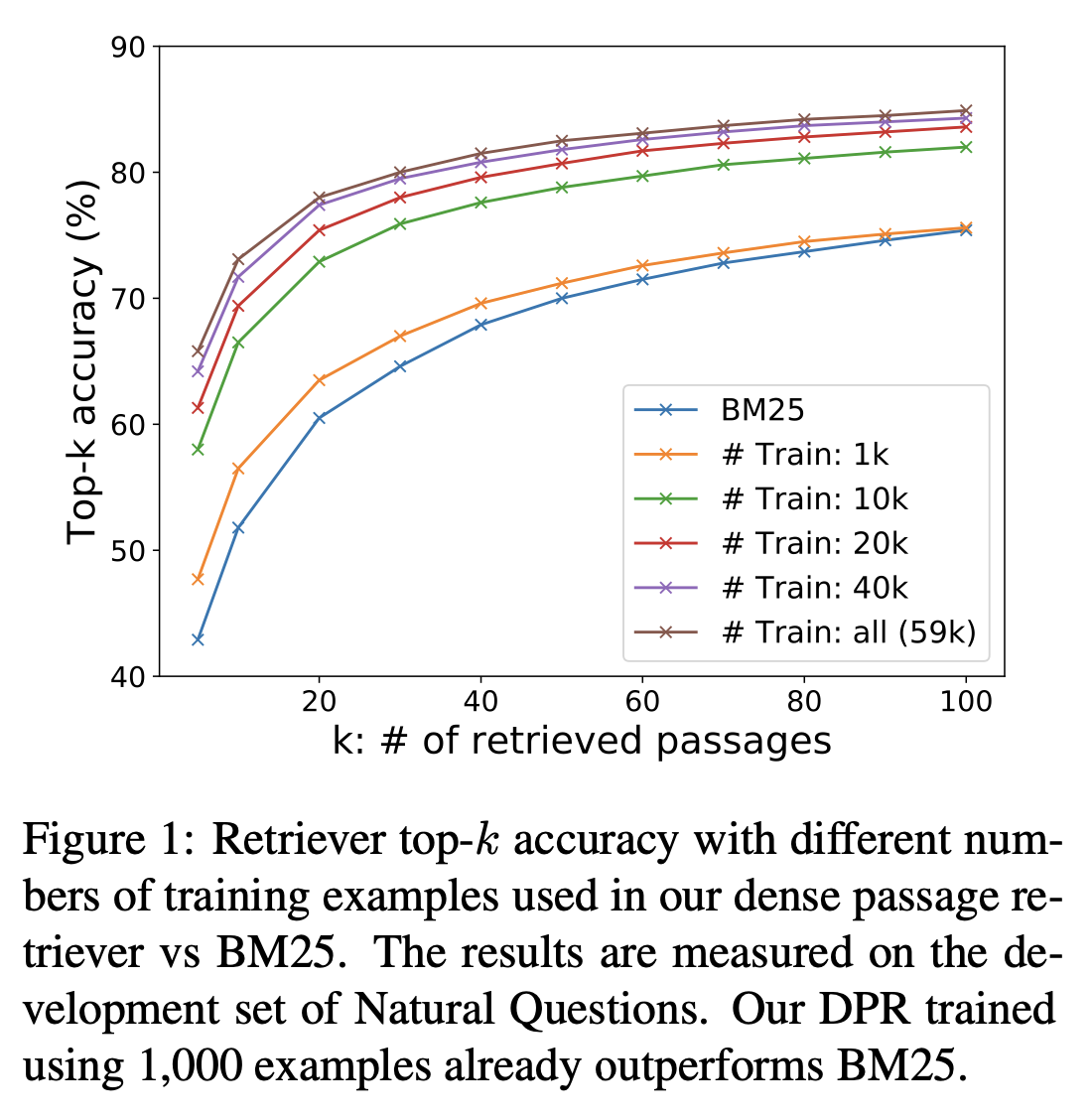
Figure 1은 development set of Natural Questions에 대해 측정된 다른 training examples 수에 따른 top-k retrieval accuracy를 보여준다.
오직 1000개의 examples를 사용해도 BM25의 성능을 능가하는 것을 보아, 작은 수의 question-passage 쌍을 가지고 높은 퀄리티의 dense retriever를 훈련할 수 있음을 확인할 수 있다. 그리고 훈련 examples를 더 추가할수록 retrieval accuracy가 계속해서 향상된다.
