0️⃣ 그래프 탐색
그래프 탐색이란, 하나의 시작점 노드에서 연결된 노드들을 모두 찾는 것을 의미한다.
시작점 노드는 정하기 나름이며 이 시작점으로부터 다른 노드들을 찾아가는 것이다.
- 그래프탐색 활용
- 주어진 두 노드가 경로를 통해 연결됐는지, 안 됐는지를 알아낼 수 있다.
- 두 노드사이의 최단경로를 알아낼 때 그래프탐색을 이용한다.
- 정렬 ... 등 다양한 곳에 사용된다.
- 그래프탐색 종류
- 그래프탐색 알고리즘은 각 노드들을 어떤 순서로 탐색하는지에 따라
Breadth First Search와Depth First Search로 나눈다.
1️⃣ BFS(Breadth First Search)
Breadth는 너비를 뜻한다. 쉽게 생각해서 높이(혹은 깊이)와 반대되는 표현이라고 생각할 수 있다. BFS는 따라서 너비를 우선적으로 탐색하는 것을 의미한다.
그래프에서 너비를 우선으로 탐색하겠다는 게 무슨 말일까? 아래 예시를 봐보자.
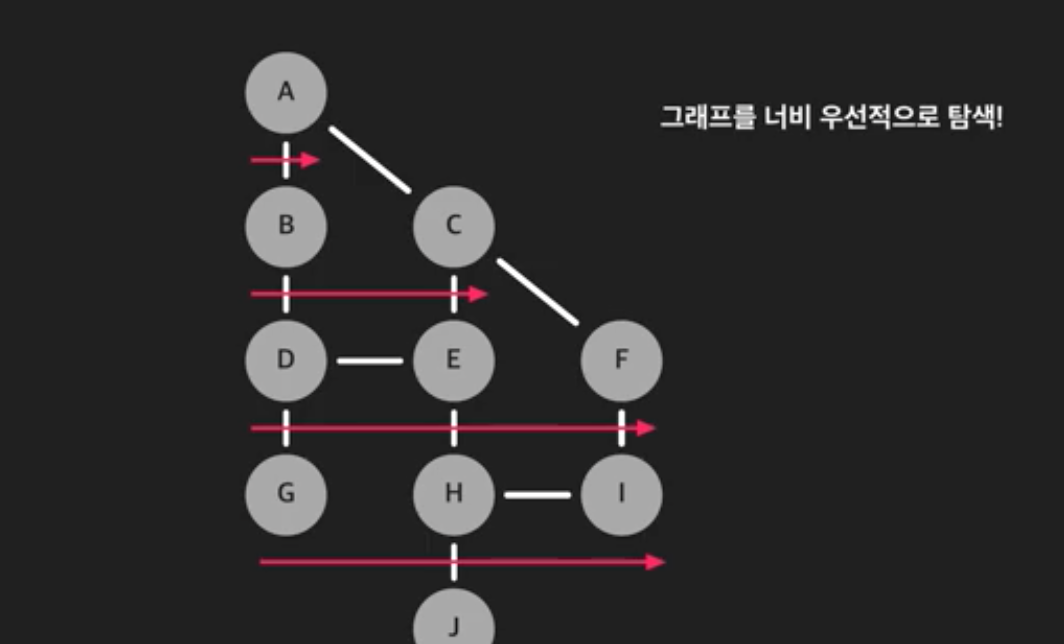
- 이렇게 생긴 그래프에서 A 노드에서 먼저 탐색을 시작하면, B, C, D, E, F .. 순으로 가까이 있는 것부터 차례대로 탐색한다. 이렇듯 화살표 방향대로 탐색하기 때문에 '너비'를 우선적으로 탐색한다고 하는 것이다.
✔️ BFS에서의 큐
큐는 BFS 알고리즘에서 굉장히 중요한 역할을 한다. 큐를 간단히 알아보자.
-
큐의 기능
- 맨 뒤에 데이터 삽입
- 맨 앞에 데이터 삭제
- 맨 앞 데이터 접근
큐는 이런 기능을 약속하는 추상자료형으로, 데이터를 가장 뒤에 추가하고 가장 앞에서 삭제할 수 있다.
이런 방식을 FIFO(First-in-First-Out)이라고 한다.
-
파이썬에서 큐 사용하기
from collections import deque
queue = deque()
# 큐 맨 끝에 뒤에 데이터 추가
queue.append("태호")
queue.append("영훈")
queue.append("현승")
queue.append("지웅")
# 큐 데이터를 출력한다
print(queue) # 태호, 영훈, 현승, 지웅
# 큐 마지막 데이터를 삭제한다
# popleft 메소드를 사용하면 가장 앞에 있는 데이터를 삭제한다.
# 보통 큐에서도 마지막 데이터를 삭제하면 해당 메소드가 삭제한 데이터를 리턴한다
print(queue.popleft()) # 태호
print(queue.popleft()) # 영훈
print(queue.popleft()) # 현승
# 큐 데이터를 출력한다
print(queue) # 지웅✔️ BFS 알고리즘
아래 예시를 보면서 하나하나 BFS 과정을 알아보자! 중요한 점이 이미 방문한 노드들과 그렇지 않은 노드들을 구별해야 한다.
