Paper : https://arxiv.org/abs/2203.02155
Abstract
모델의 크기를 키우는 것이 모델이 사용자의 의도에 맞게 만들어주진 않는다. 사람의 피드백을 이용해 fine-tuning 함으로써 다양한 문제에 할당하는 LM을 사용자의 의도와 일치시키는 방법을 보여준다.
Labeler-written prompts : 전문가나 레이블러가 직접 작성한 프롬프트
라벨러가 작성한 프롬프트들과 OpenAI API를 통해 제출된 프롬프트들의 집합으로 시작하여, 우리는 원하는 모델 동작의 labeler demonstrations의 데이터셋을 수집하고, 이 데이터셋은 supervised learning을 이용해서 GPT-3를 fine-tuning할 때 사용한다. 그 다음, model outputs의 ranking dataset을 수집한다, 이 dataset은 나아가 사람 피드백으로부터의 강화 학습을 사용하여 이러한 supervised model을 fine-tuning 하는데 사용한다. 이러한 결과적인 모델을 InstructGPT라고 부른다.
(Labeler-written prompts + OpenAI API를 통한 prompts → 그 프롬프트들의 labeler demonstrations of the desired model behavior. 결국 프롬프트와 그에 대한 답을 이용해, supervised learning을 해 GPT-3를 fine-tuning ⇒ InstructGPT)
우리의 프롬프트 분포에 대한 사람의 평가에서는 100배 적은 parameters를 갖고 있음에도 불구하고 1.3B parameter InstructGPT의 outputs이 175B GPT-3의 outputs보다 선호되었다. 게다가 공공의 NLP 데이터셋에 대해 최소한의 성능 저하를 가지면서, InstructGPT 결과 생성에서 진실성 향상과 toxic의 감소를 보였다. InstructGPT가 여전히 간단한 실수를 만들어도, 우리의 결과는 사람의 피드백을 이용해 fine-tuning한 것이 LM과 사람의 의도를 일치시키기 위한 유망한 방향임을 보인다.
1. Introduction
LLM들은 입력으로써 task의 몇몇 예시가 주어지면, 다양한 NLP tasks를 수행하기 위해 “Prompted”될 수 있다. 그러나 이러한 모델들은 사실을 꾸미거나 편향 or toxic text를 생성하거나 간단하게 사용자의 instructions을 따르지 않는 것과 같은 의도하지 않은 행동들을 종종 표현한다.
Why? 최근 많은 LLM의 Language Modeling의 목표가 다음 토큰을 예측하는 것이기 때문!
↔ 사용자의 instructions를 도움되고 안전하게 따라주는 것을 목표로 두는 것과 다름
의도하지 않은 동작을 방지하는 것은 수백 개의 애플리케이션에 배포되고 사용되는 언어 모델에 특히 중요! LM들을 사용자의 의도와 일치하게 동작하기 위해 훈련시키는 것은 LM을 조정하는데 진전이 있다. 이는 Explicit intensions(instruction을 따르는 것) + implicit intentions(truthful, biased ❌, toxic❌, 이외의 다른 안좋은 것들)를 모두 포함한다.
우리가 원하는 LM:
- Helpful : 사용자가 task를 해결하는데 도움을 주어야 함
- Honest : 정보를 날조하거나 사용자를 잘못 이끌지 않음
- Harmless : 물리적으로, 정신적으로, 사회적으로 사람이나 환경에 해를 유발하지 않음
언어 모델을 조정하기 위한 fine-tuning 접근 방식에 중점을 두는데, 특히 쓰여진 instructions의 다양한 class를 따르도록 GPT-3를 fine-tuning을 하기 위해 사람 피드백으로부터의 강화 학습(RLHF; Reinforcement Learning from Human Feedback)을 사용(See Figure 2). 모델을 fine-tuning 하기 위한 reward signals로써 사람 선호도를 이용.
- ‘OpenAI API3에 제출된 프롬프트들 + 일부 labeler-written 프롬프트들’
- 1에서 수집된 프롬프트들에 대한 원하는 출력 동작을 사람이 작성한 데모 데이터셋을 수집
- 이를 이용하여 supervised learning baseline 훈련
- 더 큰 API 프롬프트 집합에 대한 우리 모델의 출력들 간 사람이 라벨링한 비교군 데이터셋을 수집
- 이 데이터셋을 이용해 reward 함수로써 RM을 학습 : 어떤 모델의 출력을 labeler가 더 선호할지 예측하도록 학습시킴
- 최종적으로 PPO 알고리즘을 사용하여 이 reward를 최대화시키기 위해 RM을 reward function으로써 사용하고, supervised learning baseline을 fine-tuning.
⇒ 결과적으로 나온 모델을 “InstructGPT”라고 부름
(이를 통해 GPT-3의 행동을 “인간의 가치”라는 더 넓은 개념이 아닌, 특정 그룹의 사람들(대부분 labelers & researchers)이 명시한 선호도에 밎게 조정된다. 이는 5.2에서 더 토론해보도록 하자.)
어떤 의미냐면, 사람마다 선호도가 다를 수 있는데 여기서 모델이 배우는 것은 특정 그룹이 라벨링 해놓은(선호도를 적어놓은) 데이터셋을 보고 배우니까, 특정 사람들이 명시한 선호도에 맞춰 조정된다는 것!
