Paper : https://arxiv.org/abs/2302.13971
글을 잘 정리해서 업로드 했었는데.. 글을 잘못하다가 삭제해서 이전 정리해놓은 정보로 재업로드 합니다..
두서 없을 수 있습니다..
Abstract
7B에서 65B 범위의 parameters를 가지고 있는 기본 언어 모델 집합인 LLaMA를 소개한다. Trillions of tokens으로 모델을 훈련하고, 독점적이고 접근이 불가능한 데이터셋이 아닌 공공적으로 이용가능한 데이터셋을 이용하여 최첨단 모델들을 훈련시킬 수 있음을 보였다. 특히, LLaMA-13B는 대부분의 벤치 마크들에서 GPT-3(175B)를 능가하고, LLaMA-65B는 Chinchilla-70B, PaLM-540B와 같은 최고의 모델들과 경쟁할만하다.
1. Introduction
거대한 text corpora들로 훈련된 LLM은 텍스트 지시(text instruction) 또는 몇 가지 예시(few examples)에서 가져온 새로운 작업들을 수행할 수 있는 능력을 보여주었다. 이러한 few-shot 속성은 모델을 충분한 크기로 키웠을 때 처음으로 나타났고, 이는 모델의 scaling에 초점을 맞추는 작업 계통을 초래했다. 이러한 노력들은 parameters가 많을수록 더 나은 성능을 낼 수 있다는 가정에 기반되었다. 하지만 주어진 계산 budget 안에서 Hoffmann et al. (2022)로부터의 최근 연구는 최고의 성능은 가장 큰 모델로부터 달성되지 않았고, 그보단 작지만 더 많은 데이터로에 대해 훈련한 것으로부터 달성되는 것을 보였다.
Hoffmann et al.(2022)로부터 scaling 법칙의 목표는 ‘특정 훈련 계산 예산에 맞는 가장 좋은 크기의 데이터셋과 모델 사이즈를 어떻게 측정하는지’이다. 그러나 이 목표는 언어 모델을 규모에 맞게 제공할 때 중요하게 되는 inference 예산을 무시한다. 이 문맥에서 성능의 목표 레벨이 주어졌을 때, 선호되는 모델은 훈련이 가장 빠른 것이 아닌 inference 시 가장 빠른 모델이다. 그리고 특정 레벨의 성능에 도달하기 위해 큰 모델을 훈련시키는 것이 저렴할 수 있지만, 더 긴 훈련을 받은 작은 모델이 결국 inference 시에는 저렴할 것이다. 예를 들어, Hoffmann et al. (2022)는 200B tokens에 대해 10B 모델을 훈련시키는 것을 추천했지만, 1T tokens 후에도 7B 모델의 성능이 계속해서 향상하는 것을 발견했다.
이 일의 초점은 원래 이용되었던 것보다 더 많은 토큰들을 이용해 훈련하여, 다양한 inference 예산에 대해 가능한 성능의 베스트를 달성하는 LM의 series를 훈련시키는 것이다. LLaMA라고 불리는 결과 모델은 7B에서 65B의 paremeters를 가지고 현재 최고의 LLMs과 비교했을 때 경쟁력있는 성능을 가진다. 예를 들어, LLaMA-13B는 GPT-3보다 10배 작음에도 불구하고 대부분의 benchmarks에서 더 좋은 성능을 낸다. 이 모델은 single GPU에서 실행될 수 있기에 LLM의 access와 연구를 대중화하는 데 도움이 될 것이라 믿는다. 가장 큰 규모의 모델인 우리의 65B-parameter model 또한 Chinchilla나 PaLM-540B와 같은 최고의 LLM과도 경쟁력이 있다.
Chinchilla, PaLM 또는 GPT-3와 달리 우리는 오직 공개적으로 이용가능한 데이터만을 이용했기에, 우리의 작업이 open-sourcing과 호환될 수 있게 만드는 반면, 대부분 기존의 모델들은 공개적으로 이용가능하지 않거나 문서화되지 않은 데이터에 의존한다. OPT, GPT-NeoX, BLOOM, GLM과 같은 몇몇 예외가 있지만, PaLM-62B나 Chinchilla과 경쟁할 만한 것은 없다.
