- 6가지 activation function notebook
- Activation 함수 numpy 구현
- 목적
그 동안 아무 생각 없이 활성함수를 사용한 것 같다
특히 relu만 default로 사용하고 그 의미를 깊이 고민해본 적 없었다
이번 기회에 다른 기본이 되는 sigmoid, tanh과 다른 relu 가족들을 공부해보자
(sigmoid, tanh, relu, leaky_relu, elu, gelu)
ReLU 가족 정리
| 함수 | x<0 | x≈0 | x>0 | sparsity | gradient 특징 |
|---|---|---|---|---|---|
| ReLU | 0 (완전 차단) | 0 | 1:선형 | 높음 | Dead ReLU 가능, gradient = 1 |
| Leaky ReLU | (작게 통과) | 1:선형 | 낮음 | Dead ReLU 거의 없음, gradient = ~1 | |
| ELU | 부드럽게 0 근처 | x | 중간 | 음수 구간에서도 gradient 존재 | |
| GELU | , 부드럽게 통과 | 0~0.5x | 거의 x | 거의 없음 | Dead ReLU 없음, 부드러운 S자 곡선 |
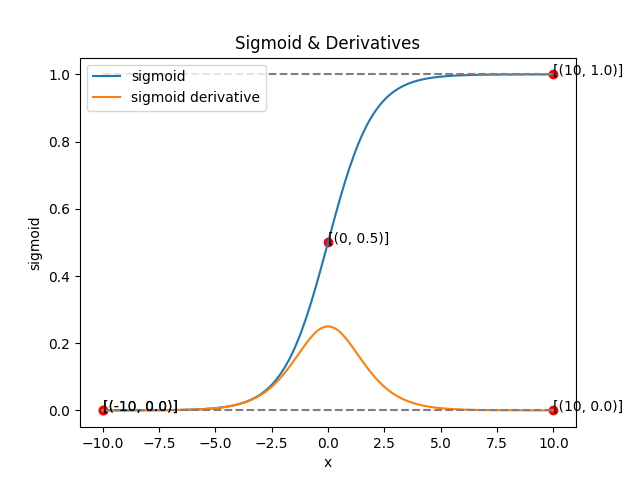
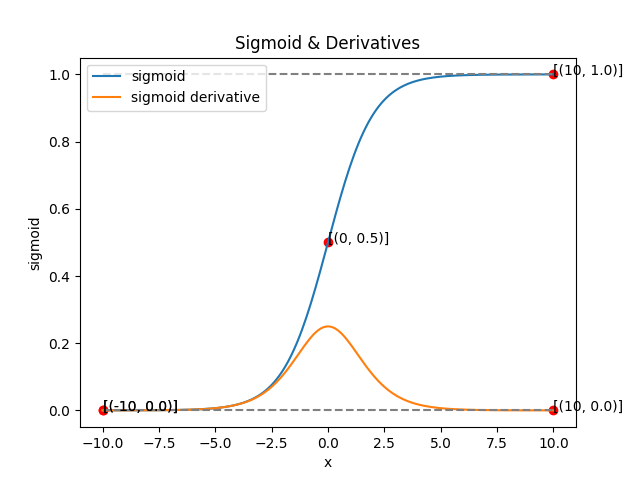
1. Sigmoid
- 정의
- 미분
- 특징
- 입력값을 0과 1사이로 매핑
- 출력을 확률처럼 해석 가능
- 미분 가능 backpropagation 사용 가능
- 단점: 입력값이 너무 크거나 너무 작으면 gradient가 0에 가까워지는 vanishing gradient 문제 발생
- 그래프 특징:
- x=0일 때,
- x
- x
- S자형 curve
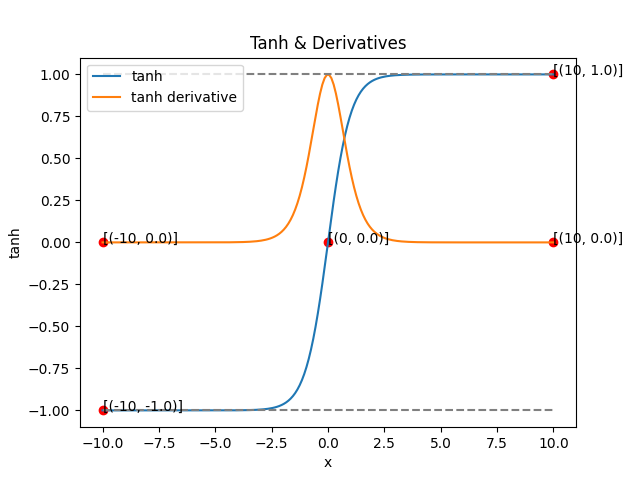
2. tanh
- 정의
- 미분
- 특징
- 입력값을 -1과 1사이로 매핑
- 출력을 정규화된 값처럼 해석 가능
