Paper review[LLM in a flash: Efficient Large Language Model Inference with Limited Memory]
논문리뷰
paper : https://arxiv.org/pdf/2312.11514
@ efficient inference
Abstract
배경: 한정적인 DRAM capacity를 가진 devices에서 LLM을 사용하는 것이 힘듦
방법: Model Parameter를 flash memory에 저장하며, 이용 가능한 DRAM의 크기를 초과하는 LLM을 효율적으로 실행
두 분야에 대해 최적화:
- Flash로부터 전송되는 data의 크기를 줄인다.
- 더 크고 연속적인 청크의 데이터를 읽는다.
Hardware-informed framework 안에서 두 가지 주요한 기술 소개:
- Windowing : 이전에 활성화되었던 뉴런을 재삿용하여 데이터 전송을 전략적으로 줄인다.
- Row-column bundling(flash memory의 시퀀셜 데이터 액세스 강도에 맞게 조정된) : Flash memory에서 읽은 데이터 청크의 크기를 늘린다.
Introduction
표준 방법) Inference 할 때, 전체 모델을 DRAM으로 로드 → 돌아갈 수 있는 모델의 크기를 매우 제한함
해결 방법) Model parameter를 DRAM보다 몇 배는 큰 Flash memory에 저장 → Inference 동안, 필요한 parameter의 subset을 바로 로드 → DRAM에 전체 모델을 맞춰야 하는 것을 피함
Contributions
- 저장 시스템에 대한 hardward 특성 연구 : Flash에서 LLM을 서비스하기 위한 효율적인 알고리즘을 설계할 때, capacity & bandwidth와 같은 하드웨어 제약이 상당한 고려사항을 가질 수 있음을 보여줌
- 아래를 도와줄 수 있는 몇몇 기술 소개:
- 필요한 데이터 전송 줄이기
- 전송 처리량 늘리기
- DRAM에서 로드된 parameters를 효율적으로 관리
- 제안된 기술이 device의 DRAM capacity보다 2배 큰 모델을 실행할 수 있고, inference 속도 향상을 보여줌.
2. Flash Memory & LLM inference
메모리 저장 시스템(e.g., flash, DRAM)의 특성, LLM inference에 대한 메모리 저장 시스템의 영향 연구
2.1 Bandwidth and Energy Constraints
요즘 NAN flash memory : 높은 bandwidth & low latency
그러나 지연율과 처리량 측면에서 DRAM 성능 수준에 미치지 못한다.
NAND 플래시 메모리에 의존하는 단순한 추론 구현은 각 forward pass에 대해 전체 모델을 reloading 해야 할 수 있다 → 이 과정은 시간이 많이 소요되며, 압축된 모델도 몇 초가 걸릴 수 있음. 또한 이 과정은 DRAM에서 CPU나 GPU의 내부 메모리로 데이터를 전송하는 것보다 더 많은 에너지를 소비
‘모델 로딩 시간’은 초기에 DRAM에 model을 상주시키는 전통방식에서도 문제가 될 수 있음 → 특히, 첫 토큰에 대한 빠른 반응이 필요한 경우(전체 모델을 처음 loading하는데 시간이 걸리니까, 첫 토큰이 빠르게 나오지 않을 수 있음)
논문에서의 해결 방안) LLM에서 activation sparsity를 활용해서 이러한 문제 해결 → 모델 weight를 선택적으로 읽어서 response latency를 줄여준다.
2.2 Read Throughput
Flash memory system의 성능은 큰 순차적 읽기 작업에서 최적화되지만, 작은 랜덤 읽기에서는 성능이 저하됨 → 작은 랜덤 읽기는 여러 단계를 거치는 다단계 과정 때문 & 각 단계는 지연을 발생시키며, 특히 작은 읽기 작업에서 그 영향이 비례적으로 커진다.
이러한 한계를 피하기 위해 함께 사용할 수 있는 두 가지 주요 전략 주장:
-
“더 큰 데이터 청크를 읽기”
문제) 작은 블록 같은 경우, 전체 read time에서 상당한 부분이 데이터 전송이 시작되는 것을 기다리는데 사용됨.
해결) FFN 행렬의 행과 열에 대한 읽기를 통합 → 주어진 행/열 쌍에 대해 한 번만 latency cost을 지불하고, 더 높은 처리량을 실현할 수 있음.
아마도 반직관적이지만 흥미로운 관찰은 일부 시나리오에서는 필요한 부분만 읽는 것이 아니라 더 큰 덩어리로 읽는 것이 더 가치가 있다는 것입니다.
