Paper review[Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference]
논문리뷰
목록 보기
23/29
url: https://arxiv.org/abs/2412.13663
배경)
- BERT와 같은 Encoder model은 Classification, Retrieval에서 좋은 성능을 보인다 → 그러나 BERT 이후, Encoder model의 Pareto 개선은 제한적
- Encoder model의 장점:
- Inference requirements가 적다 → 대량의 문서를 효율적으로 처리하여 retrieval 에 좋음 & discriminative task를 빠르게 수행
- Encoder-Deocder model과 Decoder-only model에 비해 낮은 추론 비용으로, 효율적이면서도 충분히 높은 품질 제공
- Encoder model이 쓰이는 곳
- RAG pipeline 내, retrieval
- Discriminative tasks: classification, NER(Natural Entity Recognition)
- 기존 original BERT의 단점:
- Sequence Length가 512로 제한
- 모델 디자인이 최적이 아님
- Vocabulary size
- Downstream 성능 / 계산 효율성 측면에서 Inefficient Architecture
- 학습 데이터
- 양이 제한적
- 좁은 도메인
- 최근 사건에 대한 지식 부족
의의)
- Moden BERT 제안 :
- ENCODER-only 최적화 모델
- 기존의 모델들 보다 주요 Pareto 개선
- SOTA Results (특히 더 긴 sequence length에 대해)
- Diverse Classification tasks
- Single & Multi-vector retrieval (다양한 domain에서.. 코드 포함)
- Speed & Memory efficient encoder (high inference efficiency)
- 더 큰 학습 데이터 규모: 코드 데이터를 포함한 data mixture(2 trillion tokens에 대해 학습 진행)
- 2가지 모델 제안:
- ModernBERT-base
- ModernBERT-large
방법론)
[Architecture Improvements]
Standard transformers architecture에서 확장
Modern Transformer
- Bias Terms
- Final Decoder linear layer를 제외하고, 모든 linear layer에서 bias term을 제거
- Layer Norms에서도 bias term 제거
- 결과: Linear layer에서 모델 parameter를 더 사용할 수 있게 해줌
- Positional Embeddings
- RoPE(Rotary Positional Embedding) 사용
- 이유: long- & short-context language model에서 입증된 RoPE의 성능을 보고 사용함
- 의의: 효율적인 구현 & context extension의 용이성
- Normalization
- Standard layer normalization을 이용한 Pre-normalization block 사용
- CrammingBERT와 유사하게, Embedding layer 이후 LayerNorm을 추가
- 중복을 피하기 위해 첫 Attention layer 안의 첫 Layer Norm은 제거
- Activation
- GeGLU 사용: Gated-Linear Units(GLU) 기반 activation function
- 이유: GLU 변형을 사용할 때, 일관되게 실험적인 개선을 보였기에
Efficiency Improvements
- Alternating Attention
- Global Attention과 Local Attention을 교대로 사용
- Global Attention: 시퀀스 내 모든 토큰 attending
- Local Attention: Small sliding window 안에서만 서로를 attending
- 디테일:
- 3번째 layer마다 global attention 사용 (RoPE theta=160,000)
- 나머지 layer: 128 tokens을 사용 & local sliding window attention (RoPE theta=10,000)
- Unpadding
- Encoder-only model은 배치 내에서 일정한 길이를 보장하기 위해 일반적으로 padding tokens을 사용 → 의미적으로 비어있는 토큰에 대한 waste computation 진행
- 의의: Padding tokens을 사용하지 않음으로 inefficiency 제거
- 방법:
- Mini-batch 내 모든 시퀀스들을 concatenate 하여, 하나의 sequence로 만듦 → 그리고 배치 크기 1로 처리
- FlashAttention의 가변 길이 attention & RoPE 사용 → 하나의 unpadded sequence에 대해 jagged attention masks & RoPE applications
