url: https://arxiv.org/abs/2302.00083
Example of In-context RALM

배경
- 기존 Retrieval-Augmented Language Modeling은 외부 정보를 통합을 용이하게 하기 위해서 LM architecture를 변형시킴 → 이는 배포를 상당히 복잡하게 만듦
- RETRO 논문을 보면, retrieval corpus와 cross attention 하면서 architecture를 바꾼다
의의
- In-context RALM: LM architecture를 변화시키지 않고, grounding documents를 입력 앞에 추가 (추가 LM 학습 없이)
- 기존에 사용되고 있는 retriever를 기반으로 구축되었지만, 모델 크기와 다양한 corpora에 걸쳐 매우 높은 LM 성능 달성
- Document retrieval & ranking mechanism을 RALM(Retrieval-Augmented Language Modeling) setting에 맞춰 specialize 할 수 있음 → 성능 향상을 위해
- In-context RALM이 RALM system을 더 강하게 하는데, 2가지 중요한 role:
- 간단한 reading mechanism
- 기성 LM 과의 호환성 → 광범위한 배포를 촉진하는데 도움
- In-context RALM이 기존의 모델과 다른 2가지 측면:
- Document reading에 기존 LM 사용(LM 추가 학습 X)
- LM 성능 향상을 위해 documents를 선택하는 방법에 초점
Ablation study 목록
아래 조사하면서, In-context RALM의 단순한 setting의 강력한 성능 향상을 보여줌:
- Language Modeling에 가장 적합한 범용 retriever는?
- Retrieval의 작업 빈도는?
- 최적의 쿼리 길이는?
- Perplexity를 향상시키는 2가지 reranking 방법을 통해 기존의 retrieval 성능을 향상시킴
Related Work
- RALM
- 2개의 components로 구성됨
- Document Selection: 특정 조건에 부합하는 documents 집합 선택
- Document Reading: 선택된 documents를 LM 생성 process에 어떻게 통합할지 결정
- 2개의 components로 구성됨
방법
- 일반적인 autoregressive model:
- 일반적인 RALM
