본 글은 2016년 발표된 Wide & Deep Learning for Recommender System을 읽고 요약 및 정리한 글입니다.
논문
직접 구현 WideAndDeep 모델 코드 (Pytorch)
직접 구현 WideAndDeep Movielens100k 학습 코드 (Jupyter)
0. Summary
- Wide&Deep은 추천 시스템에서 Memorization 과 Generalization 능력을 동시에 고려
| Wide | Deep | |
|---|---|---|
| 역할 | Memorization | Generalization |
| 목적 | 과거에 자주 같이 나타난 특징 조합을 기억 | 과거에 본 적 없는 특징 조합에 대응 |
| 입력 형태 | cross-product features | Sparse feature |
| 특징 | Linear modeling | Dense Embedding + MLP |
| 모델수식 |
1. Introduction
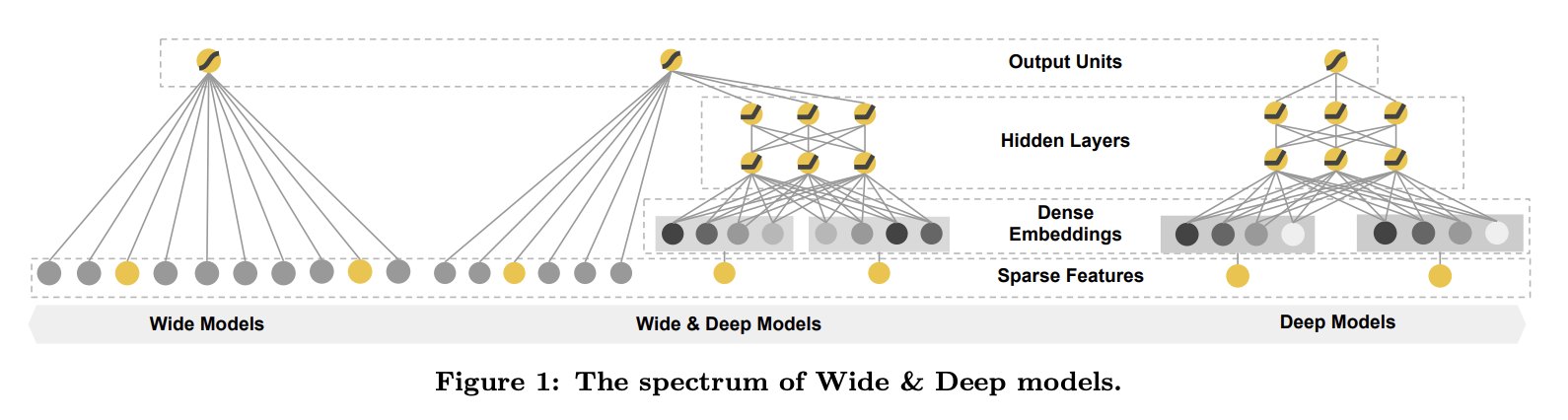
- 추천 시스템은 검색 랭킹 시스템으로 간주
- input: user, contextual information
- output: a ranked list of items
- objective: clicks or purchases
- query가 주어질 때, DB에 있는 연관된 아이템을 찾는 것
- Challenge(일반적인 검색 시스템)
- memorization & generalization
- Memorization: 빈번히 같이 등장하는 아이템이나 피처 / 연관된 데이터, 직접 연관
- Generalization: 과거에 같이 등장하지는 않았지만(적거나) 연관된 데이터, 다양성 향상
- Cross-product Transformation
- AND(user_installed_app=netflix, impression_app=pandora)
- co-occurence of a feature pair label
- 직접 수동 feature engineering 필요
- Embedding-based Model