In-batch negative training
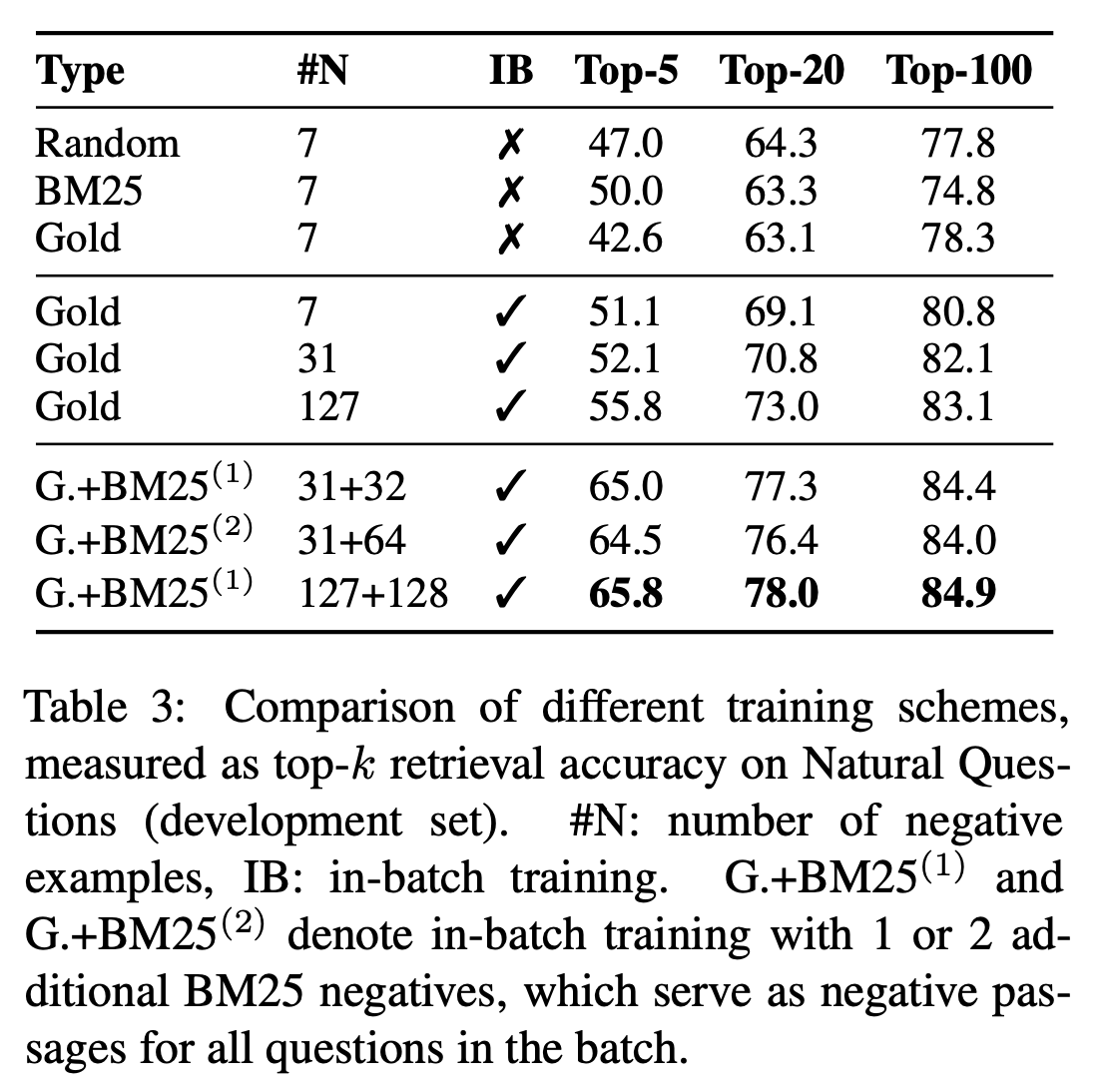
상위 블록은 배치 안의 각 문제가 하나의 positive passage와 n개의 negative passages의 집합의 쌍으로 이루어져있는 1-of-N training setting이다 Eq(2). Negative passages를 고르는 방법(Random or BM25 or Gold Passages)을 고르는 것은 k가 20 이상일 때는, top-k 정확도에 크게 영향을 주지 않는다.
중간 블록은 in-batch negative training setting이다. 유사한 구성을 이용할 때(7 gold negative passages), in-batch negative training이 결과를 상당히 개선시키는 것을 발견한다. 주요 차이점은 negative passage를 같은 배치에서 가지고 오는지 전체 훈련 세트에서 가지고 오는지이다. in-batch negative training은 배치 안에서 negative examples를 재사용해서 새로운 것을 만드는 것보다 쉽고,메모리 효율적이다. In-batch negatives training은 더 많은 쌍을 생성하고 training examples의 수를 늘려주고, 이는 좋은 모델 성능에 기여할 수 있다. 결과적으로 정확도는 배치 크기가 커짐에따라 지속적으로 증가한다.
마지막으로 아래 블록 : in-batch negative training + hard negative passages(주어진 question에 대해 높은 BM25 점수를 갖는)
추가적인 passages(high BM25 scores)는 같은 배치에서 모든 questions에 대해 negative passages로 쓰인다. 하나의 BM25 negative passage를 추가하는 것이 BM25 negative passages 2개를 추가하는 것보다 좋은 결과를 낸다는 것을 발견했다.
마지막 블록에 대해서
31 + 32 라고 적힌 것을 보았을 때, in-batch negative로 positive passage 1개와 31개의 negative passages를 가진다고 볼 수 있다(batch 안의 다른 passage들).
