Paper review[KV Quant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization]
논문리뷰
배경
- Long context window가 필요한 어플리케이션이 많이 생김 → Inference 시, KV cache가 메모리 사용량의 주요 원인으로 떠오르고 있다
- LLM inference 시, 작은 배치에서는 memory bound(메모리 병목): 계산 자체보다 memory I/O에 시간이 더 많이 걸린다는 의미
- 짧은 context의 경우, 모델 가중치가 문제(메모리 사용량, memory bandwidth). 그러나 long context를 다루는 경우, KV cache가 문제
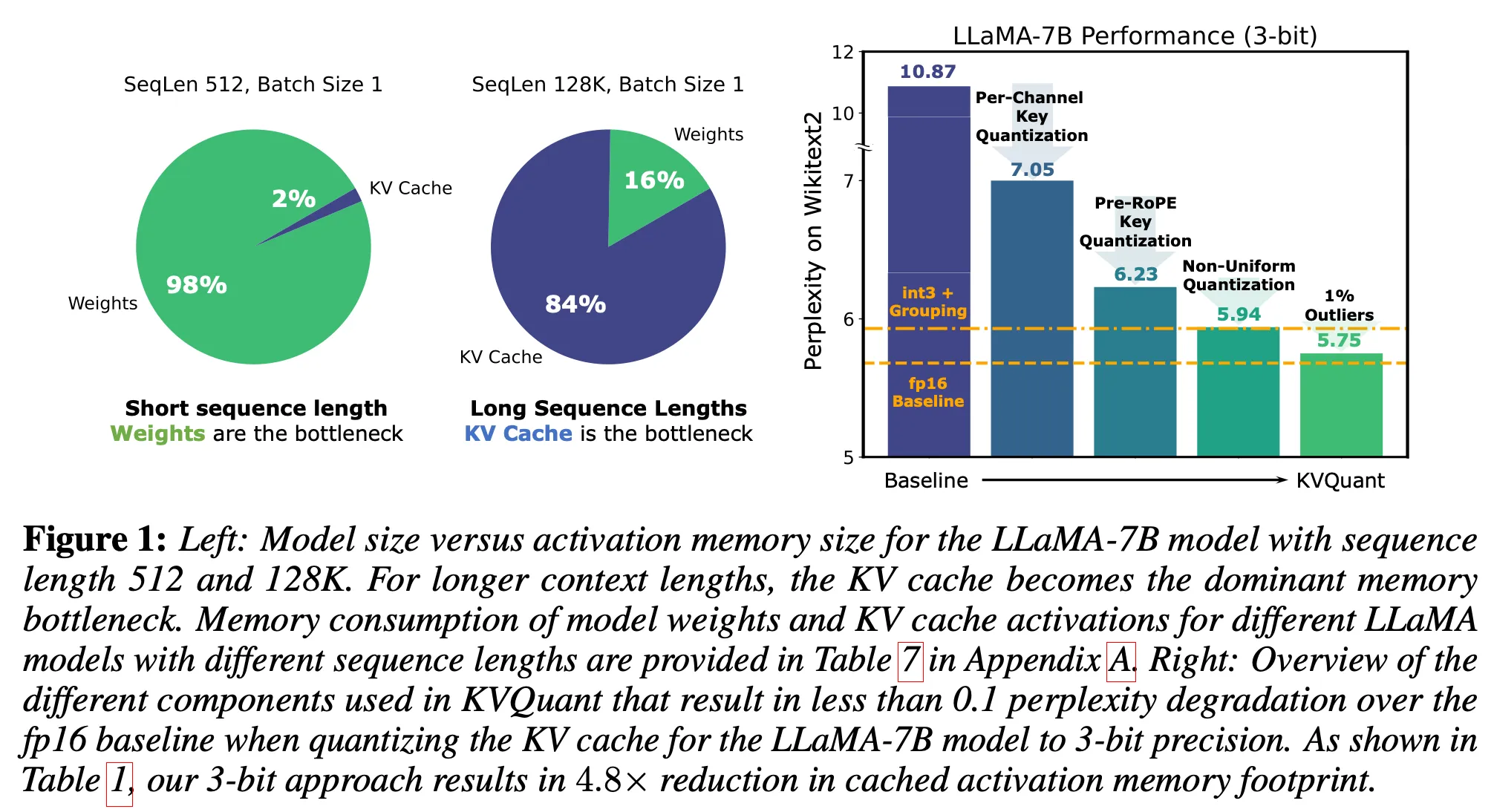
- 기존의 방법들: Accuracy 감소 초래(KV cache activations의 outlier structure & suboptimal bit allocation(기존의 uniform & non-unifrom approaches); suboptimal bit allocation 예시: 어떤 부분에서는 더 높은 정밀도가 필요할 수 있는데 동일한 bit로 quant해 정확도가 떨어지는 경우)
의의
- 3bit quantization을 LLaMA, LLama-2, LLaMA-3, Mistral model에 적용했을 때, 0.1 미만의 perplexity 감소 발생(Wikitext-2 and C4에 대해)
- LLaMA-7B 모델의 경우, 최대 1 million context length까지 1개의 A100-8GB GPU에서 처리 가능 & 8개의 GPU를 사용하는 시스템에서는 10 millions 까지 처리 가능
- KV Quant 맞춤형 Cuda 커널 개발 → 기본 FP16 matrix-vector multiplication에 비해, 최대 1.7배 속도 향상(LLaMA-7B 기준)
방법론 Overview
- Per-channel Key Quant: 분포에 알맞게, dimension 별 quantization 조절
- Pre-ROPE Key Quantization: ROPE 전에 Key Activations에 대해 quantization 진행
- None-Uniform KV cache Quantization: Layer 별 sensitivity에 따라 자신에 맞는 서로 다른 bit의 datatype 사용
- Per-Vector Dense-and-Sparse Quantization: 벡터 별로 이상치를 분리하여 quantization 범위 왜곡 최소화
방법론
1. Per-Channel Key Quantization
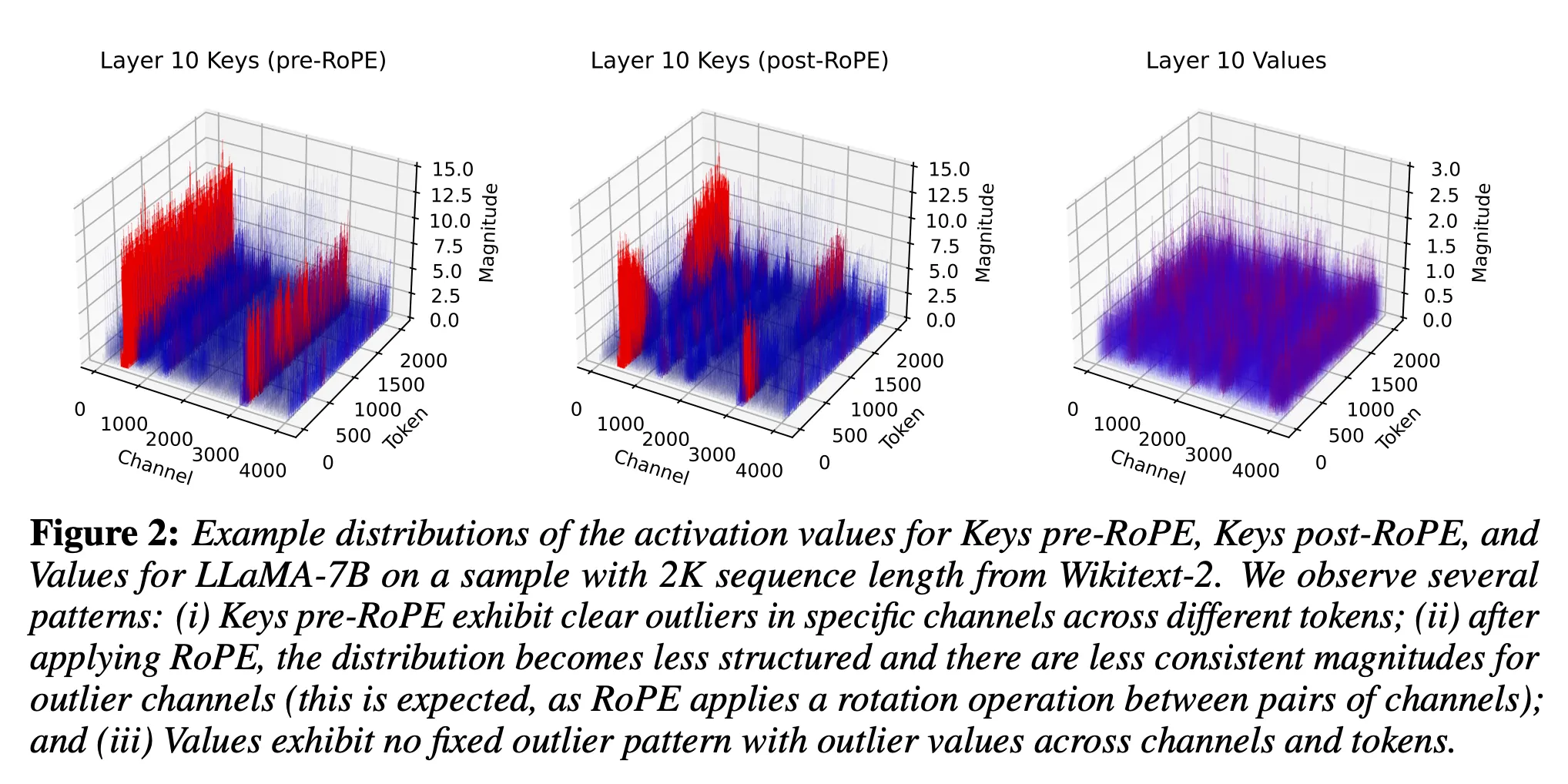
<KV cache distribution> Key matrix를 보면, 뚜렷한 outlier channel을 가짐
- 기존 KV cache quantization:
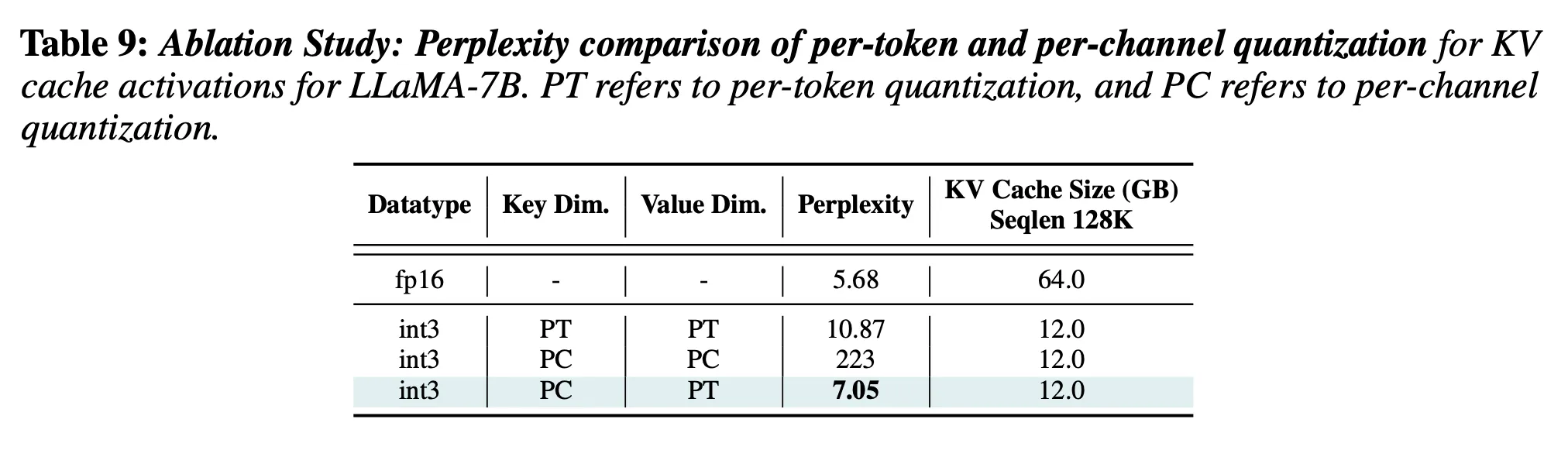
- 방법: per-token quantizaiton 사용(같은 토큰 내에서 scaling factor & zero-point를 공유하며 quantization)
