✅ Multi-Querying Retriver
💡 하나의 질의(Query)를 다양한 방식으로 변형하여 여러 개의 질의를 생성하고, 이를 통해 검색 또는 정보 추출 성능을 향상시키는 방법
| 장점 | 단점 |
|---|---|
| - 다양한 검색 결과 확보 - 질의 표현의 다양성 반영 - 정보 누락 방지 - 질의의 의도 반영 | - 높은 계산 비용 - 중복 결과 반환 가능성 높음 - 검색 결과 관리의 복잡성 - 불필요한 정보의 과도한 검색/중요한 변형 누락으로 인한 질의 생성의 어려움 - 효율성 문제 |
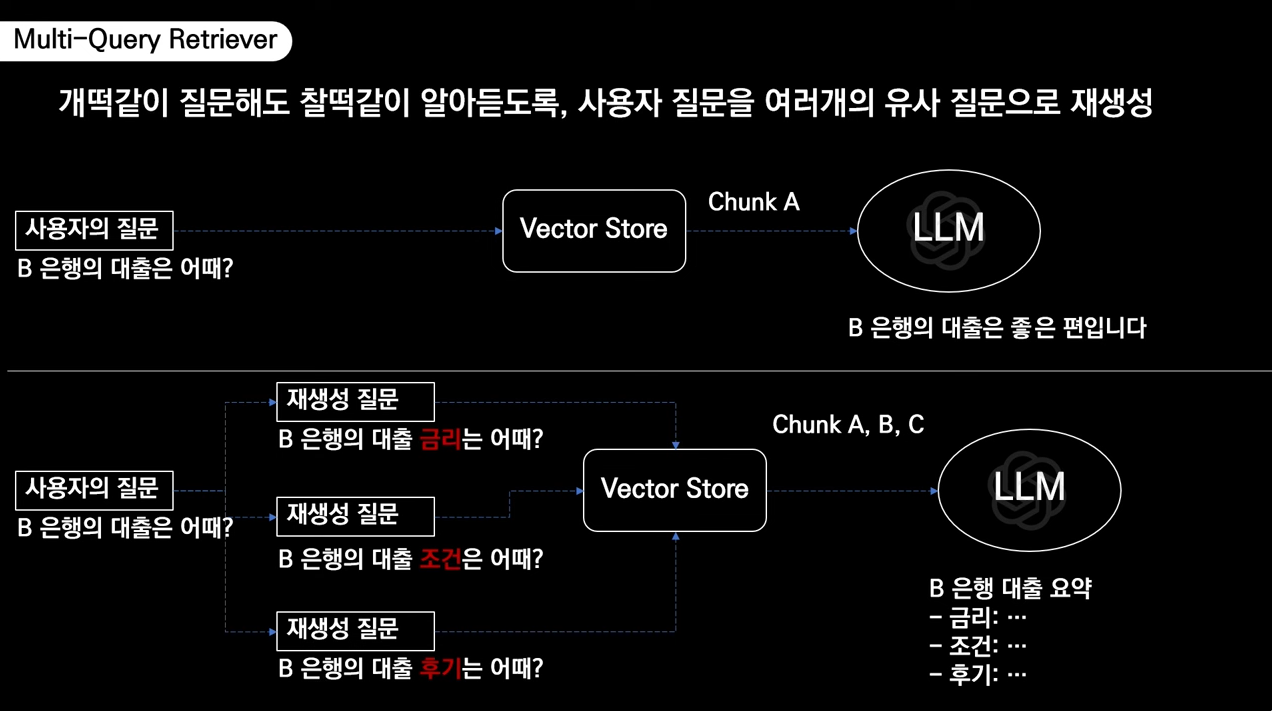
사용자 질문
삼성전자 갤럭시 S24는 어떨 예정이야?Multi-Query Retriever
1. 삼성전자 갤럭시 S24의 출시일은 언제인가요?
2. 삼성 갤럭시 S24의 기능과 사양은 어떻게 되나요?