- 먼저 A를 방문했다고 표시한 후, 큐에 넣자
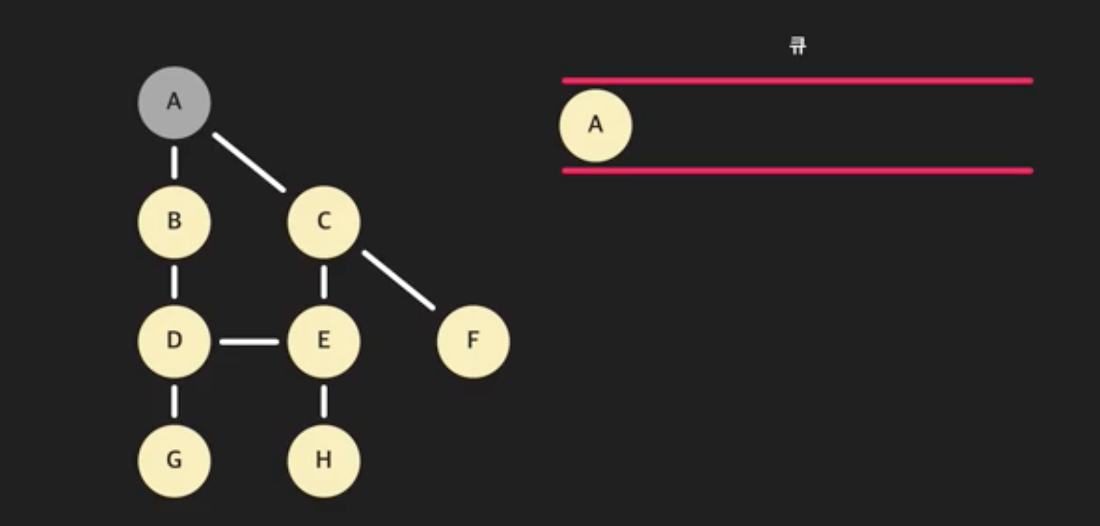
- 그리고 큐에 들어있는 노드가 없을 때까지 반복문을 돌리는데, 그 과정을 자세히 봐보자.
- 큐에 가장 앞 노드를 꺼낸다. (큐에 있는 A를 꺼내자)
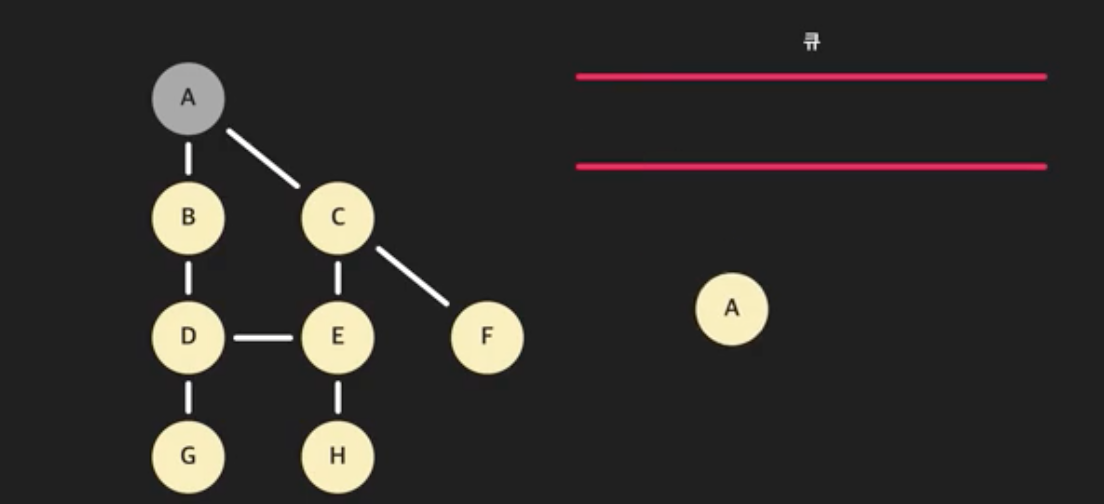
- 그리고 A에 인접한 모든 노드들을 돈다. 이때 이미 방문한 노드는 건너 뛴다. 노드 B는 A에 인접해있고 아직 방문하지 않았으니 큐에 넣는다. C도 큐에 넣는다. A와 인접한 노드는 처리했다.
