paper : https://arxiv.org/pdf/2005.11401.pdf
Abstract
LLM은 사실적 지식을 자신의 parameter에 저장하고, downstream NLP tasks들을 fine-tuning 했을 때 SOTA의 결과를 얻는다. 하지만 지식에 접근하고, 지식을 정확히 조정하는 능력은 제한적이다.
→ Knowledge-intensive tasks에 대해서는 task-specific 구조보다 성능이 뒤처진다.
추가적으로, LLM의 결정에 대한 증명을 제공하는 것과 LLM이 학습한 세상의 지식을 업데이트하는 것은 아직 연구 과제로 남아있다. Explicit non-parametric memory에 대한 미분 가능한 접근 메커니즘을 이용한 Pretrained model은 오직 추출 task에서만 연구되어왔다.
여기서 non-parametric memory란?
non-parametric 즉, 학습을 시킬 수 없는 것을 의미한다. 어떤 메모리를 이용하되, 이를 학습시킬 수는 없는 것을 의미. 즉, 외부에 있는 학습 불가능한 모델을 이용한다는 것이라고 해석할 수 있을 듯 하다.
범용적인 fine-tuning 방법인 Retrieval-augmented generation(RAG)를 탐구한다.
RAG : Language generation을 위한 “pre-trained parametric memory + non-parametric memory”
우리가 소개하는 RAG 모델 : pre-trained parametric memory(pretrained seq2seq model) + non-parametric memory(pre-trained neural retriever로 접근 가능한 dense vector index of Wikipedia)
하나의 시퀀스 전체를 생성할 때, 동일한 retrieved된 문서를 이용하는 것
시퀀스를 생성을 할 때, 토큰 별로 다른 문서를 사용할 수 있는 것
두 개의 RAG 공식을 비교한다 :
- 시퀀스 전체를 생성할 때, 동일한 retrieved된 문서를 이용하는 것
- 시퀀스를 생성을 할 때, 토큰 별로 다른 문서를 사용할 수 있는 것 → 1번과 달리 시퀀스를 생성할 때, 토큰 별로 참고하는 문서가 다르다는 것. 시퀀스를 완성할 때, 각 토큰은 꼭 동일한 문서를 참고할 필요가 없다는 것!
다양한 knowledge-intensive NLP tasks에 대해 fine-tuning 하고, 평가했다. 3가지 open domain QA task에 대해 SOTA를 달성했고, parametric seq2seq model과 task-specific retrieve-and-extract 구조를 능가했다.
언어 생성 task에 대해서 RAG가 parametric-only seq2seq baseline보다 더 특정하고 다양하고 사실적인 언어를 생성한다는 것을 발견했다.
1. Introduction
Pre-trained neural language model은 데이터로부터 상당한 양의 깊은 지식을 학습한다. 이는 외부 메모리의 접근 없이 이루어지기에 단점들을 가지고 있다:
- 그들의 메모리를 쉽게 확장하거나 수정할 수 없다.
- 그들의 예측에 대한 통찰력을 간단하게 제공할 수 없다.
- “Hallucination”을 생성할 수 있다.
Parametric memory와 non-parametric memory를 결합한 Hybrid model들은 이러한 문제들을 해결할 수 있다. Masked Language models과 미분 가능한 retriever를 결합한 REALM과 ORQA는 유망한 결과를 보여주었지만, 이 모델들은 오직 open-domain extractive QA만을 탐구했다. 여기서 우리는 hybrid parametric and non-parametric memory를 “workhorse of NLP” 즉, seq2seq model에 가져온다.