3. 삼성 갤럭시 S24의 가격과 구매 가능 여부는 어떻게 되나요?✅ Parent-Document Retriver
💡 특정 질의에 대해 개별적인 문서(fragment)나 문서의 일부(segment)가 아닌, 해당 문서를 포함하고 있는 상위 문서(parent document) 전체를 검색하는 기법
| 장점 | 단점 |
|---|---|
| - 상위 문서를 검색하여 문맥 보존 | - 문서 전체를 검색하고 반환하기 때문에 검색 결과가 방대해질 수 있고 이를 처리하는 데 더 많은 자원이 필요할 수 있음 - 필요한 정보가 전체 문서의 작은 부분일 때 불필요한 정보를 과도하게 포함할 수 있음 |
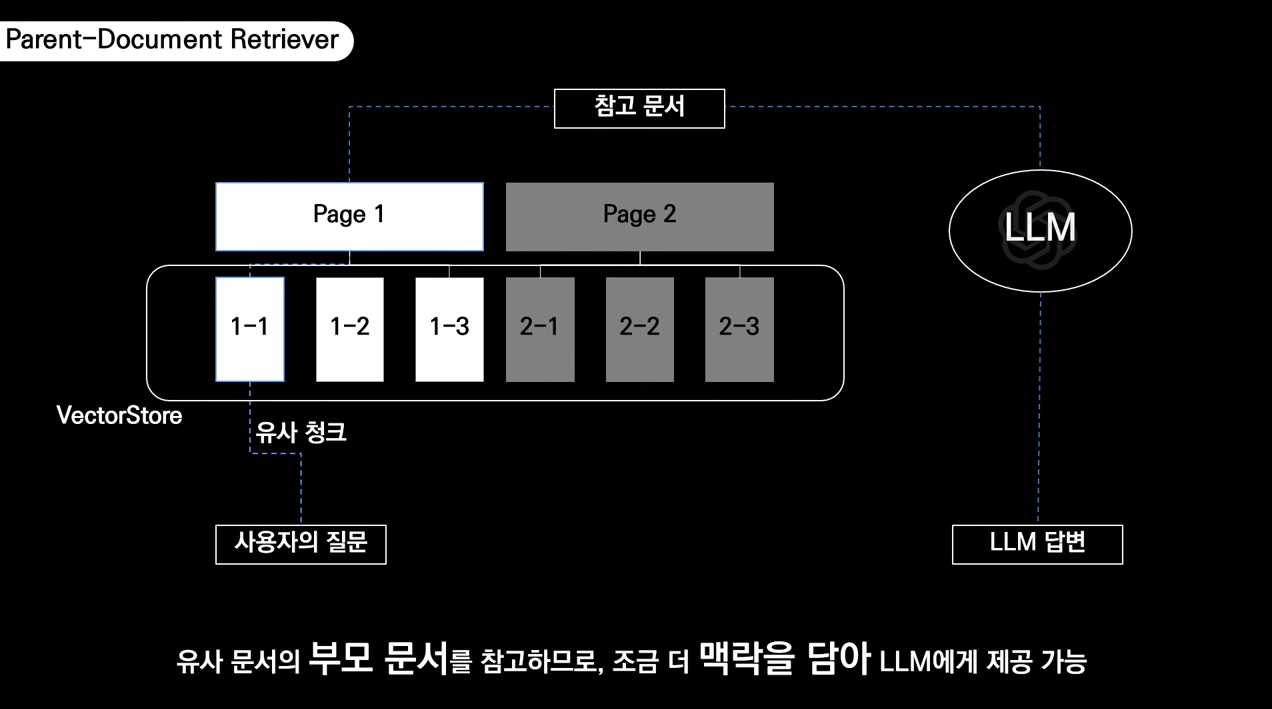
1-1과 사용자 질문이 연관되어 있다면 1-2와 1-3까지 참고