이 논문에서 남은 부분은 transformer 구조에 대해 우리가 변경한 것들과, 훈련 방법들의 개요를 기재할 것이다. 그 다음 표준 벤치마크들의 집합에 대해 다른 LLM들과 우리 모델들의 성능을 비교할 것이다. 최종적으로, responsible AI 커뮤니티에서 가져온 최근 벤치마크들의 일부를 이용하여, 우리 모델에 인코딩된 편향과 toxicity(유해성)을 보여줄 것이다.
2. Approach
우리의 approach는 이전의 작업(Brown et al. 2020; Chowdhery et al. 2022)에 설명된 방법과 비슷하고, Chinchilla scaling 법칙에서 영감을 받았다. 표준 optimizer를 이용하여 많은 양의 textual data에 대해 큰 transformer를 훈련시켰다.
2.1 Pre-training data
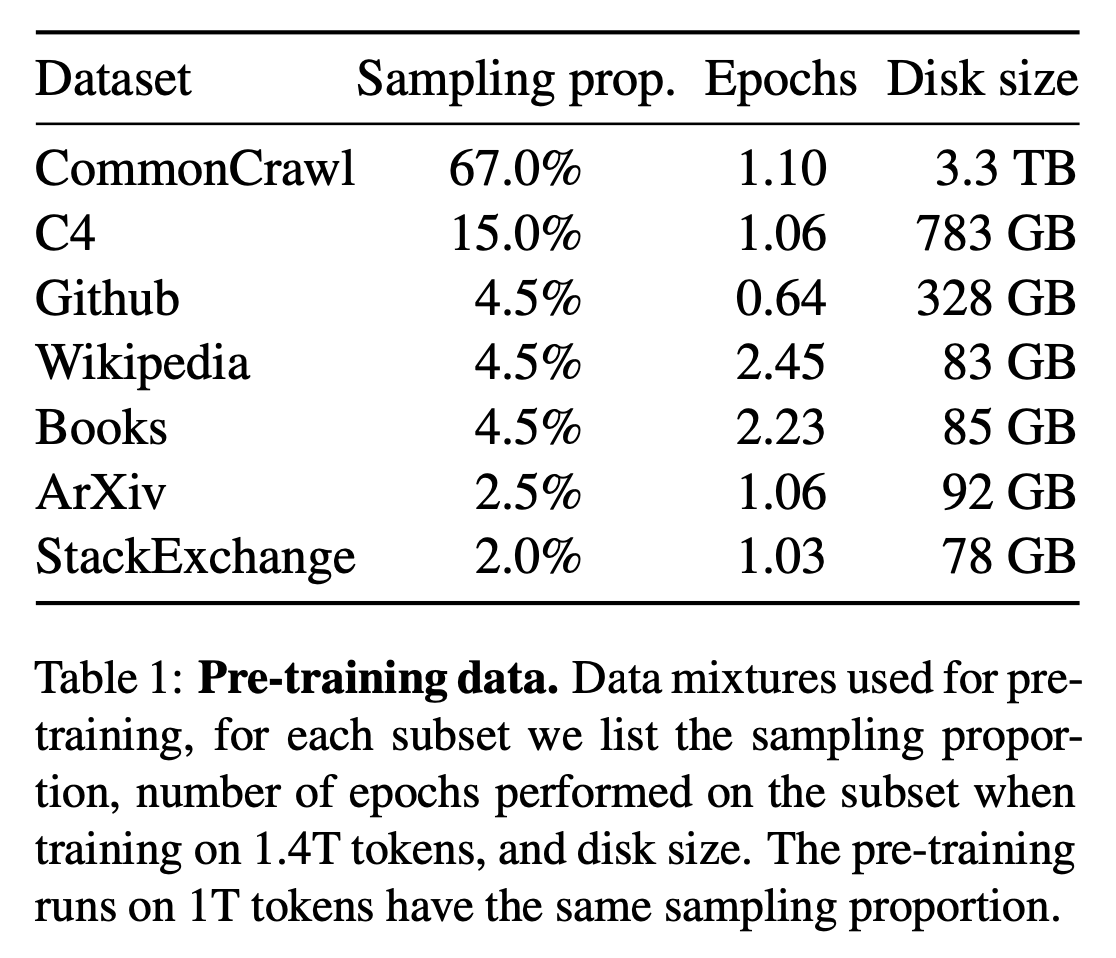
우리의 데이터셋은 Table 1에 나오는 몇몇 자원의 혼합이고, 다양한 도메인들을 다룬다. 대부분의 경우 오직 공개적으로 이용 가능하고, open sourcing과 호환되는 데이터만 이용한다는 제한을 가진채로, 다른 LLM들을 훈련시키는데 이용된 데이터 소스를 재사용한다. 이는 training set에 표현한 data와 비율의 다음과 같은 혼합을 이끌어낸다:
English CommonCrawl [67%]
우리는 CCNet 파이프라인을 가지고, 2017년부터 2020년까지 5개의 CommonCraw dumps를 전처리합니다(Wenzek et al., 2020). 이 프로세스는 라인 레벨에서 중복 데이터를 제거하고, non-English pages를 제거하기 위해 fastText linear classifier을 이용하여 언어 식별을 수행하고, n-gram 언어 모델을 이용하여 저품질의 콘텐츠를 필터링한다. 추가적으로, 사용된 pages가 references in Wikipedia 인지 랜덤하게 샘플링된 페이지인지 분류하는 linear model을 훈련시키고, references로 분류되지 않은 pages를 폐기한다.
C4 [15%]
