L2P의 1저자 Zifeng Wang의 prompt-based continual learning 후속 논문으로 general-prompt와 expert-prompt를 명시적으로 학습하는데 사용하며, task invariant
DualPrompt: Complementary Prompting for Rehearsal-free Continual Learning
Abstract
- continual learning의 top-performing methods는 보통 리허설 버퍼를 필요로 하는데 DualPrompt는 적은 parameters set인 prompts를 통해 이런 버퍼 없이 task들을 순차적으로 학습할 수 있음
- pre-trained backbone에 prompt를 붙여 task-invariant와 task-specific에 대한 지시(instructions)를 학습하도록 함
1. Introduction
- continual learning 배경은 L2P 참조
- 결국, continual learning의 central goal은 순차적인 task들에 대해 single model로 학습하는데, catastrophic forgetting을 최소화 하는 것
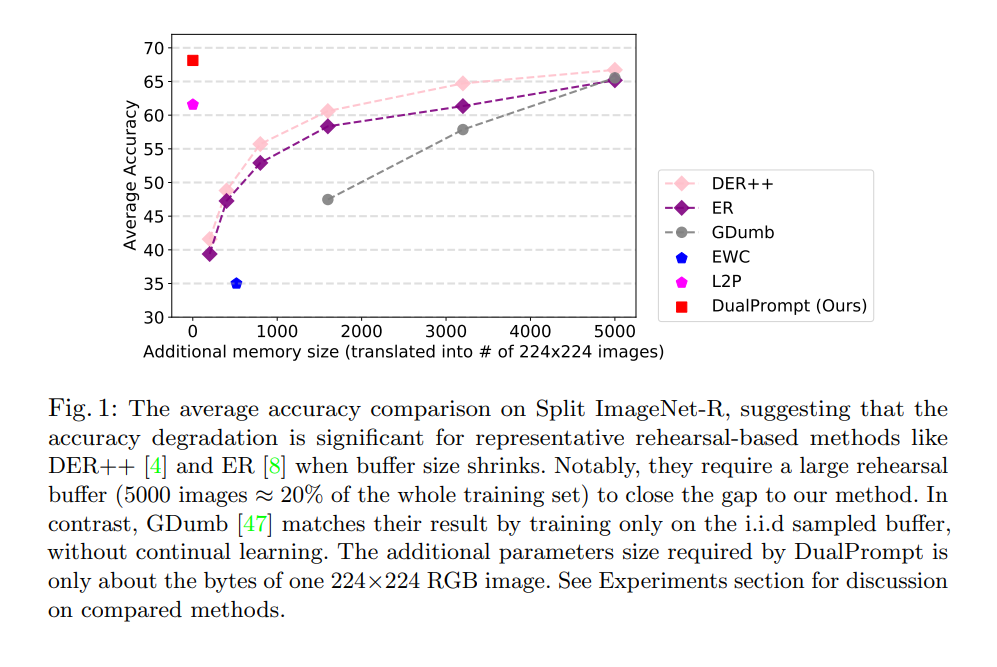
리허설 버퍼를 사용하지 않아도 높은 성능치를 보이는 것은 확인할 수 있음(기존 L2P보다도 높은 성능치 달성)
ImageNet-R의 경우 ImageNet에서의 200 subset classes, 30,000장으로 구성된 다양한 표현 스타일의 데이터 셋이기에 task-incremental관점에서의 측정이였을 것 같음
- L2P의 single prompt pool은 모든 작업간의 공통 feature와 각 작업에서의 unique한 feature를 구분하지 않고, 한 작업에서 다른 작업으로 지식을 전달하도록 디자인되어 있음
- Complementary Learning Systems(CLS)은 인간이 두 가지 학습 시스템 간의 시너지 효과를 통해 지속적으로 학습한다고 제안함
- 해마는 특정 경험에서 패턴으로 분리된 표현 학습에 집중 —> task-specific knowldege
- 신피질은 과거 경험 시퀀스에서 보다 일반적이고 전달 가능한 표현 학습에 집중 —> task-invaraitn knowldege
- 이전의 CLS-driven methods는 backbone parameter를 분리하거나 확장하여 두 종류의 지식을 학습함