- 미분 가능 backpropagation 사용 가능
- sigmoid와 달리 0이 중심이 되기 때문에 학습 속도가 조금 더 빠르다
- 학습이란? 모델이 데이터로부터 정답을 맞추는 능력을 키우는 과정
- ml에서 학습은 Backpropagation을 사용(gradient = 출력 * 다음 layer의 gradient)
- sigmoid: 출력이 항샹 양수 gradient 편향 학습이 느릴 수 있음
- tanh: 출력 0 중심 gradient 양/음 학습이 상대적으로 빠름
- 단점: 입력값이 너무 크거나 너무 작으면 gradient가 0에 가까워지는 vanishing gradient 문제 발생
- 그래프 특징:
- x=0일 때,
- x
- x
- S자형 curve
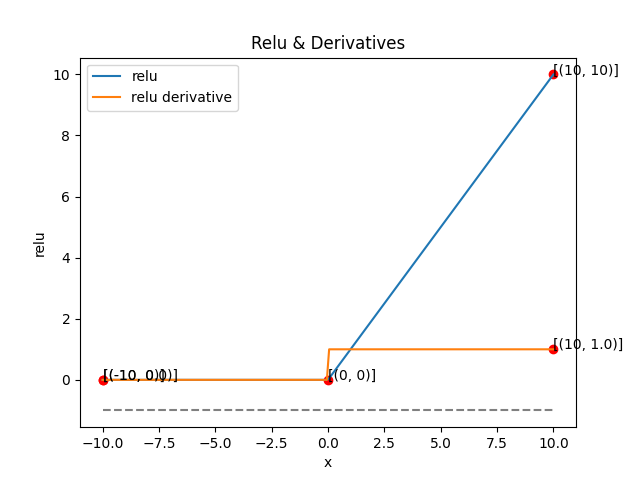
3. ReLU
- 정의
- 미분
- 0에서 미분이 정의되지 않지만 일반적으로 위와 같이 정의합니다.
- 특징
- 입력값을 0이상으로 변환
- 비선형 함수이지만 계산이 매우 간단
- 미분 가능 backpropagation 사용 가능
- x=0에서만 미분 불가능하지만, 실제 학습에서는 문제
- Vanishing Gradient 문제를 완화
- sigmoid/tanh는 입력이 크면 gradient가 0에 근사하게 작아짐
- ReLU 는 X>0인 구간에서 gradient=1 gradient 소실 문제 완화
- Sparse Activation(희소 활성화)
- 음수 입력은 0이 되므로 일부 neuron만 활성화 됨
- 이는 연산 효율성과 일반화(regularization) 측면에서 도움이 됨
- 단점: Dead ReLU problem
- 학습 중 일부 neuron의 입력이 계속 0보다 작으면
- gradient가 0 가중치가 업데이트되지 않음
- neuron이 "죽은" 상태가 됨(출력이 항상 0)
- 학습 중 일부 neuron의 입력이 계속 0보다 작으면
- Sparse Activation이란?