평가 : 훈련 데이터를 만드는데 참여하지 않은 사람들의 프롬프트를 사용하고, 우리의 labelers가 모델 출력의 퀄리티를 평가 + 다양한 공공 NLP 데이터셋에 대한 자동 평가
< 1.3B, 6B, 175B parameters 3가지 크기의 모델을 학습 + 모든 모델의 구조는 GPT-3 >
주요 결과는 다음과 같다 :
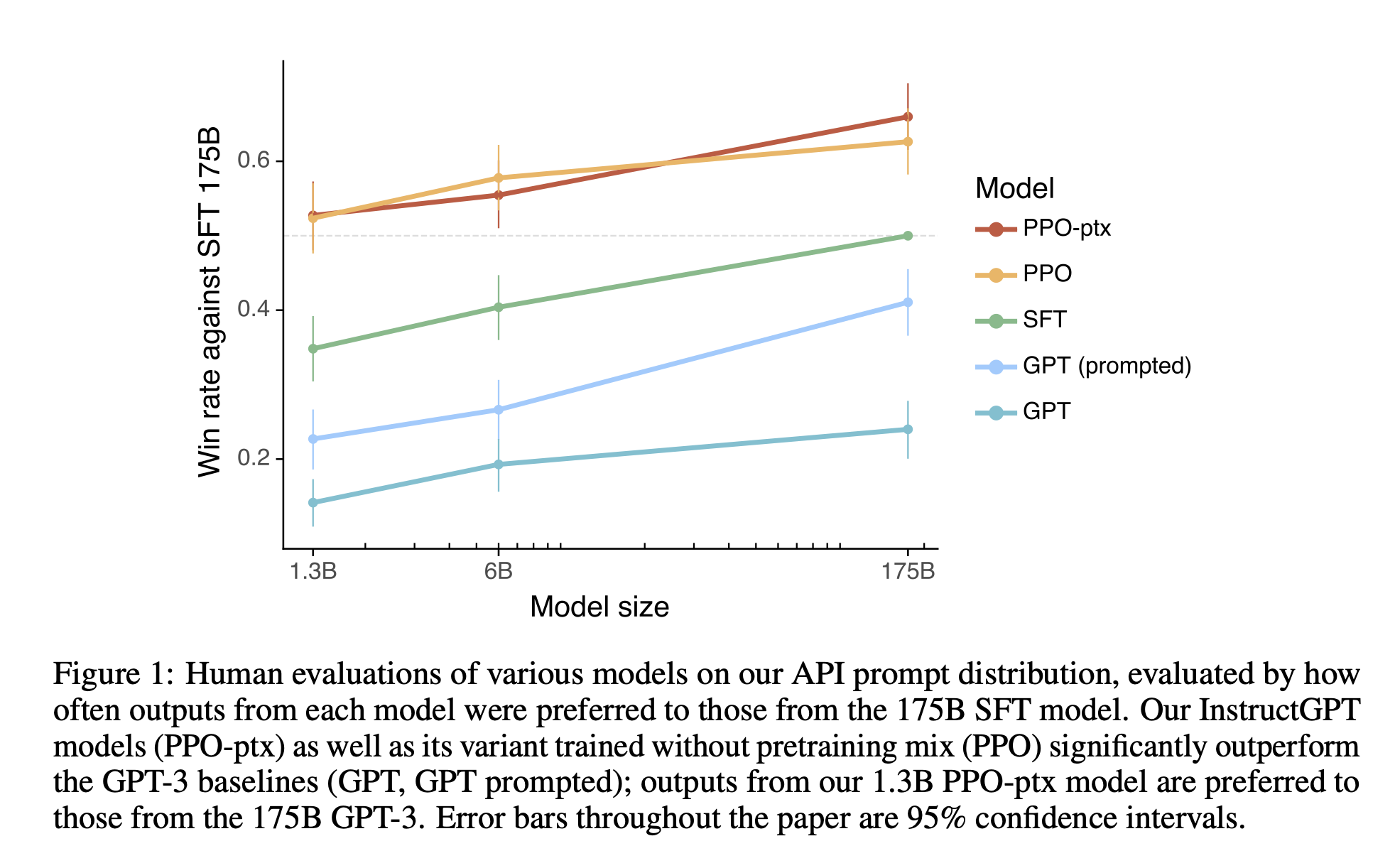
- Labelers는 GPT-3의 출력보다 InstructGPT 출력을 상당히 선호함.
1.3B parameter InstructGPT의 출력이 175B GPT-3의 출력보다 선호됨(모델의 구조는 동일하고, InstructGPT가 사람 데이터에 대해 fine-tuning 되었다는 사실만 다르다.)
Few-shot prompts를 추가하더라도 결과는 유효함. 175B InstructGPT의 출력들은 175B GPT-3 출력보다 85 ± 3%배 선호되었고, few-shot 175B GPT-3보다 71 ± 4%배 선호됨.
InstructGPT 모델들은 또한 labelers에 따라 더 적당한 출력을 생성했고, instruction의 명백한 제약들을 더 확실하게 따른다.
- Instruct GPT 모델은 GPT-3에 비해 진실성이 향상되었음을 보여줌.
TruthfulQA 벤치마크에 대해 InstructGPT는 GPT-3보다 두 배정도 더 자주 진실성있고 유익한 답변을 생성함. GPT-3가 어려워 할만한 질문의 하위 집합에서도 마찬가지로 강력함.
우리의 API prompt 배포로부터의 “closed-domain”인 출력이 입력 내용에 없는 정보를 포함하지 않아야하는 task(e.g. 요약, closed-domain QA)에 대해서, InstructGPT는 GPT-3에 비해 입력에는 없는 정보를 약 반만 만든다. (각각, 21%(InstructGPT) vs 41%(GPT-3) hallucination rate)
- InstructGPT는 GPT-3에 비해 toxicity에 대해 조금의 향상을 보여주었지만, 편향에 대해서는 그렇지 않음.
Toxicity를 측정하기 위해 RealToxicityPrompts 데이터셋을 이용했고, 자동 평가와 사람 평가를 수행했다. Respectful 하라고 prompted될 때, InstructGPT는 GPT-3보다 25% 적은 toxic 출력을 생성했다. InstructGPT는 Winogender와 CrowSPairs 데이터셋에 대해서는 GPT-3보다 상당히 향상되지는 않았다.
- RLHF fine-tuning 절차를 수정하여 공공의 NLP 데이터셋에 대해 성능 저하를 최소화할 수 있음.
RLHF fine-tuning 중에 GPT-3에 비교하여 특정 공공 NLP 데이터셋, 특히 SQuAD, DROP, HellaSwag, WMT 2015 French to English에서 성능 저하를 발견했다. “Alignment tax”의 한 예로, 우리의 조정 절차는 우리가 관심이 있을 수 있는 특정 task에 대한 낮은 성능의 비용에서 오기 때문이다. Labeler 선호도 점수와는 절충하지 않으며, PPO updates와 pretraining 분포의 log likelihood를 증가시키는 updates를 혼합함으로써 이러한 데이터셋에 대해 성능 저하를 크게 줄일 수 있다.