-
“병렬화 된 읽기 활용” → storage stacks와 flash controllers의 고유한 병렬성 활용
Sparse LLM inference에 적합한 처리량은 멀티 스레드를 통해 최신 하드웨어(32kiB 이상의 랜덤 읽기를 사용하는)에서 달성할 수 있음.
3. Load From Flash
Section 2에서의 문제들에서 동기 부여가 되어, Inference speed를 증가시키기 위해 “데이터 전송 크기 최적화” & “읽기 처리량 증가” 방법들을 제안.
다양한 Flash Loading 전략을 평가하기 위한 주요 metric : Latency
Metric ‘Latency’ 세분화:
- Flash에서 로딩하는 I/O 비용
- 새로 로드된 데이터 데이터로 메모리를 관리하는데 드는 overhead
- Inference operation을 위한 computing cost
메모리 제약 조건 하에 지연 시간을 줄이기 위해 제안된 솔루션은 다음 부분으로 분류:
- Reducing Data Load: 더 적은 데이터를 로드하면서 flash I/O operation과 관련된 latency를 줄인다.
- Optimizing Data Chunk Size: 로드된 데이터 청크의 크기를 늘려서 flash 처리량을 증가시켜 latency 완화.
- Efficient Management of Loaded Data : 데이터가 메모리에 로드된 후 이를 관리하는 과정을 간소화하여 오버헤드를 최소화
논문의 focus는 계산 최적화가 아니다 → 메모리 제한적인 기기에서 효율적인 inference를 달성하기 위해 논문은 ‘flash memory interaction 최적화’와 ‘메모리 관리’에 초점을 두고 있다.
3.1 Reducing Data Transfer
FFN model에서 발견되는 고유한 activation sparsity 활용
예) OPT 6.7B 모델은 FFN 층에서 97%의 희소성을 보인다.
이러한 정보를 바탕으로, 논문의 접근 방식은 inference 중 processing을 위해 flash memory에서 DRAM으로 오직 필수적이고 동적인 가중치의 부분 집합만을 반복적으로 전송하는 것을 포함한다 → 전체 weights를 가지고 오는게 아니라 쓰이는 weights만 전송
Selective Persistence Strategy
본 논문에서는 Transformer attention 메커니즘에 사용되는 매트릭스와 embedding을 DRAM에 항상 유지하는 것을 선택
FFN 부분에서 오직 non-sparse 부분만 필요에 따라 동적으로 DRAM에 로드됨.
모델 사이즈의 1/3을 구성하는 attention weights를 메모리에 유지하는 것은 더 효율적인 계산과 더 빠른 액세스가 가능해짐 → 전체 모델 로딩에 대한 필요 없이 inference 성능을 향상시킬 수 있음
