paper : https://arxiv.org/pdf/2304.01904
@ reasoning
배경
LM은 CoT와 같이 중간 추론(intermediate inference)를 명확히 생성하면서 reasoning task 성능 향상 → 단점: intermediate inference step이 첫 context로부터의 잘못된 추론이 될 수 있고, 잘못된 최종 예측을 야기할 수 있음.
소개
LM이 Reasoning에 자동적인 feedback을 제공하는 Critic model과 상호작용 → 명확히 중간 추론 생성
Critic model은 LM이 intermediate arguments를 반복적으로 개선하는데 사용하는 구조화된 피드백을 제공
Critic model은 비싼 human-in-the-loop data 없이 학습된다 → LM finetuning를 저렴하게 할 수 있다.
더 정교한 inference를 원하면 inference time에 critic model 대신에 사람으로 대체할 수 있다.
여기서 의문점
사람이 inference에 참여한다면, 질문에 대한 답을 굳이 LLM으로 할 필요가 있나? 그냥 바로 사람이 답을 하면 되지 않나?
내가 이해한 바)
질문에 대한 답을 사람이 바로 낼 순 없지만, 추론 과정은 사람이 검증할 수 있는 경우가 있을 수 있다.
사람도 중간 추론 과정은 비교적 쉽고, 최종 답을 출력하는데 비교적 어려움을 느낀다. 그렇기에 최종 답은 낼 수 없지만, 중간 추론 과정에는 도움을 줄 수 있다. 이 상황에서 critic model 대신 사람이 대체될 수 있다고 말하는 것 같다.
문제
NLR(Natural Language Reasoning)을 다음과 같이 쪼갠다:
중간 과정을 넣어주는 것!
다음 세 가지 작업이 (i) 논리적 추론과 (ii) 규범적 추론의 두 가지 유형을 광범위하게 다루고 있기 때문에 의도적으로 이 세 가지 작업을 선택:
- Math Word Problem (MWP) : 문제 x에 대해 이에 유효한 수학식 z(중간 표현)에 매핑한 다음, 답 y에 매핑하는 것이 목표. 이러한 task는 수학적 추론 사용하여 추론을 수행해야 함.
- Synthetic Natural Language Reasoning (sNLR) : synthetic rules 5개 & fact 1개로 구성된 추론 시나리오가 주어졌을 때, 모델이 결론 y를 추론해야 함.
이 task는 모델이 모델이 연역적 추론을 수행하고, closed-world rules & facts를 사용하여 중간 단계 와 결론 를 생성해야 함. - Moral norm and action generation for moral stories (MS) : 상황, 의도, 비도덕적 행동으로 구성된 context 가 주어지면, 도덕적 규범 와 도덕적 행동 를 생성해야 한다.
'도덕적 행동'은 '도덕적 규범'으로부터 장려됨. 이 task는 도덕적 규범을 생성하기 위해 귀납적 추론을 수행해야 하고, 도덕적 행동을 위해 연역적 추론을 수행해야 한다.