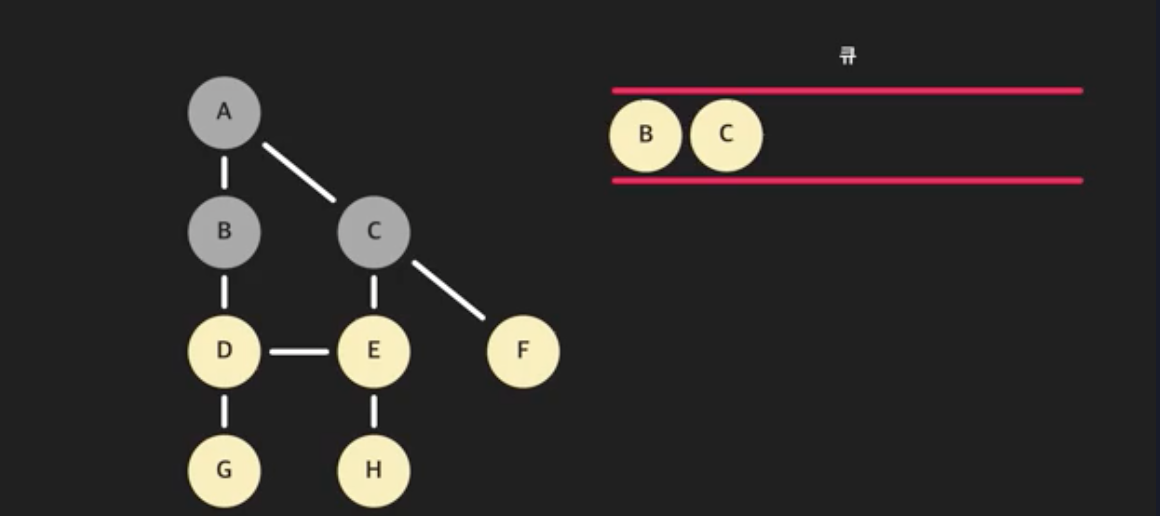
- 다시 큐에서 가장 앞 노드를 꺼낸다. (큐에 있는 B를 꺼내자)
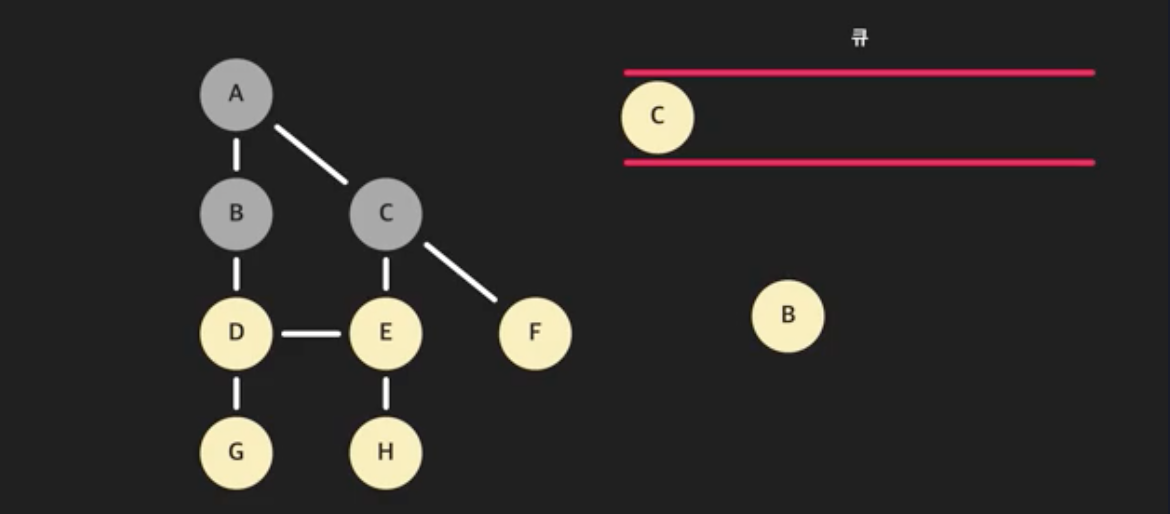
- B와 인접한 노드들을 돌자. A는 이미 방문한 노드이니 건너뛴다. 그다음 노드 D는 아직 방문하지 않았으니 큐에 넣는다. B와 인접한 노드는 처리했다.