Anticipating ReLU Sparsity
ReLU 활성화 함수는 자연스럽게 FFN의 중간 출력에서 90% sparsity를 유도 → 이러한 sparse outputs를 활용하는 그 이후 layer의 memory footprint를 줄여줌.
그러나 activation 이전인 Up project layer는 모두 메모리에 있어야 한다.
(설명: FFN은 up-project layer → activation → down-project layer 로 구성되어 있기에 activation 이전 layer는 up-project layer. Down projection layer에서는 activation layer 이후 intermediate output으로 0이 나온 부분과 계산되는 부분을 load하지 않아도 되지만, up-project layer는 전체 다 로드해야 한다는 것)
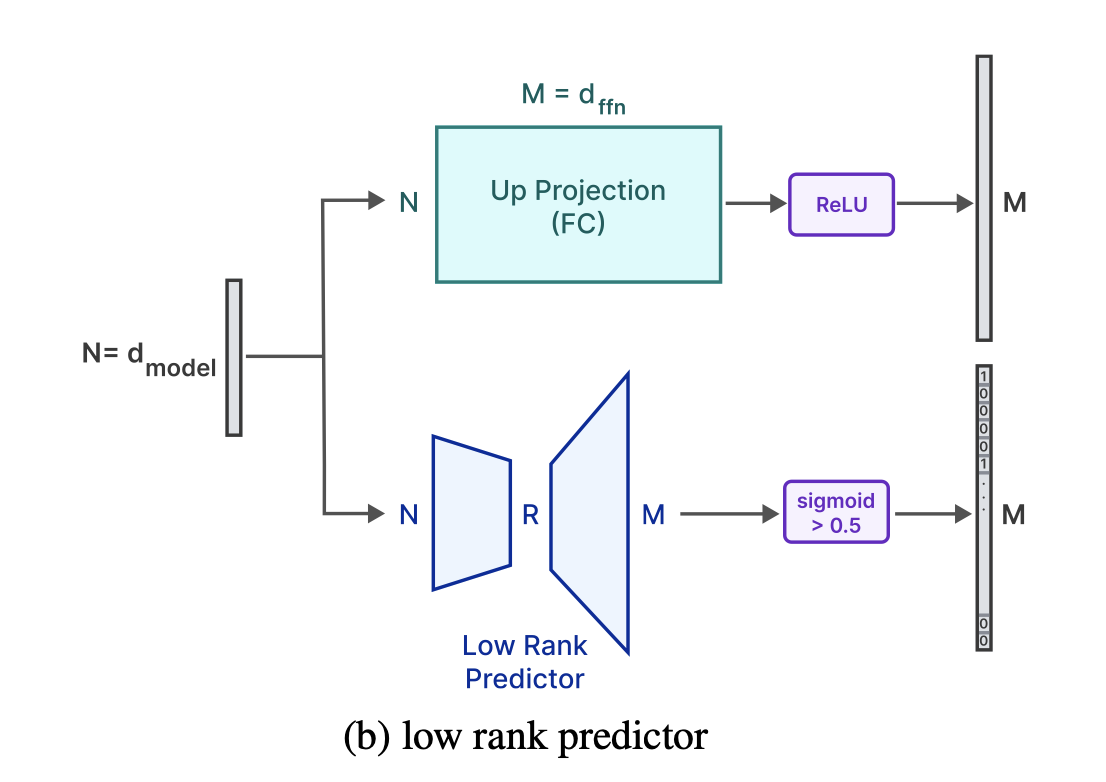
전체 up-projection matrix를 불러오지 않게 하기 위해 Low-rank predictor를 사용해 ReLU에 의해 0이 되는 요소들을 식별(”Deja vu: Contextual sparsity for efficient LLMs at inference time” 논문 따름)
본 논문에서는 각 layer의 negative, positive samples에 대해 균형잡힌 loss를 사용함.
본 논문의 predictor는 현재 layer의 attention module의 출력만 필요함(이전 layer의 FFN module의 출력은 필요 없음)
예측을 '현재 layer'까지 연기시키는 것은 hardware-aware weight-loading 알고리즘 디자인에 충분하고, 연기된 입력 덕분에 더 정확한 결과를 이끈다
→ 이전 논문에서는 해당 layer 전의 FFN layer의 결과를 토대로 up projection의 값을 prediction 한 것 같음. 그러나 이 결정을 본 논문에서는 해당 layer의 attention module의 출력을 바탕으로 하게 됨. 이는 하드웨어 가중치 로딩 알고리즘에서 메모리적으로 문제가 없고, 이전 층의 output을 사용하지 않고 해당 층의 attention module의 output을 활용하니 정확도가 증가했다는 것으로 파악
‘Predictor를 사용해도 0-shot task에서 모델의 성능에 부정적인 영향을 끼치지 않는다.’
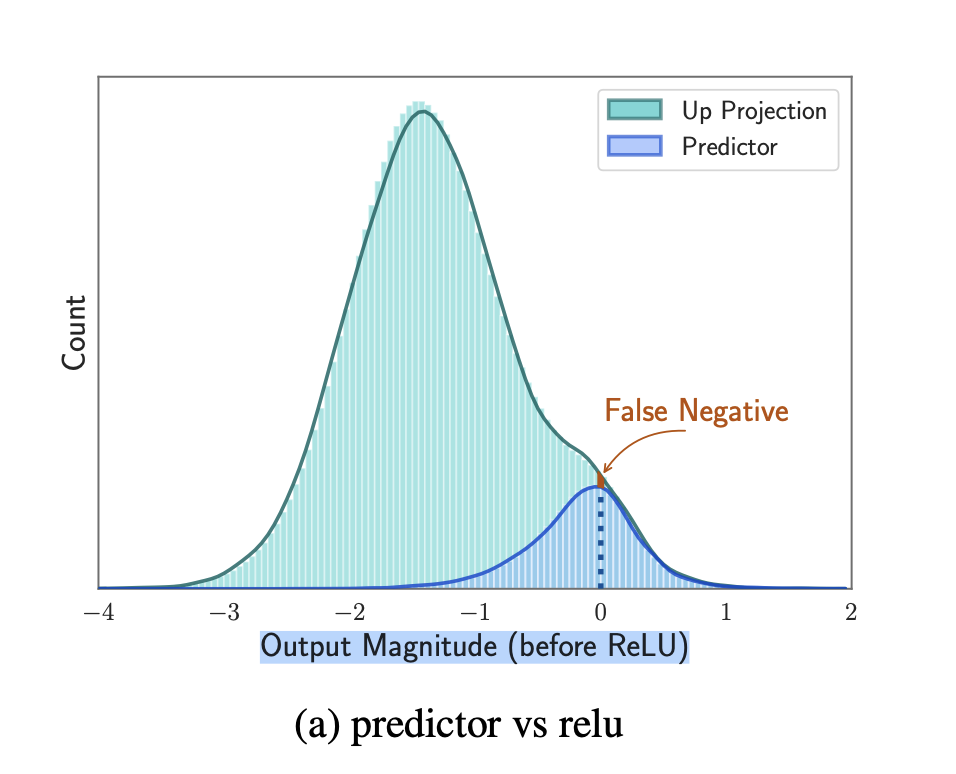
<(a)에 대한 설명>
Green 부분이 up projection을 통해 나온 값, Blue 부분이 predictor를 통해서 나온 값이다. 그러니까 predictor가 not activated라고 판단한 값들은 나오지 않는 것이다.