- 우리의 모델들은 어떤 훈련 데이터도 생성하지 않은 “held-out” labelers의 선호도를 일반화 함.
우리 모델의 일반화를 테스트하기 위해, held-out labelers와 함께 예비 실험을 수행하고, labelers가 우리의 훈련 labelers와 같은 비율로 GPT-3의 출력보다 InstructGPT의 출력을 선호하는 것을 발견했다. 그러나 이러한 모델들이 보다 광범위한 사용자 그룹에서 어떻게 수행되는지와 그리고 원하는 동작에 대하여 사람의 의견과 일치하지 않는 입력에 대해 어떻게 수행되는지를 연구하기 위해서는 더 많은 작업이 필요하다.
- 공용 NLP 데이터 세트는 우리의 언어 모델이 어떻게 사용되는지를 반영하지 않음.
사람 선호도에 대해 fine-tuning된 GPT-3(i.e. InstructGPT) vs FLAN 과 T0 라는 두 가지 공공의 NLP tasks의 다른 편집들에 대해 fine-tuning 된 GPT. 이 데이터셋들은 각 task에 대한 자연어 instructions와 결합된 다양한 NLP tasks로 구성된다. 우리의 API 프롬프트 배포에 대해, FLAN과 T0 모델들은 SFT(Supervised Fine-Tuning) baseline 보다 약간 성능이 떨어졌고, labelers은 이러한 모델들 보다 InstructGPT를 상당히 선호한다. (InstructGPT 73.4±2% winrate vs baseline T0 26.8 ±2%, FLAN 29.8 ±2%).
- InstructGPT 모델들은 RLHF fine-tuning 분포 이외의 instructions에 대해 유망한 일반화를 보여줌.
InstructGPT의 성능을 질적으로 조사하고, 코드 요약에 대한 instructions를 따를 수 있고, 코드에 대한 질문들에 답을 할 수 있으며, instructions이 fine-tuning 분포에서 매우 드물게 있음에도 불구하고 다른 언어로 된 instructions을 종종 따를 수 있음을 발견했다. 반대로, GPT-3가 이러한 tasks들을 수행할 수 있지만 더 신중한 prompting이 필요하고, 이러한 도메인의 지침을 대게 따르지 않는다. 이 결과는 우리 모델들이 “following intructions”의 개념을 일반화할 수 있음을 시사하기 때문에 흥미롭다. 그들은 직접적인 감독 신호가 거의 없는 작업에서도 약간의 조정을 유지한다.
- IntructGPT는 여전히 간단한 실수를 함.
예를 들어, InstructGPT는 여전히 instructions을 따르는데 실패하거나 사실을 꾸미거나 간단한 질문에 대해 긴 hedging 답을 내거나 잘못된 전제로 instructions을 감지하지 못할 수 있다.
전반적으로, 우리의 결과는 사람의 선호도를 이용해 LLM들을 fine-tuning하는 것이 그들의 안정성과 신뢰성을 향상시키기위해 해야 할 많은 작업이 남아있지만, 다양한 tasks에 대해 그들의 행동을 상당히 향상시키는 것을 나타낸다.
2. Related Work
사람 피드백으로부터의 학습과 조정에 대한 연구
우리는 모델을 인간의 의도, 특히 인간 피드백(RLHF)의 강화 학습에 맞추는 이전 기술을 기반으로 한다. 본래 모의 환경과 Atari 게임에서 훈련된 간단한 로봇을 위해 개발된 이전 기술은 최근에 텍스트를 요약하기 위해 LM을 fine-tuning하는 것에 적용되었다. 이 작업은 차례로 대화, 번역, 의미적 분석, 이야기 생성, 리뷰 생성, 증거 추출과 같은 영역에서 사람의 피드백을 보상으로 사용하는 비슷한 작업의 영향을 받는다. Madaan et al. (2022)는 prompt를 증강하기 위해 서면(written) 사람 피드백을 사용하고, GPT-3의 성능을 향상시켰다. 또한 RL을 사용한 텍스트 기반 환경의 에이전트와 규범적 선행(normative prior)을 조정하는 작업이 있었다(Nahian et al., 2021). 우리의 작업은 언어 작업의 광범위한 배포에 대해 언어 모델을 조정하는 데 RLHF를 직접 적용하는 것으로 볼 수 있습니다.
LM이 조정되는 것이 무엇을 의미하는지에 대한 질문은 또한 최근에 주목을 받았다(Gabriel, 2020). Kenton et al. (2021)은 유해 콘텐츠 제작과 게임 오지정 목표를 포함하여 misalignment로 인한 LM의 행동 문제를 분류합니다. 동시에 Askell et al. (2021)은 alignment 연구를 위한 시험대로 언어 보조자를 제안하고, 몇 가지 간단한 baselines과 스케일링 특성을 연구한다.
Instructions을 따르게 LM 훈련
우리의 작업은 또한 LM의 cross-task 일반화 연구와 관련이 있다. 이는 LMs이 다양한 공공 NLP 데이터셋(보통 적당한 instruction이 붙어있는)으로 fine-tuning 되고, 다른 NLP tasks의 집합으로 평가되는 것이다. 이 도메인에서는 훈련 및 평가 데이터, instructions의 형식, pretrained model의 크기, 다른 실험적 디테일에서 차이가 있는 다양한 작업이 있었다. 연구 전반에 걸쳐 일관된 발견은 instructions을 가지고 다양한 NLP tasks에 대해 LM들을 fine-tuning하는 것은 zero-shot, few-shot settings에서 held-out tasks에 대해 downstream 성능을 향상시킨다는 것이다.
또한 모의 환경에서 탐색하기 위해 자연어 instructions을 따르도록 훈련된 내비게이션에 대한 instruction following 작업의 관련 라인도 있다.