✅ Self-Querying Retriver
💡 사용자의 초기 질의를 바탕으로 시스템이 스스로 추가적인 관련 질의를 만들어 저장된 문서의 내용과 의미적으로 비교
💡 사용자의 질의에서 문서의 메타데이터에 대한 필터를 추출하고, 이 필터를 실행하여 관련된 문서를 검색
| 장점 | 단점 |
|---|---|
| - 향상된 검색 정확도 - 정보 회수율 증가 - 질의의 의도 파악 - 사용자 편의성 | - 계산 비용 증가 - 잠재적인 결과의 복잡성 증가 - 관련 없는 질의 생성 위험 - 사용자 제어 감소 - 복잡한 설정 및 유지 관리 |
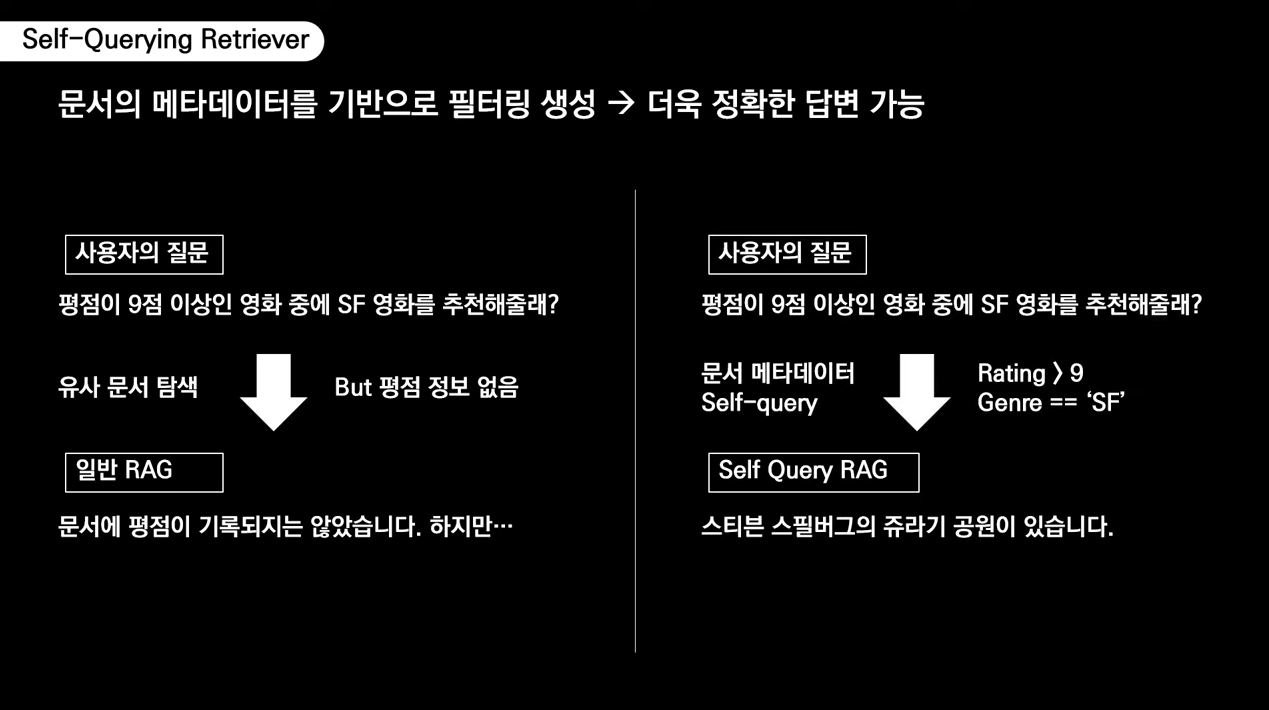
질문하는 것이 필터링 필요한 작업에 적합한 리트리버
✅ Time-weighted Vector Retriever