여기서 False negative는 model은 activate인데 predictor는 not activate로 예측한 것이다 → 그러니까 0~2 에서 green과 blue의 gap이 false nagative라고 볼 수 있다 → 해당 부분은 실제로 모델은 activate 해야되는 값들이지만 predictor가 예측하지 못해서 gap이 생기는 것이니까
얼마나 줄어들까?
예시) Opt 6.7B
Up-projection matrix → (4096, 16384) → 원래 크기: 67,108,864
Predictor Rank : 128(non -sensitive layer; 마지막 4개의 layer를 제외한 나머지 layer → 마지막 4개의 layer는 sensitive layer라고 한다)
Predictor 크기 : (4096, 128) + (128, 16384) → 2,621,440
Predictor가 sparsity가 70%라고 한다면 → Up-projection matrix에서 30%만 load한다.
그러면 메모리 사용량:
원래 : 67,108,864
Predictor 사용: predictor 크기 + activated 된 up-projection matrix(약 30%)
비교) 원래의 70%(46,976,205) vs Predictor 크기(2,621,440) → 무조건적으로 predictor를 사용했을 때 메모리 사용량이 적다!
The Sliding Window Technique
본 논문에서 다음과 같이 정의 → “active neuron” : Low rank Predictor에서 positive output을 산출하는 neuron
Neuron data를 ‘Sliding window technique’을 사용함으로써 관리
이점) 이전 토큰의 neuron을 모두 내리고, 현태 토큰의 neuron을 모두 올리는데 드는 시간을 줄이기 위해서 사용. Latency에 이점을 주기 위해서
Key aspect) Incremental loading → 현재 토큰에서와 이전 토큰에서의 neuron의 차이를 이용한 loading:
설명) 이전 토큰들에서 활성화 되어있는 neuron을 토대로 현재 neuron에서 새롭게 activate 되는 neuron을 추가하고 not activated 되는 neuron을 삭제해주는 방식 → 이전 방식에서는 토큰에서의 neuron을 모두 지우고, 현재 토큰에서의 neuron을 모두 올리는 방식을 사용했는데. 그게 아니라, 차이점을 바탕으로 부분을 업데이트 해주는 방식