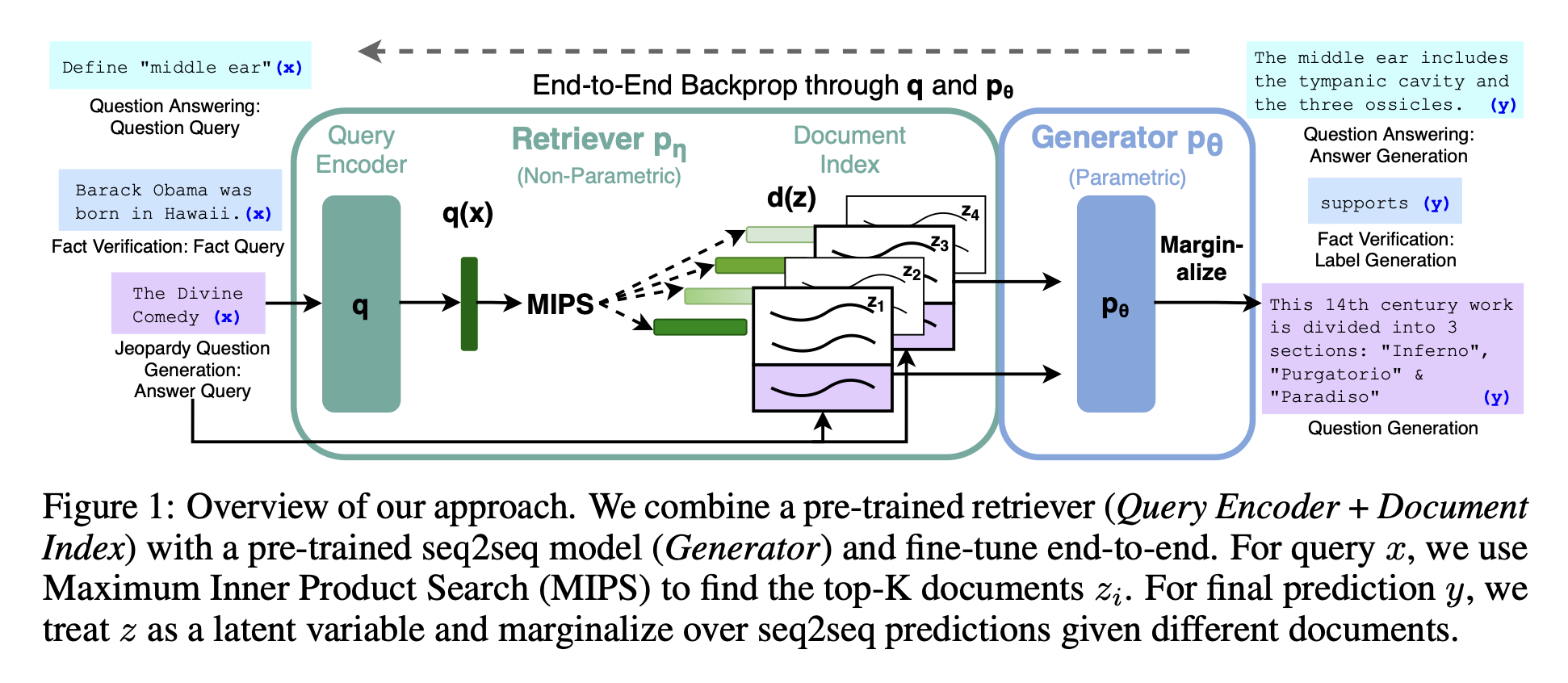
Retrieval-augmented generation(RAG)라고 하는 범용적 fine-tuning 접근 방법을 통해 pre-trained parametric memory 생성 모델에 non-parametric 메로리를 제공한다.
우리가 설계하는 RAG model : pre-trained seq2seq transformer(parametric memory) + pretrained neural retriever로 접근하는 a dense vector index of Wikipedia(non-parametric memory)
이 pretrained seq2seq transformer와 a dense vector index of Wikipedia를 end-to-end로 학습된 확률 모델에 결합한다(Fig 1). Dense Passage Retriever가 input에 대한 잠재적인 문서들을 제공하고, seq2seq model(BART)가 latent 문서들을 입력과 함께 사용하여 출력을 생성한다. Per-output basis(동일한 문서가 모든 토큰을 담당한다고 가정) or per-token basis(다른 문서들이 다른 토큰들을 담당한다고 가정)에 따라 Top-k 근사값으로 잠재적 문서들을 제한한다. RAG는 아무 seq2seq task에 대해 fine-tuning 할 수 있으므로, generator와 retriever를 함께 학습시킬 수 있다.
