이미지 처리에 앞서 CNN을 복습해 보자.
✅CNN
- 합성곱 인공 신경망
- 이미지는 행렬 데이터, CNN은 이미지 처리에 특화되어 있음
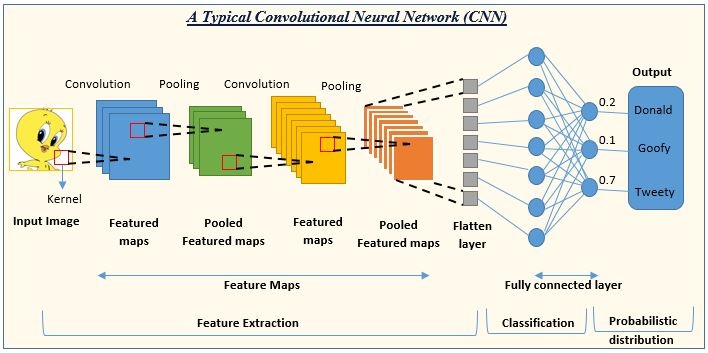 출처 : https://www.analyticsvidhya.com/blog/2022/01/convolutional-neural-network-an-overview/
출처 : https://www.analyticsvidhya.com/blog/2022/01/convolutional-neural-network-an-overview/
- 컨볼루션 레이어(Convolution layer)
- 컨볼루션 연산을 수행하는 층 (채널 증가, 크기 유지)
- 선형 변환, 선형 변환만 반복하면 기울기 손실 문제 발생
- 그래서 비선형 연산을 하나 추가한다(ReLu 등)
- 풀링 레이어(Pooling Layer)
- 특징을 유지하며 크기를 축소하는 층 (채널 유지, 크기 축소)
- 컨볼루션 레이어의 마지막 구성
- 이미지와 필터의 특징 가진 채로 크기만 축소
여기까지 특징 추출, 보통 컨볼루션 + 풀링 레이어 2~3회 반복(예. VGG 컨볼루션 3 풀링 1 반복)
- 완전 연결 레이어(Fully-connected layer)
- 충분히 특징 추출됐다고 판단되면 완전 연결 레이어로
- 특징을 추출하는 건 아니고 추출된 특징을 통해 분류를 수행하는 층
하나씩 상세히 알아보자
컨볼루션
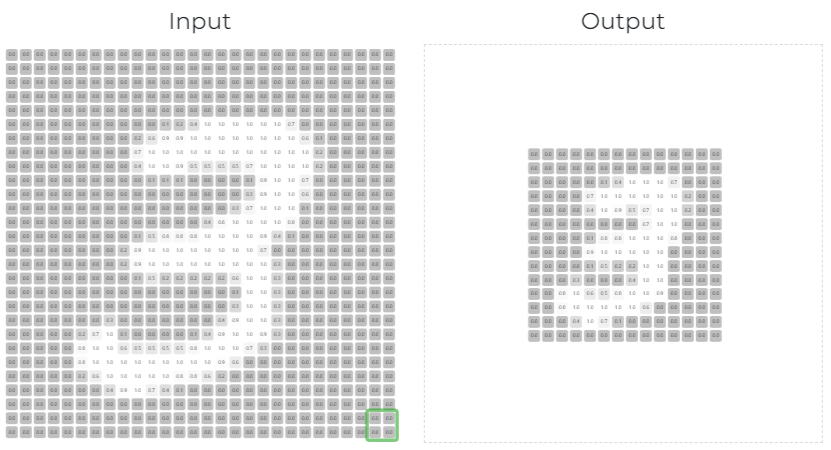
- 컨볼루션 : 정한 커널(필터, 윈도우) 내에서 가장 큰 값을 선택하여 출력하는 방식
- 특징을 넘겨주기 위한 최소 단위 창 (계산 방식 상 보통 정사각형)
- 특징을 유지하며 크기를 축소시켜, 부분의 합을 통해 특징 지도(feature map)을 만드는 연산법
- 만들어진 특징 지도는 풀링(pooling) 과정을 통해 또다시 컨볼루션 레이어의 입력값이 된다.
