본 글은 2019년 발표된 Deep Learning Recommendation Model for Personalization and Recommendation Systems
을 읽고 요약 및 정리한 글입니다.
논문
직접 구현 DLRM 모델 코드 (Pytorch)
직접 구현 DLRM Movielens100k 학습 코드 (Jupyter)
0. Summary
| 구분 | Wide & Deep | DeepFM | DCN | xDeepFM | DLRM |
|---|---|---|---|---|---|
| 핵심 아이디어 | Wide(선형) + Deep(비선형) 모델 결합 → 기억( memorization ) + 일반화( generalization ) | FM의 2차 상호작용 + Deep MLP 결합 | cross layer로 명시적 feature 교차 학습 | CIN layer로 고차 상호작용을 세밀하게 모델링 | 임베딩 벡터 간 dot product 로 2차 상호작용만 학습 |
| 상호작용 방식 | Wide: 수동으로 정의된 feature cross | FM 파트: 자동 2차 교차 | cross layer에서 feature 간 곱(product)으로 상호작용 | CIN에서 feature 벡터 원소 단위까지 조합 | 임베딩 간 dot product 계산 후 MLP로 예측 |
| 상호작용 차수 | Wide: 수동 고차, Deep: 비선형 | 2차 + deep network로 간접적 고차 | 2차 이상 (layer 깊이에 따라) | 명시적 고차 (CIN 깊이에 따라 증가) | 2차 (dot product 한정) |
| Interaction 단위 | feature 단위 (hand-crafted cross) | feature vector 전체 간 조합 | feature vector 원소 단위 곱 | feature vector 원소 단위 조합 | feature vector 전체 단위 dot product |
| 구조적 복잡성 | 중간 (두 branch 결합) | 중간 (FM + MLP) | 높음 (cross layer 추가) | 매우 높음 (CIN 계산량 많음) | 낮음 (embedding + dot product + MLP) |
| 계산 효율성 | 중간 | 중간 | 낮음 | 낮음 | 높음 |
| 장점 | 단순, 빠름, 해석 쉬움 | 자동화된 2차 상호작용 + deep 표현력 | 명시적 교차로 feature 관계 잘 학습 | 강력한 고차 상호작용 표현력 | 단순·효율적·대규모 데이터 처리에 적합 |
| 단점 | 수동 feature cross 필요 | 고차 표현 한계 | 계산 복잡도 증가 | 계산/메모리 비용 매우 큼 | 고차 표현력 제한 (2차까지만) |
| DLRM과의 차이점 | DLRM은 수동 cross 없이 dot-product로 자동 학습 | DLRM은 FM처럼 2차만 다루지만 더 효율적 | DLRM은 cross layer 제거, 구조 단순 | DLRM은 element-level 교차 없이 vector-level만 | — |
1. Introduction
- 최근에 되서야 neural network 구조가 추천 시스템에 적용
- 개인화 추천 딥러닝 모델 구조에 대한 두가지 관점
- 추천 시스템
- content-filtering
- collaborative filtering
- 주어진 데이터에 대한 예측력 분석
- logistic regression
- deep network
- categorical feature처리를 위해 dense embedding
- 추천 시스템
- DLRM
- input
- sparse_features: embedding
- dense_features: mlp
- interact
- statistical technique
- overhead
- classifier: mlp
- input
2. Modle Design and Architecture
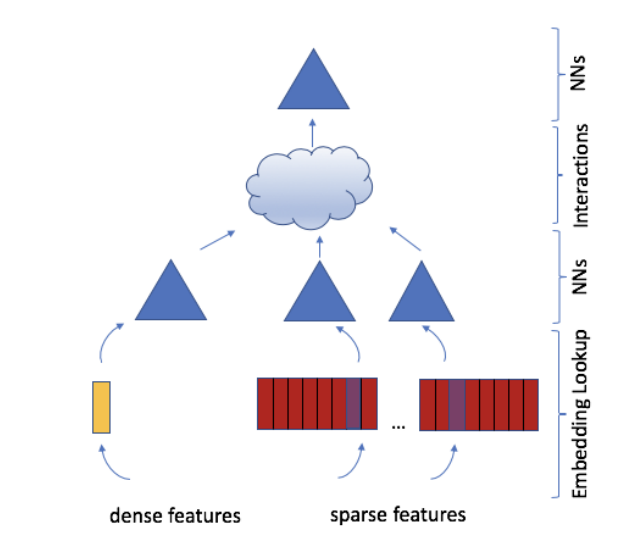
2.1 Components of DLRM
- Embeddings
- category 데이터를 embedding하여 dense representation
- 다양한 상황에서 사용 가능
- one-hot vector or multi-hot vector
- weighted combination
- Matrix Factorization
- embedding이 왜 효과적인지 다시 살펴보는 부분
- 이전 연구에서 latent factor method
- matrix factorization:
- Factorization Machine
- 2-order interactions를 1차 linear model
- 2-order interaction matrix를 latent factor로 분해
- 이로 인해 sparse data를 효과적으로 처리
- linear computational complexity
- Multilayer Perceptrons
- more complex interactions를 포착
- Neural Collaborative Filtering에서 성공적으로 사용
2.2 DLRM Architecture
- 위의 이전 연구들을 합하여 DLRM 모델을 설계
- user와 product를 많은 continuous and categorical features로 정의
- embedding과 mlp로 동일한 길이의 dense vector로 표현
- 모든 pair의 dense feature사이에 dot product를 통해 FM을 표현
- 이를 원래의 dense feature와 conconcatenate 하여 또다른 MLP로 확률 계산
2.3 Comparison with Prior Models
- 이전의 많은 deep learning model들 모두 high-order interactions을 설계
- Wide & Deep
- Deep & Cross
- DeepFM
- xDeepFM
- 이 모댈들은 각각의 output을 합하여 sigmoid로 확률 계산
- DLRM
- 이전의 모델과 달리 복잡한 상호작용 구조 대신 임베딩과 벡터 내적(dot product)만 사용
- 계산량과 메모리 비용 효율화
