
✅ PEFT(Parameter Efficient Fine-tuning)
PEFT는 대규모 모델을 효율적으로 파인튜닝하는 Hugging face에서 소개한 방법론입니다. 최근 공개되는 LLM들이 갈수록 거대해지면서 일반 GPU로 모델 전체를 파인튜닝하는 것은 불가능해지고 있습니다. 또한, 파인튜닝된 모델을 저장하고 불러오는 것 또한 시간, 비용적으로 부담스러워지고 있습니다. PEFT는 모델의 성능을 개선하면서도 자원과 시간의 효율성을 고려하여 파라미터를 조정하는 방법론입니다.
✅ PEFT의 주요 개념 및 장점
- 효율적인 파라미터 조정
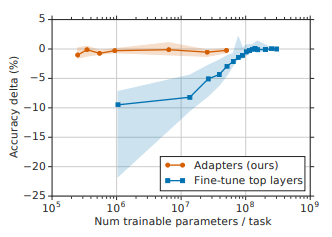
- 전통적인 파인튜닝에서는 모델의 모든 파라미터를 조정했으나, PEFT는 모델의 전체 파라미터 중 대부분의 파라미터를 freeze 하고 일부 파라미터(0.5~8%)만을 파인튜닝하여 효율성을 높입니다.
- 이를 통해 메모리 사용량과 계산 비용을 줄이면서도 모델의 성능을 개선할 수 있습니다.
- 프롬프트 기반 파인튜닝
- PEFT는 프롬프트를 이용하여 모델의 학습을 조정합니다. 모델의 파라미터를 직접 조정하는 대신 입력 프롬프트를 조정하여 제한된 라벨링 데이터만으로도 모델의 성능을 개선할 수 있습니다.
- Castographic Forgetting(치명적 망각) 위험도 감소
- Castographic Forgetting은 LLM 모델 전체를 파인튜닝할 때 주의해야 하는 현상으로, 새로운 정보를 학습할 때 과거 학습을 유지하지 못하고 새로운 데이터에만 최적화되어 기존에 학습한 일부 지식에 대해 망각하게 되는 현상을 의미합니다.
- PEFT를 활용하면 사전 훈련된 상태의 지식을 보존하여 새로운 downstream task(궁극 과제)에 대해 학습할 수 있습니다.
✅ PEFT의 대표적인 기법들
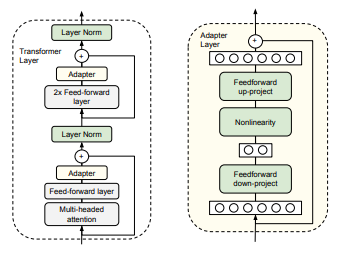
- Adapter Layers
- Adapter는 pre-trained model 사이사이에 학습 가능한 작은 신경망 층인 feed-forward networks를 삽입하는 구조입니다.
- 학습 시 기존 파라미터는 고정되고 Adapter 레이어의 파라미터만 학습하므로 계산량을 줄일 수 있습니다.
- Prompt Tuning
- 특정 입력에 대한 응답을 조정함으로써 pre-trained model의 원래 가중치는 유지하면서 입력 프롬프트에 해당하는 파라미터만을 학습합니다.