그리고 32개의 negative passages은 question 하나당 높은 BM25 score를 가진 하나의 passage를 넣어주니까, 결국 배치에서는 32개의 negative passages가 추가되는 것으로 볼 수 있다.
Impact of gold passages
원래 Positive passages로 쓰이는 것은 original datasets에서의 가장 일치하는 gold contexts였다. Natural Questions에 대한 실험은 distantly-supervised passages로 바꾸는 것이 오직 작은 영향을 미친다는 것을 보였다. Retrieval에 대해 top-k 정확도가 약 1포인트 낮았다.
여기서 distantly-supervised passage는 gold passage로써 answer를 포함하고 있는 가장 높은 순위의 BM25 passage를 이용하는 것이다. Appendix A를 봐보길~
Similarity ans Loss
Dot product 뿐만 아니라, cosine과 유클리디언 L2거리도 흔히 분해가능한 유사도 함수로 쓰인다. 실험해 본 결과, L2가 dot product와 비슷하고 L2와 dot product가 코사인보다 우수한 것을 발견했다.
이와 비슷하게 negative log-likelihood 뿐만 아니라 순위를 매기는 것에 triplet loss도 인기있는 옵션이다.
Triplet loss란? → 각 question에 대해 positive passage과 negative passage를 직접적으로 비교
자세한 것은 Appendix B를 보면 알겠지만, 우리의 실험은 triplet loss를 이용하는 것이 결과에 큰 영향을 미치지 못했음을 보였다.
Cross-dataset generalization
DPR의 차별적 훈련에 대한 흥미로운 질문은 “non-iid setting에서 얼마나 성능 저하가 올까?” 이다. 즉, “추가적인 fine-tuning 없이도 다른 데이터셋에 바로 적용할 때, 일반화가 여전히 잘 될 수 있는가?” 이다. Cross-dataset 일반화를 실험하기 위해서 Natural Questions에만 DPR을 훈련시키고, 더 작은 데이터셋인 WebQuestions & CuratedTREC 데이터셋에 바로 실험했다. DPR은 top-20 retrieval 정확도에서 가장 성능이 좋은 fine-tuning된 모델보다 3-5점 정도 떨어지며, 일반화가 잘 되는 것을 발견했다. BM25보다는 여전히 훨씬 좋다.
WebQuestions/TREC : 69.9/86.3(Cross dataset) vs 75.0/89.1(Best Fine-tuning performance)
BM25 baseline ⇒ 55.0/70.9
5.3 Qualitative Analysis
DPR이 일반적으로 BM25보다 더 좋은 성능을 띄지만, 다음과 같은 2가지 방법들로 retrieved된 passages는 질적으로 다르다. DPR은 어휘적 변화나 의미론적 관계를 더 잘 포착하지만, BM25와 같은 용어 매칭 방법은 매우 선별적인 키워드와 어구에 민감하다. 더 많은 논의는 Appendix C
Conclusion
ODQA에서 Dense Retrieval이 전통적인 sparse retrieval component를 능가할 수 있고, 잠재적으로 대체할 수 있음을 보였다. 간단한 dual-encoder 방법도 잘 수행되도록 만들어질 수 있지만, dense retriever를 성공적으로 훈련시키기 위한 몇몇의 크리티컬한 요소들이 있음(How to select negative passages)을 보였다. 게다가 우리의 경험적인 분석과 ablation studies는 더 복잡한 모델 프레임워크나 유사도 함수가 반드시 추가적인 가치를 제공하는 것은 아님을 나타낸다.
느낀점
확실히 Sparse로는 단어가 같은 의미의 다른 단어로 대체되면 유사한 passage를 찾는 것이 쉽지 않을 것이라 생각했다. 같은 의미 다른 단어를 매치시키기 위해서는 dense retrieval가 좋은 성능을 낼 것이라고 생각했다. 하지만 그렇지 않았던 적도 있다는 것이 신기했다.
그리고 Negative Passages를 고르는 방법으로 retriever를 더 잘 학습시키는 것이 신기했고, gold passage를 이용하면 자연스레 계산도 효율적으로 하고 성능도 잘 나오는 것이 흥미로웠다.
Negative Passage와 Positive Passage를 어떻게 잘 고르면 더욱 retriever를 잘 학습시킬 수 있을 것 같다. 유사해보이는 passage를 Negative Passage에 넣어주어 retriever가 더 민감하게 학습되었으면 좋겠는데, passage를 사람이 선택하기에는 한계가 있으니 어떤 방법이 더 고안될지 궁금해졌다.
<추가>
Experiment를 보고 느낀점은 in-batch negative를 썼을 때 왜 더 좋은 성능이 나오는지 신기했다.
어차피 같은 수의 negatives를 사용하는 것인데 왜 성능이 더 잘나올까?..? 메모리 효율적이거나 계산 효율적인 것은 알겠는데, 성능 또한 오르는 점이 너무 신기했다.