- 단점: Channel 간의 평균 크기가 다르기에 quantization 하기 힘들다(토큰 별 차이보다 채널 별 차이가 더 크다)
- 개선: Per-token quantization이 아니라 per-channel quantization 진행
확실히 위의 distribution을 보았을 때, per-token quantization보다 per-channel quantization(같은 채널 내에서 scaling factor & zero-point를 공유하며 quantization)이 더 적합해 보인다.
하지만 Key와는 달리 Value에는 per-channel quantization이 효과적이지 않음
이 때, per-channel quantization에서는 fp16 zeropoint (low-precision X)만 사용 / 이유: 만약에 채널의 모든 값이 양수거나 음수이면, 0을 표현할 수가 없다(ex. 모든 음수를 [-128,127]에 mapping하면, 기존의 0은 해당 범위를 벗어날 것. 그렇기에 zero-point는 이런 경우에서도 표현할 수 있게 fp16으로 표현)
결과적으로 ‘Key: per-channel & Value: per-token’을 사용했을 때, perplexity가 7.05로 기존(per-token & per-token)보다 3.82 감소했다(성능 개선).
하지만 이런 per-channel quantization은 runtime overhead를 초래
- Quantization dimension과 Reduction dimension이 일치하지 않아서 → Section 4.4에서 효율적으로 quantization 하여 Query-Key matrix multiplication에서 추가 overhead 발생하지 않는 방법을 보여줌
- Channel 별로 quantization을 진행하게 된다면, KV cache가 추가될때마다 다시 scaling을 계산해야 하기 때문에 → Offline에서 scaling factor를 calibration하여, online에서 재계산을 피함
Per-channel key quantization을 사용한 이전 연구와 본 논문 비교)
- 이전 연구(Kivi: Plug-and-play 2bit kv cache quantization with streaming asymmetric quantization)
- 큰 값들을 가진 channel들을 grouping하여, quantization 진행
- 세밀한 그룹화(fine-grained grouping) 과정이 필요함
- 완전한 quantization을 하지 않고, 일부 캐시는 fp16으로 유지하는 방식을 사용함
- 본 논문
- Offline calibration을 통해 grouping 없이 per-channel quantization 수행
2. Pre-RoPE Key Quantization
Rotary embedding란) Query와 Key vector에 position-dependent rotations을 곱해주어, 위치 정보를 넣어주는 것( )
Key vector를 caching 할 때, 위치 정보가 없는 Key vector()를 caching 하거나 위치 정보까지 포함된 Key vector()를 caching 해야한다.