- FM, DNN
- 학습 데이터에 없는 상황도 일반화
- feature enginering 필요 없음
2. Recommender System Overview
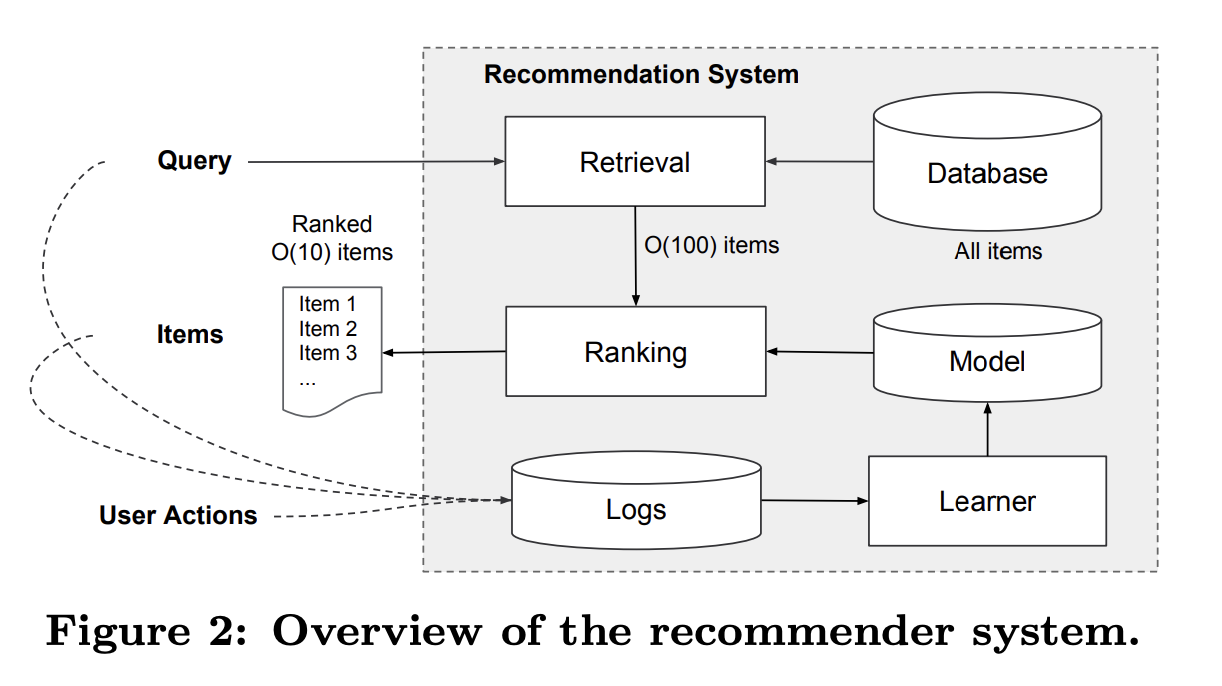
Google Play
- Query: 다양한 user와 Contextual features
- Return: a list of apps
- DB에는 수백만 앱 존재
- 모든 query에 모든 app을 scoring할 수 없음
- Latency Requirements:
- 따라서 하나의 query가 주어질 retrieval이 필요
- Retrieval
- 사람이 정의한 규칙(Human-defined rules)
- 머신러닝 모델(Machine-learned models)
- Output: Candidate pool
- Ranking
- features가 주어질 때, Candidate pool에 대한 score
- Wide And Deep!
3. Wide & Deep Learning
3.1 The Wide Component
- Generalized Linear Model
- d개의 피처를 갖는 벡터:
- model parameters:
- Feature Set
- Raw input features
- Transformed features(cross product)
- binary features 사이에 interactions을 기억
- 비선형성
- 예시
import pandas as pd
# 원본 데이터 (raw input)
data = [
{"user_country": "Korea", "user_gender": "Female", "device_os": "Android", "app_category": "Game", "clicked": 1},
{"user_country": "USA", "user_gender": "Male", "device_os": "iOS", "app_category": "Finance", "clicked": 0},