💡 정보 검색 시스템에서 시간 요소를 고려하여 검색 결과의 순위를 매기는 기법
💡 시간에 따라 정보의 중요도나 관련성이 변하는 환경(뉴스 기사, 소셜 미디어, 실시간 데이터 분석 등)에서 유용
| 장점 | 단점 |
|---|---|
| - 최신 정보 제공 - 관련성 향상 - 트렌드 반영 - 유연성 | - 오래된 정보 무시 가능성 - 시간 가중치의 효과적 설정 및 조정의 어려움 - 추가 계산 비용 발생 - 시간에 덜 민감한 중요 정보의 저평가 가능성 |

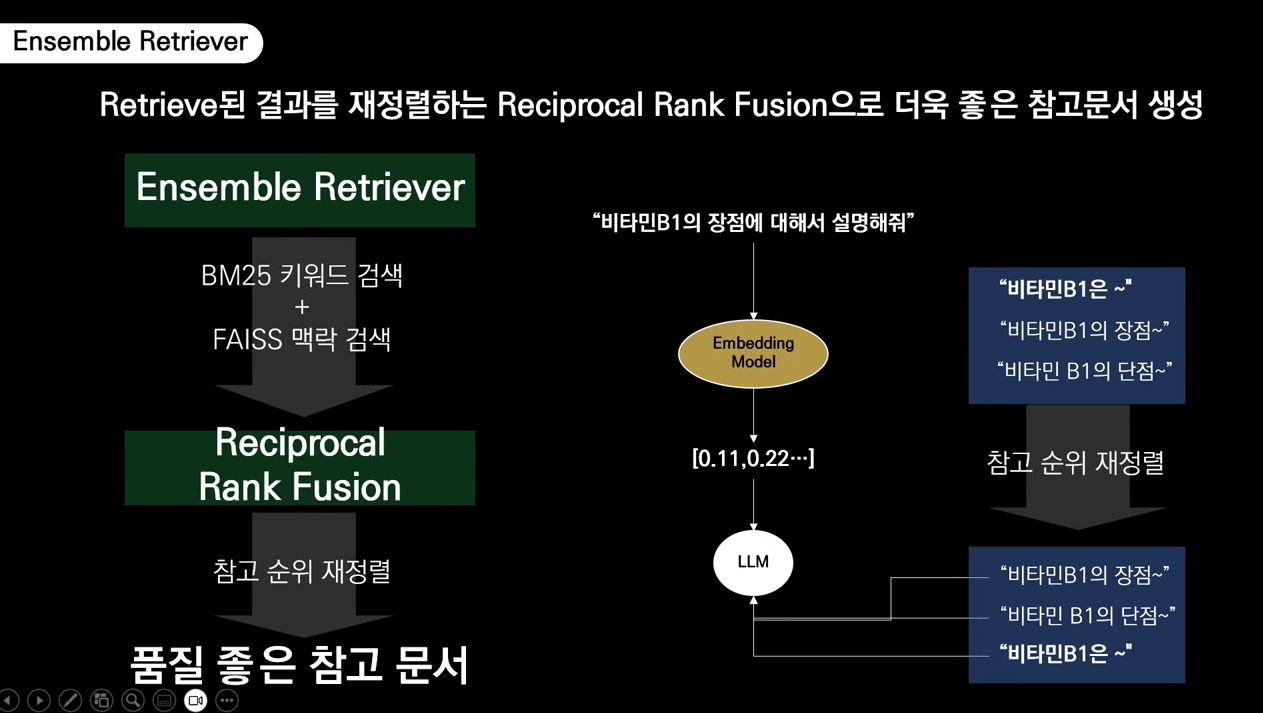
✅ Ensemble Retriver
💡 정보 검색 시스템에서 다양한 검색 전략이나 모델을 결합하여 최종 검색 결과를 도출하는 방법
문서 행렬 구성 방법에 따라 Sparse/Dense Retriever 구분