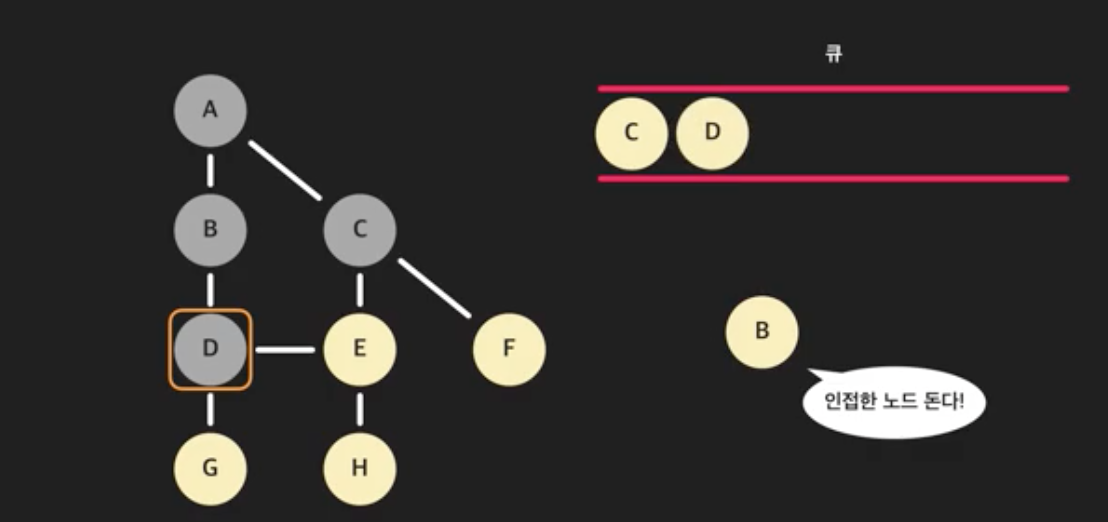
- 다시 큐에서 가장 앞 노드를 꺼낸다. (큐에 있는 C를 꺼내자)
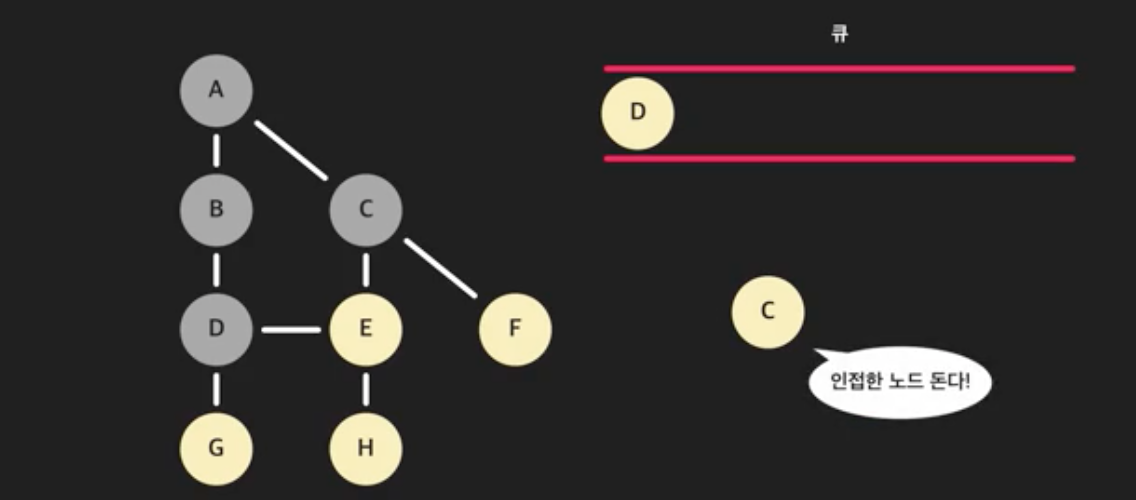
- A는 방문했으니 건너뛴다. E는 방문하지 않았으니 큐에 넣는다. F도 넣는다. C에 인접한 노드는 처리했다.
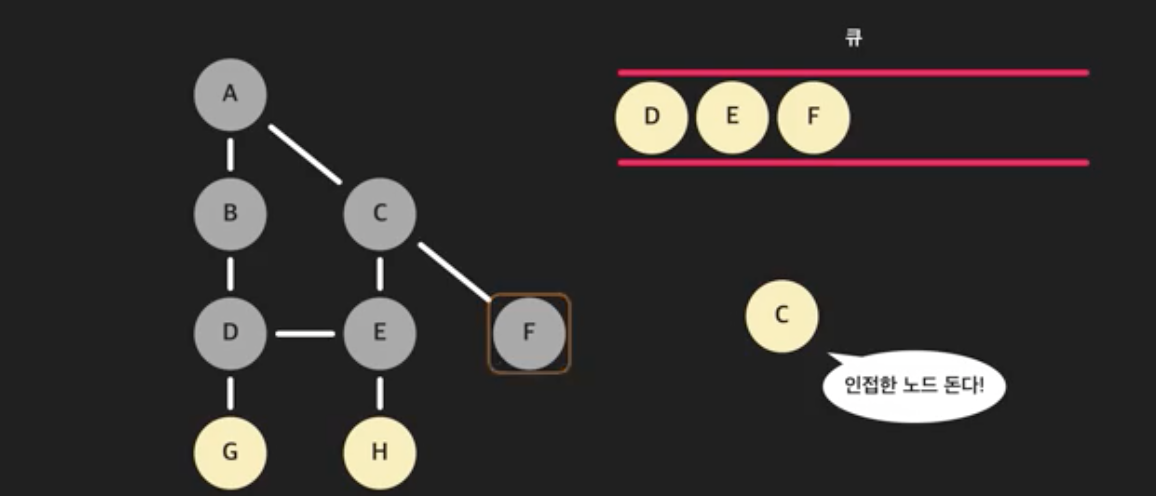
- 이런 과정을 계속 반복한다. 큐에 아무 노드도 없을 때까지 실행하면 A에서 연결된 노드들을 모두 찾을 수 있다. 노드들이 방문되는 순서를 보면 A, B, C, D, E, F, G, H 로, 위에서 아래보다 옆으로 먼저
너비우선적으로 탐색된다.