LM의 유해성 평가
LM의 행동을 수정하는 목표는 LM이 실제 세상에 배치되었을 때, 이러한 모델들의 피해를 완화하는 것이다. 이러한 리스크들은 광범위하게 문서화되어 있다. LM은 편향된 출력을 생성할 수 있고, 개인 데이터를 누설할 수 있고, 잘못된 정보를 생성할 수 있고, 악의적으로 이용될 수도 있다; 철저한 리뷰를 위해 독자를 Weidinger et al. (2021)로 안내한다. LM을 특정 분야(e.g. 대화 시스템)에 배포하는 것은 새로운 위험과 과제가 발생시킨다. 특히 toxicity, 고정관념, 사회적 편향을 중심으로 이러한 유해성을 구체적으로 평가할 수 있는 벤치마크를 만드는 것을 목표로하는 초기지만 성장하고 있는 분야가 있다. LM 행동에 잘 의도된 개입은 부작용을 가질 수 있기에 이러한 문제들에 대해 상당한 진전을 만드는 것은 힘들다; 예를 들어, LM의 toxicity를 줄이기 위한 노력은 훈련 데이터에서 편견적인 상관 관계로 인해 적게 나온 그룹들로부터의 텍스트를 모델링하는 능력을 감소시킬 수 있다(데이터셋에 잘 나오지 않는 것들은 텍스트 모델링하기 힘들어지는!).
해를 완화시키기 위해 LM의 행동을 수정
LM의 행동 생성을 바꾸는 많은 방법들이 있다. Solaiman과 Dennison (2021)는 모델들이 question answering task에서 데이터셋의 값을 준수하는 능력을 향상시켜주는 작고, value-targeted 데이터셋에 대해 LM을 fine-tuning했다. Ngo et al. (2021)는 LM이 연구자가 작성한 트리거 문구 집합을 생성할 높은 조건부 확률을 가지는 문서를 제거하며 pretraining 데이터셋을 필터링한다. 이 필터링된 데이터셋에 대해 훈련될 때, LM들은 약간의 Language Modeling 성능 저하 대신 덜 유해한 텍스트를 생성한다. Xu et al. (2020)은 챗봇의 안정성을 향상시키기 위해 데이터 필터링, 생성 시 특정 단어들 또는 n-grams을 막기, 안전에 특화된 제어 토큰, 사람에 의한 데이터 수집을 포함해 다양한 접근 방법들을 사용했다. LM들로부터 편향이 생성되는 것을 완화하기 위한 다른 접근 방법들은 word embedding regularization, 데이터 증강, 민감한 토큰들에 대한 분포를 더욱 균등하게 만들기 위한 null space projection, 다른 목표 함수 또는 인과적 매개 분석을 사용한다. 또한 LM의 생성을 조정하기 위해 두 번째 LM (대게 더 작은)을 사용하는 작업이 있고, 이 아이디어의 변형들은 LM의 toxicity를 줄이는데 사용된다.
3. Methods and experimental details
3.1 High-level methodology
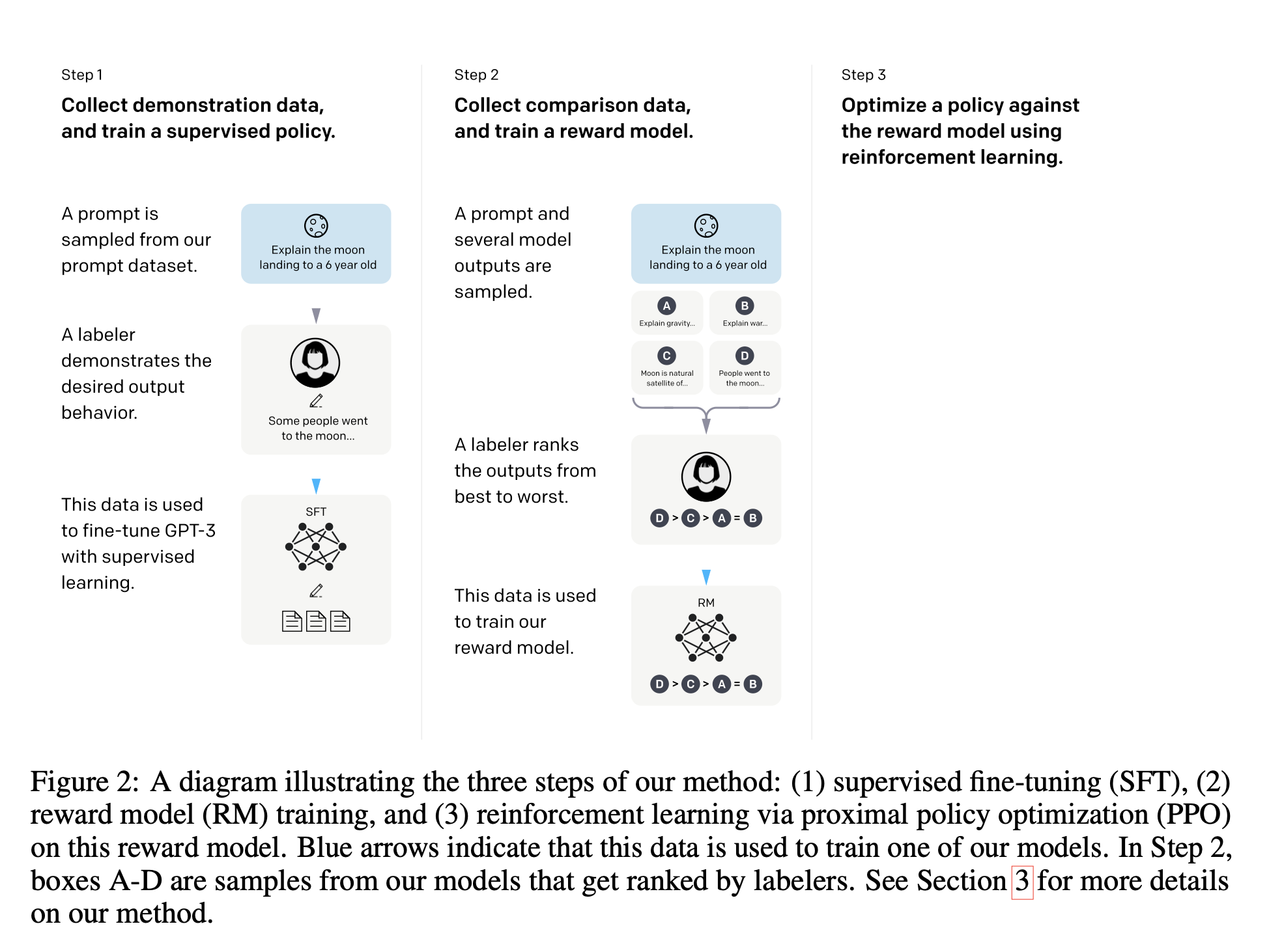
우리의 방법론은 stylistic 연속과 요약 도메인에 적용한 Ziegler et al. (2019)와 Stiennon et al. (2020)을 따른다. Pretrained LM(상세는 논문 참조)로 시작해, 우리 모델이 aligned outputs을 생성하기를 원하는 prompt 배포, 훈련된 사람 labelers의 팀으로 시작한다. 우리는 다음의 3가지 절차를 적용한다(Figure 2):
Step 1: 데모 데이터를 수집하고, 감독된 정책을 훈련하라.
