Inductive Representation Learning on Large Graphs
https://arxiv.org/pdf/1706.02216.pdf
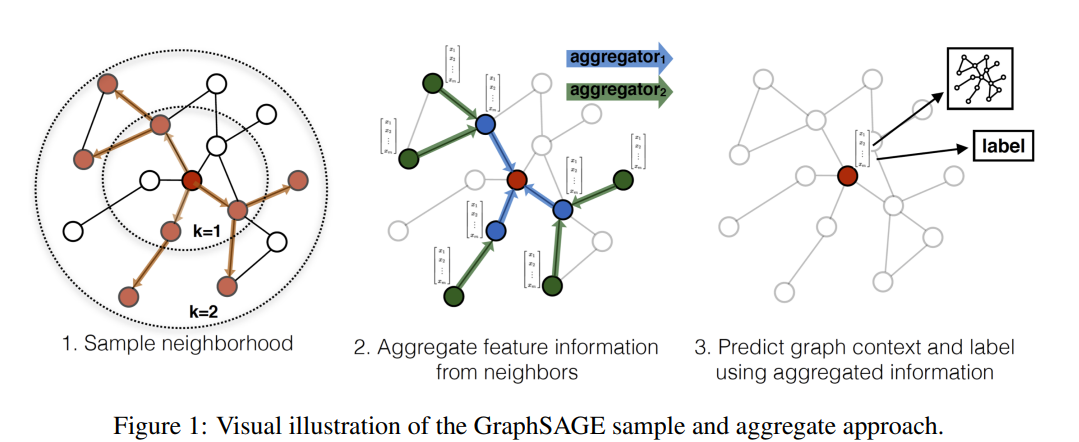
GCN은 spectral하다는 점에서(decomposition등을 다시해야하므로) 새롭게 추가되는 node에 대해서 처리하기 어렵다.
이런 점을 극복하기 위해 등장한 것이 GraphSAGE 이다.
- target node를 neighborhood와 aggregation하는 방법에 대한 이야기를 한다.
:input features
: weight matrix, k depth,
: non-linearity
: neighborhood function

Learning the parameters of GraphSAGE
Graph-based Loss function을 정의해서 적절한 representations를 unsupervised learning을 통해 배운다.
: 에서 fixed-length 만큼 random walk했을 때의 node
: non-linearity
: negative sampling distribution
: negative sampling 하는 개수
representation의 output은 이라고 할 때,
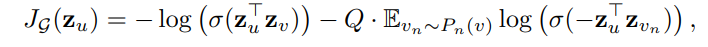
위 loss function 같은 경우 특정한 downstream task에 적합한 representation을 만들도록 수정 할 수 있다. (cross-entropy 처럼)
Aggregator
Mean aggregator
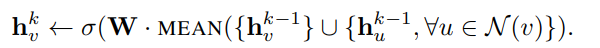
위 공식의 와 를 element-wise mean 연산한다.
해당 aggregator의 특징은 다음과 같다.
-
Algorithm1에서 CONCAT 하는 경우는 mean aggregator만 해당하는 과정이다. 아래 서술하게 될 다른 aggregator들은 해당 과정이 없다.
-
이전 layer (k-1)와 concatenate 한다는 점은 "skip
connection"과 상통하는 부분이 있다. -
거칠게 말하면 linear approxi. of a localized spectral convolution [GCN paper] 이라고 볼 수 있기 때문에, 저자들은 mean aggregator를 "convolutional aggregator" 라고 부른다.
LSTM aggregator
특징은 다음과 같다.
inherently symmetric ( i.e, permutation invariant )
Pooling aggregator
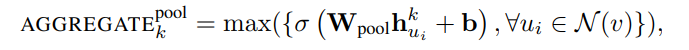
특징은 다음과 같다.
symmetric
trainable : learnable parameter 를 확인할 수 있다. fully connected neural network를 통해 feedback 된다. MLP를 Deep 하게 구성해도 되지만 저자는 single-layer를 구성했다.
저자는 mean aggregator와 pooling aggregator 사이의 유의미한 차이는 발견하지 못했다고 한다.