{"user_country": "Korea", "user_gender": "Male", "device_os": "Android", "app_category": "Shopping", "clicked": 1},
{"user_country": "Japan", "user_gender": "Female", "device_os": "Android", "app_category": "Music", "clicked": 0},
]
df = pd.DataFrame(data)
# cross-product feature 생성 (예: user_country x app_category)
df["country_app_cross"] = df["user_country"] + "_" + df["app_category"]
print(df)
| user_country | user_gender | device_os | app_category | clicked | country_app_cross |
|---|---|---|---|---|---|
| Korea | Female | Android | Game | 1 | Korea_Game |
| USA | Male | iOS | Finance | 0 | USA_Finance |
| Korea | Male | Android | Shopping | 1 | Korea_Shopping |
| Japan | Female | Android | Music | 0 | Japan_Music |
3.2 The Deep Component
- Feed-forward neural network
- 고차원 카테고리 피처는 저차원의 벡터로 embedding
- 10 ~ 100차원
- embedding vector를 MLP로 학습
3.3 Joint Training of Wide & Deep Model
- Joint Train
- 모든 parameter를 동시에 업데이트
- 주의: Ensemble은 model들을 각각의 학습
4. System Implementation
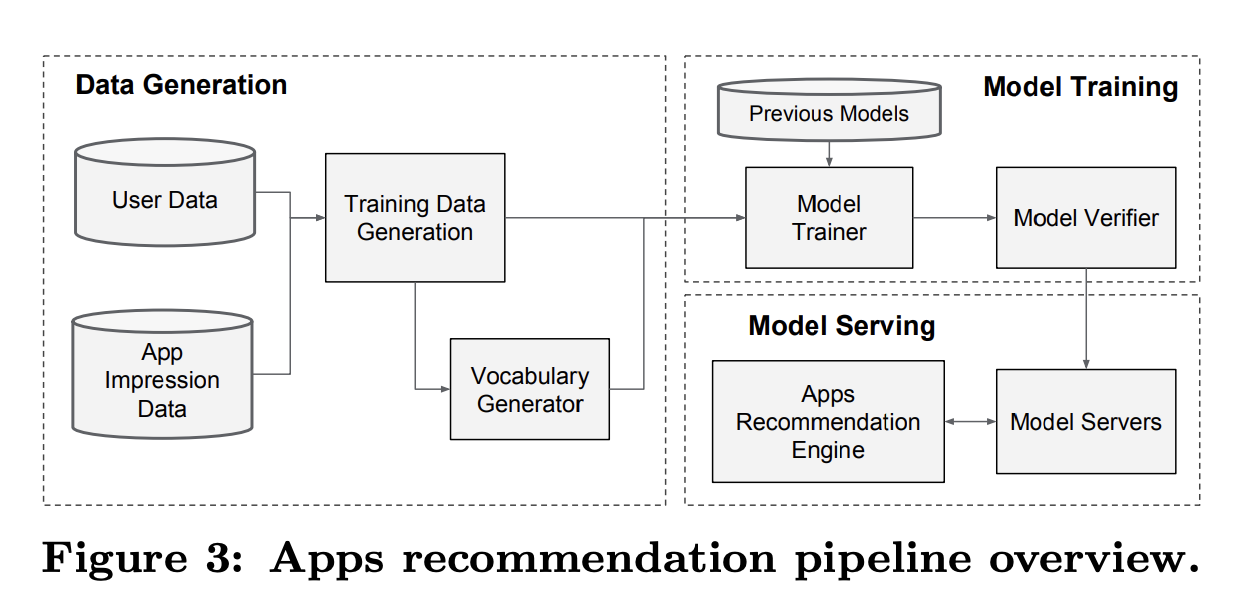
4.1 Data Generation
- user와 app impression data가 학습 데이터 생성