- 리허설 버퍼에 크게 의존
- 이 논문에서 DualPrompt를 제안
- 리허설 없는 continual learning
- 분리된 prompts spaces
- G(eneral)-Prompt: encode task-invariant
- E(xpert)-Prompt: encode task-specific
- lower-level latent representation 공간보다 더 효과적인 것으로 밝혀진 higher-level prompt 공간을 직접 분리 함
2. Related work
- L2P 참조
3. Prerequisties
- L2P 참조
4. DualPrompt
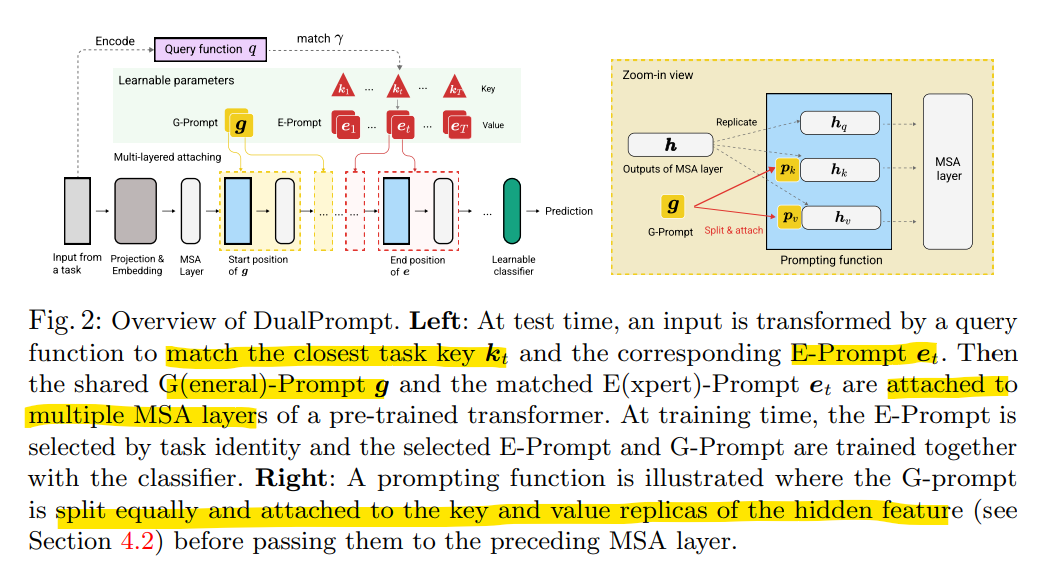
query function을 통해 input으로 부터 matching되는 key로 task-specific한 E-Prompt 와 task-general한 G-Prompt g를 Prefix Tuning방식으로 prompt를 분리하여 key, value hidden feature에만 attatch하도록 함.
이때 G-Prompt와 E-Prompt는 어떤 위치의 MSA에 attatch하는 것이 가장 효과적인지를 여러 벤치마크를 통해 실험 하여 일관된 성능향상 보이는 지점을 찾음
- Complementary G-Prompt and E-Prompt
- G-Prompt
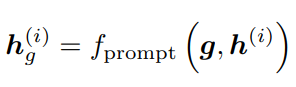
G-prompt를 i번째 MSA layer에 연결한다고 할때의 수식, 여기서 prompt는 hidden embeding에 attatch하는 방법 정의; 아래에서 다룸
- sequence length: , embedding dim: D
- embedding feature of the i-th MSA layer
- E-Prompt
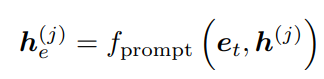
위의 prompt 방법을 통해 j번째 MSA layer에 attach
- task-dependent parm
- T: total # of tasks, 는 특정 task key에 대한 parm
- L2P와 마찬가지로 query matching 전략을 사용
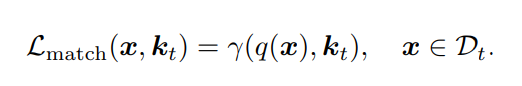
- G-Prompt
- Prompt attaching: where and how?