우리의 labelers는 input 프롬프트 분포에 대해 원하는 동작의 데모를 제공한다(이 분포에 대한 디테일은 Section 3.2). 그 다음 이 데이터에 대해 supervised learning을 사용해서 pretrained GPT-3를 fine-tuning 한다.
Step 2: 비교 데이터를 수집하고, reward model을 훈련하라.
모델의 출력들 사이에서 비교 데이터셋을 수집한다. 여기서 labelers는 주어진 input에 대해 어떤 outputs을 선호하는지 나타낸다. 그 다음 사람이 선호하는 output을 예측하게 reward model을 훈련시킨다.
Step 3: PPO를 사용해서 reward model에 대항하여 정책을 최적화한다.
RM(Reward Model)의 output을 scalar reward로써 사용한다. PPO 알고리즘(Schulman e al., 2017)을 이용해 이러한 reward를 최적화하기 위해 supervised policy를 fine-tuning한다.
Step 2와 Step 3는 연속적으로 반복할 수 있다; 새로운 RM을 훈련시킨 후 새 정책을 훈련시키는데 사용되는 현재 최고의 정책에 대해 더 많은 비교 데이터가 수집된다. 실제로 대부분의 비교 데이터는 supervised 정책으로부터 나오고, 일부는 PPO 정책으로부터 나온다.
3.2 Dataset
우리의 프롬프트 데이터셋은 주로 OpenAI API로 제출된 text prompt, 특히 Playground interface에 대한 InstructGPT 모델의 이전 버전(우리의 데모 데이터의 subset에 대해 supervised learning을 통해 훈련된)을 사용한다. Playground를 사용하는 고객들은 InstructGPT를 사용되는 어느 시간마다 반복되는 알림을 통해 그들의 데이터가 모델의 추가 훈련에 사용될 수 있음을 통보받았다. 본 논문에서는 운영 중인 API를 사용하는 고객의 데이터를 사용하지 않았다. 긴 흔한 prefix를 공유하고 있는 프롬프트들을 확인함으로써 경험적으로 프롬프트들의 중복을 제거하고, 사용자 ID당 프롬프트들의 수를 200으로 제한했다. 또한 사용자 ID에 따라 train, validation, test를 만들었고, validadtion과 test sets은 training set에 데이터가 있는 사용자로부터 온 데이터는 포함되지 않았다. 잠재적으로 고객의 민감한 디테일을 모델이 배우는 것을 막기 위해 개인 식별 정보(PII : personally identifiable information)에 대한 훈련 데이터의 모든 프롬프트를 필터링한다. 가장 첫 번째 InstructGPT 모델들을 훈련시키기 위해서는 labeler들에게 스스로 프롬프트들을 작성해달라고 요청했다. 이는 프로세스를 부트스트랩하기 위해 instruction과 같은 프롬프트의 초기 소스가 필요했기 때문이고, 이러한 종류의 프롬프트들은 일반적인 GPT-3 모델 API에 대게 제출되지 않았다. Labeler들에게 3가지 종류의 프롬프트들을 적어달라고 요청했다:
- Plain : Tasks들이 충분히 다양한지 보장해주며, labeler들에게 임의의 task를 제안하도록 간단히 요청한다.
- Few-shot : Instruction에 대한 다수의 query/response 쌍과 Instruction을 제안하도록 labeler들에게 요청한다.
- User-based : OpenAI API의 대기 목록 응용 프로그램에 명시된 많은 사용 사례를 가지고 있었다. Labeler들에게 이러한 사용 사례에 해당하는 프롬프트를 제안하도록 요청했다.
이러한 프롬프트들로부터 우리의 fine-tuning 절차에서 3가지 다른 데이터셋을 생성한다:
- 우리의 SFT model들을 훈련하는데 사용될 labelers의 데모가 있는 SFT dataset
- 우리의 RM들을 훈련하는데 사용될 모델 outputs에 대한 labelers의 랭킹이 있는 RM dataset
- RLHF fine-tuning의 input으로써 사용될 어느 사람 라벨링도 없는 PPO dataset
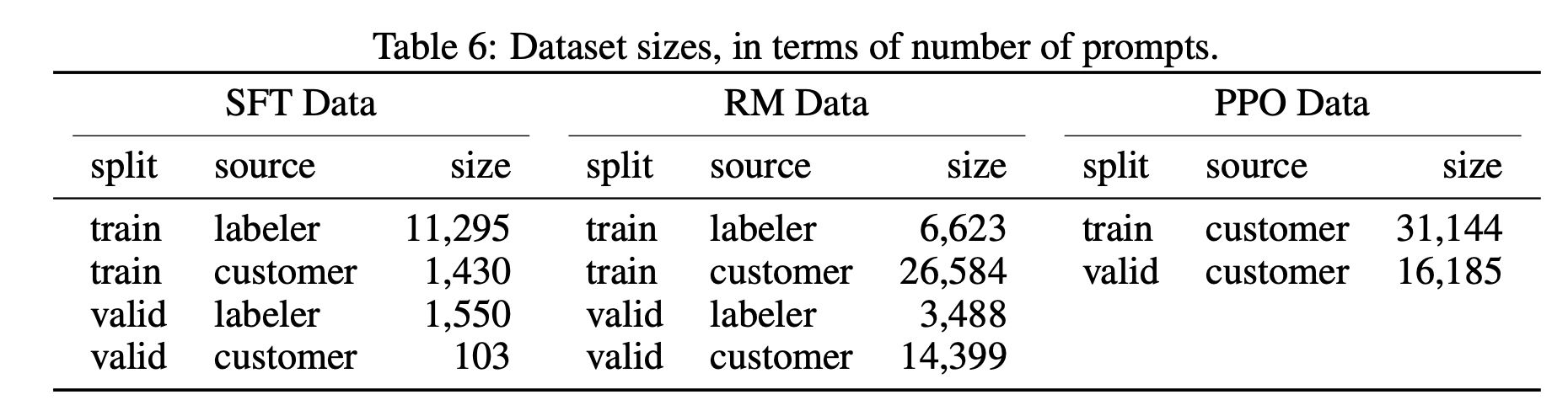
SFT 데이터셋은 13k개의 훈련 프롬프트들(API로부터 온 것 + labeler가 쓴 것)을 포함하고 있고, RM 데이터셋은 33k개의 훈련 프롬프들(API로부터 온 것 + labeler가 쓴 것)을 가지고 있고, PPO 데이터셋은 31k개의 훈련 프롬프트들(오직 API로부터 온 것)을 가지고 있다. 데이터 크기에 대한 디테일은 Table 6에 있다.