특정 task에 대해 처음부터 학습된 non-parametric memory(e.g. memory networks, stack-augmented networks, memory layers)를 가지고 시스템을 풍부하게 해주는 구조를 제안하는 많은 이전의 연구가 있어왔다. 반대로 우리는 parametric memory와 non-parametric memory 2개 모두를 광범위한 지식을 가지고 pre-trained, pre-load되는 설정을 탐구한다. 결정적으로, pre-trained 접근 메커니즘을 사용함으로써 추가적인 훈련없이 지식으로 접근하는 능력이 존재한다.
우리의 결과는 knowledge-intensive tasks에 대해 parametric memory와 non-parametric memory를 생성과 결합시키는 것의 이점을 강조했다. 이 tasks들은 외부 지식 자원에 접근하지 않고는 사람들이 수행하기를 합리적으로 예상할 수 없는 tasks이다. RAG가 open Natural Questions, WebQuestions, CuratedTrec에서 SOTA를 달성했고, TriviaQA에 대해 특별한 pre-training objectives를 사용한 최근 접근법도 능가했다. 이들은 추출 task에도 불구하고, 제약 없는 생성이 이전의 추출 접근 방식을 능가한다는 것을 발견했다. Knowledge-intensive 생성에 대해 MS-MARCO와 Jeopardy question 생성을 가지고 실험했고, 우리의 모델이 BART baseline보다 더 사실적이고, 더 구체적이고 더 다양한 반응을 생성한다는 것을 발견했다. FEVER 사실 판별에 대해, 강한 retrieval 감독을 사용하는 SOTA pipeline models과 4.3% 이내의 결과를 달성한다. 최종적으로 non-parametric memory를 대체하여 세상의 변화에 따라 모델의 지식을 업데이트할 수 있음을 보였다.
Non-parametric memory를 이용해, 문서를 가지고 온다. 이를 이용하면 세상의 정보가 업데이트 되더라도, pre-trained된 모델에 변화를 주지 않고도 non-parametric memory를 대체하여(세상의 정보가 변함에 따라 업데이트) 모델의 생성에 변화를 줄 수 있다. 모델이 retrieved된 문서를 이용해서 생성을 하기 때문에 문서를 retrieve 해오는 non-parametric memory만 대체하면, 새로 업데이트 되는 정보를 이용할 수 있다!
2. Methods
RAG : text documents z를 retrieve하기 위해 input x를 이용하고, text documents를 추가적인 배경으로 사용하여 target sequence y를 생성.
Fig 1에서 볼 수 있듯이, RAG는 2가지 구성요소를 활용한다:
1. Retriever : with parameter
⇒ 주어진 query 에 대한 text passages의 분포 (상위 k개로 짤린)
2. Generator : 로 parameterized된
⇒ 이전의 개의 토큰들(), 원래 입력 , retrieved된 문서 의 배경을 기반으로 현재 토큰을 생성
Retriever & Generator를 end-to-end로 훈련시키기 위해서, retrieved된 문서를 latent variable로 처리해야한다. 생성된 텍스트에 대한 분포를 생성하기 위해 latent 문서들을 다른 방법으로 주변화하는 2개의 모델을 제안한다.
- RAG-Sequence : 각 타겟 토큰을 예측하기 위해 동일한 문서를 사용하는 approach
- RAG-Token : 다른 문서를 기반해 각 타겟 토큰을 예측하는 approach
다음에서는 두 모델을 소개하고 components와 훈련, decoding 절차를 설명한다.
2.1 Models
RAG-Sequence Model
RAG-Sequence model은 retrieved된 동일한 문서를 사용하여 전체 시퀀스를 생성한다. 기술적으로 retrieved된 문서를 하나의 latent 변수로 처리한다. latent 변수는 top-k 근사화를 통해 seq2seq 확률 를 갖기 위해 주변화 되는 것이다. 구체적으로 top K개의 문서들은 retriever를 사용하여 retrieved되고, generator는 각 문서에 대해 출력 시퀀스 확률을 생성하고, 그 후에 이러한 확률들은 주변화(marginalized)된다.