- RALM은 를 예측할 때, 사용되는 retrieval operation(외부 corpus 로부터의 operation)은 prefix에 기반함:
- 식:
In-context RALM
배경)
- In-context learning의 성공에 영감
방법)
-
Retrieved documents를 transformer 입력의 prefix 앞에 단순히 concatenate → LM의 weight 를 바꾸지 않음:
여기서 는 string a, b를 concatenate 한다는 의미
-
Transformer 기반 LM은 제한된 context length를 가지고 있음 → input이 제한된 context length를 초과하면?
-
해결 방법: 입력의 시작부분부터 토큰들을 제거 → 전체 입력이 모델의 limited context length가 될 때까지
<코드 참조>
-
Prompt 생성 코드
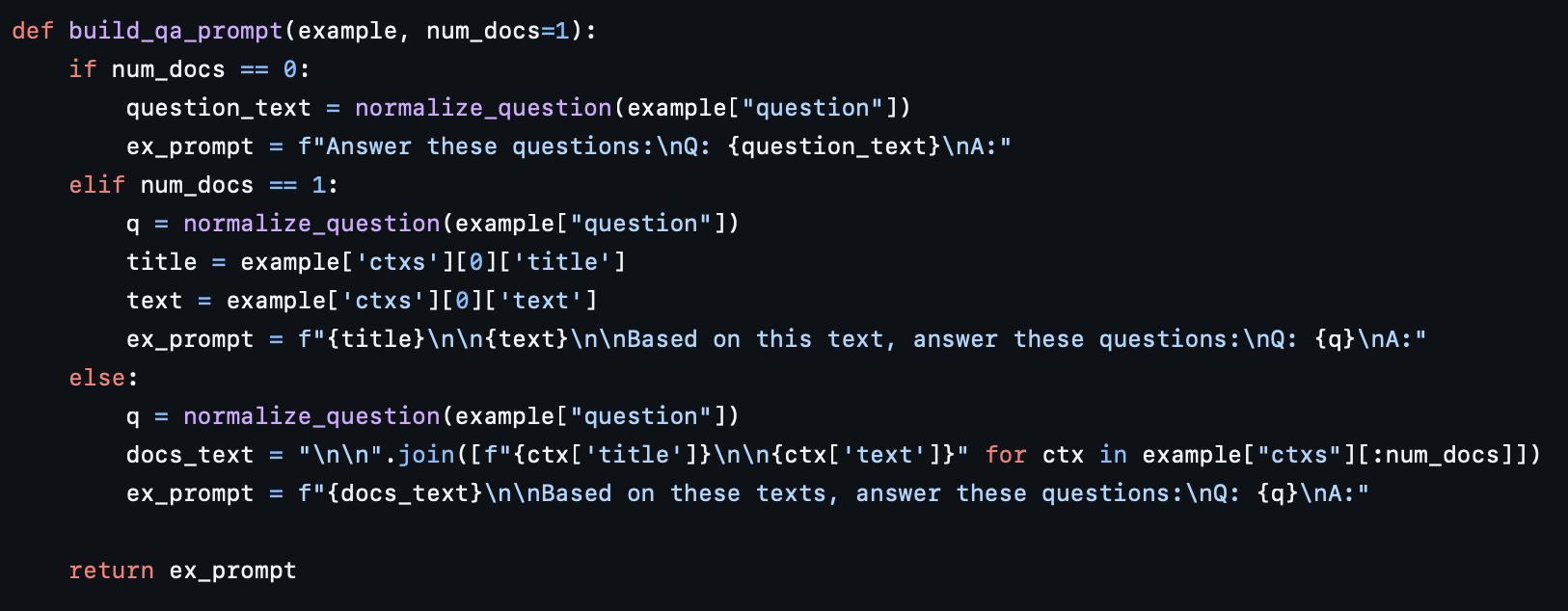
-
모델 입력에 들어가는 input_ids
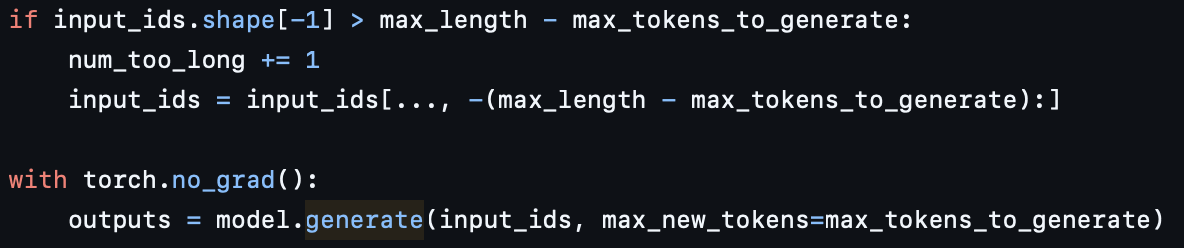
-
-
하지만 retrieved docs의 length가 짧기 때문에, 이렇게 잘리는 경우가 거의 없을 것 (걱정 ㄴㄴ!)
- 이유: passage는 100 words로 구성됨 → 대부분은 150 tokens 보다 작음 → Retrieved passage가 256 토큰으로 truncation 하는데, 대부분 훨씬 작다(100 words로 구성되니까)
-
RALM design choices
Retrieval Stride
- 배경: 토큰마다 retrieval을 하면 retrieval 비용이 너무 많이 듦 / retriever 호출 비용
- 방법: ( > 1)개의 토큰마다 한 번 retrieval을 진행함 / 여기서 “: retrieval stride”
- 이점: 매번 retrieval 할 때보다 비용이 줄어듦
- 식:( : retrieval stride의 수)
- 특징:
- retrieval stride 가 작을수록 더 우수한 성능 → 그러나 시간은 더 오래걸림
- Token마다 retrieval을 진행하는 기존 in-context ralm보다 비용적으로 이득
- Retrieval 횟수가 감소 → runtime 이득
- Stride 구간에서는 KV cache를 사용할 수 있음(기존에는 계속 retrieved docs가 바뀌니 계속 recomputing을 해줘야했지만) → runtime 이득
Retrieval Query Length
- 배경:
- Retrieval query가 너무 길면, 정보가 희석될 수 있다.