탐색 실험 중, 전처리 된 다양한 CommonCrawl datasets를 이용하는 것이 성능을 향상시키는 것을 발견했다. 따라서 공개적으로 이용가능한 C4 데이터셋을 우리의 데이터에 포함했다. C4 데이터 전처리 과정 또한 중복 제거와 언어 식별이 포함되어 있었다 : CCNet과의 주된 차이점은 punctuation marks의 유무 또는 web pages에서 단어와 문장의 수와 같은 heuristics에 의존하는 quality filtering 이다.
Github [4.5%]
Google BigQuery에 이용될 수 있는 공개 Github dataset을 이용한다. 우리는 오직 Apache, BSD 및 MIT 라이선스로 배포되는 프로젝트만 유지했다. 추가적으로, 우리는 문장의 길이 또는 영숫자의 비율에 기반한 heuristics을 이용해 낮은 퀄리티의 파일들을 필터링했고, regular expressions으로 헤더(header)와 같은 boilerplate(반복적으로 나타나는 표준적이고 일반적인 내용; 특정한 목적이나 내용이 아니라, 일반적으로 문서의 형식을 유지하기 위한 부분)를 제거했다. 최종적으로 파일 수준에서 정확한 일치(exact match)를 이용해 resulting dataset의 중복을 제거한다.
Wikipedia [4.5%]
2022년 6월부터 8월까지 20개의 언어를 포함하는 Wikipedia dumps를 추가한다. 여기에는 라틴어 또는 키릴 문자를 사용하는 bg, ca, cs, da, de, en, es, fr, hr, hu, it, nl, pl, pt, ro, ru, sl, sr, sv, uk가 포함된다. 우리는 hyperlinks, 댓글 그리고 다른 formatting boilerplate를 제거하기 위해 data를 처리한다.
Gutenberg and Books3 [4.5%]
우리는 2개의 book corpora를 우리의 훈련 데이터셋에 포함한다 : 공개적인 도메인에 있는 책들을 포함하는 Gutenberg project와 LLM을 훈련시키기 위해 공개적으로 이용가능한 dataset인ThePile(Gao et al., 2020)의 Books3 부분. Book level에서 중복 제거를 수행하여, 90% 이상 내용이 겹쳐지는 책들을 제거한다.