- Embedding layer 전에 Inputs를 unpadding & (선택적으로) 모델 outputs를 repadding → 다른 unpadding 기법에 비해 10~20% 성능 향상
- 기존 unpadding 구현:
- Unpad & Repad sequence를 서로 다른 layer에서 내부적으로 진행 → 계산 & memory bandwidth 낭비
- FlashAttention
- FlashAttention 3은 Nvidia H100 GPUs에 최적화된 버전 but 아직 sliding window attention을 지원하지 않음
- ModernBERT ⇒ Global Attention Layer에서는 Flash Attention 3 사용 & Local Attention Layer에서는 Flash Attention 2 사용
- torch.compile
- PyTorch의 built-in compiling을 사용해서 학습 효율을 개선 → 10% throughput 개선 + 무시할만한 compilation overhead
Model Design
-
같은 parameters 수를 가질 때, 두 가지 모델 특징이 있다:
- Deep & Narrow) Layer가 많고, hidden dimension이 작은
- Shallow & Wide) Layer가 적고, hidden dimension이 큰
- 두 모델의 학습 패턴 차이: Deep & Narrow model이 downstream tasks에서 더 좋은 성능을 내지만 inference가 더 느림
-
Hardware-aware 모델 design은 대형 모델에서 runtime 성능 향상을 이끌어낼 수 있음
- ModernBERT는 여러 작은 규모의 ablations을 통해 GPU 자원의 최적화를 목표로 설계됨
-
[결과] ModernBERT는 Deep & Narrow 구조를 채택하면서도, inference speed 저하가 크지 않도록 설계됨
-
ModernBERT-base:
- 22 layers
- total # of parameters: 149M
- hidden size 768 with a GLU expansion of 2,304
-
ModernBERT-large:
- 28 layers
- total # of parameters: 395M
- hidden size 1024 with a GLU expansion of 5,248
[Training]
Data
- Mixture
- 2T of tokens ( 주로 영어 데이터이며, 다양한 data source로 부터 옴: web documents, code, scientific literature, etc. )
- Tokenizer
- modern BPE tokenizer: OLMo tokenizer의 개선된 버전 → code 관련된 tasks에 대해 더 좋은 token efficiency and performance
- Original BERT와 동일한 special tokens(e.g., [CLS], [SEP]) & templating 사용 → 이전 버전과 호환성 유지
- 최적의 GPU 활용을 위해 64의 배수인 50,368로 설정 & Downstream applications를 지원하기 위해 83개의 사용하지 않는 토큰 포함
- Sequence Packing
- Unpadding으로 인해 미니배치 크기 내에서 높은 Minibatch-size 분산을 피하기 위해, greedy algorithm을 사용한 sequence packing 채택(shortest-pack-first histogram-packing; SPFHP) → 99% 이상의 sequence packing 효율성을 달성 & 배치 크기의 균일성 보장
- SPFHP 설명)
- bin 기반 긴 시퀀스부터 작은 시퀀스로 sorting
- 긴 시퀀스부터 시작해서 작은 시퀀스로 진행하며, 가장 남은 부분이 많은 시퀀스에 현재 시퀀스를 붙여줌(packing)
- 이렇게 packing 진행
- visualization: https://share.vidyard.com/watch/r2nX2Ddfx3Mbp1sHPuyFb7 (출처: graphcore blog)
- 내가 이해한 바) 미니 배치 내의 시퀀스를 이어 붙여서 하나의 시퀀스를 만들어주는데, 미니 배치를 랜덤하게 하면 미니배치 길이의 분산이 클 수 있음 ex) minibatch1: [길이2, 길이3, 길이4] → (unpadding) → [길이9] / minibatch2: [길이5, 길이10, 길이3] → (unpadding) → [길이18] 그래서 unpadding 했을 때, 각 미니 배치의 길이에 대한 분산을 최대한 줄여서 uniform하게 맞추기 위해 진행하는 것 같음
- 이유: 분산이 커지면, 어떤 배치에서는 시퀀스 길이가 매우 짧고 어떤 배치에서는 시퀀스 길이가 매우 길 수 있다 → 시퀀스 길이가 매우 길어지면, 메모리 spike가 올 수 있다. 이를 방지하기 위해 균등하게 만들어 놓는 것이 필요해 보인다!