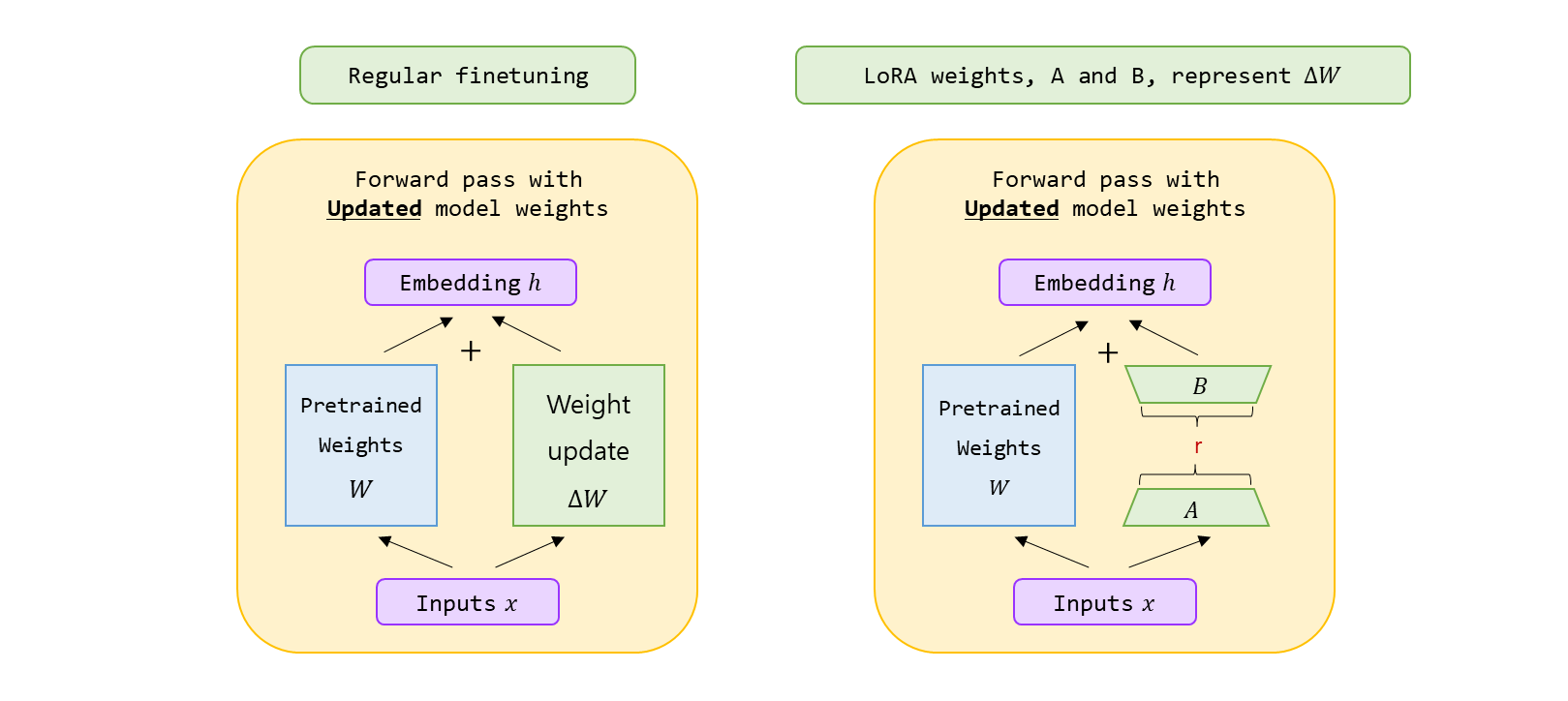
- LoRA(Low-Rank Adaptation)
- LoRA는 pre-trained model의 원래 가중치는 유지하면서 학습 가능한 저차원 행렬인 lank decomposition 행렬을 삽입하여 소수의 파라미터만 조정하는 방법입니다.
- Pre-trained model 사이사이에 학습 가능한 파라미터를 삽입했다는 점에서 adapter와 비슷하지만 구조적으로 차이가 있습니다.
참고자료
Parameter-Efficient Transfer Learning for NLP
🤗 PEFT: Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware
PEFT(효율적 파라미터 파인 튜닝) 활용한 성능 최적화: 프롬프트 튜닝 딥다이브
Full Fine-Tuning, PEFT, Prompt Engineering, or RAG?
LLM 모델 튜닝, 하나의 GPU로 가능할까? Parameter Efficient Fine-Tuning(PEFT)을 소개합니다!

Human×Tech Bridge Builder | EdTech | AI Service Developer