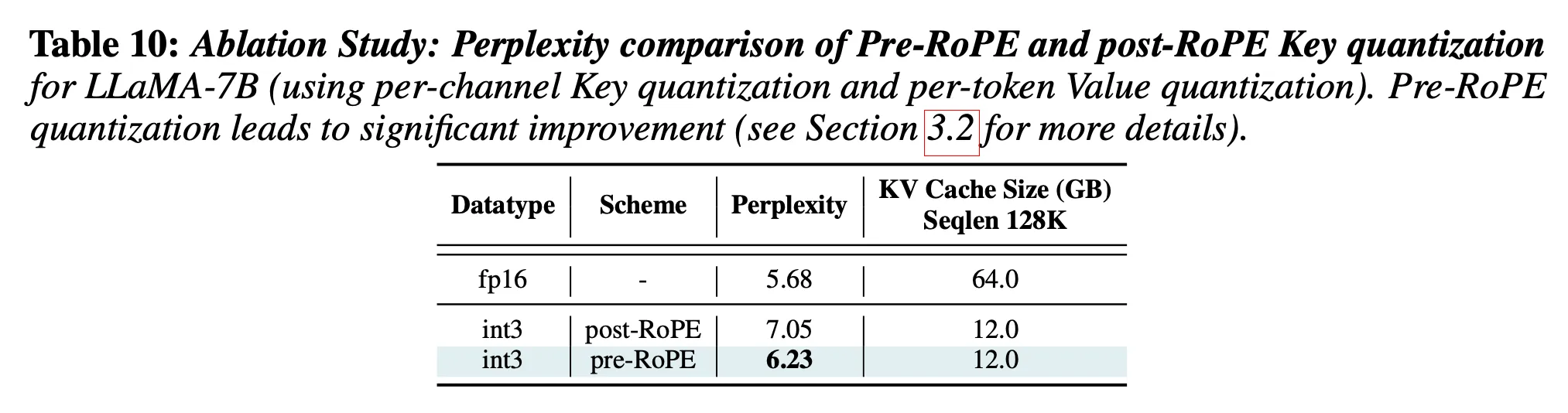
RoPE 전에 key quantization을 하는 이유)
- RoPE를 적용한 Key 벡터를 캐싱하면, 토큰의 위치마다 채널 값이 다르게 변형됨 → 같은 채널이라도 토큰 위치에 따라 값이 달라져 일관성이 약해짐
- 위의 Figure 2에서 확인 가능:
- Pre-ROPE: 채널별 activation 크기가 비교적 일정
- Post-ROPE: 같은 채널이라도 토큰 위치에 따라 크기가 달라짐
- Quantization은 채널값이 일정할 때, 더 효과적 → Pre-RoPE key Quantization을 수행하는 것이 더 효과적
Pre-ROPE의 효과) 0.82 perplexity 개선
결론) RoPE이 key quantization을 어렵게 만든다
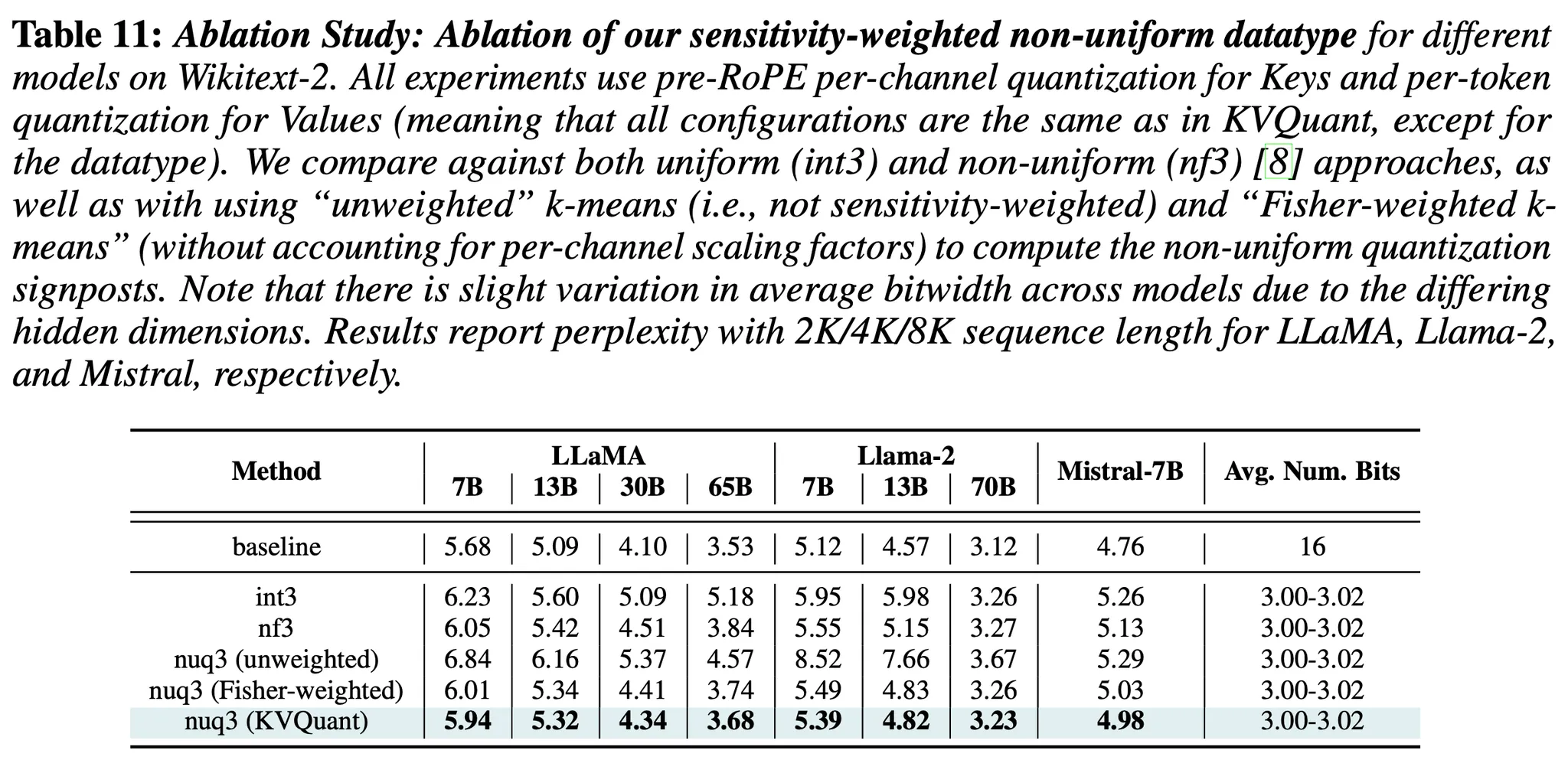
3. nuqX: An X-Bit Per-Layer Sensitivity-Weighted Non-Uniform Datatype
Query & Key activations가 non-uniform이기 때문에, uniform quantization은 KV cache quantization에 suboptimal
Non-uniform quantization의 단점)
- Dequantization overhead 발생
단점 해결)
KV cache loading은 batch size나 sequence length에 관계없이 memory bandwidth → 추가적인 연산이 latency에 영향을 주지 않음(연산 속도가 아니라 메모리 로딩 속도가 주요 병목)
이는 non-uniform quantization으로 인해 발생하는 dequantization overhead는 문제가 되지 않는다는 것을 의미
[Non-uniform quantization 방법]
- 배경) 기존 연구에서의 non-uniform quantization
- Sensitivity-weighted k-means 방법을 사용하여 quantization signposts(양자화 기준점)를 계산함 (sensitive한 데이터에 가중치를 주며, 양자화 구간을 설정하는 방법)
- 하지만 이 방법을 KV cache quantization에 직접 적용할 수 없음 (per-token quantization을 진행하는 Values는 runtime동안 동적으로 quantized 되기 때문)
- Inference 동안, K-means를 online으로 사용할 수 있게 해야 함
- 방법)
- Calibration dataset에 맞는 non-uniform datatype을 offline으로 계산(추론 전에): per-channel(Key), per-token(Value)
- Calibration dataset에 맞춰, sensitivity-weighted quantization signposts를 offline에서 미리 계산
- Per-vector quantization과의 호환성 유지를 위해 quantization 전에 각 채널을 [-1, 1] 범위로 정규화
- diagonal Fisher information matrix를 사용해서, activation A의 quantization error를 최소화하는 방향으로 공식화:여기서 는 activation을 1차원으로 Flatten, 은 calibration set의 모든 elements의 수
- 위 식을 calibration set에 사용하여, key와 value에 대한 non-uniform datatype quantization singnpost을 구함