우리 데이터셋의 구성을 파악하기 위해, Table 1에서 우리의 API 프롬프트들(구체적으로 RM dataset)에 대한 사용 사례 카테고리의 분포를 우리의 계약자들이 라벨링한 것과 같이 보여주었다. 가장 많은 사용 사례는 classification 또는 QA가 아닌 generative 였다. 또한 Table 2의 몇 가지 예시적인 프롬프트들(InstructGPT 모델에 제출된 프롬프트의 종류를 모방하기 위해 연구자에 의해 작성된)을 보여준다; InstructGPT에 제출된 더 많은 프롬프트들은 Appendix A.2.1에서 볼 수 있고, GPT-3에 제출된 프롬픞트들은 Appendix A.2.2에서 볼 수 있다. 우리의 데이터셋에 대한 더 디테일한 부분은 Appendix A에 있다.

3.3 Tasks
우리의 훈련 tasks들은 두 가지 소스로부터 온다:
- 라벨러로부터 작성된 프롬프트들의 데이터셋
- 우리 API에 이전의 InstructGPT에 제출된 프롬프트들의 데이터셋(see Table 6)
이러한 프롬프트들은 매우 다양하고, 생성, QA, 대화, 요약, 추출 그리고 다른 자연어 tasks을 포함하고 있다(see Table 1). 우리의 데이터셋은 96% 이상이 영어이지만, Section 4.3에서는 또한 다른 언어인 instructions에 반응하고, 코딩 작업을 완료할 수 있는 우리 모델의 능력을 조사한다. 각 자연어 프롬프트에 대해 task는 대게 자연어 instruction(e.g. “Write a story about a wise frog”)을 통해 직집적으로 특정되지만, few-shot 예시(e.g. 개구리 이야기의 2가지 예시를 주고, 새로운 것을 생성하라고 모델에 프롬프트 해준다) 또는 내재적인 연속성(e.g. 개구리에 대한 이야기의 시작 부분을 제공한다)을 통해 간접적으로 특정될 수도 있다. 각 상황에서 라벨러에게 프롬프트를 작성한 사용자의 의도를 최선을 다해 추론해달라고 요청했고, task가 불분명한 inputs은 건너뛰라고 요청했다. 게다가 제공한 지침(Appendix B)과 labeler들의 최고의 판단에 따라 Labeler들은 응답의 진실성과 같은 내재적 의도와 편향과 toxic 언어와 같은 잠재적으로 유해한 출력들 또한 고려했다.
3.4 Human data collection
데모 데이터와 비교 데이터를 생성과 주요 평가를 수행하기 위해서 Upwork와 ScaleAI를 통해서 40명의 contractors로 이루어진 팀을 고용했다. 요약 문제에 대해 사람의 선호도를 모았던 이전의 작업과 대조적으로, 우리의 inputs은 더 다양한 tasks에 걸쳐져 있으며 때때로 논란이 많고, 민감한 주제도 포함할 수 있다. 우리의 목표는 다양한 인구통계학적 그룹의 선호도들에 민감하고, 잠재적으로 유해한 출력들을 식별하는 것에 능한 labelers 그룹을 뽑는 것이다. 따라서 이러한 축에서 라벨러의 능력을 측정하기 위해 설계된 screening test를 수행했다. 이 테스트에서 좋은 성과를 내는 라벨러들을 뽑았다; 선별 절차와 라벨러 인구 통계에 대한 자세한 내용은 Appendix B.1을 참조!
훈련과 평가 동안, alignment 기준이 충돌할 수도 있다: 예를 들어, 유저가 잠재적으로 유해한 반응을 요청한 경우. 훈련동안, 우리는 사용자에게 도움을 주는 것을 우선시한다(그렇게 하지 않으면 어려운 설계 결정을 내려야 하며, 자세한 논의는 섹션 5.4 참조). 그러나 우리의 최종 평가에서는 라벨러들에게 진실성과 무해성을 우선시하도록 요청한다(왜냐면 이게 우리가 정말로 신경쓰는 것이니까).
Stiennon et al. (2020)과 같이, 우리는 프로젝트의 과정에서 라벨러들과 긴밀하게 협력한다. 프로젝트에 대해서 라벨러들을 훈련시키고, 각 task에 대한 구체적인 지침을 작성하고, 공유된 대화방에서 라벨러의 질문에 답해주는 onboarding 절차가 있다.
다른 라벨러들의 선호도들을 우리 모델이 얼마나 잘 일반화했는지 확인하기 위한 첫 연구로써, 우리는 훈련 데이터의 어느 것도 생성하지 않은 별도의 라벨러들을 고용한다. 이 라벨러들은 동일한 공급 업체에서 데려오지만, screening test를 받지 않는다.
Task의 복잡성에도 불구하고, inter-annotator 일치율이 꽤 높은 것을 확인했다: Training 라벨러들은 서로에게 72.6 ± 1.5%의 시간 동안 일치하는 반면, held-out 라벨러들의 경우 이 숫자는 77.3 ± 1.3%이다. 비교를 위해, Stiennon et al. (2020)의 요약 작업에서 연구자-연구자 일치는 73 ± 4%였다.