RAG-Token Model
RAG-Token 모델에서는 각 타겟 토큰에 대해 다른 latent 문서를 뽑고, 그에 따라 주변화(marginalized) 할 수 있다. 이는 generator가 답을 생성할 때 여러 문서로부터 내용을 고를 수 있게 해준다. 구체적으로 top K개 문서들은 retriever를 사용해 retrieved되고, 그 후 주변화 전에 generator는 각 문서에 대해 다음 출력 토큰의 분포를 생성한다. 그리고 다음 토큰을 사용해 이 절차를 반복한다. 공식적으로 다음과 같이 정의한다:
최종적으로 RAG는 target class를 길이가 1인 target 시퀀스로 간주함으로써 sequence classification tasks에 사용될 수 있다. 이 경우 RAG-Sequence와 RAG-Token은 같다.
내가 이해한 정리
즉, y가 완성이 될 때,
RAG-Sequence Model = 한 문서에서 그 답이 나올 확률을 구하고, top-k개의 문서에서 그 답이 나올 확률을 다 더해준다.
ex) “나는 학교에 간다” → z1에서 ‘나는 학교에 간다’가 나올 확률 + z2에서 ‘나는 학교에 간다’가 나올 확률 + …
RAG-Token Model = 답에서 차근차근 그 답이 나올 확률을 다양한 문서에서의 확률을 이용해서 구한다.
ex) “나는 학교에 간다” → (z1에서 ‘나는’이 나올 확률 + z2에서 ‘나는’이 나올 확률 + …) (z1에서 ‘학교에’가 나올 확률 + z2에서 “학교에”가 나올 확률 … ) …
이렇게 계산
2.2 Retriever: DPR
Retrieval 구성요소 는 DPR에 기반된다. DPR은 다음의 bi-encoder 구조를 따른다:
는 BERT-base document encoder를 통해 생성된 document z의 dense representation이고, 는 BERT-base query encoder를 통해 생성된 query 의 dense representation이다. Top-K 를 계산하는 것은 k개의 높은 사전 확률 를 갖는 문서 리스트로, 약 sub-linear time에 풀리는 Maximum Inner Product Search(MIPS)문제이다. DPR의 pre-trained bi-encoder를 사용하여 우리의 retriever를 초기화하고 문서 index를 짓는다. 이 retriever는 TriviaQA 문제들과 Natural Questions의 답을 포함하고 있는 문서들을 가져오게 훈련되어 있다. 우리는 문서 index를 non-parametric memory라고 한다.
내가 이해한 정리
결국 query문과 document의 점수를 이용해서 어떤 document가 해당 query에 맞는지 확인을 할 방법이 필요한데, 이 때 Retriever:DPR을 이용한다.
대부분 점수를 매길 때, 내적을 이용한다. 내적을 이용하려면, 비교하는 것들의 차원의 크기가 같아야 한다. 그래서 Document와 query를 변형시켜 동일한 차원의 dense representation으로 나타내야 한다. 여기서 쓰이는 것이 BERT-base이다. 그렇게 나타낸 dense representation들로 각 문서와 해당 query의 유사도(점수)를 계산할 수 있다.
Pretrained bi-encoder를 사용해서 retriever 초기화하고, indexing 작업을 한다.
→ 여기서 indexing 작업이란? 문서의 dense representation을 retriever에 저장하고, 그것을 indexing하는 작업!
2.3 Generator: BART
Generator 구성요소 는 어느 encoder-decoder를 사용해서도 모델링 될 수 있다. 400M parameter 크기 pretrained seq2seq 모델인 BART-large를 사용할 것이다. BART를 이용해 생성을 할 때, 입력 와 retrieved된 값을 간단하게 concatenate한다. BART는 denoising objective와 다양한 노이즈 함수를 사용해 pretrained 되었다. BART는 다양한 생성 문제에서 SOTA 결과를 얻었고, 비슷한 크기의 T5 모델을 능가했다. 우리는 이제부터 BART generator parameters 를 parametric memory라고 한다.