- 결과)
- 성능적 측면)
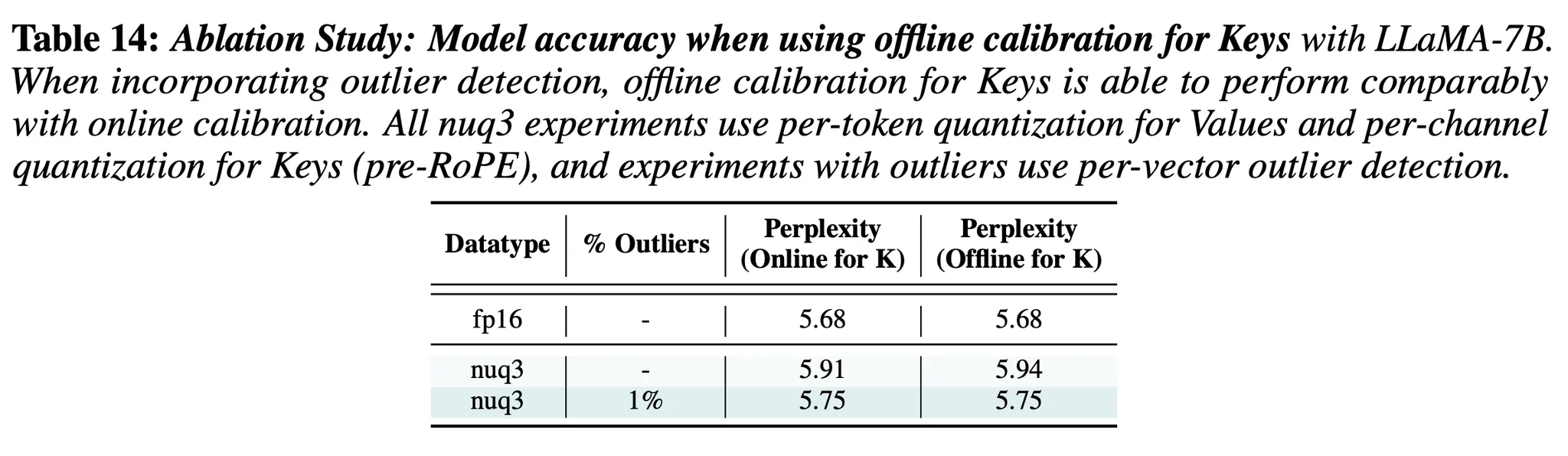
- Calibration set을 통해 Key의 scaling factor를 offline으로 구한 후 했을 때의 결과(성능 감소가 미미함)
- 기존의 uniform & Non-uniform quantization baseline과 본 논문의 방법론과의 비교(3-bit uniform 방법보다 좋은 성능을 보여줌)
- Calibration set을 통해 Key의 scaling factor를 offline으로 구한 후 했을 때의 결과(성능 감소가 미미함)
- Latency 측면) 걸리는 시간이 미미함

- Fisher Information: 어떤 channel이 sensitive한지 체크
- Calibration Per-Layer(including k-means): 해당 bit로 quantization 했을 때, quantization range & scaling factor & signpost를 구함
- 성능적 측면)
4. Per-Vector Dense-and-Sparse Quantization
배경)
- Key, Value의 값들은 대부분 작은 범위 내에 위치(흩뿌려져 있는 것이 아니라 특정 작은 범위 내에 있음) → 조금의 Outlier 처리하면, 전체적인 범위를 제한할 수 있음 → 전체적인 범위를 줄여, 남은 값들을 더 정밀도 있게 표현할 수 있음
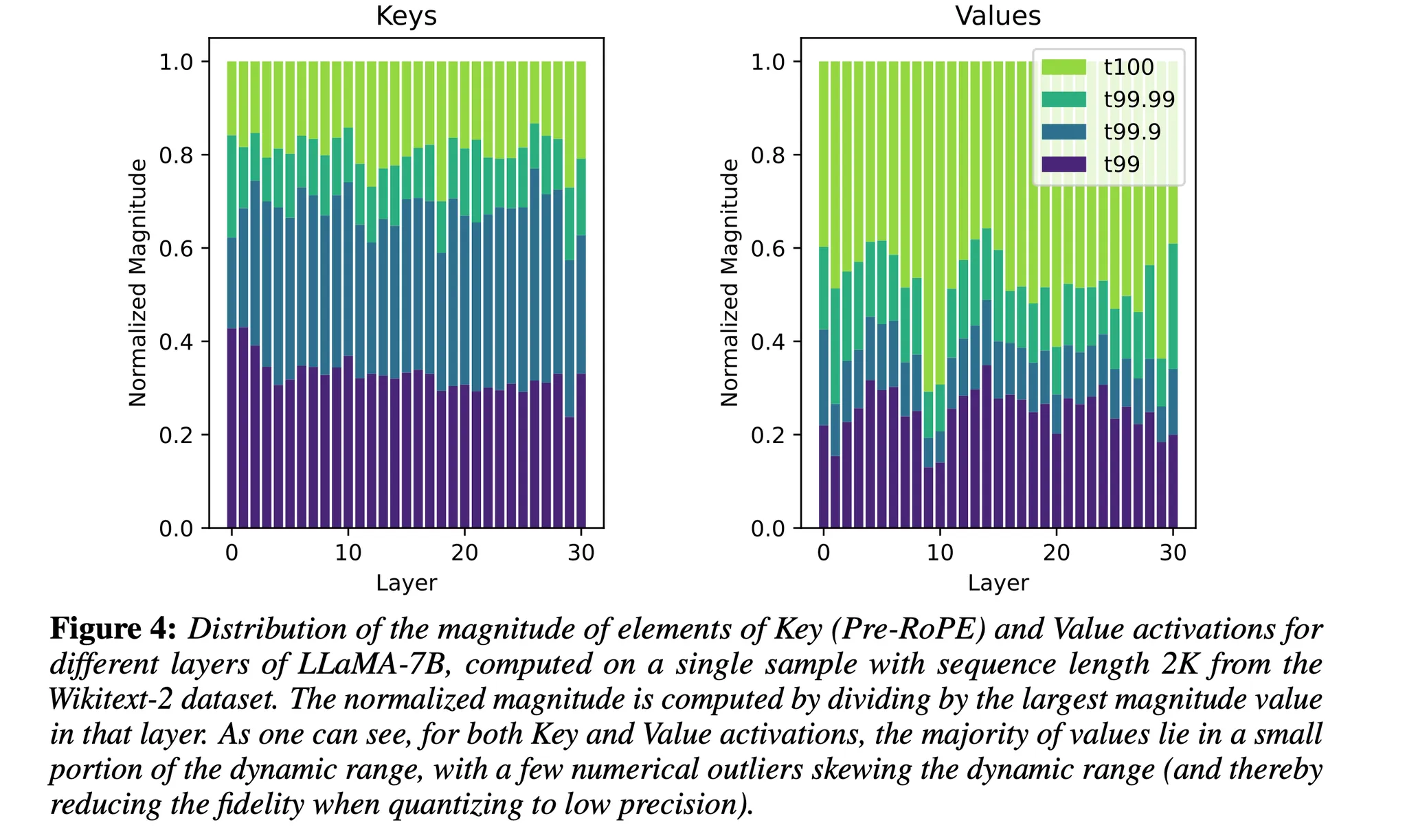
- 하지만 Figure 2에서 Key, Value의 분포를 확인해보면, channel과 tokens는 서로 다른 평균 magnitude를 가짐 → 어떤 채널에서는 이상치인 element가 다른 채널에서는 이상치가 아닐 수 있음 → 단순한 dense-and-sparse quantization을 사용하는 것은 suboptimal
방법)
- Per-vector dense-and-sparse quantization 사용: vector당 다른 outlier threshold를 설정 ↔ 기존에는 layer마다 하나의 outlier threshold가 있었음
- Per-channel의 outlier는 offline으로 계산 & Per-token의 outlier는 online으로 계산(6에서 보일 것)
- upper & lower outlier를 구한 후, 남은 것들을 사용해서 [-1, 1]로 정규화
결과)
- 작은 부분의 outlier를 없애고 그들을 full-precision으로 유지했을 때의 효과
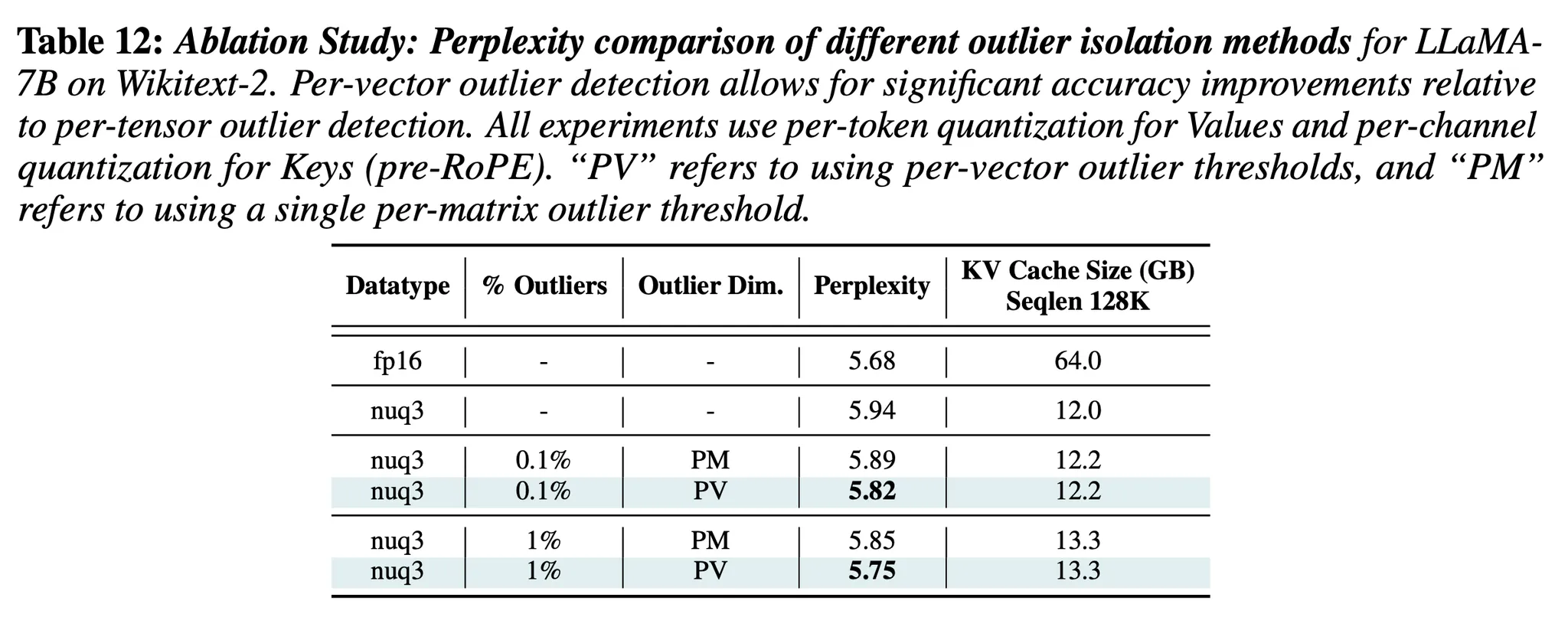
- Figure 1을 보면, per-vector outlier를 사용해서 1%의 outlier를 없애는 것(1%는 full-precision으로 유지)이 0.19 perplexity 향상을 이끌어낸다는 것을 확인할 수 있음
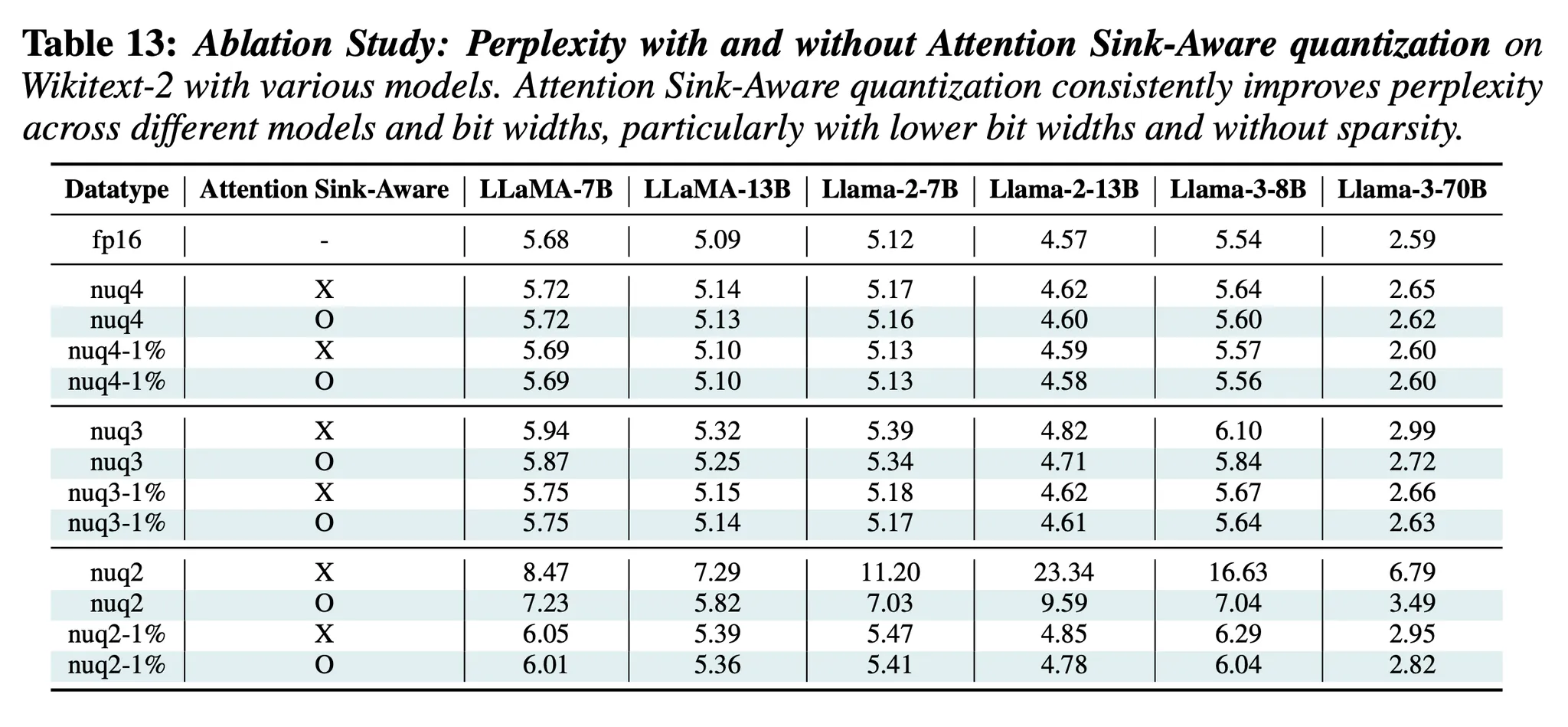
5. Attention Sink-Aware Quantization
배경)
- 이전 연구들은 “LLM의 초기 layer들에서는 첫 토큰한테 큰 attention score를 할당하는 경향이 있음”을 확인함 → 초기 토큰이 의미적으로 중요하지 않은 토큰이어도 이러한 현상이 발생함
- 위의 현상은 모델이 첫번째 토큰을 “sink”로 사용하기 때문에 발생
- 본 논문은 위의 “attention sink 현상” 때문에 모델이 불균형적으로 quantization error에 민감하다는 것을 보일 것