3.5 Models
GPT-3 pretrained LM으로 시작한다. 이러한 모델들은 다양한 종류의 인터넷 데이터에서 훈련되었으며, 다양한 downstream tasks에 적응이 가능하지만, 특정화된 동작에서는 좋지 않다. 이러한 모델들로부터 시작해서, 모델들을 3가지 다른 기술을 이용해 훈련시킨다:
Supervised fine-tuning (SFT)
Supervised Learning을 사용해서 라벨러의 데모(demonstrations)에 대해 GPT-3를 fine-tuning. 16 epochs동안 훈련했고, cosine learning rate decay, residual dropout=0.2를 사용했다. Validation set의 RM score에 기반하여 최종 SFT 모델을 선택했다. Wu et al. (2021)과 유사하게, 우리의 SFT 모델들은 1 epoch 이후에 validation loss에 대해 과적합 되었다는 것을 발견했다; 그러나 이러한 과적합에도 불구하고, 더 많은 epochs 동안 훈련을 하는 것은 RM score와 인간 선호도 평가 모두에 도움이 된다는 것을 발견했다.
Reward modeling (RM)
최종 unembedding layer(최종적으로 dense 차원에서 vocabulary차원으로 unembedding 시켜주는 layer)가 제거된 SFT 모델로부터 시작해, 우리는 프롬프트와 response를 받고 scalar reward를 출력하기 위해 모델을 훈련시킨다. 본 논문에서는 6B RM이 엄청난 계산을 절약하기에 오직 6B RM만을 사용하고, 175B RM 훈련은 불완전할 수 있다는 것을 발견했다. 그래서 RL동안 175B RM 훈련은 value function으로써 사용되기에 덜 적합했다는 것을 발견했다(Appendix C for more details).
Stiennon et al. (2020)에서 RM은 같은 입력에 대한 두 모델의 출력 사이의 비교 데이터셋으로 훈련되었다. 비교된 것들을 레이블로 가지며, cross-entropy loss를 사용한다. 보상에서의 차이는 사람 라벨러에 의해 한 응답이 다른 응답보다 선호될 logg odds를 나타낸다.
비교군 수집을 빠르게 하기 위해, 우리는 순위를 매길 K=4 ~ 9 사이 수의 응답들을 제시한다. 이는 라벨러에게 보여질 각 프롬프트에 대한 개의 비교쌍들을 제공한다. 각 라벨링 task내에서 비교쌍들이 매우 상관관계가 있기에, 비교군들을 하나의 데이터셋으로 간단하게 섞으면 데이터셋에 대한 single pass가 reward model의 과적합을 초래하는 것을 발견했다. 대신에, 하나의 배치 요소로써 각 프롬프트로부터 모든 개의 비교군들에 대해 훈련한다. 각 완료에 대해 RM의 single forward pass만 필요하기 때문에 계산적으로 훨씬 효율적이고, 더 이상의 과적합이 되지 않기 때문에, 훨씬 향상된 validation 정확도와 log loss를 달성한다.
이해를 위한 설명
만약 각 개의 비교쌍들이 개별적인 데이터 포인트로 여겨지면, 각 completion(response)가 K-1번 gradient updates에 사용된다. 그렇기에 1에폭 후에는 과적합이 될거다!
예시) response가 a,b,c,d 있다면, (a,b)비교, (a,c)비교, (a,d)비교, (b,c)비교, (b,d)비교, (c,d)비교를 통해, 1에폭에 각 response는 gradient update에 K-1번(3번) 쓰인다. 그러면 과적합 될거다..!
하나의 에폭에 데이터를 반복해서 사용하면 과적합! 그래서 비교군들을 하나의 배치에 넣으면, 종합적인 gradient update는 한 번 일어나니까 과적합이 일어나지 않는다. 또한 single forward pass만 필요하기에 gradient update도 한 번 일어나니까 계산적으로도 효율적이다.)
구체적으로, reward model에 대한 손실 함수는 다음과 같다:
여기서 는 prompt x와 parameter 를 이용한 completion y에 대한 reward model의 scalar output이고, 는 쌍의 preferred completion이고, D는 사람 대조군의 데이터셋이다. (하나의 배치에 모든 loss가 들어가니까, 저렇게 나눠주는 듯~)
마지막으로 RM loss가 reward의 이동에 무관하기 때문에, 라벨러의 demonstrations가 RL을 하기 전에 평균 0을 달성하기 위해 bias를 이용해서 reward model을 정규화한다.
Reinforcement learning (RL)
다시 한 번 Stiennon et al. (2020)에 따라, SFT 모델을 PPO를 이용해 우리의 환경에 대해 fine-tuning. 환경은 임의의 소비자 프롬프트를 표현하고 프롬프트에 대한 반응을 기대하는 bandit 환경이다. 프롬프트와 반응이 주어지면, reward model에 의해 결정된 reward를 생산하고 에피소드를 끝낸다. 또한 reward model의 over-optimization를 완화시키기 위해 각 토큰에 SFT 모델의 per-token KL penalty를 추가한다. Value 함수는 RM으로부터 초기화된다. 이러한 모델들을 “PPO”라고 부른다.
또한 공공 NLP 데이터셋에 대한 성능 회귀를 고정하기 위해, pretraining gradients를 PPO gradients와 섞는 실험을 한다. 이러한 모델들을 “PPO-ptx”라고 부른다. RL 훈련에서 다음의 합쳐진 목적 함수를 최대화한다:
와 는 KL penalty의 강도와 pretraining gradients를 각각 통제한다. PPO 모델의 경우 는 0으로 설정되어있다. 달리 명시되지 않는 한, 본 논문에서 Instruct GPT는 PPO-ptx 모델을 참조한다.
Baselines
PPO 모델의 성능을 SFT 모델과 GPT-3에 비교한다. 또한 Instruction-following mode로 GPT-3를 “프롬프트”하기 위해 few-shot prefirx가 제공될 때의 GPT-3와도 비교한다(GPT-3-prompted). 이 prefix는 사용자 특정의 instruction 앞에 붙는다.