ArXiv [2.5%]
과학 데이터를 dataset에 추가하기 위해 arXiv Latex 파일들을 처리한다. Lewkowycz et al. (2022)에 따라, bibliography(참고 문헌 목록)뿐만 아니라 첫 번째 section 이전의 모든 것들을 지웠다. 또한 .tex 파일에서 주석을 제거하고 사용자가 쓴 inline-expanded 정의와 매크로를 지우며 논문 간의 일관성을 높였다.
Stack Exchange [2%]
컴퓨터 사이언스부터 화학까지 다양한 도메인을 포함하는 수준 높은 질의 응답의 website인 Stack Exchange의 dump도 포함했다. 가장 큰 28개의 웹사이트의 데이터를 보관하고, text로부터 HTML tag를 제거하고, 점수를 기준으로(최고점에서 최저점으로) 답변을 정렬했다.
Tokenizer
SentencePiece의 구현을 사용하여 BPE(byte-pair encoding) 알고리즘을 가지고 데이터를 토큰화했다. 특히, 모든 숫자를 digits(개별 숫자; 0~9)으로 나누고 알려지지 않은 UTF-8 문자를 분해하기 위해 byte로 되돌린다. 전체적으로 모든 훈련 데이터셋은 토큰화 후 약 1.4T tokens를 포함한다. 훈련 데이터의 대부분에 대해, 각 토큰들은 훈련동안 오직 한 번 이용된다. 하지만 예외적으로 Wikipedia와 Books 도메인은 약 2번의 에폭을 수행한다.
2.2 Architecture
LLM에 대한 최근 연구에 따라, 우리의 네트워크는 transformer 구조(Vaswani et al., 2017)에 기반되어있다. 우리는 그 후 제안되거나, PaLM과 같은 모델에서 이용된 다양한 개선 사항들을 활용했다. 다음은 원래 구조와의 주요 차이점이고, 빈칸에는 이러한 변화에 대한 영감을 얻은 곳이다 :
Pre-normalization [GPT3]
훈련 안정성을 향상시키기 위해, 각 transformer sub-layer의 output을 정규화하는 대신 input을 정규화한다. Zhang과 Sennrich에 의해 소개된(2019) RMSNorm 정규화 함수를 이용한다.
SwiGLU activation function [PaLM]
성능을 향상시키기 위해 ReLU non-linearity를 Shazeer(2020)에 의해 소개된 SwiGLU 활성화 함수로 대체했다. PaLM에서와 같이 4d 대신 차원을 이용한다. → (FFN에서 ReLU를 이용하면 2개의 가중 matrix를 이용하는 것과는 달리 SwiGLU는 3개의 가중 matrix를 이용한다. Computation은 일정한데, matrix의 개수가 3/2로 증가했으니, hidden units들은 2/3로 감소한다.)
Rotary Embeddings [GPTNeo]
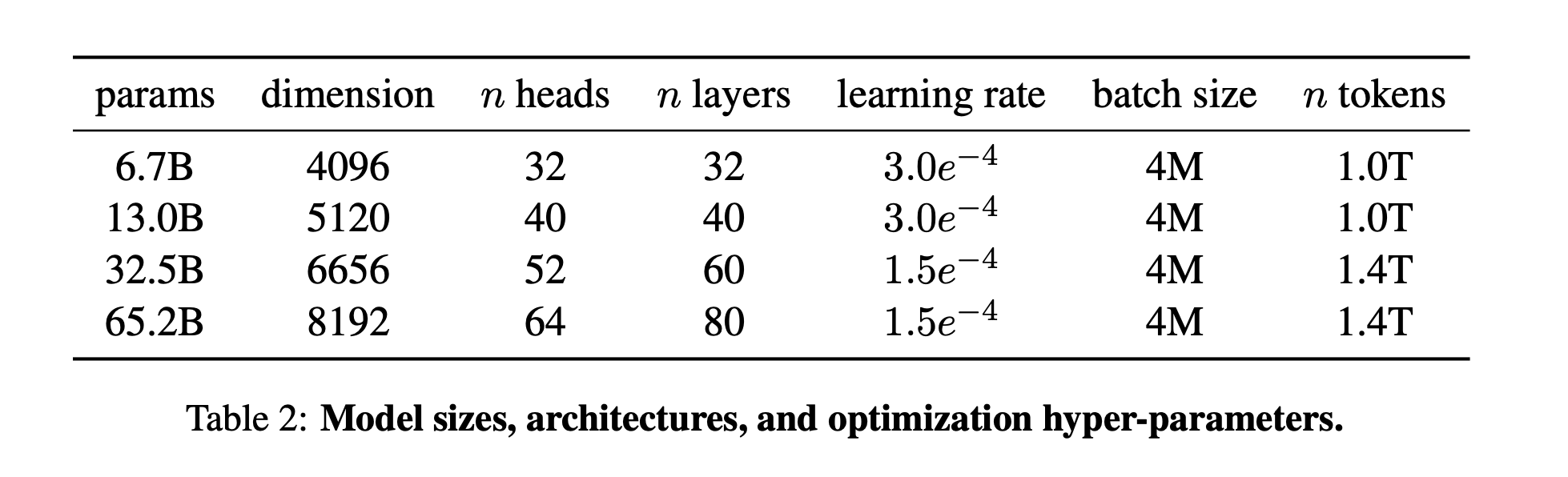
Network의 각 층에서 absolute positional embeddings를 지우고, 대신에 Su et al. (2021)에 의해 소개된 rotary positional embeddings(RoPE)를 추가한다. 우리의 다른 모델에 대한 hyperparameters의 디테일은 Table 2에 주어져 있다.