- 본 논문은 위의 “attention sink 현상” 때문에 모델이 과도하게 quantization error에 민감하다는 것을 보일 것! (이게 맞을까?)
방법)
- 첫번째 토큰만 fp16으로 유지 → Perplexity 개선(특히, 2-bit quantization)
- 첫번째 토큰은 fp16으로 유지하는 방법을 사용할 것이면, calibration process에서도 적용해야 한다 → nuqX datatype을 사용할 때, 첫번째 토큰을 제외하고 offline에서 scaling factor & zero points를 계산
결과)
- 이 방법은 모든 실험 조건에서 성능 향상을 보이며, 특히 ‘낮은 bit’ & ‘dense-and-sparse quantization이 없을 때’
6. Offline Calibration versus Online Computation
[Quantization의 방법]
- Offline에서 Calibration을 사용 → Calibration set을 통해 scaling factor & zero points를 미리 계산하고 이를 inference 시 사용하는 방법
- Online에서 computation → scaling factor & zero points를 inference 동안 입력에 맞춰 계산해서 구해주며 사용하는 방법
[Offline Calibration vs Online Computation]
- Per-channel quantization인 Key의 경우: Offline Calibration
- 이유: Per-channel의 경우, 새로운 토큰이 들어오면 그에 맞게 채널별로 scaling factor와 zero-point를 재계산해야 한다. 즉, 새로운 토큰이 생성될 때마다 모든 채널에서 scaling factor와 zero-point update가 일어나야 함. 너무 복잡하고 계산이 많이 필요함
- Per-token quantization인 Value의 경우: Online Computation
- 이유: 토큰마다 activation magnitude가 다르며, 특정 토큰은 outlier일 수 있기 때문에 Calibration set으로 미리 scaling factor & zero-point를 계산하면 정확도가 떨어질 수 있다. 또한 per-channel과 달리 per-token은 추가되는 토큰에 대해서만 scaling factor & zero point를 계산하면 되기 때문에 계산 비용도 크지 않다.
7. Kernel Implementation
- 본 논문에서 구현한 Kernel: 벡터 compression 4-bit quantization 방법 구현 & sparse outlier 추출
- Quantized Key and Value matrices를 4-bit element로 저장하며, lookup table을 통해 Fp16으로 복원 (즉, fp16으로 복원할 때 lookup table의 인덱스로 사용하는데, Lookup table은 인덱스가 16개인 작은 테이블일 것이므로 메모리를 크게 신경쓰지 않아도 된다.)
- Sparse Outlier를 Compressed-Sparse Row(CSR) 또는 Compressed-Sparse Column(CSC) 형식으로 저장(Value, Key의 특성에 따라 선택. Per-token 방식과 Per-channel 방식을 고려)
- pre-RoPE quantization을 지원하기 위해, 해당 kernel의 Key matrix-vector operations은 RoPE을 실시간으로 적용.