요약) 불필요한 unloading & loading을 줄여주며 efficient memory utilization !
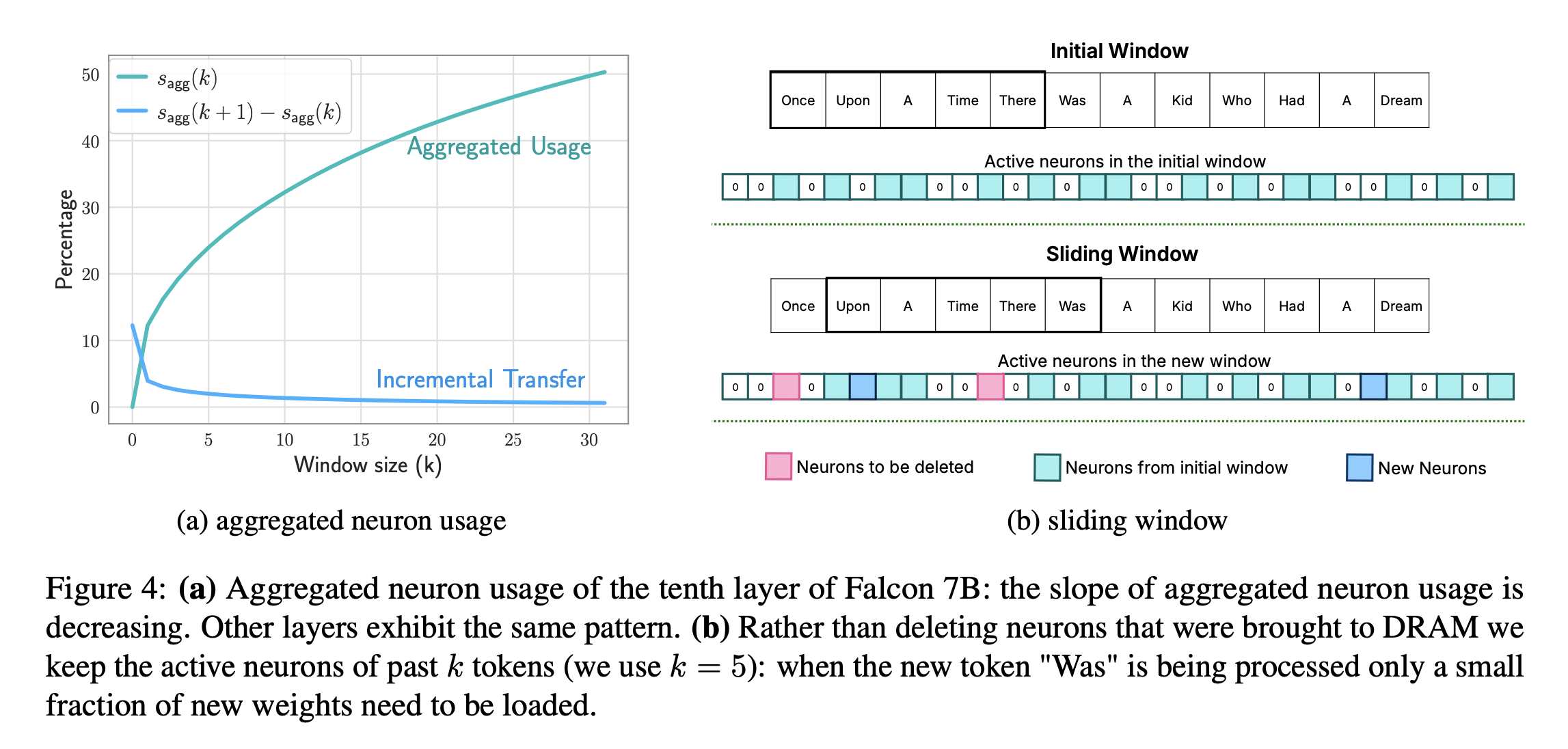
<그림 설명>
(a) : window k 증가 → active neuron(aggregated usage)의 비율이 늘어남 & 다음 토큰이 올 때 update 되는(load & unload) 뉴런의 비율이 줄어듦
(b) : sliding window를 하면서 새로운 토큰이 들어왔을 때, window 밖을 벗어나는 토큰에서 active 한 토큰을 지워주고(분홍색; neurons to be deleted) 새로운 토큰에서 active 한 토큰은 추가해준다(파란색; new neurons)
따라서 k개 클수록 update가 줄어듦 but 사용하는 DRAM memory 증가함
Sliding window k 결정 : 제한된 memory capacity 내에서 sliding window k를 최대화 하는 것
3.2 Increasing Transfer Throughput
Flash memory로부터 데이터 처리량을 늘리기 위해, 데이터를 더 큰 청크로 읽는 것이 중요하다.
Bundling Columns and Rows
번째 Intermediate neuron의 activation은 up-projection의 번째 column과 down-projection의 i번째 row의 사용과 일치한다
→ 설명) Predictor이 판단 후, up-projection의 i번째 column이 사용되어야 intermediate neuron의 번째 값이 생성됨(not sparse) & 번째 intermediate neuron이 activated 되어있으면 down-projection의 번째 row가 사용되어 최종 출력을 낸다.
따라서 해당 column과 row를 함께 flash memory에 저장함으로써 데이터를 더 큰 청크로 통합하여 읽을 수 있다. Predictor를 통해 활성화 될 intermediate neuron을 파악한 후, 해당하는 Up proj column & Down proj row를 통합한 bundle Load
방식
기존 방식) load up projection → 계산 → unload up projection → load down projection → 계산 → unload down projection
bundling) load bundling → 계산 → unload bundling
Bundling을 통해서 load & unload 에서 발생하는 overhead를 줄였다.