정리해서 일반화하면 아래와 같다.
- BFS 알고리즘
- 시작 노드를 방문 표시후, 큐에 넣는다
- 큐에 아무 노드가 없을 때까지 :
- 큐 가장 앞 노드를 꺼낸다
- 꺼낸 노드에 인접한 노드들을 모두 보면서 :
- 처음 방문한 노드면 :
- 방문한 노드 표시를 해준다
- 큐에 넣어준다
예제) BFS로 연결된 역 찾기
visited 변수로 방문을 확인한다. visited가 False면 방문하지 않은 역, Tru면 이미 방문한 노드이다.
from collections import deque
from subway_graph import create_station_graph
def bfs(graph, start_node):
"""시작 노드에서 bfs를 실행하는 함수"""
visited = []
queue = deque() # 빈 큐 생성
queue.append(start_node) # 처음에는 시작 노드 담아주고 시작하기.
# 일단 모든 노드를 방문하지 않은 노드로 표시
for station_node in graph.values():
station_node.visited = False
while queue: # 더 이상 방문할 노드가 없을 때까지.
node = queue.popleft()
node.visited = True
for station in node.adjacent_stations:
if station.visited is False:
queue.append(station)
stations = create_station_graph("./new_stations.txt") # stations.txt 파일로 그래프를 만든다
gangnam_station = stations["강남"]
# 강남역과 경로를 통해 연결된 모든 노드를 탐색
bfs(stations, gangnam_station)
# 강남역과 서울 지하철 역들이 연결됐는지 확인
print(stations["강동구청"].visited)
print(stations["평촌"].visited)
print(stations["송도"].visited)
print(stations["개화산"].visited)
# 강남역과 대전 지하철 역들이 연결됐는지 확인
print(stations["반석"].visited)
print(stations["지족"].visited)
print(stations["노은"].visited)
print(stations["(대전)신흥"].visited)2️⃣ DFS(Depth First Search)
DFS(Depth First Search)는 말그대로 깊이를 우선적으로 보고 탐색하는 것을 의미한다.
BFS와는 다르게 하나의 노드에서 최대한 깊이, 그리고 멀리 가는 탐색 방법이다.
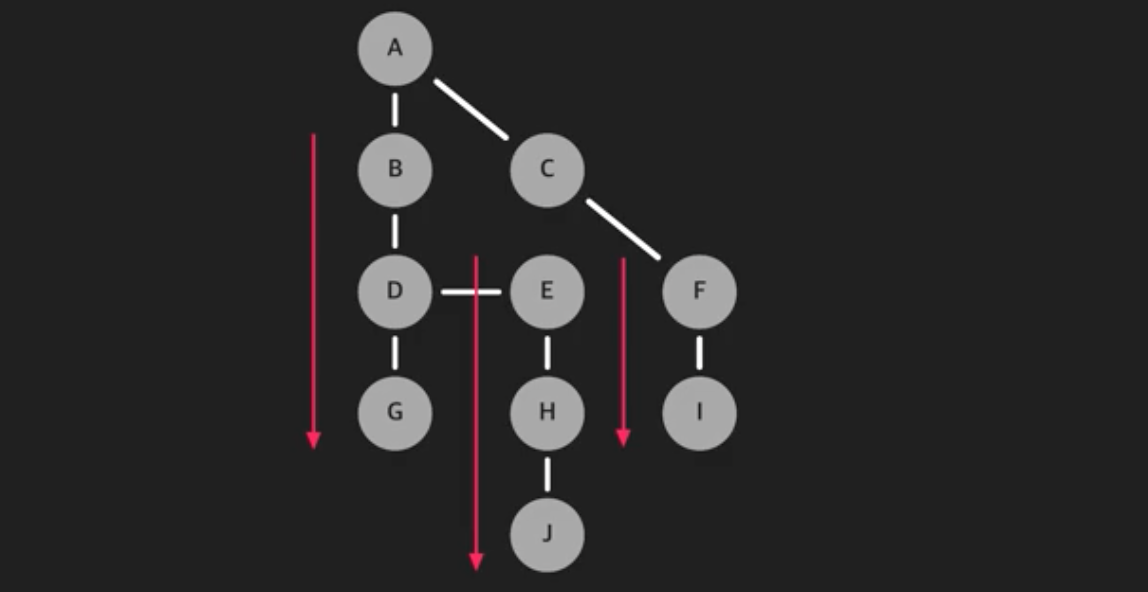
✔️ DFS에서의 스택
DFS에서의 중요한 추상자료형은 바로 스택이다.