- 많은 뉴런에서 0을 출력하고 일부만 활성화되는 상태
- 한 번의 입력에서 전체 뉴런 중 일부만 켜지는(활성화) 현상
- [0, 0, 3.2, 0, 0, 5.1, 0]
- 3.2와 5.1만 활성화 되었다고 할 수 있음
- 이런 상태를 sparse 하다고 함
- 활성 함수 ReLU가 input의 음수를 비활성화 하기 때문에 발생
- 장점?
- 계산 효율성: 0을 출력하는 뉴런은 이후 계산에 거의 참여하지 않음
- 일반화 효과(regularization): 일부 뉴런만 작동하므로 너무 많은 feature에 의존하지 않음
- 단점?
- 정보 손실
- dead relu
3-1. Vanishing Gradient
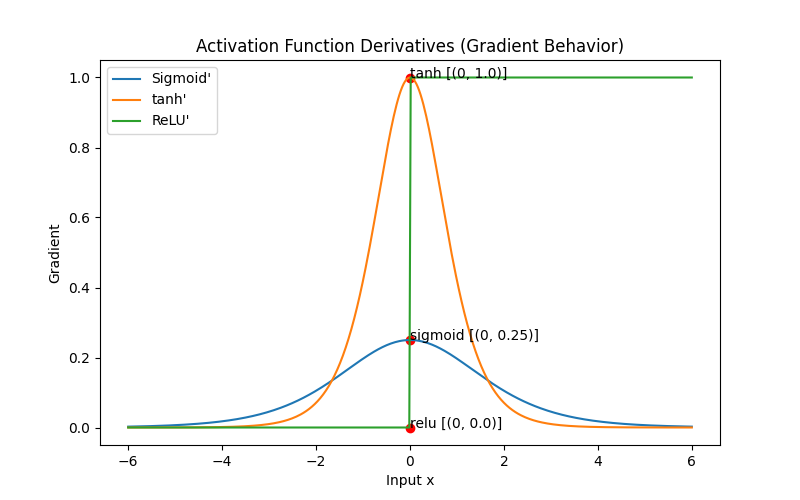
- X값의 구간에 따른 Gradient 값
| 구간 | Sigmoid | tanh | ReLU |
|---|---|---|---|
| x < -3 | 거의 0 | 거의 0 | 0 |
| x ≈ 0 | 약 0.25 | 1 | 0~1 |
| x > 3 | 거의 0 | 거의 0 | 1 |
- 정리
- sigmoid & tanh은 입력이 0근처에서 0.25와 1이 최대
입력 값이 커지거나 작아지면 gradient가 0에 근접 소실 - ReLU는 x>0 구간에서는 gradient=1
gradient가 계속 살아남음 학습이 잘 전달됨
- sigmoid & tanh은 입력이 0근처에서 0.25와 1이 최대
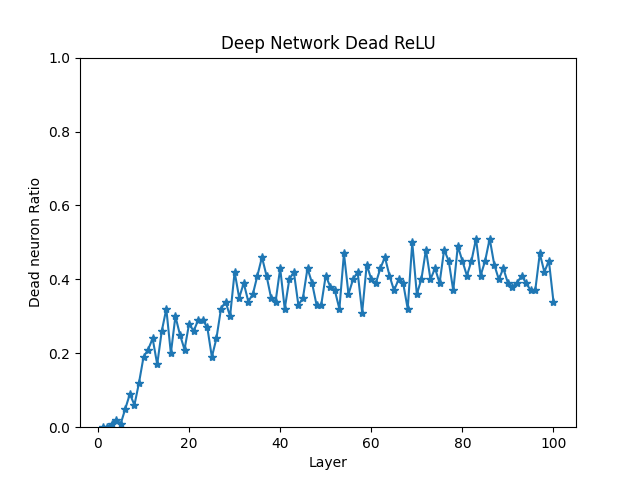
3-2. Dead ReLU
ReLU의 출력이 0인 상태가 계속 유지되어,