- 각각의 row는 impression
- label은 app acqusition(install)
- Categorical Data: Vocabulary 생성
- Continuous Data: Normalize [0, 1]
- where : quantiles
4.2 Model Training
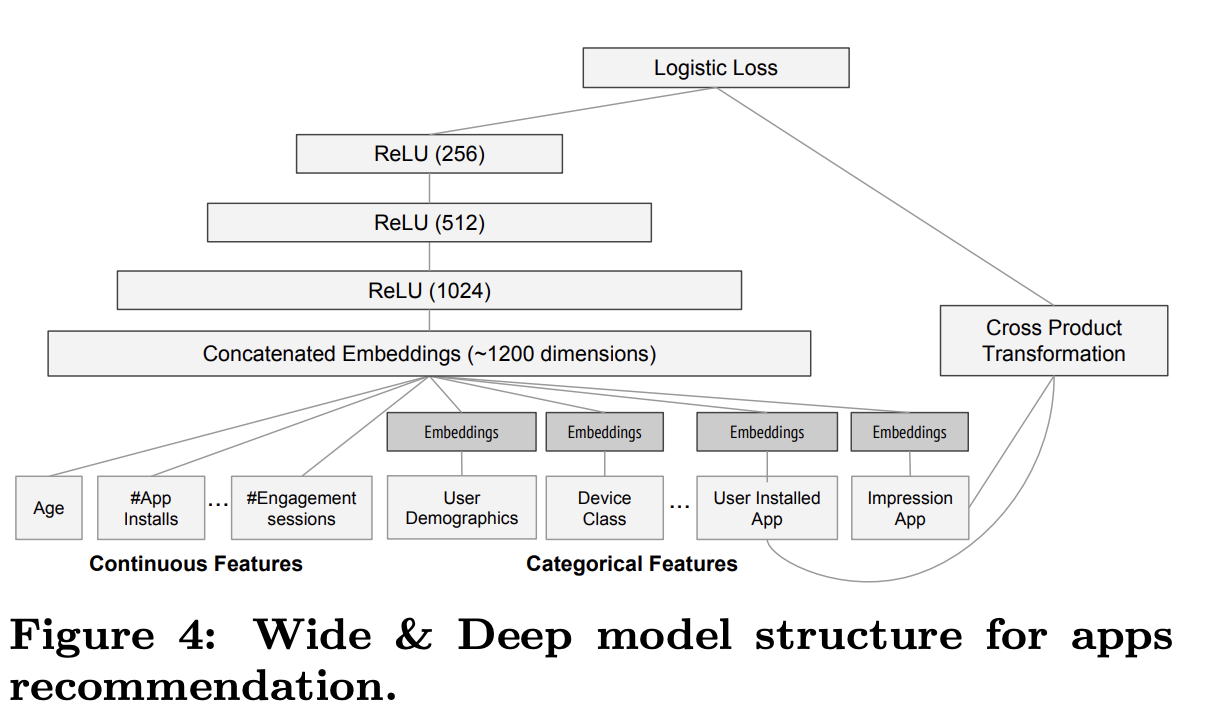
- Wide: cross-product transformation
- user installed apps
- impression apps
- Deep
- Embedding Dim: 32
- Concat(1200-d) 3 ReLU Layers logits
- Warm-starting System
- 이전 학습 모델로 embeddings과 linear model의 weights를 초기화
- re-train을 from scratch로 하는 것은 너무 오랜 시간이 걸림
4.3 Model Serving
- 학습 후 model server에 올림
- app retrieval system을 통해 candidate을 전달 받음
- 학습된 모델로 score from high to low
- Multithread
- Single batch로 scoring하지 않음
- smaller batch
- parallel score
- 10ms
- Single batch로 scoring하지 않음
5. Experiment Result
5.1 App Acquisition
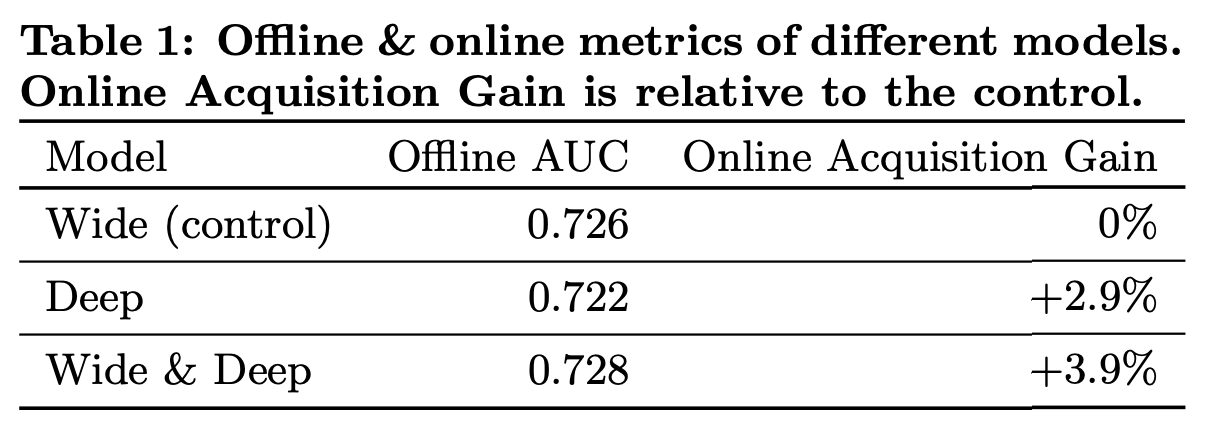
- Wide
- control(Previous version)
- logistic regression
- rich cross-product feature transformations
- 1% users
- Wide & Deep
- experiment
- same set of features
5.2 Serving Performance
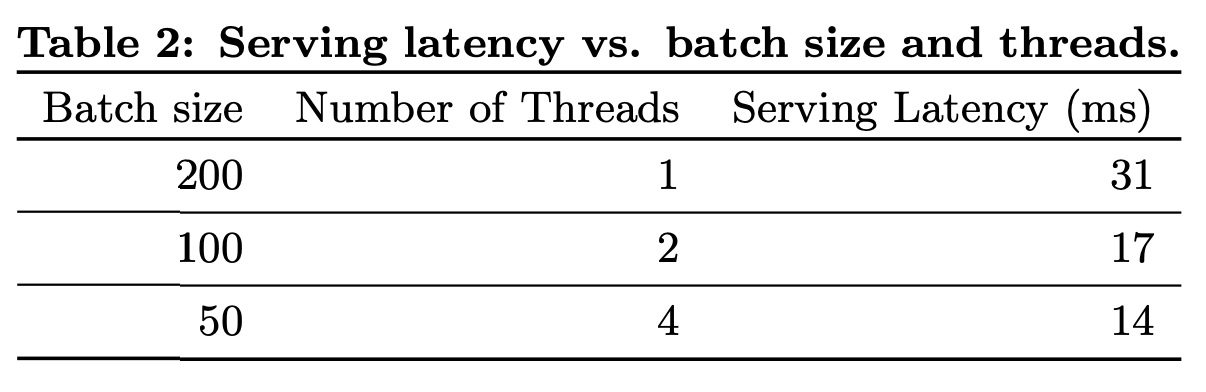
- GOAL
- high throughput
- low latency