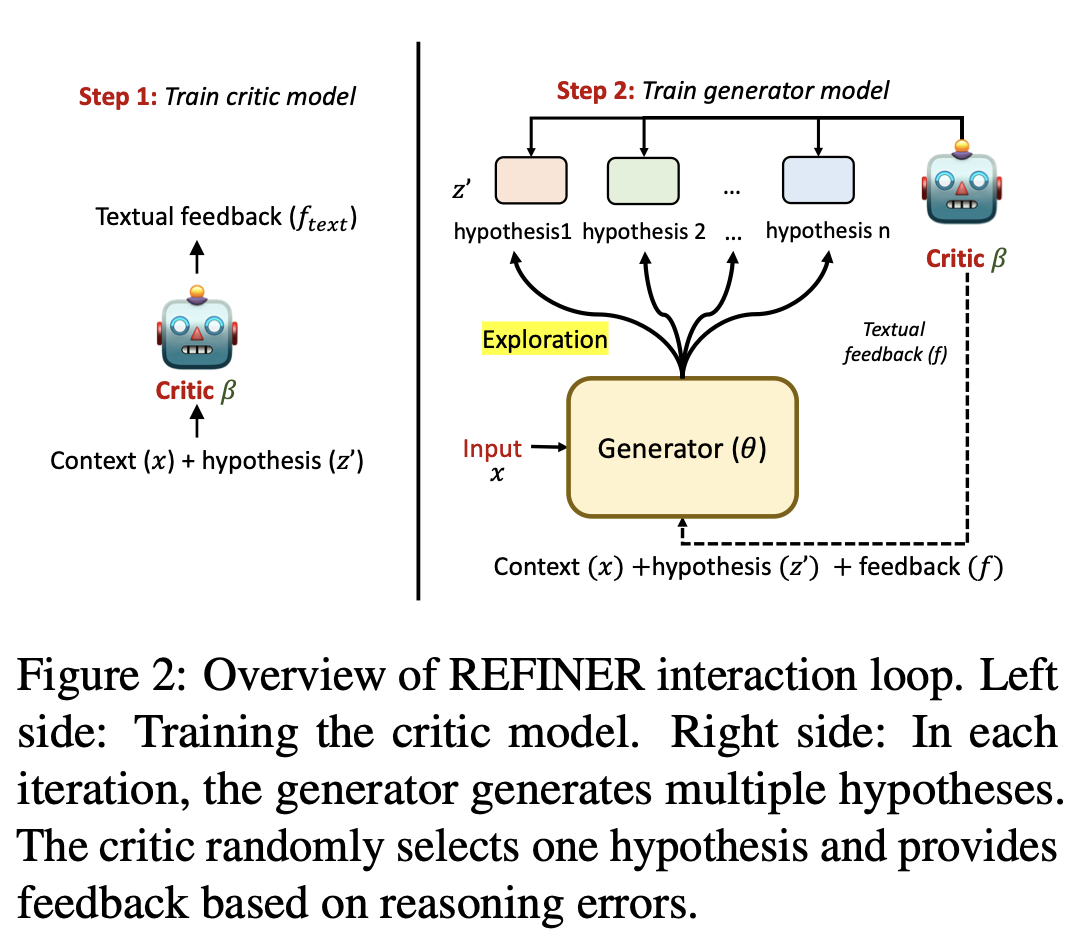
구조
- Critic model : 중간 reasoning step에 대해 구조화된 feedback을 제공하도록 학습됨
- Generator model : 먼저 중간 reasoning step을 생성함으로써 reasoning task를 해결하도록 학습됨
<몇몇 중요한 특성>
- Generator : Feedback을 통합하고 활용하도록 학습됨 → 더 나은 추론으로 수렴하는데 도움을 줌 & test time에 feedback을 통합하도록 함
- 학습된 critic은 그 자체로도 유용할 수 있음 → GPT 3.5와 논문의 critic을 함께 사용하니 좋은 결과를 내는 것을 보였음
- 두 분리된 모델(critic, generator) 사용 → 학습과 추론 동안 Feedback의 이익을 측정할 수 있음
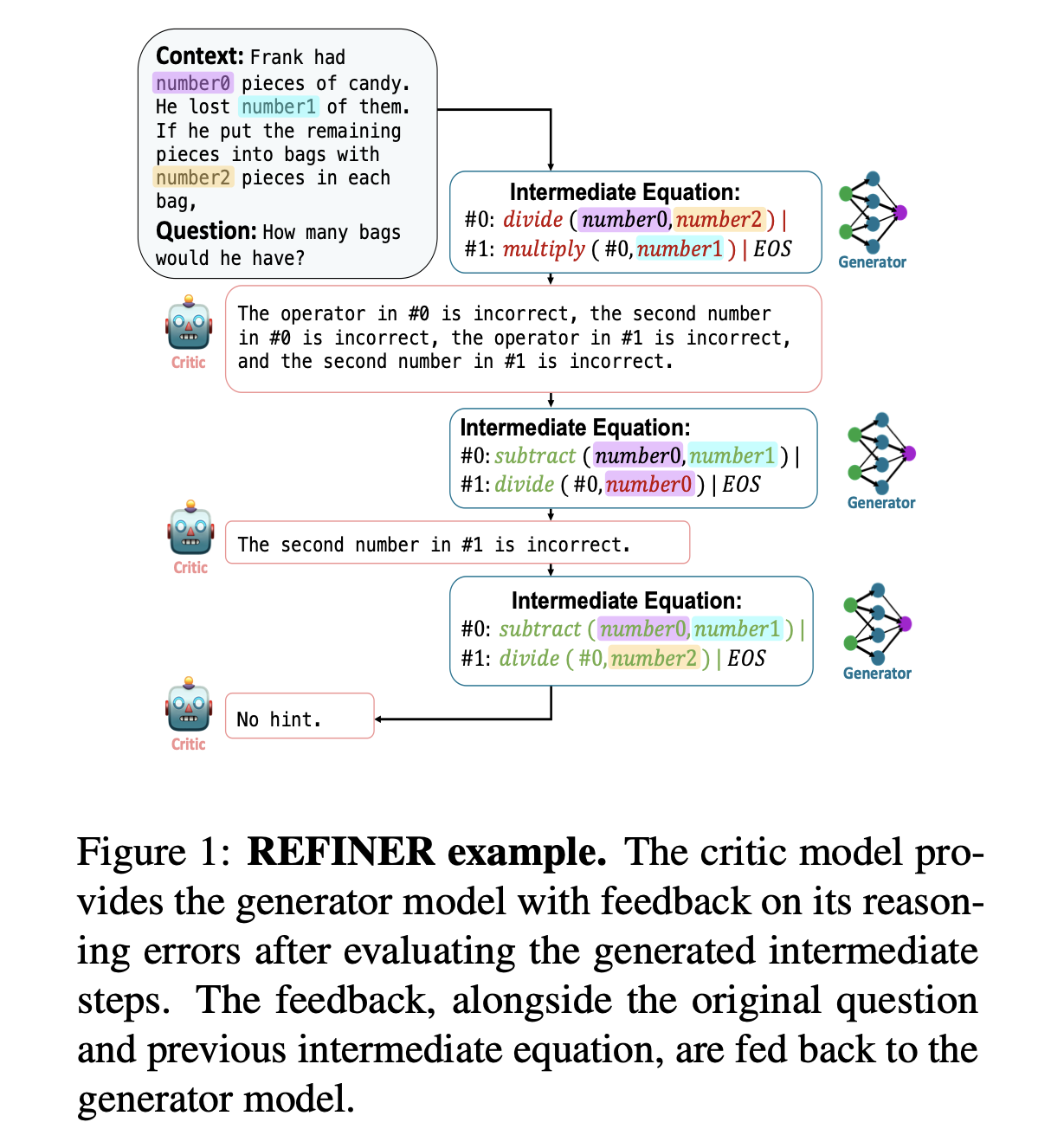
학습
데이터 생성
Feedback data generation
- Rule based perbutation strategy
학습 데이터 내 plausible hypotheses (z)를 혼란시키고, data (: input, : plausible hypothesis, : implausible hypothesis)를 수집
방법: plausible hypothesis에서 생략, 대체, 추가 또는 다른 방법들을 이용해서 자동으로 implausible hypothesis 생성. - Synthetic Generation
OpenAI GPT-3.5에게 error type에 기반해 implausible hypotheses를 자동으로 생성해 달라고 프롬프트.
모든 예제 에 대해 구조화된 feedback 를 생성 ( 에서는 발생하지만, 에서는 발생하지 않는 오류 유형을 명시하며 )
공식적으로 data pool 를 생성

<구조화 된 feedback>
Critic Model
Critic model() 학습 → 입력: context() & hypothesis( or ), 출력: textual feedback
Loss : where
학습된 critic은 inference에만 쓰이고, generator 학습에는 oracle critic이 사용된다
Generator Model
Critic model과 상호작용 하는 것을 반복적으로 학습하는 generator model
Warm-up
주어진 context 에 대해 plausible hypotheses를 생성하기 위해 generator model( 학습
Critic이 loop에 왔을 떄, generator가 안좋아 보이는 랜덤한 답을 생성하지 않도록 하는데 중요하다.
그래서 학습 데이터의 10%를 사용해서 관심있는 NLR task에 대해 finetuning.
즉, generator가 해당 task에 대한 hypothesis를 생성하도록 학습을 해서 원하는 format 등과 같은 특징을 출력할 수 있도록 학습시킨다.