- 스택의 기능
- 맨 뒤에 데이터 추가
- 맨 뒤 데이터 삭제
- 맨 뒤 데이터 접근
스택은 이런 기능을 약속하는 추상자료형으로, 가장 마지막에 들어간 데이터가 가장 먼저 나오기 때문에 이것을 LIFO(Last-In-First-Out)이라고 부른다.
- 파이썬에서 스택 사용하기
from collections import deque
stack = deque()
# 스택 뒤에 정보 추가: "Taeho!"
stack.append("T")
stack.append("a")
stack.append("e")
stack.append("h")
stack.append("o")
# 스택 정보를 출력한다
print(stack) # T, a, e, h, o
# 스택 마지막 정보를 삭제한다
# 파이썬 deque에서는 pop 메소드를 이용하면 뒤에서부터 데이터를 삭제할 수 있ek.
# 보통 스택에서 마지막 데이터를 삭제하면 해당 메소드가 삭제한 데이터를 리턴한다
print(stack.pop()) # o
print(stack.pop()) # h
print(stack.pop()) # e
# 스택 정보를 출력한다
print(stack) # T, a✔️ DFS 알고리즘
아래 예시를 보면서 하나하나 BFS 과정을 알아보자! 중요한 점이 BFS와 마찬가지로 이미 방문한 노드들과 그렇지 않은 노드들을 구별해야 한다.
- 먼저 A를 방문했다고 표시한 후, 큐에 넣자
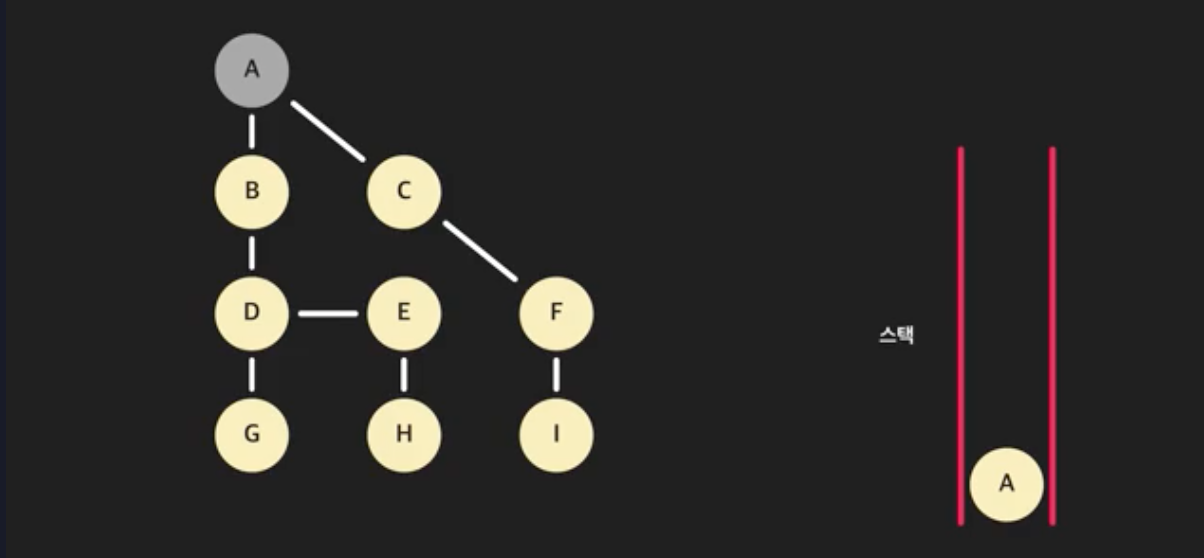
- 그리고 스택의 가장 위 노드 A를 꺼낸다. 그리고 A를 방문한 노드로 처리한다.
