1. Sequence-to-Sequence(Seq2Seq) Learning
간단히 말해 Sequence를 input-output, 순차적으로 처리하는 것
추천 논문: Sutskever et al., 2014 / Cho et al., 2014
추천 페이지: Alamar(Attention)
기본 구조
Input: Items의 Sequence를 받는 모델('각 아이템'의 '일련의 순서')
Items의 Sequence는 단어, 캐릭터, 사진의 특징 등이 될 수 있음
Output: Items의 Sequence를 또 다른(another) 결과물(출력)로 나타내는 것
ex) 
→ 이런 식으로 나름대로의 방식을 거쳐? 새로운 어떤 출력을 만들어 냄
여기서 주의해야될 점은 input이 세 개일 때 output도 꼭 세 개로 나오는 RNN 모델과는 달리 Input이 세 개여도 Seq2Seq 모델을 거친다면 해당 모델만의 방식으로 Ouput을 4개 혹은 그 이상이하를 출력할 수도 있다는 점!
그래서 자주 그리고 많이 사용되는 것이 Machine Translation Model
I(1) am(2) a(3) student(4) » Je(1) suis(2) étudiante(3)
핵심 아이디어 및 아키텍처
- Encoder
입력된 정보를 어떻게 '저장' 및 '처리'할 것이냐
각각의 Input Sequence의 Item을 process 시키고 그 Items가 가진 정보들을 컴파일해서 하나의 벡터로 재정의하는 역할
→ Context Vector
모든 정보들에 대한 Context Vector를 생성하면 Encoder가 Decoder에게 해당 Context Vector를 넘겨줌
- Decoder
Encoder에서 압축 입력된 정보를 어떻게 풀어서 반환(내놓을) 것이냐
Encoder에서 받은 내용을 Item by Item으로 시퀀스를 출력
그렇다면!!!
Encoder-Decoder는 어떤 아키텍쳐를 기반으로 작용할까?
제일 기본은 기본 중의 기본 RNN을 사용
해당 글에서도 RNN을 사용하는 Seq2Seq을 전제하고 설명하겠다
RNN 정리는..... 추가로 할 수 있다면 하겠음
불가능이란 없다!!!
각각의 Hidden State가 업데이트되면서 가장 마지막, 최종의 Hidden State가 Context Vector로 Encoder에서 다 들어오면 Decoder에서 출력으로 작용
RNN의 매커니즘을 잘 생각하며 이해해야됨!! 앞의 Hidden State에서의 결과물이 다음으로 전달되며 업데이트, 쉽게말해 각 Hidden State가 순차적으로 업데이트 및 누적되며 최종 Hidden State가 만들어지며 그걸 통해 Context Vector가 만들어지고 Decoder으로 출력이 만들어짐
But!!!
여기서 생길 수 있는 문제점!!! Gradient Vanishing....!!
간단히 설명하자면 첫 번째 단어는 처음엔 1의 가중치를 가지지만 뒤로 갈수록 쪼개지고 더 쪼개어진다. 그렇다면 문장이 길어졌을 때, 첫 단어의 의미가 소실될 수도 있다는 말이다.
이 점을 어느정도 완화 및 보완하기 위해 LSTM이나 GRU가 나왔지만...
완벽한 기술이란... 없는 법.....
Attention
따라서 최근에 Attention~이라는 개념을 차용한다
Attention이 나온지 좀 됐는데 당시 엄!청!나!게! 센세이셔널했다고 ..!!
원래라면 Context Vector 자체는 긴 Sequence에 대해서 취약한 점이 많았지만 Attention은 Input Sequence의 Item 중에 특히 주목하고 싶은 부분들에 추가 가중치를 줄 수 있게 연구자가 설정할 수 있도록한다.
- Bahadanau Attention
- Luong Attention
이렇게 두 가지의 Attention 모델이 있는데 실제 실험결과에 따르면 두 개의 결과가 눈에 띄게 다르진 않았다고 함
