Seq2Seq!
너무나도 어려운 모델이다
모든 공부가 그렇겠지만 겉보기엔 단순히 RNN이랑 같네~ 했는데 내가 잘못 이해했던 것이었다.
Sequence-to-Sequence
말 그대로 순차 데이터를 입력으로 사용하고 순차 데이터도 출력으로 생성하는 기계 학습 모델
관련 수업을 어제 들었는데 나에게는 새롭게 다가오는 말이 있었다.
AI에게는 '생성'도 '분류'이다.
맞는 말이더라 하하 싱기하다
Seq2Seq 모델은 Neural Network, 특히 Recurrent-Neural-Network(RNN)을 활용해 문제를 해결
해당 아키텍처는 NLP작업을 위한 '기본 프레임워크' ㄱ=...로 크게 'Encoder'와 'Decoder' 두 개의 모듈로 구성됨
✍🏻 Encoder(인코더)
입력 시퀀스를 처리 및 고정된 크기로 Context Vector에서 정보를 탐지
Source 문장을 입력받음
- Architecture:
- 입력 시퀀스를 인코더에 넣음
- 인코더가 신경망을 사용하는 입력 시퀀스의 각 요소들을 처리
→ 해당 과정을 통해 인코더는
- '내부상태' 유지
- Context Vector역할을 하는 최종 은닉 상태로 작동
(Context Vector: 전체 입력 시퀀스의 압축된 상태를 캡슐화한 것이며 입력 시퀀스의 시멘틱한 의미나 주요 정보들을 탐지)
이런 인코더의 최종 은닉층은 Context Vector를 인코더에서 디코더로 전달
🖨️ Decoder(디코더)
Encoder 블록과 유사하지만 Encoder로부터 받은 Context Vector를 점진적으로 출력 시퀀스를 생성
Target 문장을 생성
Initial Hidden State로써, Encoder의 Last Word의 'Hidden State'를 입력 받음
또한 현재 Token을 입력받아 다음 Token을 예측하도록 학습
→ 전의 단어를 기준으로 다음 단어를 예측/추론하는 형식
What if, 앞의 단어가 없는 '문장의 시작'에서는?!
» 문장의 시작을 알리는 로 문장의 시작을 선언
» 문장의 끝을 선언하는 가 다음 단어로 예측/추론될 때까지 학습 및 수행
이런 흐름으로 decoder가 수행됨
- Architecture:
- 훈련 단계에서 Decoder는 Context Vector랑 출력하고자하는 출력 시퀀스 둘 다 받음
- 추론과정에서 이전에 생성된 자체 출력을 후속 단계의 입력으로 사용
전반적인 Seq2Seq의 아키텍쳐
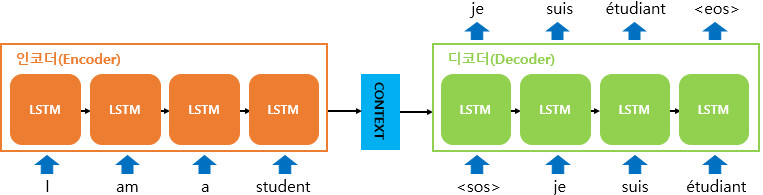
이러한 Seq2Seq 모델은 RNN을 기본 셀으로 사용하지만 Source와 Target의 단어수가 항상 일치할 수 없는 점과, 나라마다 어순이 다르다는 점을 보완할 수 있는 모델이다.
예를 들어, I(1) am(2) a(3) Student(4).(5)와 Je(1) suis(2) étudiante(3).(4)는 같은 '저는 학생입니다'의 의미를 가지나, 단어의 수가 다르다.
이러한 문제가 발생하는 이유는 다음과 같은 RNN의 특징 때문이라 볼 수 있다.
RNN은 순차적으로 입력되고 출력된다.
RNN은 input과 output의 1:1 대응을 가진다.
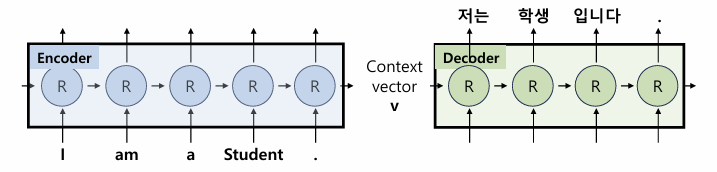
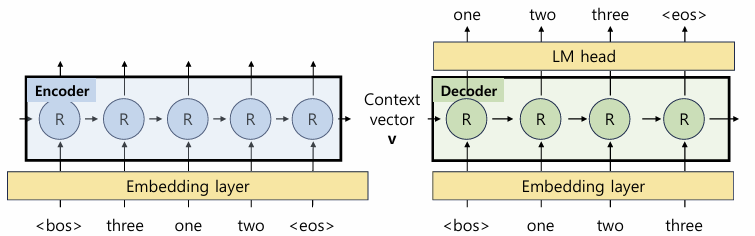
다만 내가 헷갈렸던 것은 Tensor를 이동시키는..? 연결시키는..? 그 작업이 머릿속에서 잘 발생하지 않았다.. 많은 노력을 해야될 것으로 예상..
근데 문제는 이거 헷갈리면 LM head에 누가 들어가고 input이 누구고 다음으로 나와야되는 output의 tensor가 어떻게되고 이게 계속 헷갈리더라.. 아...
🌄 요약
- RNN(혹은 Transformer, GRU 등을 사용) 셀을 활용하는 해당 Seq2Seq 모델은 특히 번역 모델에서 흔히 사용하며 또한 반복되는 형태를 가지고있다.
- RNN의 특징 상, 4개의 input이 들어가면 4개의 output이 나와야하지만 번역을 하며 발생하는 언어간의 차이로 1:1대응이 안되는 문제점을 보완할 수 있는 모델
- 시작할 때는 (beginning of sentence)가 꼭 있어야되며 마무리 할 때는 (end of sentence)가 추론 될 때까지 추론을 진행한다. - Seq2Seq은 학습 단계에서 Teacher Forcing(교사 강제)을 활용함(AtoZ로 다 알려주며 훈련)
- Seq2Seq은 학습 완료 후의 단계에서는 출력을 생성하기 위해 학습된 내용을 바탕으로 Inference(추론)를 수행함
✨ To-Do 💪🏻
- LM head에 대한 소개
- 코드를 활용한 Seq2Seq 구현 방식
- Auto-Regressive에 대한 설명
- 관련 논문(https://arxiv.org/pdf/1409.3215) 읽고 더 전문적인 내용으로 정리
- 조교님한테 첫 번째로 통과받기 ㅡ,,ㅡ