실험
Main Evaluation
Grouping 유무에 따른 결과 확인(본 논문의 KV quant vs ATOM & FlexGen)
-
LLaMA의 성능 & 메모리 측면)
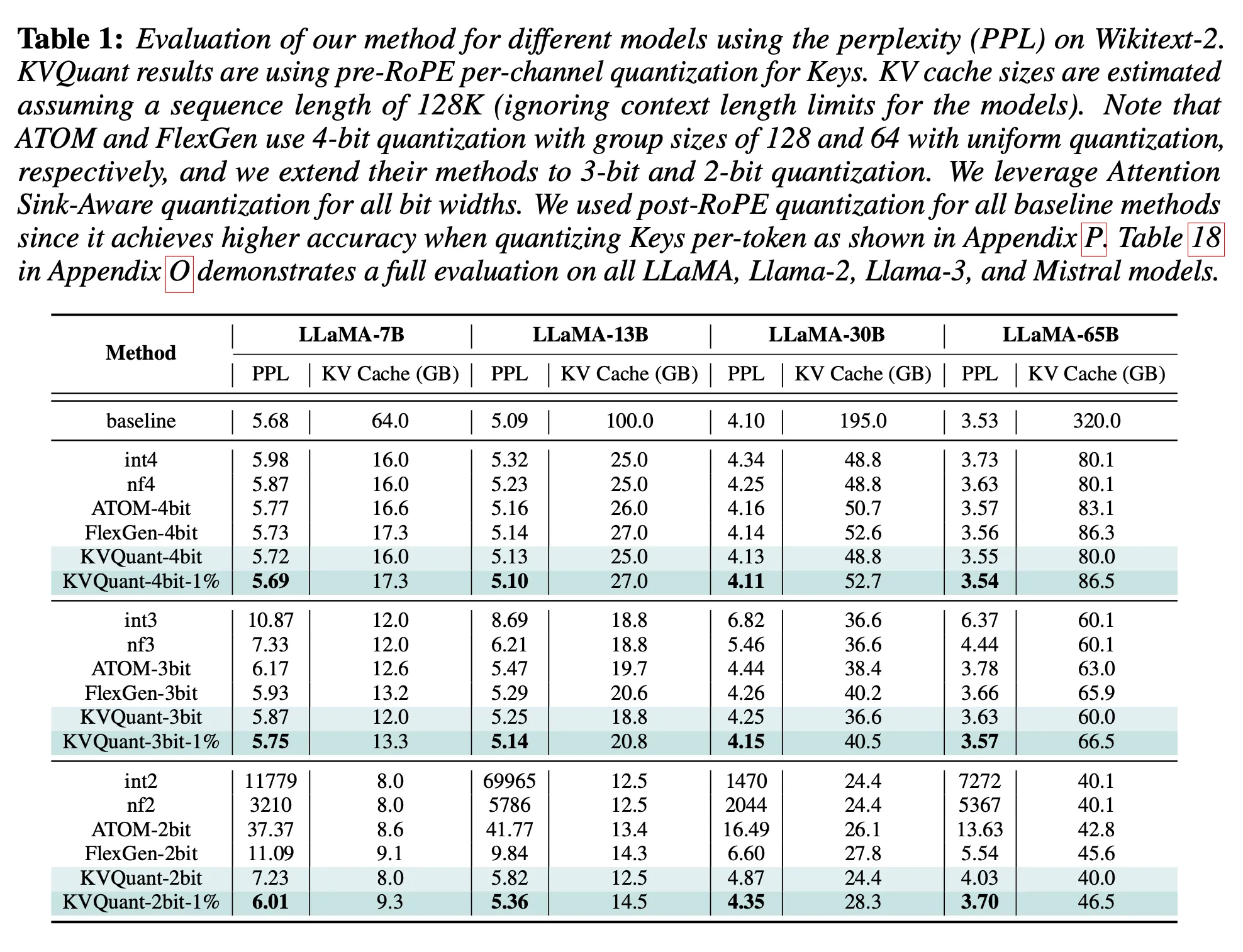
(다른 모델들의 성능 결과)
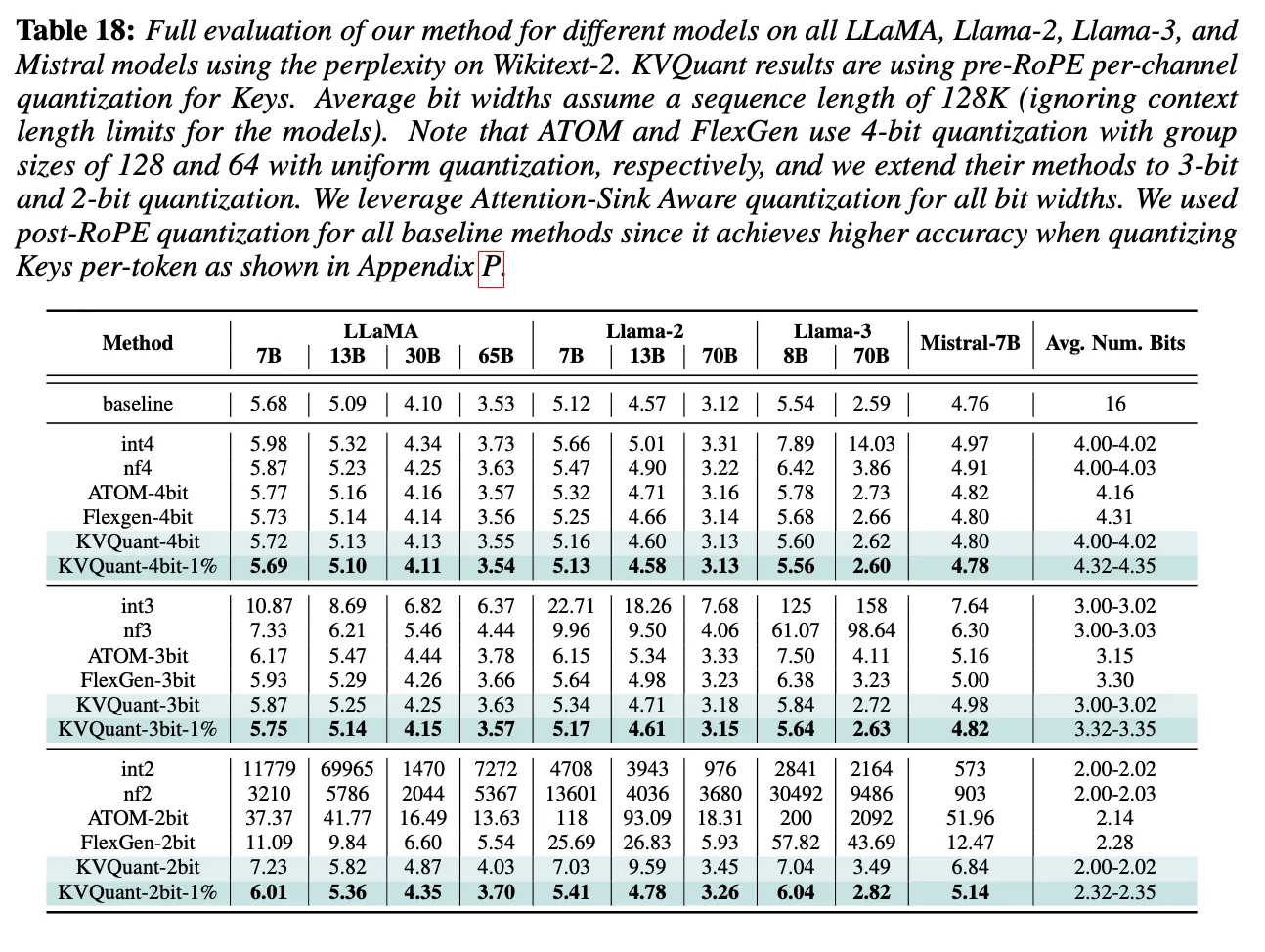
Long context Length Evaluation
-
Perplexity Evaluation

Long context 다루는 모델들로 실험을 해봤는데, 그래도 좋은 결과를 보임(Accuracy 유지) → 효율적이고 정확한 long sequence length inference 가능
-
Passkey Retrieval Evaluation
Passkey retrieval: 긴 텍스트에서 특정 정보를 찾을 수 있는 능력 평가하는 것을 포함 & Inference 동안 token이 attend 될 수 있는 최대 길이를 효과적으로 측정할 수 있음