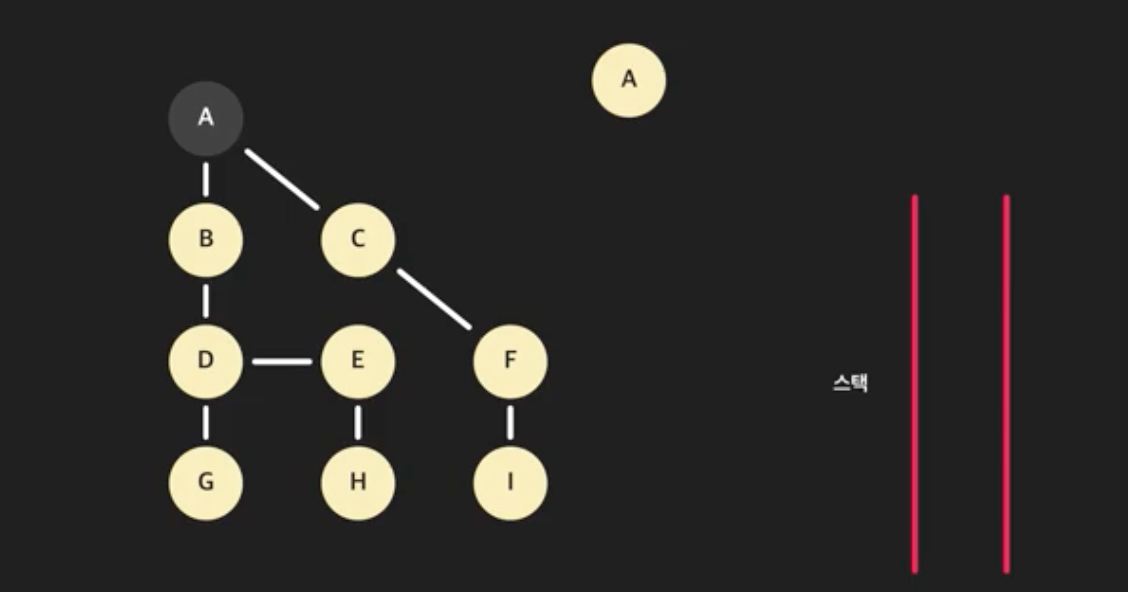
- A에 인접한 모든 노드를 돈다. 스택에 있거나 방문한 노드는 건너뛴다. C와 B를 스택에 넣는다. A와 인접한 노드는 처리했다.
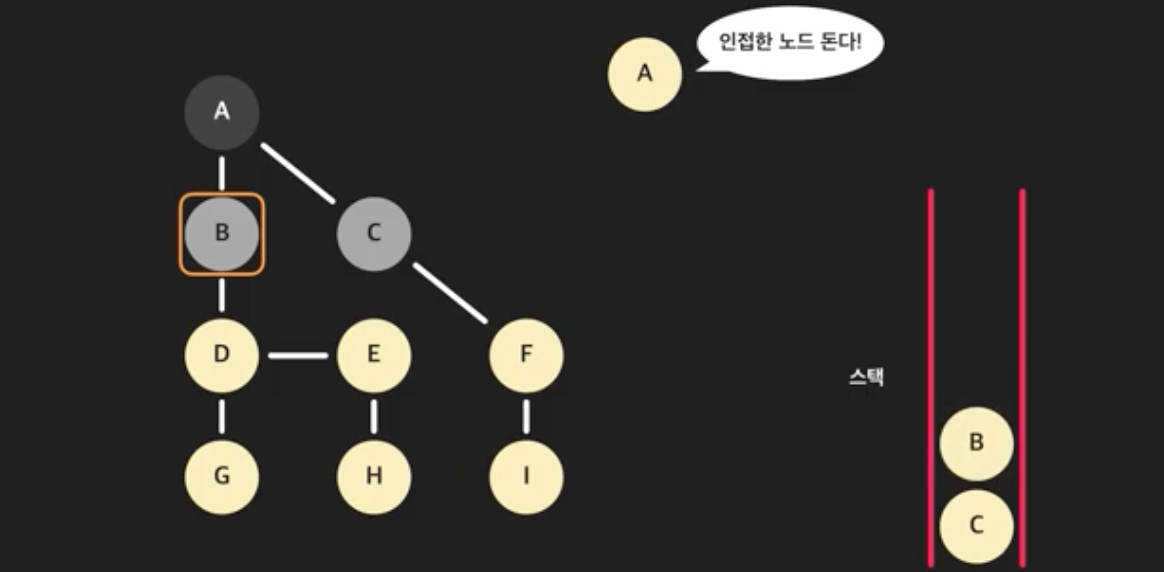
- 다시 스택의 가장 위 노드 B를 꺼낸다. B를 방문한 노드로 처리한다. 그리고 B와 인접한 모든 노드를 돈다. 이미 방문한 A는 건너뛴다. D는 방문하지 않았으니 스택에 넣고 표시한다.