Training Settings
-
MLM
- NSP objective는 제거 [이유: overhead를 야기하지만, 성능 향상은 없음]
- Masking ratio: 30% (original ratio: 15% → sub-optimal)
-
Optimizer
- StableAdamW
-
Learning rate schedule
- [Pretraining] Warmup-Stable-Decay(WSD): modified trapezoidal(사다리꼴) Learning Rate schedule
- 설명: 짧은 LR warmup(일정 기간 서서히 증가) → 일정하게 유지 → 짧은 LR decay(일정 기간 서서히 감소) & 1 - sqrt LR decay 사용
- 장점: Cosine scheduling 성능과 match & 어느 체크포인트에서나 continual training 가능하다는 장점(cold restart issue 없이)
- ModernBERT-base
- [Warmup] 3B tokens
- [Constant] Constant LR: 8e-4 & Scale: 1.7T tokens
- ModernBERT-large
- [Warmup] 2B tokens
- [Constant] Constant LR: 5e-4 & Scale: 900B tokens
- [Rollback]
- [Constant] Constant LR: 5e-5 & Scale: 800B tokens
- 이유: Large model의 loss가 더이상 감소하지 않고 일정한 값에 머무는 현상이 있어, 학습률을 낮추고 재학습
- [Pretraining] Warmup-Stable-Decay(WSD): modified trapezoidal(사다리꼴) Learning Rate schedule
-
Batch size schedule