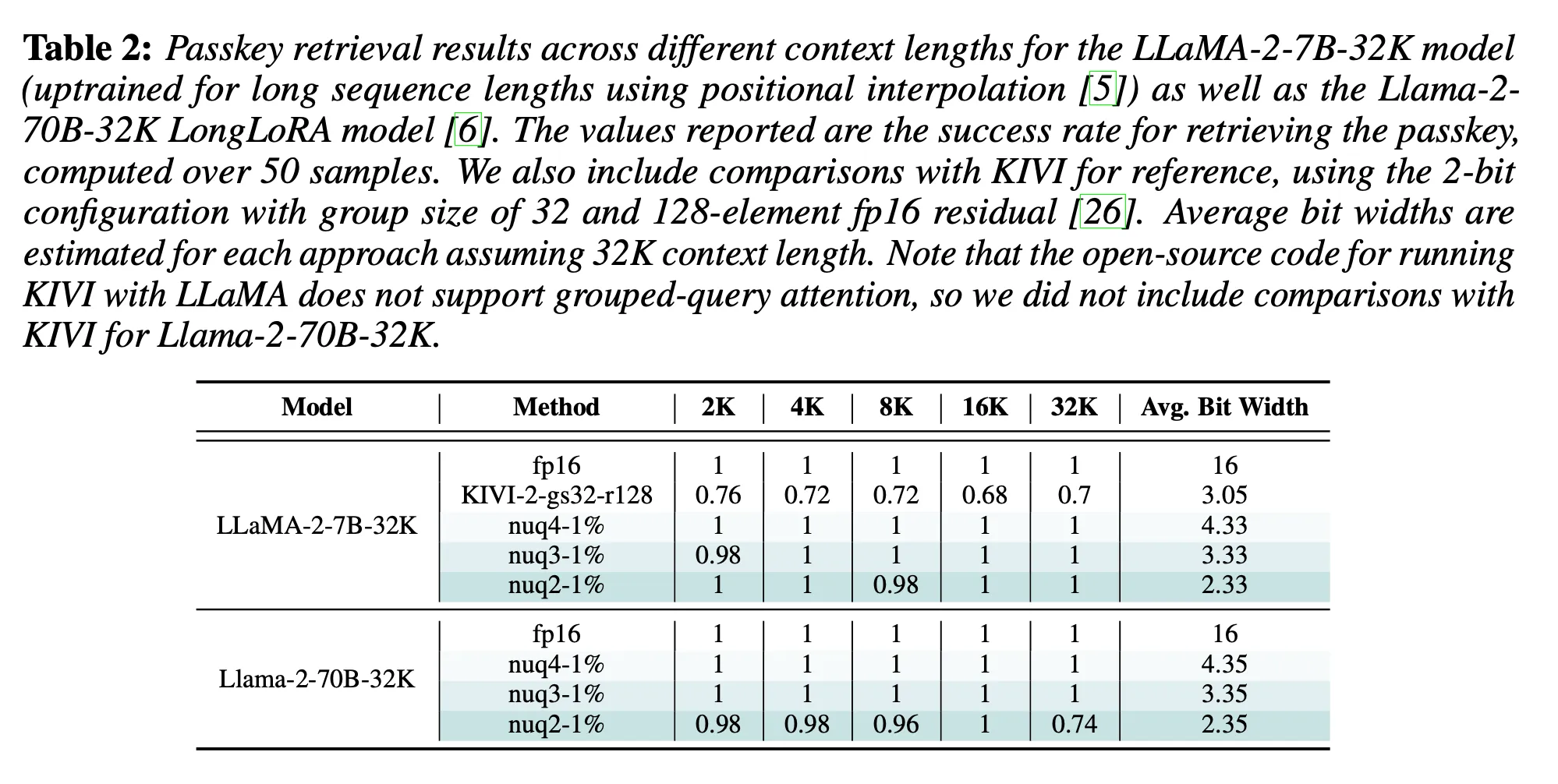
성공적으로 passkey를 가지고 오는 비율(50개의 sample에 대하여)
- LongBench: QA tasks, summarization, few-shot learning과 같은 평가 벤치마크 포함 long-context length evaluation

- RULER evaluation
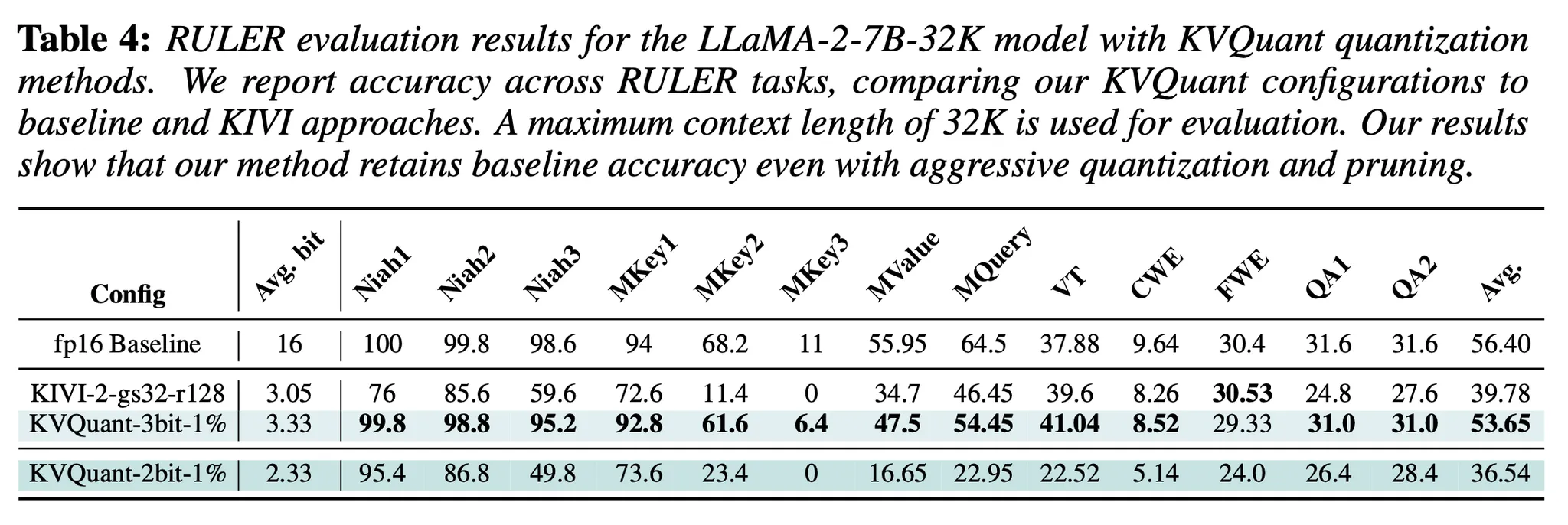
Weight quantization과 KV cache quantization 동시에 사용
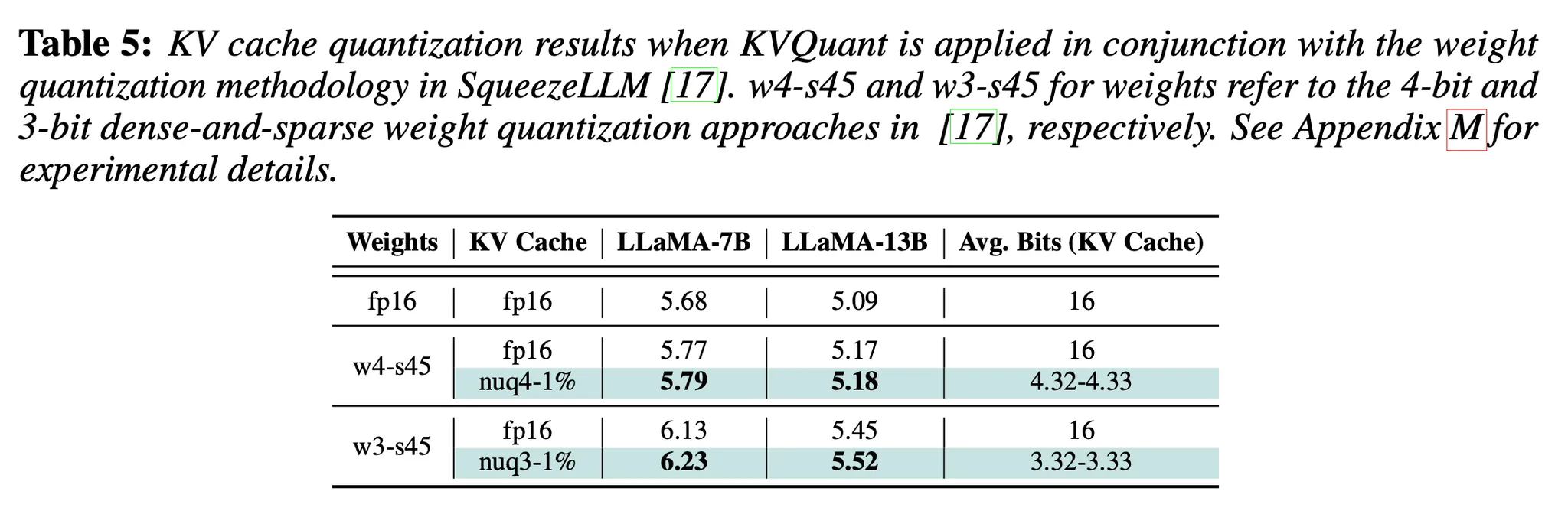
결과를 보면, weight quantization과 kv cache quantization을 함께 사용해도 perplexity 성능 감소가 작다 → 기존의 weight-only quantization 방법론들과 KV cache quantization은 함께 사용될 수 있다