한 번에 읽어들이는 chunk size:
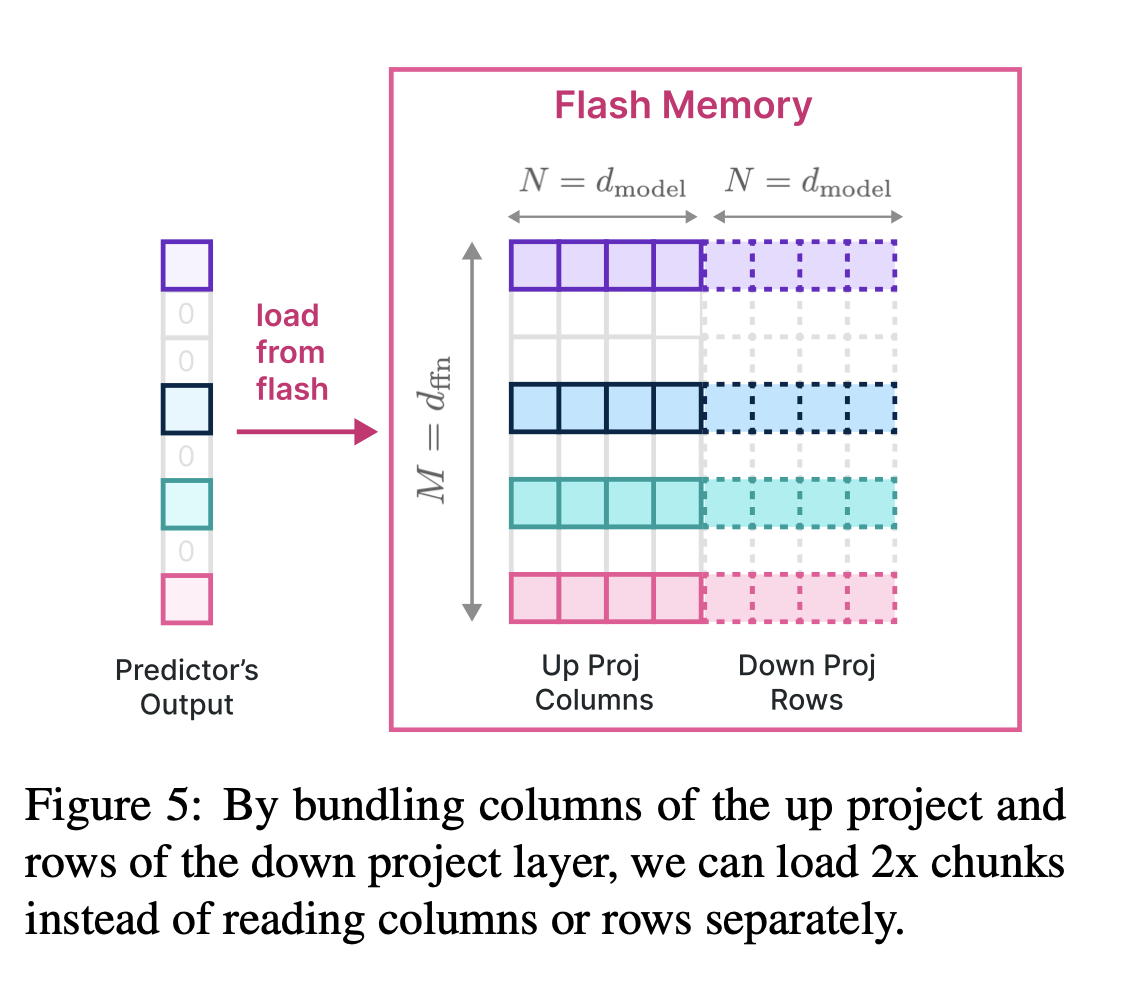
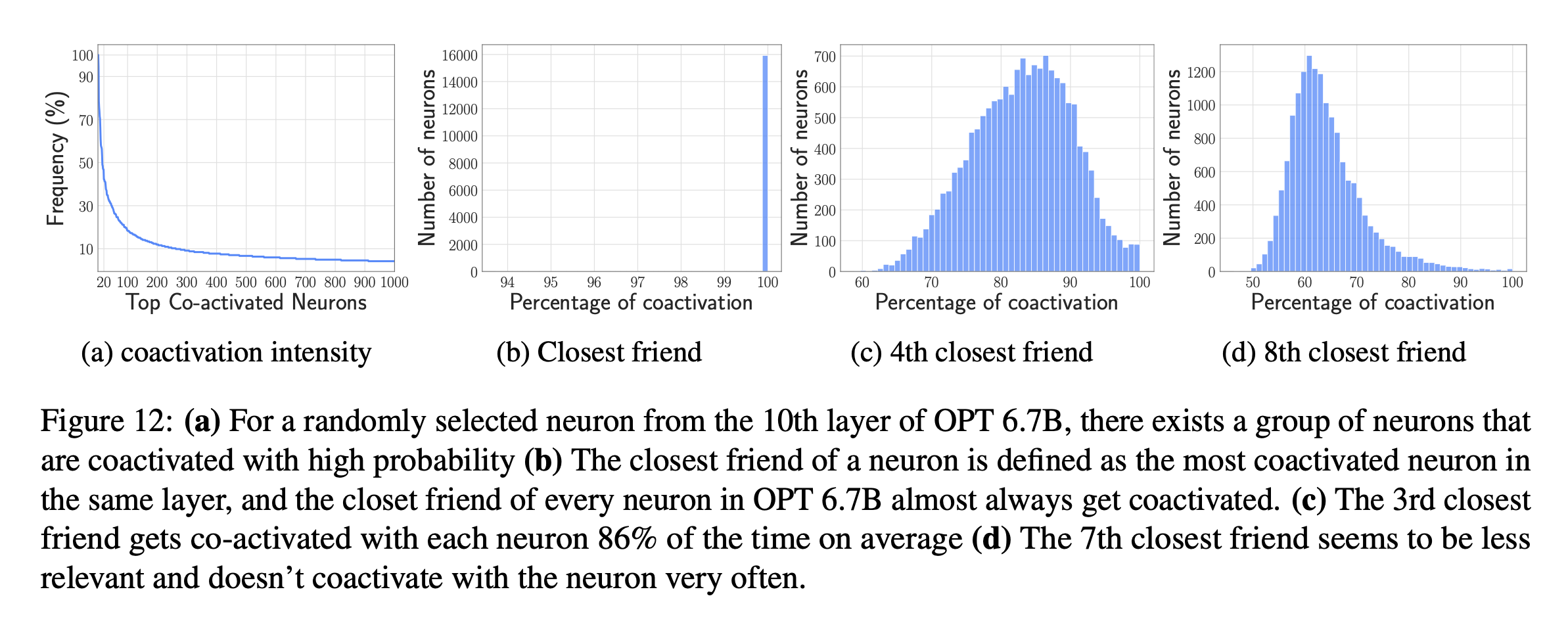
Bundling Based on Co-activation
Neuron에게 상관관계가 높은 activity pattern을 보여 bundling이 가능하게 할 수 있다고 가정을 세웠음.
C4 validation dataset에 대한 activation을 분석한 결과 coactivation의 power law distribution of activations을 발견.
Neuron들에게 그들과 매우 coactivated 한 neuron과 묶게 하면, 잘 active 되는 neuron들을 여러번 loading 하게 된다 → 메모리 효율을 중요시하는 논문의 목표에 반대된다.
매우 active 한 neuron들은 대부분의 neuron들과 가깝다.
이러한 부정적인 결과를 ‘효율적인 inference를 위한 효과적인 neuron bundling’에 대한 미래 연구에 제시.
3.3 Optimized Data Management in DRAM
DRAM 안에서 데이터 전송이 flash memory에 접근하는 것보다 효율적이지만, 여전히 무시할 수 없는 비용 발생
매트릭스 재할당 & 새로운 매트릭스 appending 은 상당한 overhead를 초래한다 (DRAM 안에 존재하는 neuron data를 다시 써야 하기 때문) → 상당한 부분(약 25%)이 Rewritten 되어야 하면 비용이 많이 든다.
해결하기 위한 방법 ⇒ 모든 필요한 메모리 preallocation & 효율적 관리를 위한 해당 데이터 구조 구축