- 작은 gradient accumulated batches로 시작해서, full batch size로 증가 → 이러한 schedule이 학습 프로세스를 가속화 시킴 (Uneven token schedule을 사용해서 각 batch size가 같은 수의 update steps를 갖게 함)
- ModernBERT-base: [Warm up] 50B tokens 동안 batch size를 768 → 4,608
- ModernBERT-large: [Warm up] 10B tokens 동안 batch size를 448 → 4,928
-
Weight Initializing and Tiling
- ModernBERT-base: Megatron initialization
- ModernBERT-large: Phi Model family를 따름
-
Context Length Extension
- 1024 sequence length & RoPE of theta 10,000: 1.7T tokens
- 8192 sequence length & RoPE of theta 160,000: 추가적인 300B tokens
- 250B: constant LR 3e-4
- 50B: upsampling high quality sources & decay phase(1 - sqrt LR schedule)
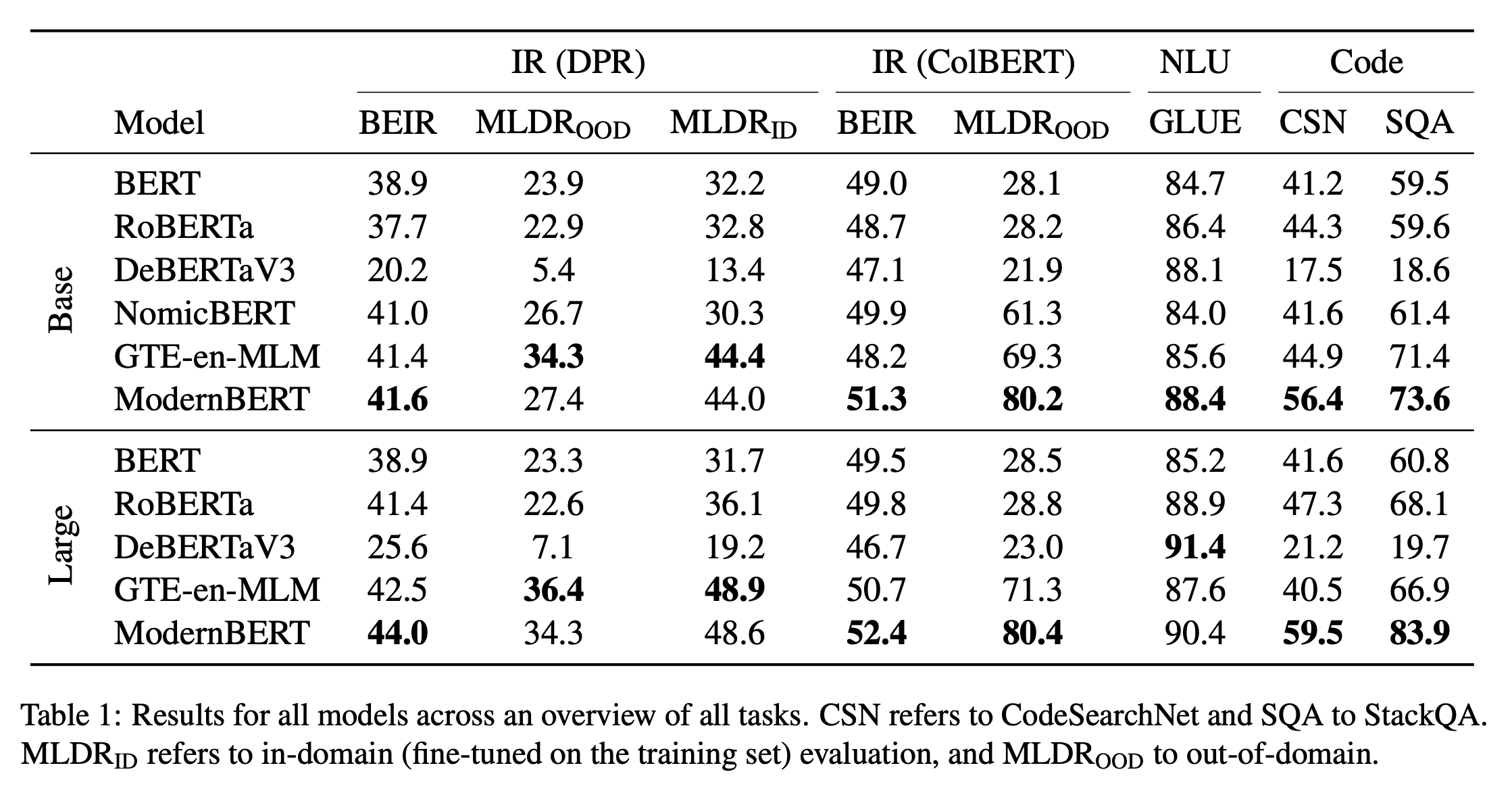
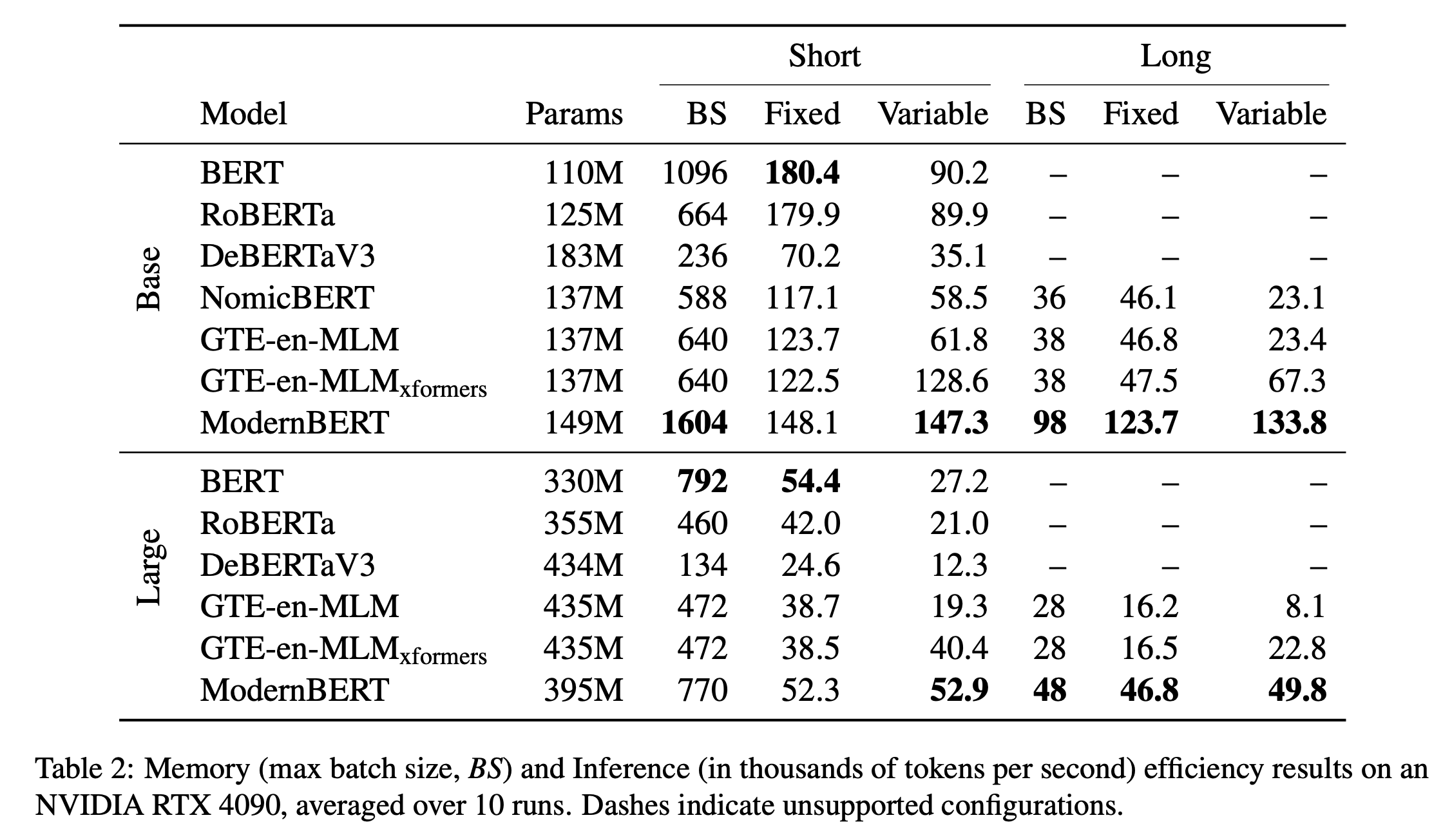
Evaluation(Results)
느낀점)
새로운 encoder model이 나왔다고 해서 살펴봤다.
좋은 성능일 것 같고, layer마다 local attention & global attention을 쓰는 것이 신기했다.
Long Context Embedding을 얼마나 잘 나타내어, RAG에 도움이 될 수 있을지 궁금하다.

수학, AI, CS study 그리고 일상🤗