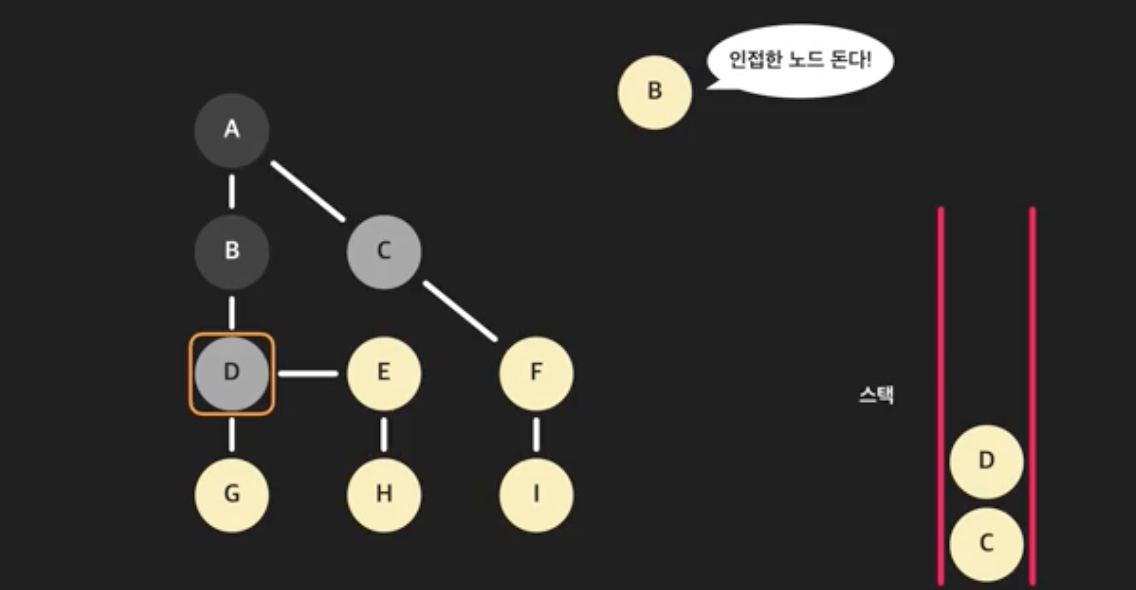
- 스택에서 D를 꺼내고 D를 방문한 노드로 처리한다. D의 인접한 모든 노드를 돈다. B는 건너뛰고, E와 G를 스택에 넣는다.
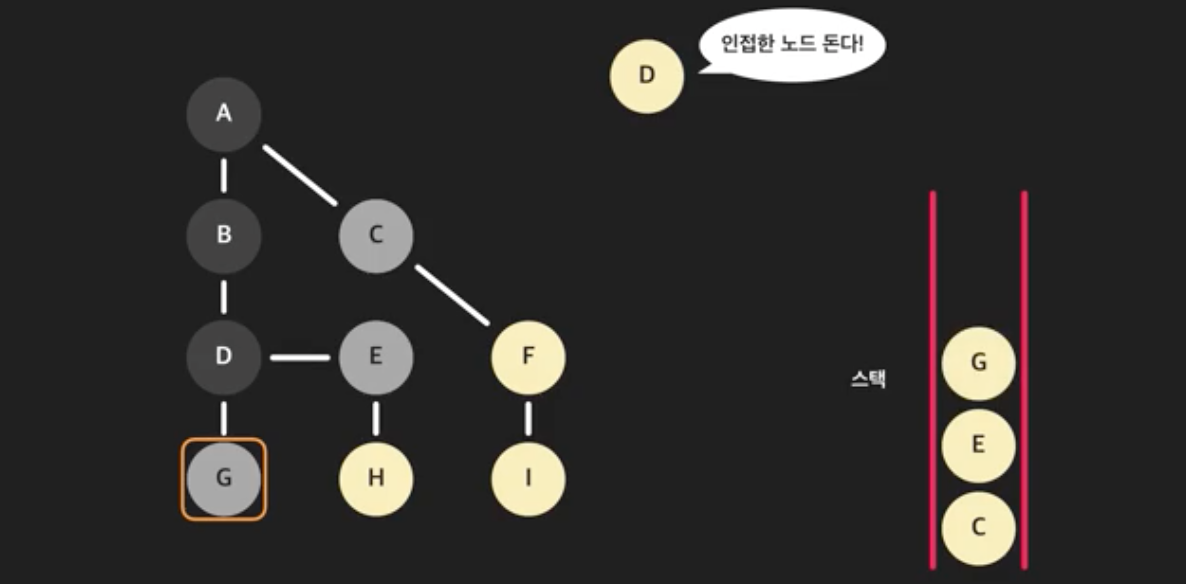
- 스택에서 G를 꺼낸다. G와 인접한 노드 중 방문하지 않은 노드는 없으므로 건너뛴다.
- 스택에서 E를 꺼낸다. E의 인접한 노드 중 방문하지 않은 노드 H를 스택에 넣어준다.
- 이런방식을 계속하여 스택에 아무노드도 남지 않을때까지 반복하면
깊이를 우선으로 한 탐색이 끝난다.
정리해서 일반화하면 아래와 같다.
- DFS 알고리즘
- 시작 노드를 회색 표시후, 스택에 넣는다
- 스택에 아무 노드가 없을 때까지 :
- 스택 가장 위 노드를 꺼낸다
- 노드를 방문(진한 회색) 표시한다.
- 인접한 노드들을 모두 보면서 :
- 처음 방문하거나 스택에 없는 노드면 :
- 옅은 회색 표시를 해준다
- 스택에 넣어준다