대부분의 prompt-releated work는 단순히 첫 번째 MSA 또는 모든 MSA 레이어에만 프롬프트를 배치, 해당 논문은 두 가지 유형의 prompt를 어디에 어떻게 attach할지 탐색하는 것이 중요하다 주장함
- Where: Decoupled prompt positions
- backbone의 서로 다른 layer는 서로 다른 level의 feature abstraction을 갖고 있음
- 때문에, task를 순차적으로 학습 할때, 일부 표현 계층은 다른 표현 계층보다 task-specific 지식에 더 높은 response를 가질 수 있고, task-invariant의 경우 그 반대일 수 있음
- 두 가지 prompt를 적절한 위치에 연결하여 서로 다른 prompt가 서로 다른 instrictions로 해당 표현과 더 효과적으로 상호작용할 수 있음
- 와 는 완전히 다르거나 겹치지 않을 수 있으며, 실험에서는 여러 검증 세트에서의 특정 start-end 종료 세트를 경험적으로 검색하고, 다양한 벤치마크에서 일관되게 수행됨을 발견
- l-th MSA layer 시작부터 끝까지 attach
- backbone의 서로 다른 layer는 서로 다른 level의 feature abstraction을 갖고 있음
- How: Configurable prompting function
- : prompts를 embedding feature와 결합하는 방식 제어 해당 논문에서는 NLP community의 두 가지 주요 구현인 Prompt Tuning과 Prefix Tuning을 연구
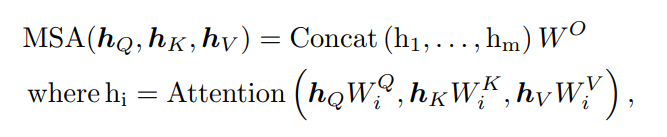
- Prompt Tuning (Pro-T)
- 동일한 prompt를 Q, K, V에 동일하게 concatenate함
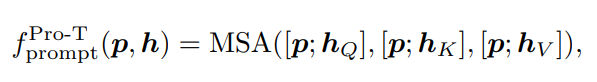
- 출력 dimension 은
- 동일한 prompt를 Q, K, V에 동일하게 concatenate함
- Prefix Tuning (Pre-T)
- prompt를 와 로 분리하고 Q를 뺀 K, V에 concatenate함
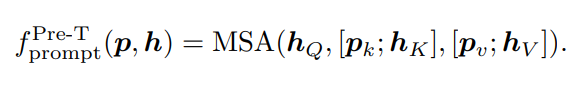
- 출력 dimension은 input과 동일하게
- prompt를 와 로 분리하고 Q를 뺀 K, V에 concatenate함
- : prompts를 embedding feature와 결합하는 방식 제어 해당 논문에서는 NLP community의 두 가지 주요 구현인 Prompt Tuning과 Prefix Tuning을 연구
- dualprompt loss
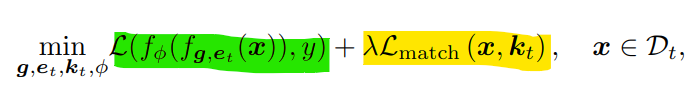
- : classification head
- : t-th task에 해당하는 input x에 대해 prompt가 attach된 transform forwarding
- : cross-entropy loss
- : input x와 matching되는 task의 key
- Where: Decoupled prompt positions
5. Experiments
- Evaluation benchmarks
- Split ImageNet-R
The Split ImageNet-R benchmark is build upon ImageNetR by dividing the 200 classes randomly into 10 tasks with 20 classes per task
- Split CIFAR-100
It splits the original CIFAR-100 into 10 disjoint tasks, with
10 classes per task - Additional results on 5-datasets
- CIFAR-10
- MNIST
- Fashion-MNIST
- SVHN
- notMNIST
- Split ImageNet-R
- Comparison with state-of-the-arts
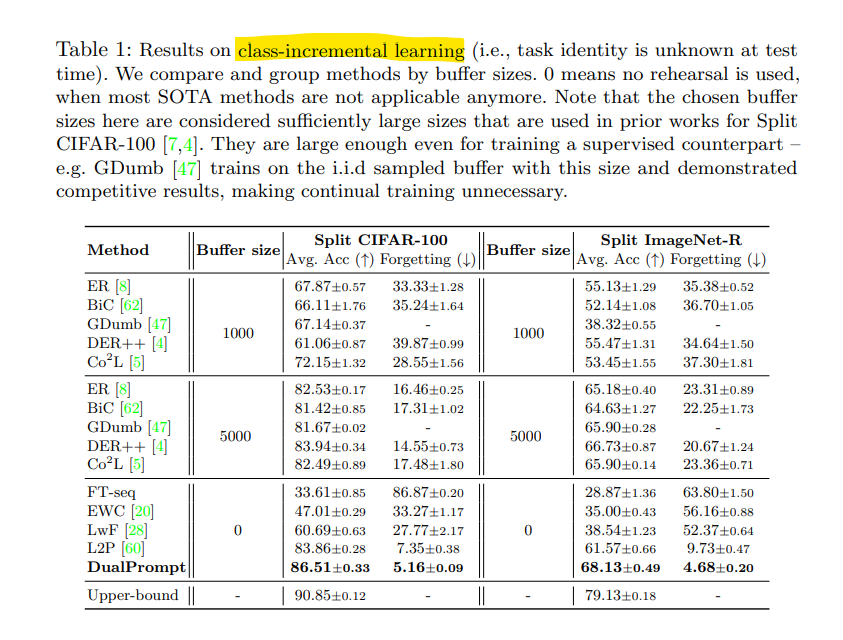
class-incremental에 대한 성능, 버퍼 사이즈를 크게 사용하는 다른 모델들 보다도 높은 성능 + L2P보다도 높은 성능
- Does stronger backbones naively improve CL?