( 데이터 구조 구성: )
- 의 각 row : concat(column of up-project, row of down-project)
- vector : matrix의 각 row에 해당하는 original neuron index를 가리킴
- : Original model 안의 up project의 bias (Original model 안에서 Up project의 bias : 해당 element에 표시됨)
- parameter : 현재 matrix에서 활용되고 있는 row의 수 (처음엔 0으로 초기화)
- : 최근 k개의 토큰을 사용해서 활성화 된 neuron 식별
번째 layer에서의 는 로 preallocated 됨 ( : C4 validation set의 subset 안에서 특정 window size에 필요한 neuron의 최대 수) → 각 layer에 미리 충분한 preallocation을 통해 reallocation의 필요성을 최소화
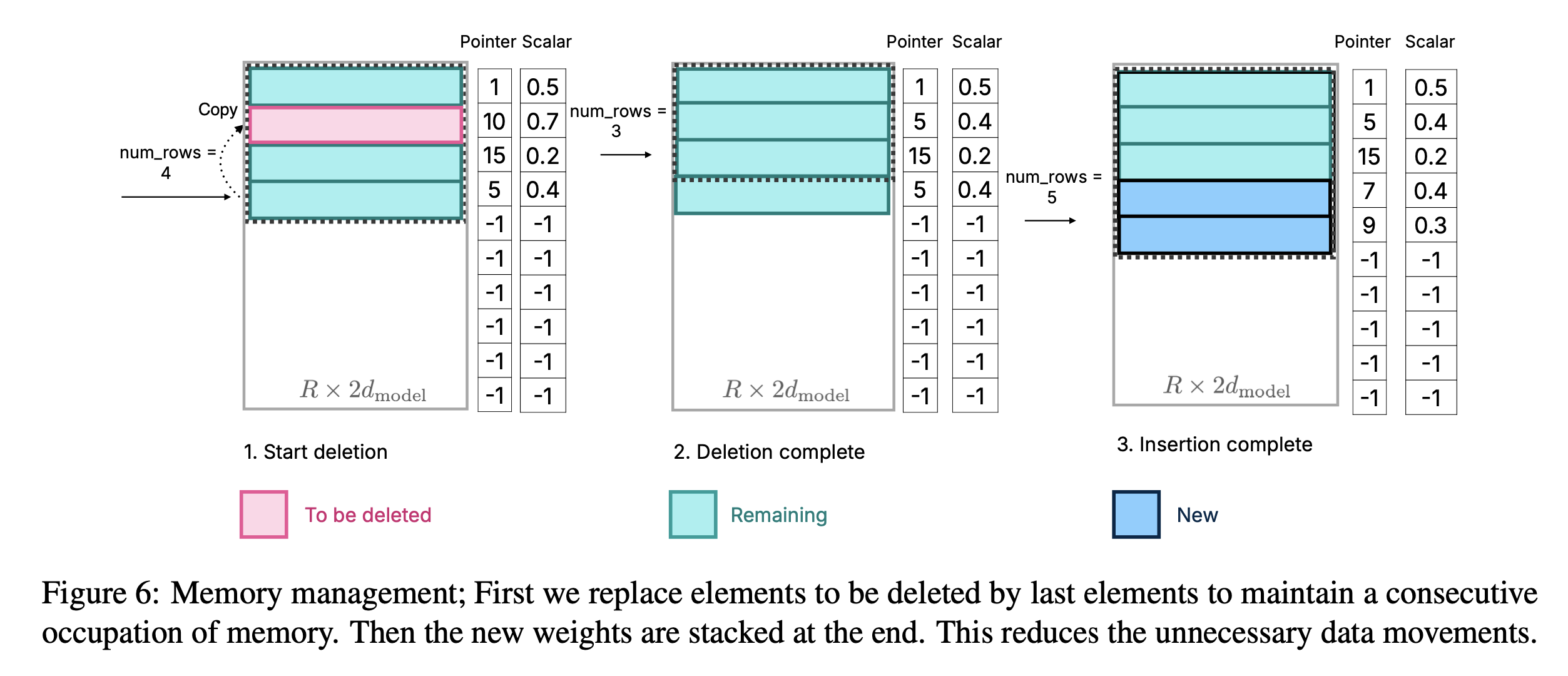
1. Deleting Neurons
더이상 필요하지 않은 neuron은 값과 현재 prediction을 활용하여 linear time에 효율적으로 식별됨. 중복된 neuron의 Matrix, pointer, scalars은 가장 최근 element에 대체된다.
위 Figure 6을 봐보자)
필요 없어진 neuron의 matrix, pointer, scalars는 가장 최근의 element로 대체된다. 그리고 num_rows에서 불필요해진 neuron의 수를 뺀다.