Exploration
목적: 학습동안 generator가 다양한 feedback을 받으며 → "출력의 분산을 늘림"
방법 :
- 각 iteration에서 generator가 nucleus sampling을 통해 여러 개의 hypotheses()를 생성
- Critic model이 랜덤하게 하나의 hypothesis를 고르고, 해당 hypothesis에 대한 feedback을 제공
여기서 가장 좋은 hypothesis를 고르는 것이 아니라 여러 개의 hypotheses를 생성한 후, 그 중 하나를 랜덤하게 골라서 feedback을 제공하기에 학습에서 다양성이 증가한다.
Learning
다음의 cross-entropy loss로 학습이 됨:
where = total number of iterations
Feedback이 error type과 hint(세분화되고 논리적인)를 가지고 있기 때문에, feedback에서 언급된 추론 오류를 해결하여 모델이 학습하고 생성을 업데이트할 수 있어야 한다.
Inference
학습된 critic과 학습된 generator를 함께 사용하여 궤적 를 생성
Generator에 의해 가 생성되거나 critic에 의해 "No hint"가 생성되면 생성을 멈춘다.
이해가 안되는 부분
<Learning에서>
1. 학습 시, iteration 중에 generator가 잘 생성해서 critic이 'no hint'를 뱉는 경우가 있을 텐데, 이 경우에 대한 stop sign이 없음.
학습 시에는 total iteration을 정해놓으면, 그 중간에 정확한 generation이 생성되어도 멈추지 않는 것인가?
계속해서 generation을 진행하는 것인가?
- 생각의 이유
왜냐면 generator를 학습시키는 과정에서는 oracle critic이 사용되기에 정확한 feedback이 나올 것이기에, 정확한 generation이 나오면 이에 대한 feedback은 'no hint'일 것인데, 이에 대해 계속 학습이 진행될 것인가?
학습이 진행된다면 plausible hypothesis + 'no hint' 이후의 상황을 학습하는 것인데, 이는 inference에서는 나올 수 없는 상황이다. Inference에서는 'no hint'가 나오면 iteration이 멈춰지기 때문이다. 그렇기에 plausible hypothesis + 'no hint' 이후 상황에 대해 학습을 진행하는 것이 유의미한 것인지 모르겠다.
2. Iteration에서 Loss가 어떻게 cross entropy loss로 생성이 되는지 모르겠다.
→ 해결) context에 대해 ground truth 는 하나가 할당되어 있다. 그렇기에 iteration마다 (context, hypothesis, feedback)이 들어갈 때, hypothesis와 feedback이 바뀌었다고 해도 해당 context에 대해 generator가 생성해야 하는 ground truth는 계속 일 것이다. 그렇기에 를 예측하기 위해 Next token prediction에서 loss를 가져오는 것으로 보인다.
<Inference에서>
는 feedback으로 critic이 생성하는 것 같았는데, 위에서 stop signal로 generator가 생성한 를 언급했다. 이 부분은 이해가 되지 않는다.
Stop signal이 critic이 뱉는 'no hint'말고 어떤 것이 더 있는지 궁금하다.
알고리즘으로 표현한 REFINER


알고리즘에서 이해가 안되는 부분
알고리즘1)
1. 6번째 줄에서 critic model의 output으로 이 나오는데, 이게 무엇을 의미하는지 이해가 되지 않음
알고리즘2)
논문의 내용은 이해가 되나 알고리즘으로 표현된 식은 전체적으로 이해가 안됨.. 대신에 를 사용하고 이있는데, 가 어떻게 사용되는지 조금 더 디테일이 있었으면 좋겠다.
느낀점
논문을 읽다보면 수식이 깔끔하지 않다고 많이 느끼는 것 같다.
논문의 흐름을 중심으로 수식을 이해할 수 있어야 하는데, 수식에서 정밀한 표현이 부족하니 나 자신의 이해에 확신을 가지지 못하게 되는 것 같다.
(물론 이 과정에서 내가 수식을 잘못 이해한 것일 수도 있지만..)
수식의 정확한 표현에 집착하지 말고, 논문의 contribution과 해당 contribution에 대한 추가적인 발전 방향 또는 부족한 점이 없는지 생각하며 읽어야 할 것 같다.
그래서 스스로 어떤 ablation study가 진행될 수 있는지 생각하는 것이 필요한 것 같다.