해당 neuron gradient가 가중치가 업데이트되지 않는 문제
즉, 입력이 계속 음수면 neuron이 "죽어서" 항상 0만 출력
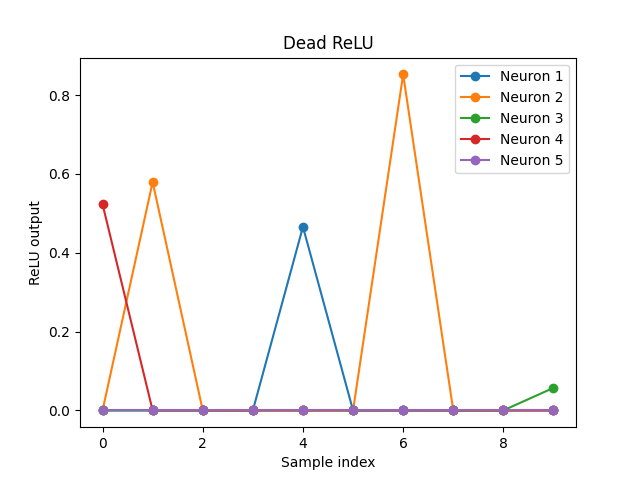
- inputs는 평균을 -1로 설정하여 음수 입력이 많음
- ReLU를 거치면서 음수 입력 0 출력
- 일부 neuron은 모든 샘플에서 0 Dead ReLU 발생
- 출력 그래프에서 평평하게 0인 neuron이 바로 dead neuron
4. Leaky ReLU
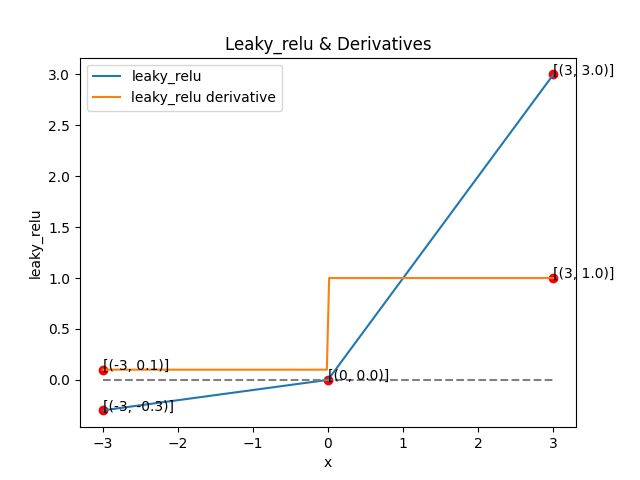
- 정의
- 미분
- 0에서 미분이 정의되지 않지만 일반적으로 위와 같이 정의합니다.
- 특징
- ReLU의 변형 버전
- 음수 구간에서 alpha라는 상수를 부여
- Dead ReLU 문제 완화
- ReLU는 이면 완전히 0이 되어 gradient가 사라지는 단점이 있다(dead relu)
- Leaky ReLU는 아주 작은 상수를 통해 완전히 사라지는 것을 막는다
- Vanishing Gradient 문제 완화
- 음수 부분에서도 작은 gradient가 존재
- 단점
- 음수 입력에서 출력이 조금 남아 있어서 완전한 희소성(sparse activation) 이 사라짐
- 값을 잘못 설정하면 학습 불안정
- 가 너무 크면 음수 방향으로 과도한 출력
- ReLU의 변형 버전
5. ELU(Exponential Linear Unit)
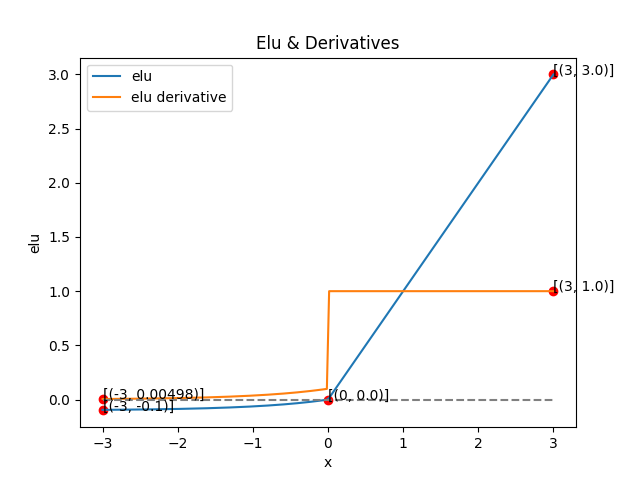
- 정의
- 는 음수 영역의 완만함을 조절하는 상수(보통 1)
- 미분
- 0에서 미분이 정의되지 않지만 일반적으로 위와 같이 정의합니다.