Architecture Matters in Continual LearningVit는 ConvNets보다 강력한 backbone이지만 반드시 강력한 backbone이 continual learning performance가 좋은 것은 아님
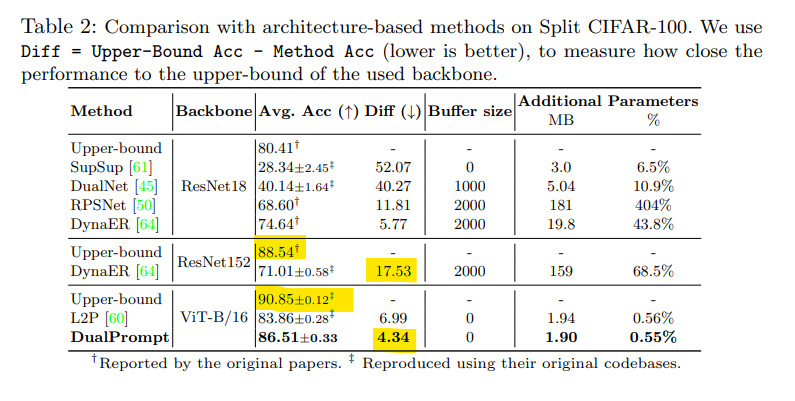
ResNet152의 upper-bound와 ViT-B/16의 upper-bound는 큰 차이가 나지 않지만,
성능은 크게 떨어지는 양상을 보임
—> ResNet152도 충분히 강력한 backbone이지만, forgetting이 크기 때문에, 모델 아키텍처 자체가 CL의 performace 향상을 보이는건 아님 - Exploration of where and how to attach prompts
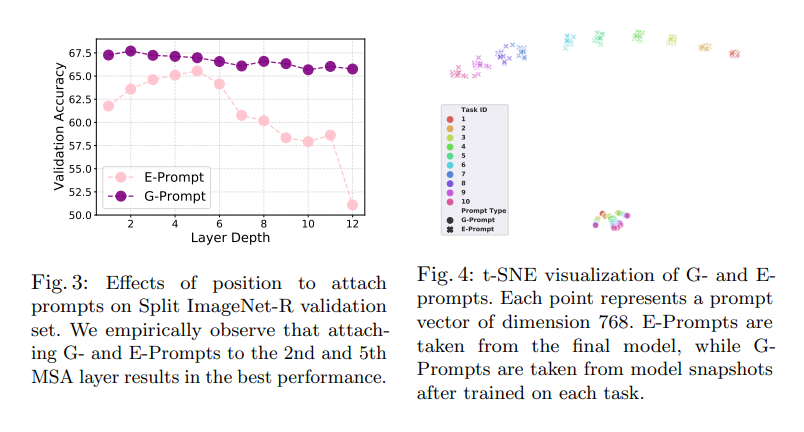
G-Prompt start = 1, end = 2, E-Prompts start = 3, end = 5가 가장 성능이 좋게 나옴을 실험적으로 찾음.
t-SNE통해 G- 와 E-prompts의 prompt vector 분포를 통해 각 prompt의 목적에 맞게 task-general하게 뭉쳐있고, task-specific하게 흩어져 있는 분포를 확인할 수 있음

Prefix Tuning의 성능이 더 좋은 것을 확인.
G-P와 E-P를 같이 사용했을 때의 성능이 더 좋은 것을 확인. - 추가로 prompt length는 Split Imagenet-R로 optimal choice
- G-Prompts: 5, E-Prompts: 20
- Evaluation metric
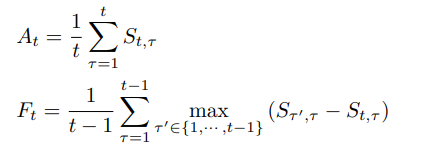
는 평균적으로 얼마나 맞추는지 전체 task에 대한 accuracy 측정
는 task가 3개가 있다고 했을때 2번 taks 까지 학습했을 때의 forgetting 평균을 내도록 하는데 이 때 forgetting은 max((task3까지 학습한 model - task2까지 학습한 모델), (task3까지 학습한 model - task1까지 학습한 모델))
6. Conclusion
과거 지식의 데이터를 직접 저장하는 리허설 방법과 달리, prompt-based method는 과거 지식을 학습 가능한 작은 매개 변수에 저장하여 continual learning이 가능함.
해당 논문에서 새로운 benchmark인 Split ImageNet-R이외에도 여러 benchmark들에 대해 이전 architecture-based, rehearsal-based methods 보다 SOTA performance를 보임