- Sparse : 각 단어가 문서에서 몇 번씩 출연했나를 기준으로 행렬을 만들고 행렬 기반으로 인덱스를 만들어서 사용자 쿼리와 유사한 인덱스를 뽑아 답변(ex. TF-IDF, BM25)
TF-IDF란? - Dense : 딥러닝 모델의 인코더로 문서와 질문을 각각 밀집 벡터로 변환하여 밀집 벡터 간의 유사도 비교(ex. Sentence-BERT, DPR)
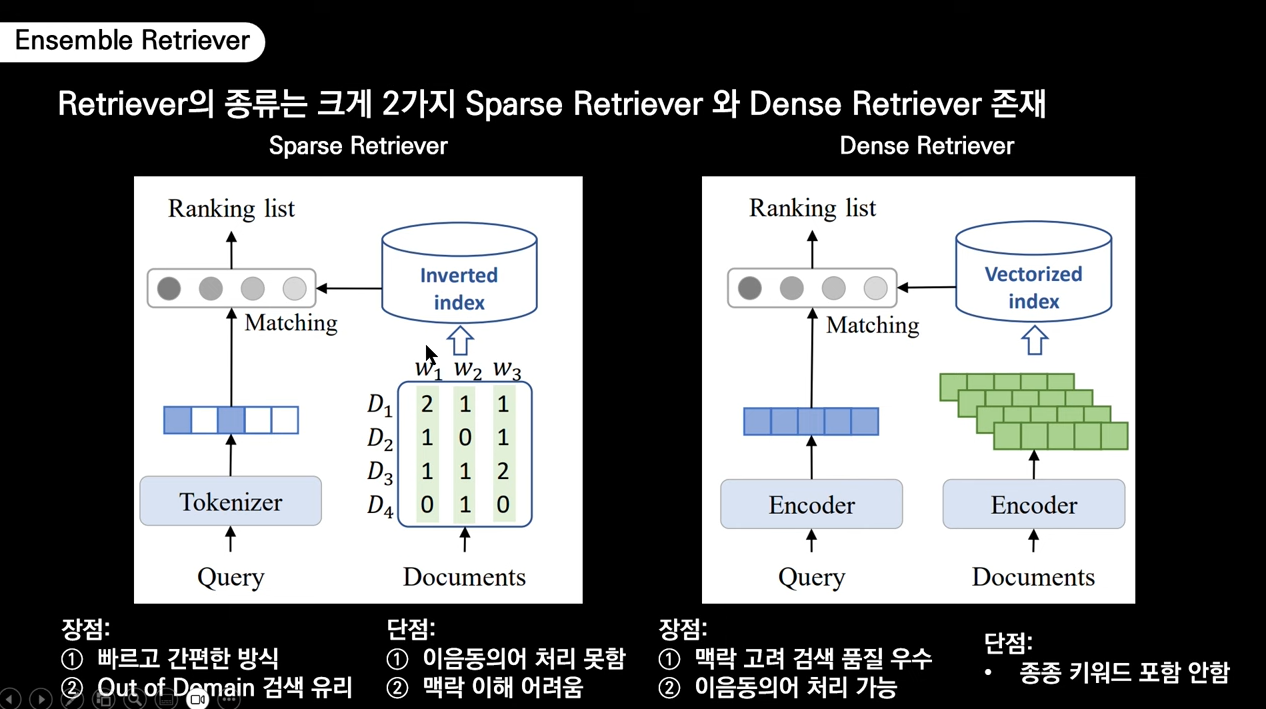
Sparse Retriever는 빠르고 간편하게 키워드를 추출하지만 맥락 이해에 어려움을 가진다. Dense Retriever는 벡터 간 유사도 검색을 통해 맥락을 고려하지만 질의와 문서 간 유사성 비교 시 정확한 단어 일치 여부가 아닌 의미적 유사성을 기반으로 비교하여 종종 키워드를 포함하지 않는다.