- 특징
- ReLU의 변형 버전
- 음수 입력을 완전히 죽이지 않고 부드럽게 이어줌
- 음수 구간에서 출력이 0보다 작지만 0은 아님
- 장점
- dead relu 문제 완화
- vanishing gradient 완화
- 단점
- 계산 비용 증가
- 계산 필요 ReLU보다 연산량 많음
- Sparse Activation 감소
- 설정 필요
- 계산 비용 증가
- ReLU의 변형 버전
6. GELU(Gaussian Error Linear Unit)
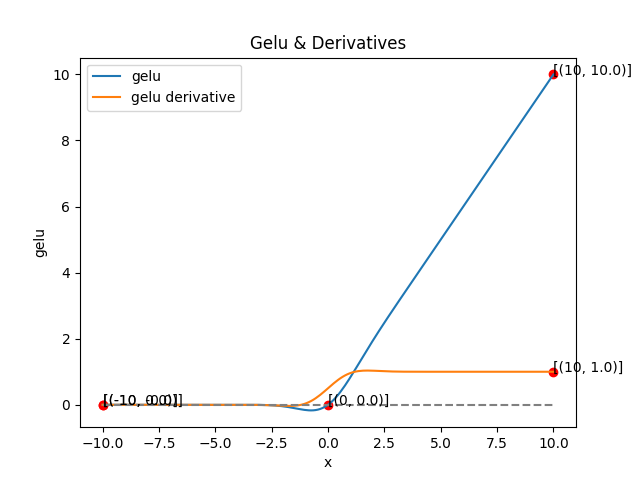
- 정의
- 여기서 는 표준 정규분포의 누적분포함수(CDF)
- 근사식(실제 구현에서 자주 사용)
- 미분
- 근사식 기준 미분은 복잡하지만, 수치적으로 계산 가능
- 연속적이고 전 구간에서 미분 가능
- 특징
- ReLU의 부드러운 확률적 버전
- 입력값 x가 클수록 활성화 될 확률이 높음
- 입력값 x가 작을수록 비활성화될 확률이 낮음
- 즉, 입력을 확률적으로 통과시키는 "soft gating"
- 완저히 0이 되지 않아 dead neuron이 없음
- 전 구간에서 연속적으로 부드러운 미분 학습 안정적
- BERT, GPT 등 Transformer 기반 모델의 기본 활성화 함수로 사용됨
- ReLU의 부드러운 확률적 버전
- 장점
- ReLU보다 매끄럽고 gradient 흐름이 자연스러움
- dead relu 문제 완전 제거
- vanishing gradient 완화
- 학습이 더 안정적이며 성능 향샹(특히 대규모 모델)
- 단점
- 계산 복잡도 증가(erf, tanh 연산 포함)
- 완전히 sparse 하지 않음 모든 뉴런이 어느 정도 활성화됨
Soft gating 이란
- 입력을 0~1 확률로 곱해서 통과시키는 부드러운 문(gate)
- Gate: 문을 열고 닫는 장치
활성화 함수에서 "출력을 얼마나 통과시킬지 결정하는 역할" - Soft: 부드럽게 열거나 닫음
0과 1처럼 완전히 꺼지거나 켜지지 않고, 중간의 어떤 값이 가능 - 에서
- = 0~1사이의 값(CDF, 누적 확률)
- x가 크면 거의 그대로 통과 ()
- x가 작으면 거의 막힘 ( 하지만 0은 아님)
- x가 0 근처 절반 정도만 통과