성능 분석 & 메모리 절약
“특징: bacth = 1”
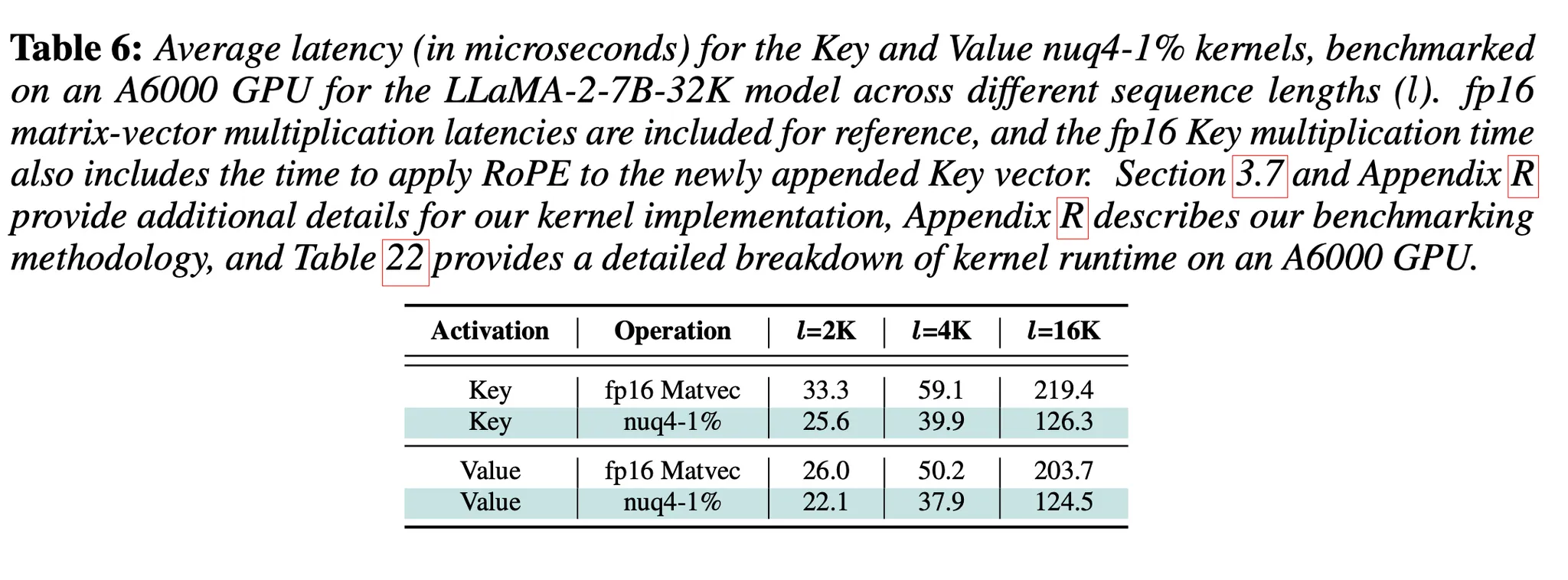
Key multiplication에 걸리는 시간: RoPE 적용까지 포함한 latency
Latency 향상이 이뤄짐(Key multiplication: 1.2-1.6× & Value multiplication: 1.3-1.7×). Quantized elements를 가져오는 것이 Memory I/O에서 latency를 많이 줄여주나 보다. Dequantization overhead가 발생하는데도 latency 향상이 이렇게 있는 것을 보면(batch가 커지면, 어떻게 될지 모르겠지만)
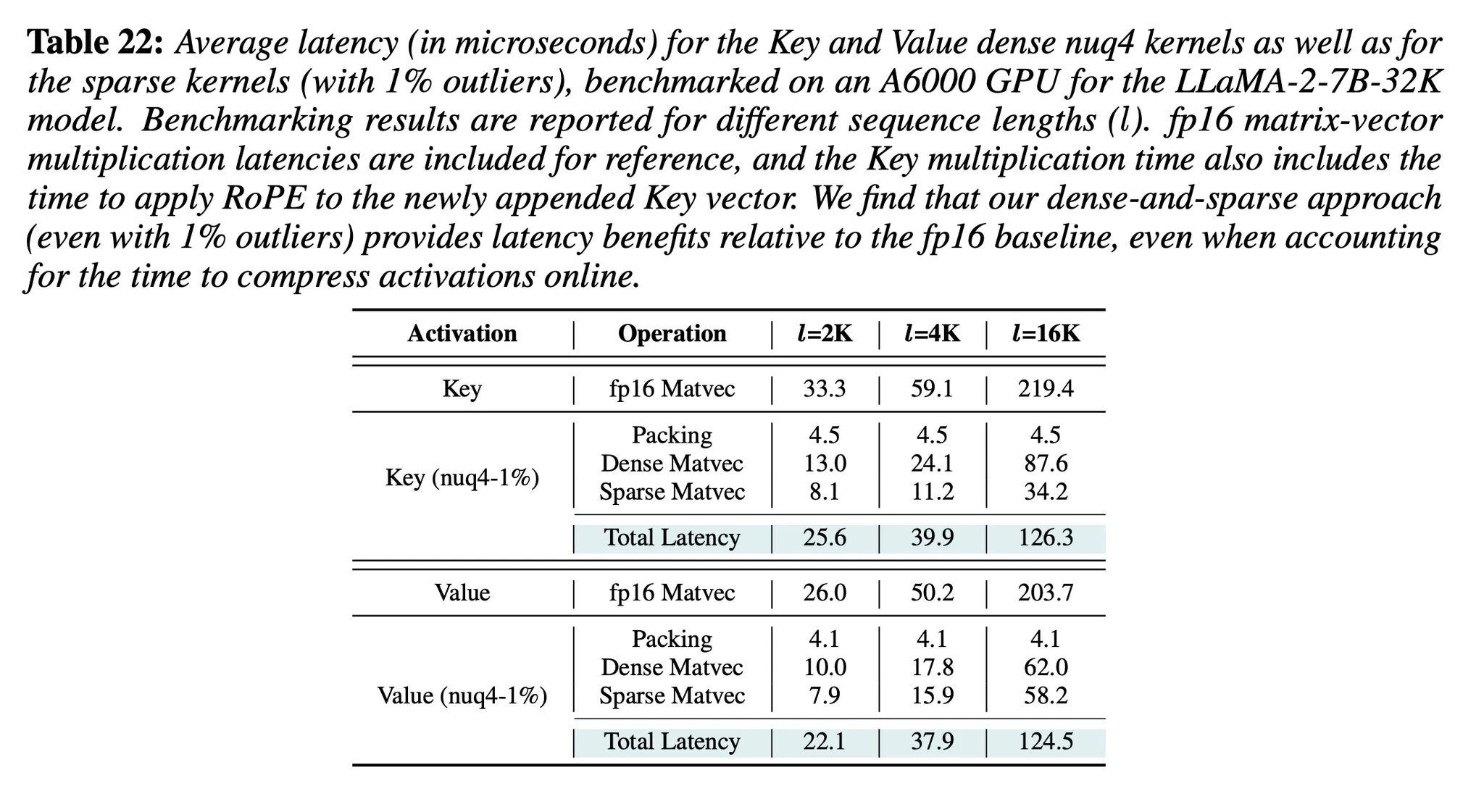
(자세한 latency 정보)