따라서 우선 전반적인 Attention을 활용한 Seq2Seq에 대해 설명하겠다
Attention in Seq2Seq
✨차이점: 더이상 Encoder에 들어가는 Sequence의 최종 Hidden State '뿐만 아닌' 전반적인 State의 정보를 다 Decoder로 넘겨줌!✨
ㄴ Decoding이 수행되는 과정에서 특히 더 필요한 Hidden State를 입맛에 맞게 골라 서로 다른 가중치를 부여해 활용 가능
예를 들어,
I am a student에서 제일 중요한 부분은 무엇일까? I도 아닌, am도 아닌, 'Student'이다! 지금 이 문장이 단순한 문장이어서 그렇지 더 긴 문장 혹은 더 복잡한 정보를 가진 Sequence를 기계 번역 혹은 학습을 시킬 때 이는 매우매우 효율적이고 중요한 작용을 할 것이다!
그래서 Attention in Seq2Seq을 활용한다면 Je(I) 혹은 suis(am)은 연하게, 즉, 크게 중요하지 않게 표시가 될 것이고 'étudiante'(Student)는 진하게 표현 될 것이다.
위의 내용은 Encoder쪽의 관점이 더 부여되었다.
이제 Decoder의 관점에서의 Attention in Seq2Seq Learning을 공부해보겠다.
원래의 경우, 아무리 Gradient Vanishing이 완화된 LSTM이나 GRU의 경우라도 최종 Hidden State가 속한 단어가 제일 큰 가중치를 가진다는 것이 전제이자 문제이다.
하지만 Attention은 각 Hidden State에 대해 Score(가중치라 생각해도 될 듯?!)를 부여한 후 입력 신호의 총합을 출력 신호로 변환하는 함수인 Activation Function(활성화 함수), Softmax를 적용
활성화 함수로 구해진 총합으로 하나의 Weighted Vector를 생성 → Context Vector가 되고 해당 내용을 Decoder에서 Output을 만드는 정보로 사용되게 함!!
실제 Decoder로 넘어갈 때는 Hidden State Vector와 마지막에 생성된 Context Vector가 concat을 하고 사용함(이어 붙이는 그 concat 마자요)
말이 장황한데 다시 더 간략히 정리해보겠다.
Step1. Encoder에서 Sequence를 받은 다음 가중치를 더할 단어를 선정 후, Score 부여
Step2. Hidden State에 대해 부여된 Score을 Softmaxed Score로 Weighted Vector 생성(이는 Context Vector로 작용)
Step3. 생성된 Context Vector와 Hidden State Vector를 Concatenate(Tensor 크기 변화 있음)
Step4. Decoder로 넘어가서 출력 생성
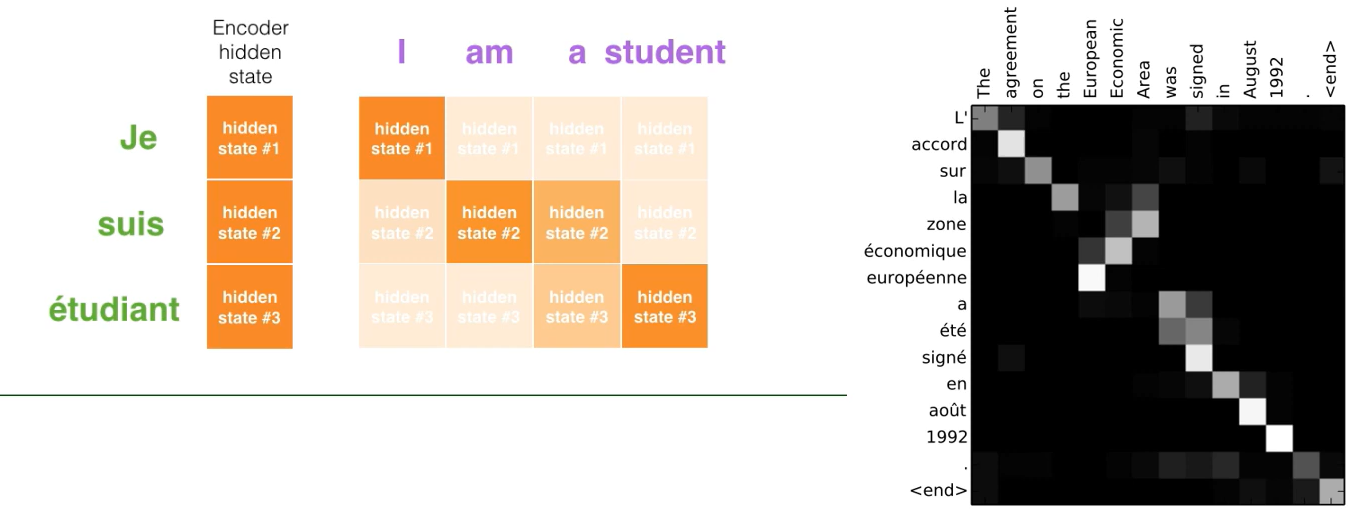
조금 더 자세히 말하자면 원래 모든 Sequence의 시작과 끝을 알리는 Flag같은 존재가 <bos> 혹은 <sos>, 그리고 <eos> 이런 식으로 있다. 아마 해당 Heatmap에서 있는 <end>가 저 <eos>를 뜻하는게 아닐까 유추해본다.
2. Transformer
..

다음 포스팅에서.....
.........
..............

결론:
Tensor 공부를 게을리 하지 말았어야한다..
머릿속에서 빠르게 돌아가지 않는 이상.......

직접 코딩 실습을 하며 느낀 점이기도 하다.
Pretrained 모델을 사용하기엔 문제가 덜할 수 있지만 진짜 공부해보고싶고 파고들고싶다면 이 내용은 정말 새 발의 피일 것이다.
더 깊게 공부해보고싶다면~ 논문 추천 ㅋㅋ..
참고 자료:
https://youtu.be/0lgWzluKq1k?feature=shared 외 ISNLP 출처의 스터디 자료