Sparse와 Dense Retriever의 장점은 포함시키고 단점은 보완하기 위해 Ensemble Retriever를 사용한다.
| 장점 | 단점 |
|---|---|
| - 검색 정확도 향상 | - 높은 계산 비용 - 결합 방법 선택의 어려움 등으로 인한 복잡한 구현 - 디버깅의 어려움 - 모델 간 충돌 가능성 |
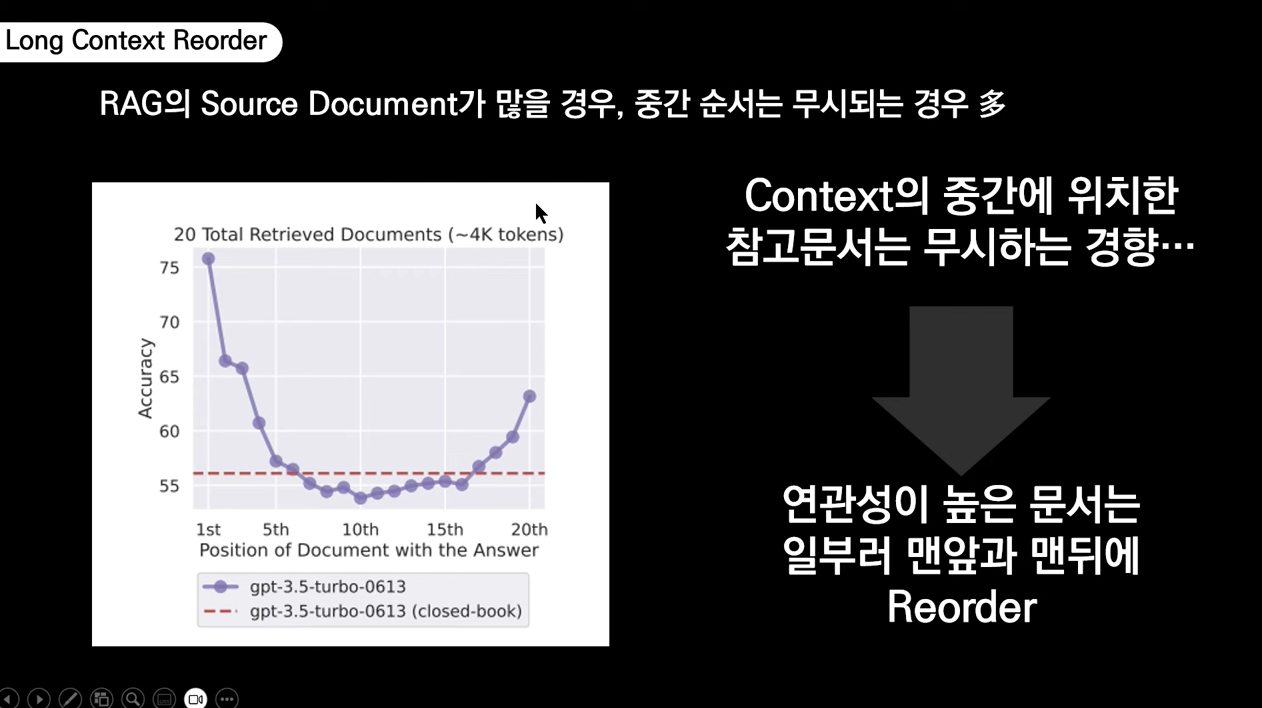
✅ Long Context Reorder
💡 긴 문서나 대규모 텍스트 데이터에서 중요한 부분을 식별하고, 이를 검색이나 분석에 더 유리한 순서로 재배치하는 기법
| 장점 | 단점 |
|---|---|
| - 효율적인 정보 접근 - 질의 관련 정보 우선 제공 - 문서 처리 최적화 | - 문서 왜곡 가능성 - 재배치 기준의 복잡성 - 추가 계산 비용 |
참고자료
실전! RAG 고급 기법 - Retriever (1)
실전! RAG 고급 기법 - Retriever (2)
<랭체인LangChain 노트> - LangChain 한국어 튜토리얼🇰🇷