→ 불필요해진 것을 없애주고, 아직 사용 중인 것들을 불필요해진 것의 자리에 넣어주며 위로 정렬을 한다. 그리고 아직 사용중인 것들은 별도로 삭제해주지 않으며 삭제 overhead를 줄여주며, num_rows를 활용하여 사용되는 row들을 말해준다. 의 neuron이 삭제될 때, 만큼의 memory rewrite 가 필요.
Bringing in New Neurons
필요한 weights는 flash memory로부터 검색되어짐. 해당 pointer, scalars가 DRAM으로부터 읽히고, 해당 rows가 matrix로 삽입되며, num_row를 num_row + num_new로 늘려준다.
이 approach의 장점: DRAM 안에서 memory reallocating & 기존 데이터 복사의 필요성을 없애줌 → inference latency를 줄여줌
Inference Process
Inference operation에서 matrix의 첫 반 이 ‘up project’로 사용 & 남은 반은 transpose 해서() down project로 사용
이 구성이 가능한 이유: FFN의 intermediate output 안의 neurond 순서가 최종 output을 바꾸지 않기 때문.
그리고 추론 과정 간소화를 해줌.
모르는 점)
Figure 6에서 Scalar가 의미하는 것이 무엇인지 모르겠다.
느낀점
LLM Inference Optimization/Acceleration에 관련된 논문을 읽고 싶어서 찾아보다가 발견했다.
하드웨어적인 내용에 치중되어 있어서 읽지 말까 고민했지만, ACL 2024에 게재되어 있었기에 읽었다. 이해가 비교적 잘 되었던 것 같다.