2.4 Training
어떤 문서가 retrieved되어야 하는지 어느 직접적인 감독 없이 retriever와 generator 구성요소들은 함께 훈련된다. Input/output 쌍의 fine-tuning 훈련 corpus 가 주어지면, Adam을 이용한 확률적 경사 하강법을 사용해 각 타겟의 negative marginal log-likelihood 를 최소화한다. 훈련동안 문서 encoder 를 업데이트하는 것은 REALM이 pre-training동안 그러는 것처럼 document index를 주기적으로 업데이트 해주어야 하기에 비용이 많이 든다. 강한 성능을 위해 이러한 단계가 필수적이라는 것을 발견하지 못했고, document encoder와 index를 고정시킨 채로 오직 query encoder 와 BART generator만 fine-tuning한다.
2.5 Decoding
Test time에 RAG-Sequence와 RAG-Token은 를 근사하는 다른 방법이 필요하다.
RAG-Token
RAG-Token 모델은 기본으로 보여질 수 있다. transition 확률을 이용한 Autoregressive seq2seq generator :
Decode를 위해서는 를 기본 beam decoder에 연결할 수 있다.
RAG-Sequence
RAG-시퀀스의 경우 p(y|x) 가능성이 기존의 토큰당 가능성으로 분해되지 않으므로 단일 빔 검색으로는 해결할 수 없다. 대신에 을 사용해 각 가설의 점수를 내며, 각 문서 z에 대해 beam search를 실행한다. 이는 가설들의 집합 를 산출하고, 그 중 일부는 모든 문서의 beam에 나타나지 않을 수 있다.
가설의 확률을 추정하기 위해, beam에 y가 나타나지 않는 각 문서 z에 대해 추가 전진 패스를 실행하고, generator 확률에 를 곱한 다음 marginals에 대한 빔 간 확률을 더한다. 우리는 이러한 decoding 절차를 “Thorough Decoding”이라고 한다. 더 긴 출력 시퀀스의 경우, |Y|는 커질 수 있으며 많은 forward pass가 필요할 수 있다.
더 효율적인 decoding을 위해서는 인 더 나아간 근사를 만들 수 있다. 여기서 는 로 부터의 beam search동안 생성되지 않은 것이다. 이는 후보 집합 가 한 번생성되면, 추가적인 forward passes를 실행시킬 필요를 없애준다. 우리는 이러한 decoding 절차를 “Fast Decoding”이라고 한다.
내가 이해한 정리
문장이 생성되었는데(hypothesis), 이 문장은 모든 문서의 beam에 나타나지 않을 수 있다.
ex)
문서A에서는 “나는 학교에 간다”, “나는 교회에 간다”가 나왔으면,
문서B에서는 “나는 학교에 간다”, “나는 운동장에 간다” 가 나올 수 있고
모든 가설들의 집합 Y를 산출하니까
“나는 운동장에 간다”는 문서A에는 나오지 않으니까. “나는 운동장에 간다”가 문서A에 나타난 건지 추가적인 forward pass를 진행한다.
더 긴 출력 시퀀스의 경우 왜 가 커질까??
길이가 길어질수록 정확하게 같은 시퀀스가 나오기가 힘들어진다.
즉, 문서당 4개(beam k=4)의 시퀀스를 뽑는다고 치자.
시퀀스의 길이가 3이면 겹칠 확률이 높지만, 길이가 18 이렇게 되면 당연히 겹치지 않을 확률이 높고 그러면 가 커질 것이다.
Fast Decoding : 가 에 근사하면, 사실 이 시퀀스가 어떤 문서에 해당하는지 안하는지 계산하지 않아도 된다(여기서의 계산은 additional forward pass). 왜냐면 해당해도, 곱해지면 0에 가까워지므로 의미없어진다.
결국 forward pass를 줄여주고, 이를 Fast Decoding
느낀점
요즘 많이 쓰인다고 하던데, 코드로 직접 구현하고 이용해보고 싶다!
기회되면 해봐야지!~!
RePLUG가 이를 이용한 것 같고, LLM이 변하는 데이터에 대해 다시 학습시키지 않고 LLM에 지식을 넣어줄 수 있는 좋은 방법론인 것 같다~!
논문을 읽었을 때, 이해가 어렵진 않았다!