- 생성된 토큰은 prefix의 가장 끝 부분과 가장 유사할 것 → Retrieved docs도 prefix의 가장 끝 부분에 연관되면 generation에 좋은 영향을 주지 않을까?
- 방법:
- Retrieval query length 제한: Documents Retrieving에 현재 stride의 특정 부분만 사용함(현재 stride에서 뒤에서 l개)
- 식:(
, = query length)
- 특징:
- 로 설정하면, 성능 감소가 일어남
- 궁금증:
- 이 방법론의 기대 효과가 무엇인지 궁금하다. 효율성인지, 효과성인지.
- 효율성: Docs Retrieving에 짧은 query를 사용하니, 비용적으로 적게 들 것
- 효과성: 정보가 희석될 수 있다고 하더라도, 아예 앞 부분을 없애는 것이 좋은 효과를 가져올 것인가? → 앞 부분의 내용은 input query에 남아 있는 것으로 충분한가? Retrieved docs는 앞 부분의 내용을 가지고 있지 않아도 되는 것인가.. 신기하다
- 이 방법론의 기대 효과가 무엇인지 궁금하다. 효율성인지, 효과성인지.
- 실험:
 <Sparse: BM25>
<Sparse: BM25>  <Dense: BERT>
<Dense: BERT>  <Dense: Contriever>
<Dense: Contriever>
- 결과
- 어떤 retriever를 사용하느냐에 따라 최적의 query length가 달랐다.
- 정말로 retrieved docs의 효과를 볼 때, prefix의 앞 부분이 적당히 없이 retrieving 한 docs를 사용한 generation의 효과가 좋았다.
- Retrieve docs 할 때, 모든 정보를 사용하지 않은 것이 더 좋은 결과를 가져오는 것이 신기..하다
실험
- Models
- Language Models (Maximum Sequence length=1024로 수행)
- GPT-2
- GPT-Neo
- GPT-J
- OPT
- LLaMA
- Retriever
- Sparse
- BM25
- Dense
- frozen BERT-base
- Contriever