2.3 Optimizer
Adam optimizer을 이용해서 모델을 훈련시켰고, hyperparameter는 다음과 같다: . 최종 learning rate가 최대 learning rate의 10%인 cosine learning rate schedule을 이용한다. Weight decay = 0.1, gradient clipping = 1.0을 이용한다.
- 단어 설명 Weight decay 란? Weight Update with Weight Decay = 현재 가중치 − 학습률 × ( 그레디언트 + λ × 현재 가중치 ) Gradient Clipping 이란? gradient explosion을 막기 위해 gradient가 임계치를 넘어가면, gradient를 임계치로 바꾸어 주는..! gradient clipping=1이면, gradient vector가 1.0을 넘어가면 1.0으로 맞춰주겠다!
2,000 warmup steps를 이용하고, 모델의 크기에 따라 learning rate와 batch size를 다양하게 했다(자세한 것은 Table 2).
2.4 Efficient implementation
우리 모델의 훈련 속도를 높이기 위해 몇몇 optimization을 만들었다. 첫 째, 메모리 사용량과 실행 시간을 줄이기 위해서 causal multi-head attention의 효율적인 구현을 사용할 것이다. Xformers library에서 사용가능한 이 구현은 Rabe와 Staats(2021)에 영감을 받았고, Dao et al. (2022)의 backward를 사용한다. 이는 attention weights를 저장하지 않고 언어 모델링 작업의 인과적 특성으로 인해 마스킹되는 key/query 점수를 계산하지 않음으로써 달성된다.
훈련 효율을 더 향상시키기 위해서, 우리는 checkpoint를 통해 backward pass 동안 재계산되는 activation의 양을 줄였다. 더 정확하게는 linear layer의 output과 같은 계산하기 비싼 activation을 저장한다. 이는 PyTorch autograd에 의존하는 대신 transformer layers의 backward function을 수동으로 구현함으로써 달성된다. 이러한 최적화의 이점을 충분히 누리려면 Korthikanti et al. (2022)에서 설명된 모델과 sequence parallelism(병렬)을 이용하여 모델의 메모리 사용량을 줄여야 한다. 게다가 네트워크를 통한 GPU 간의 communication과 활성화 계산도 최대한 많이 겹친다(all_reduced operations 때문에).
65B-parameter 모델을 학습시킬 때, 우리의 코드는 80GB의 램을 가진 2048 A100 GPU로 약 380 tokens/sec/GPU를 처리한다. 이는 1.4T tokens를 포함하는 우리의 데이터셋을 훈련하는데는 약 21일이 걸린다는 것이다.
글을 함부로 지우거나 하면 안되겠다...
후회중...