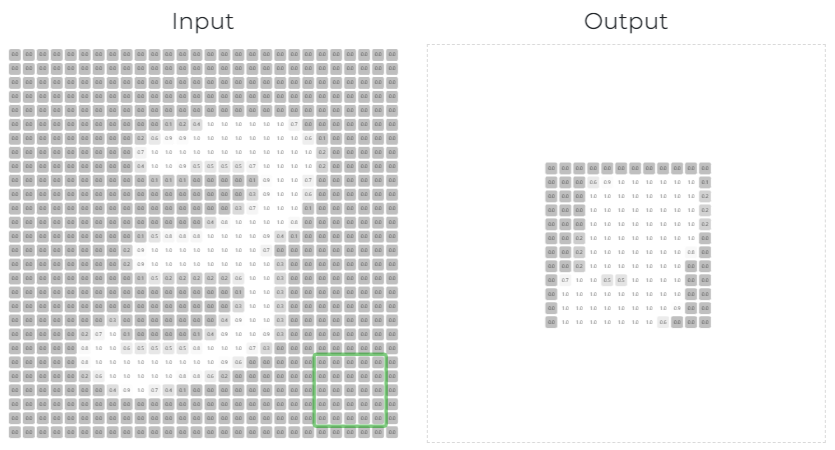
- 스트라이드(stride) : “걸음, 보폭” 이라는 뜻으로, 커널 윈도우가 몇 칸(걸음)씩 움직일지 설정하는 것
- 스트라이드 크기에 따라 feature map 크기가 달라질 수 있다.
- 이 개념을 알아야 입력 출력 사이즈 차이 이해할 수 있다.
- 패딩(padding)
- 가장자리 바깥 칸에 추가로 최외곽 테두리 칸을 만들어 숫자를 채우는 것
- 샘플링 횟수 증가시키기 위함(예. 패딩이 없으면 가장자리로 갈수록 샘플링 횟수가 줄어든다) → 패딩을 포함해서 계산해주면 중앙의 횟수와 원래의 가장자리의 샘플링 횟수를 동일하게 만들어줌
- 모서리에 있는 feature를 추출하기 위한 방법
- 풀링(pooling)
- 레이어 크기를 줄이며, 강한 특징만 강조하는 방식. (샘플링Sampling이라고도 함)
- 보통 맥스풀링 사용(성능이 가장 좋음)
- 정말 필요한 경우가 아니라면 패딩 사용 X, 일반적으로 패딩은 컨볼루션 레이어에서만 사용
풀링 후 레이어 크기 변화 :
n : 입력 크기, p : 패딩 크기, f : 커널 크기, s : 스트라이드
filter 2x2일 때 : 특징 유지하면서 사이즈 줄이는 게 이런 거
filter 5x5
활성화 함수(Activation Function)
- 컨볼루션/풀링 레이어는 기본적으로 선형 변환이기 때문에, 반복할수록 역전파로 얻는 오차의 기울기가 작아져 앞쪽 레이어의 가중치가 무시되는 경향이 있다. = 더 효율적인 특징 추출을 위한 깊은(두꺼운) 레이어 구성이 의미가 없어짐
→ 기울기 소실 - 따라서 CNN의 컨볼루션 레이어에 활성화 함수를 적용하는 것은 비선형 변환을 수행함으로써 기울기 소실 문제를 최소화하기 위한 방법론
완전 연결 레이어(Classification layers)
- 확보한 특징을 통해, 데이터를 분류하는 레이어
- 평탄화 과정을 통한 1차원 벡터 행렬을 입력으로 받음
- 차원 변환 연산(선형 변환), 활성화 함수 연산(비선형 변환)을 차례로 적용
- Softmax 함수를 통해, 레이어의 출력을 라벨로 변환
- 평탄화Flatten : 특징 추출 레이어의 최종 출력 데이터를 입력으로 받아, 1차원 벡터로 출력하는 레이어
- 소프트맥스(Softmax) 함수
- CNN을 통해 출력된 실수값을 0~1(=0%~100%) 사이의 확률로 계산하는 함수
- 결국 입력된 이미지는 각 라벨에 대한 일치 확률을 갖게 된다
CNN 개념 정리를 이해가 잘 되도록 정리해 주신 포스팅을 찾았다.
https://di-bigdata-study.tistory.com/18
✅실습
CNN 학습 결과가 잘 나오는 MNIST 데이터셋으로 실습을 진행해 보자.