- Spider
- Sparse
- Reranking
- RoBERTa-base
- Language Models (Maximum Sequence length=1024로 수행)
LM: GPT-2 & Retrieval: BM25 의 results
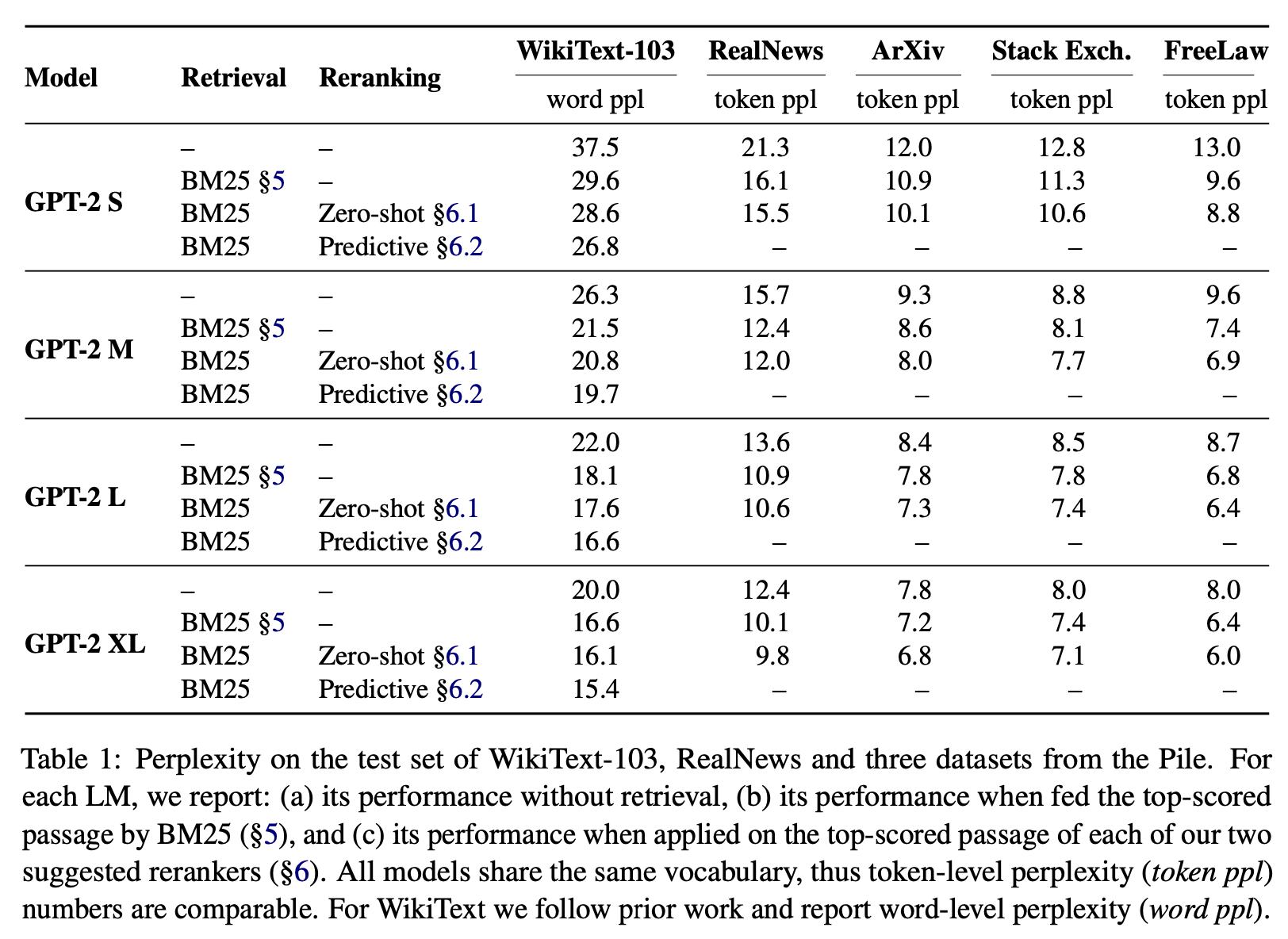
위에서 Reranking 항목 의미:
- Zero-shot: Zero-shot Reranker로 LM 사용
- Predictive: Reranker로 LM을 학습시킨 후, LM을 사용
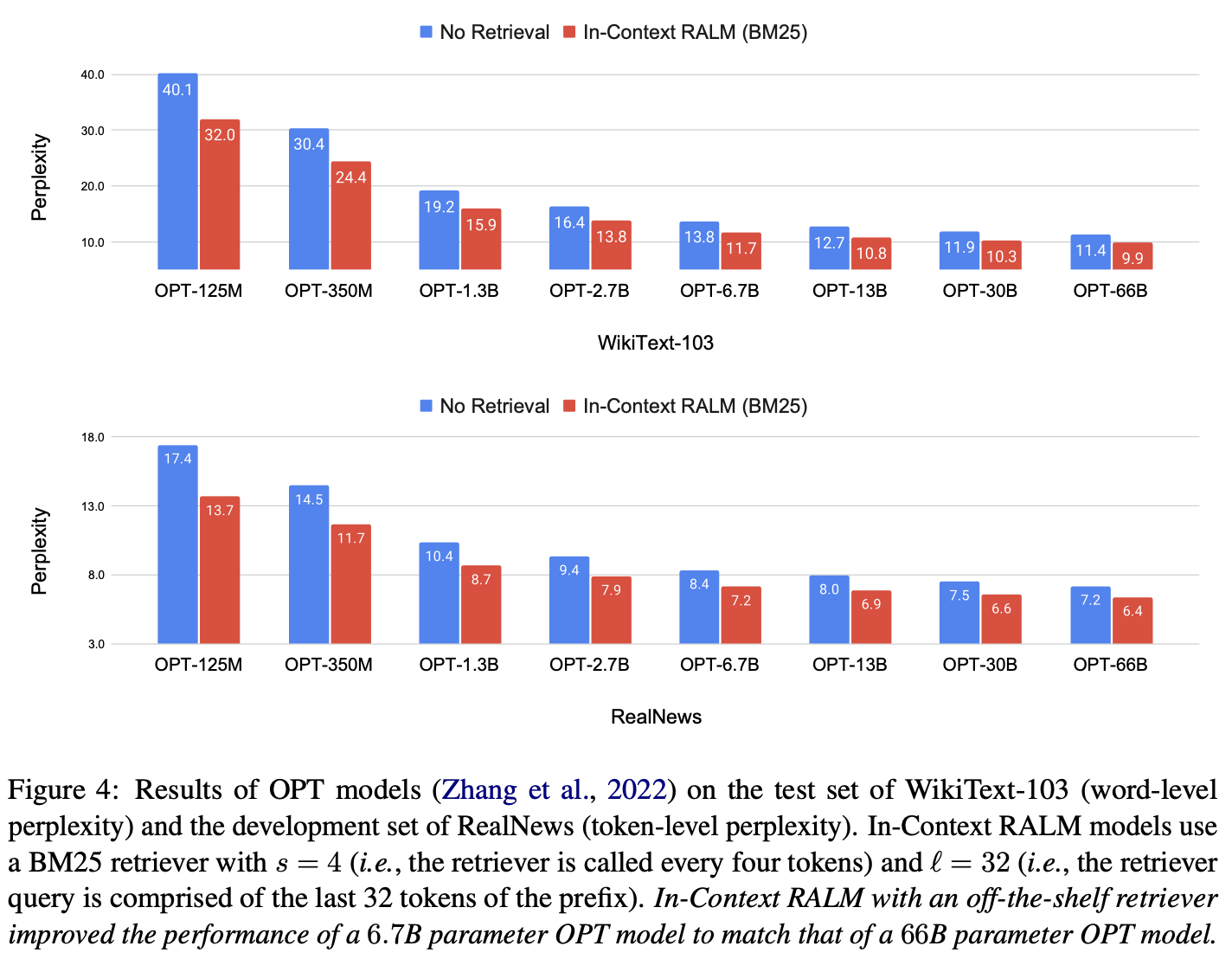
Retrieval Stride Ablation Study
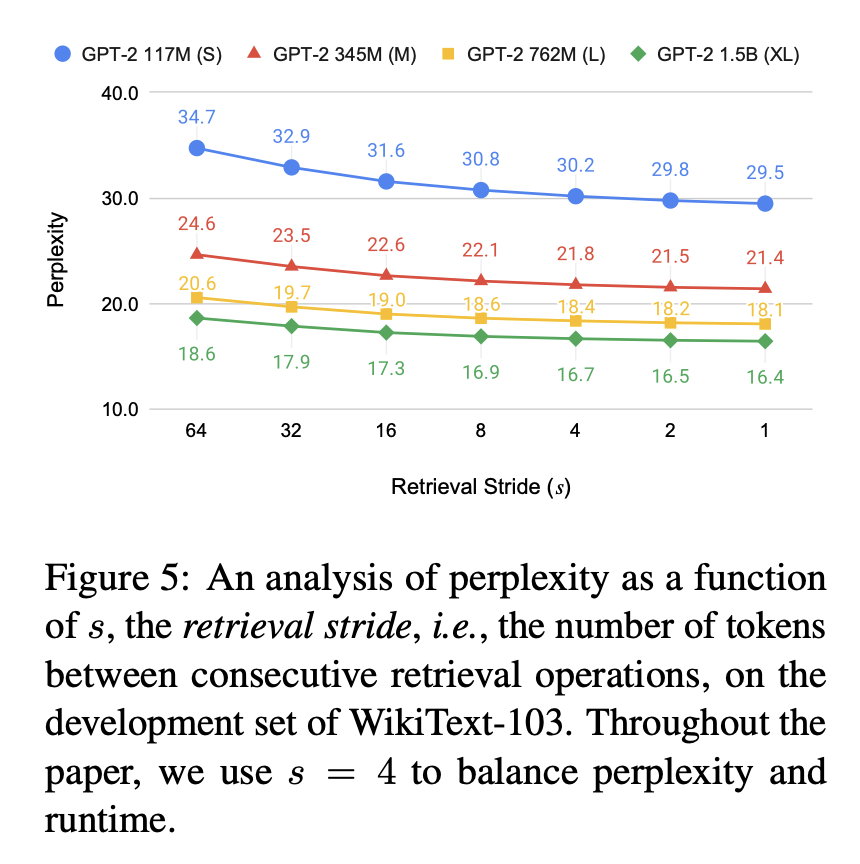
확실히 retrieval stride가 작아질수록 성능은 향상됨
ODQA에서 Retrieved docs의 수에 따른 Exact Match
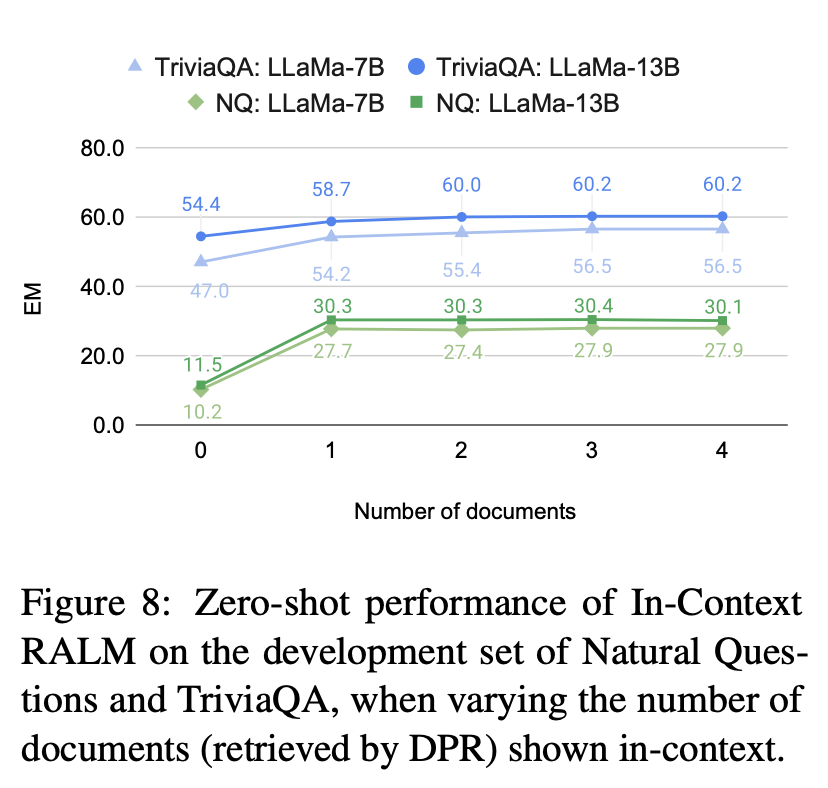
결론
- RALM을 위해 Architecture를 바꿔야 하는 RETRO보다, retrieved docs를 query 앞에 붙여주면서 retrieved docs를 사용하는 것이 다양한 모델에 사용하고 실험해 보기 간편해 보였다.
- Maximum Query Length 부분에서 모든 prefix를 사용하지 않고, prefix의 끝 부분만 사용해 retrieved 된 docs를 이용했을 때 결과가 오히려 좋아지는 점이 신기했다.
- Stride를 사용하는 것이 in-context RALM을 사용함에 runtime과 성능의 trade-off를 줄여줄 수 있을 것 같다.
- Retriever 호출 횟수도 줄여줌.
- Stride 함으로써 같은 stride 내에서는 retrieved docs가 변하지 않으므로 inference 시, KV cache를 사용할 수 있게 되었다 → 속도 가속화
- 두번째 부분이 runtime적으로 중요한 부분인 것 같다.
- RAG 프로젝트를 통해 한 번 구현해 봐야겠다.

수학, AI, CS study 그리고 일상🤗