게다가 다양한 NLP tasks들로 구성되고, 각 task에 대한 자연어 instruction과 합쳐진 FLAN&T0 데이터셋에 대해 InstructGPT를 fine-tuning 175B GPT-3를 비교할 것이다(데이터셋들은 포함된 NLP 데이터셋과 사용된 instruction의 스타일이 다르다). 그들을 약 1 million 예시들에 대해 각각 fine-tuning하고, validation set에 대해 가장 높은 reward model 점수를 얻은 checkpoint를 골랐다. More detail? Appendix C
3.6 Evaluation
얼마나 모델이 “Aligned” 되었는지 평가하기 위해서는 먼저 여기서 alignment가 무엇을 의미하는지를 명백히 해야한다. Alignment가 모호하고, 헷갈리는 주제지만 여기서 우리의 목표는 모델이 사용자의 의도와 일치하게 행동하도록 훈련시키는 것이다. 좀 더 실질적으로 우리의 Language Modeling task의 목적에 대해서는, 모델이 helpful, honest, harmless 하면 aligned 되었다고 정의하는 사람과 비슷한 framework를 사용한다.
- Helpful : 모델은 instructions도 따라야하지만, few-shot 프롬프트 또는 다른 해석 가능한 패턴(e.g. “Q: {question}\nA:”)으로부터 의도를 추론해야함. 주어진 프롬프트의 의도가 모호하고 불확실할 수 있기에, labeler의 판단에 의존하고 우리의 주된 metric은 labeler의 선호도 평가이다.
하지만 라벨러는 프롬프트를 만든 사람이 아니기에 실제로 프롬프트가 어떤 의도로 만들어졌는지와 오직 프롬프트를 읽기만 하고 프롬프트의 의도를 라벨러가 생각한 것에 차이는 있을 수 있다.
- Honesty : 모델의 “실제 출력”과 옳은 출력에 대한 모델의 “믿음”을 비교해야하는데, 모델은 큰 블랙박스이기 때문에 모델의 믿음을 추론할 수 없다(그래야 정직한지 알지요~).
“세계에 대한 모델의 진술이 사실인지”(Truthfulness)를 측정하기 위해 2가지 metric을 이용한다:
(1) Closed domain tasks에서 정보를 꾸며내는 모델의 경향을 평가 (Hallucination)
(2) TruthfulQA dataset을 이용
이렇게 하는 것이 “Truthfulness”이 실제로 의미하는 것의 오직 작은 부분만을 포착할 뿐인 것을 알고 있다.
- Harmless : Language Model으로부터의 “harm”은 출력이 실제 세계에서 어떻게 쓰이는지에 달려있다.
( e.g. 배포된 챗봇에서 Toxic 출력들을 생성하는 것은 “harmful” 할 수 있다. 하지만 더 정확한 toxicity detection 모델을 훈련시키기 위한 데이터 증강에 사용된다면 이는 도움이 될 수도 있다. )
이전의 프로젝트에서는 labelers에게 “잠재적으로 해로운가”를 평가하도록 했지만, 이는 고찰이 너무 필요하기에 더이상 이렇게 하지 않기로 했다.
그러므로 배포된 모델의 행동 중에 해로울 수 있는 다양한 측면을 포착하려고 더 구체적인 proxy criteria들을 사용한다:
사용자를 도와주는 측면에서 출력이 부적절한지, 출력이 보호 계층을 폄하하는지, 출력이 성적이거나 폭력적인 내용을 포함하는지를 labeler가 평가한다. 또한 bias와 toxicity를 측정하기 위해 의도된 데이터셋(RealToxicity & CrowS-Pairs와 같은)에 대해 모델을 벤치마킹한다.
요약하면, Quantitative 평가를 두 부분으로 나눌 수 있다:
Evaluations on API distribution
주된 metric은 훈련 배포처럼 같은 소스에서 나온 held out set of prompts에 대한 사람 선호도 평가이다. 평가를 위해 API로부터의 프롬프트들을 사용할 때, 훈련 동안에는 포함되지 않았던 프롬프트들만 선택한다. 그러나 주어진 훈련 프롬프트들ㄹ은 InstructGPT 모델들과 사용되게 설계되었고, GPT-3 baseline에는 불리할 수 있다. 그래서 API에서 GPT-3 모델에 제출된 프롬프트들에 대해서도 평가를 한다; 이 프롬프트들은 일반적으로 “instruction following” 스타일이 아니고, 특히 GPT-3를 위해 만들어졌다. 두 가지 경우에서, 각 모델에 대해 해당 모델의 출력이 baseline policy보다 선호되는 빈도를 계산한다; 175B SFT model을 baseline 으로 선택한다. 왜냐면 이 모델의 성능이 중간 정도 하니까. 추가적으로 labelers에게 각 대답에 대한 전반적인 퀄리티를 1-7 Likert scale로 판단하고 각 모델 출력에 대한 다양한 메타데이타를 수집해달라고 요청했다.
Evaluations on public NLP datasets
공공 데이터셋의 2가지 타입들에 대해 평가했다:
- Language Model Safety, particularly truthfulness, toxicity, bias의 측면을 포착하는 데이터셋
- zero-shot 성능을 포착하기 위한 QA, reading comprehension, summarization과 같은 전통적인 NLP tasks
또한 RealToxicityPrompts dataset에 대해 toxicity의 사람 평가를 수행했다.
느낀점
강화 학습의 목적 함수 부분은 느낌은 알겠는데 정확히는 잘 모르겠다. 강화 학습에 대해 공부를 아직 안해 보아서 그런 것 같다.
현재 책을 빌렸고~ 강화학습을 공부할 예정이라, 공부를 해보고 다시 한 번 봐봐야겠다!
그리고 처음 읽을 때는 무슨 말인지 모르고, 이해하기 어려웠는데
이는 번역을 중심으로 논문을 읽어서 그런 것 같다.. 그리고 Figure 참고를 잘 안하고, 문장으로 이해를 끝내기 위해 이해되지 않은 문장을 계속 잡고 있어서 오래 걸린 것 같다.
전체적으로 쑥 훑고, Figure를 잘 활용한다면 전체적인 맥락을 기준으로 잘 이해될 것 같다.
이 논문도 처음에는 어려워 보였지만, 마지막에 다시 한 번 쑥 읽어보며 Velog에 정리를 하니 어떤 메커니즘인지 이해를 할 수 있었다!