필요 모듈 불러오기
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import cv2
import matplotlib.pyplot as plt모델 클래스 정의
# myCNN 클래스 정의
class myCNN(nn.Module):
def __init__(self):
super(myCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size = 5, padding = 2)
self.conv2 = nn.Conv2d(32, 64, kernel_size = 5, padding = 2)
self.conv3 = nn.Conv2d(64, 128, kernel_size = 5, padding = 2)
self.fc1 = nn.Linear(128*3*3, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2(x), 2))
x = F.relu(F.max_pool2d(self.conv3(x), 2))
x = x.view(-1, 128*3*3)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim = 1)MNIST 데이터셋 로드 및 전처리
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST('./data', train = True, download = True, transform = transform)
test_dataset = datasets.MNIST('./data', train = False, transform = transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size = 64, shuffle = True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size = 1000, shuffle = False)모델, 손실 함수, 최적화 알고리즘 설정
model = myCNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum = 0.5)모델 학습
# 손실과 정확도를 저장하기 위한 리스트
train_losses = []
test_losses = []
test_accuracies = []
# 훈련 함수
def train(model, train_loader, optimizer, epoch):
model.train()
train_loss = 0
for data, target in train_loader:
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
train_loss += loss.item()
loss.backward()
optimizer.step()
# 평균 훈련 손실 계산
train_loss /= len(train)
train_losses.append(train_loss)
print(f'Epoch {epoch}, Training loss: {train_loss:.4f}')모델 평가
# 테스트 함수
def test(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = model(data)
test_loss += criterion(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader)
accuracy = 100. * correct / len(test_loader.dataset)
test_losses.append(test_loss)
test_accuracies.append(accuracy)
print(f'Test loss: {test_loss:.4f}, Accuracy: {accuracy:.2f}%')10회 반복 시행
# 훈련 및 테스트 실행
for epoch in range(1, 11):
train(model, train_loader, optimizer, epoch)
test(model, test_loader)결과 시각화
# 손실 및 정확도 시각화
fig, axs = plt.subplots(2,1,figsize=(10,10))
axs[0].plot(train_losses, label = 'Training Loss')
axs[0].plot(test_losses, label = 'Test Loss')
axs[0].set_xlabel('Epoch')
axs[0].set_ylabel('Loss')
axs[0].legend()
axs[0].set_title('Training and Test Loss')
axs[1].plot(test_accuracies, label='Test Accuracy', color='orange')
axs[1].set_xlabel('Epoch')
axs[1].set_ylabel('Accuracy (%)')
axs[1].legend()
axs[1].set_title('Test Accuracy')
plt.tight_layout()
plt.show()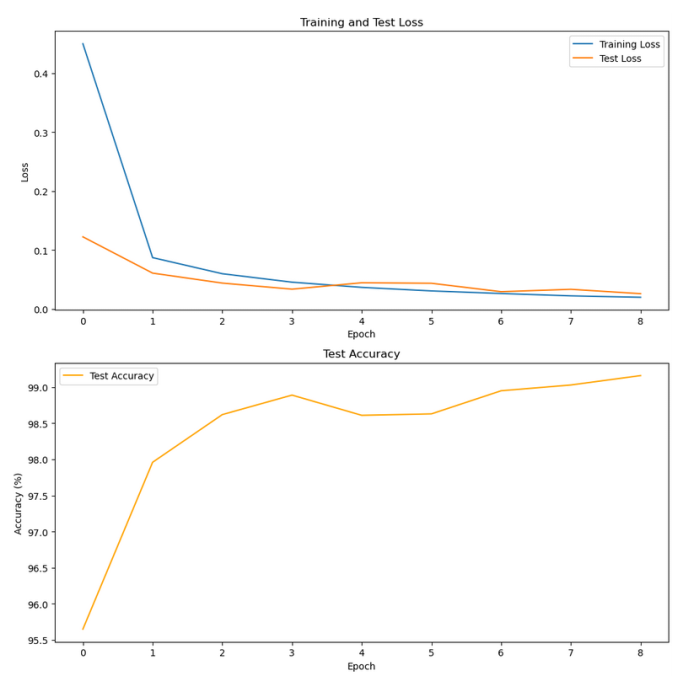

M.S. Student in Data Science @ Seoul National University