https://arxiv.org/pdf/2404.17729
간단 요약
논문 "CoMM: Collaborative Multi-Agent, Multi-Reasoning-Path Prompting for Complex Problem Solving"는 대규모 언어 모델(LLM)을 활용하여 복잡한 문제를 해결하는 데 중점을 둔 프레임워크를 제안합니다. 이 논문에서는 다양한 역할을 수행하는 여러 에이전트가 협력하여 복잡한 문제를 해결하는 방법을 설명합니다.
주요 내용 요약
- 문제 정의와 목표:
- 대규모 언어 모델이 전통적인 자연어 처리 작업이나 간단한 추론 작업에는 효과적이지만, 복잡한 과학 문제에서는 성능이 제한적임을 지적합니다.
- CoMM은 여러 에이전트를 사용하여 다양한 역할을 수행하고 여러 추론 경로(multi-reasoning paths)를 통해 문제 해결 능력을 높이고자 합니다.
- CoMM 프레임워크의 개요:
- CoMM은 여러 에이전트를 통해 팀을 구성하며, 각 에이전트는 특정 도메인 지식이나 문제 해결 방식을 기반으로 역할을 수행합니다.
- 예를 들어, 물리학자와 수학자로 구성된 두 명의 전문가와 최종 요약을 담당하는 요약자(summarizer) 에이전트로 구성될 수 있습니다.
- 각 에이전트는 자신만의 추론 경로를 따라 문제를 해결하며, 이를 통해 여러 추론 경로가 결합되어 보다 깊이 있는 분석과 정확한 답을 제공합니다.
- 실험과 결과:
- CoMM은 대학 수준의 물리학 문제와 도덕적 시나리오 문제에서 기존 방법보다 우수한 성능을 보였습니다.
- 특히, 단일 에이전트 대신 여러 에이전트를 사용할 때 더 나은 협력 성과를 보여주었으며, 각 에이전트가 독립적인 역할을 맡았을 때 성능이 향상되었습니다.
- 주요 성과:
- CoMM은 단순히 하나의 에이전트가 여러 역할을 수행하는 방식보다 다양한 에이전트가 각기 다른 역할을 수행하는 방식이 더 효과적임을 보여줍니다.
- 또한, 특정 문제에서는 여러 차례의 토론이 필요하며, 예를 들어 물리학 문제에서는 단일 토론으로 충분한 반면, 도덕적 시나리오에서는 여러 번의 토론이 성과에 기여할 수 있습니다.
- 결론:
- CoMM 프레임워크는 협력적 추론 방식을 통해 대규모 언어 모델의 복잡한 문제 해결 능력을 한층 높입니다.
- 특히, 여러 에이전트를 활용한 협력적 접근이 복잡한 문제 해결에 필요한 정교한 추론 전략을 제공할 수 있음을 실험적으로 입증했습니다.
이 논문은 다중 에이전트가 협력하여 복잡한 과학 문제를 해결하는 데 강력한 효과가 있음을 보여주며, 향후 LLM을 활용한 고급 추론 및 문제 해결 연구에 중요한 기여를 할 수 있습니다.
- *CoMM 방법론 (Collaborative Multi-Agent, Multi-Reasoning-Path Prompting)**에 대해 다음과 같은 내용을 담고 있습니다.
CoMM 방법론은 복잡한 문제 해결을 위한 다중 에이전트 및 다중 추론 경로를 포함하는 프레임워크입니다. 이 방법론은 각 에이전트가 독립적인 역할을 수행하면서 협력하여 문제 해결을 향상시키는 방식을 채택하고 있습니다. 주요 구성 요소는 다음과 같습니다:
1. 단일 에이전트와 다중 에이전트 프레임워크
- 단일 에이전트: 단일 에이전트는 하나의 언어 모델을 사용하여 입력 텍스트를 처리하고, 그 텍스트의 의미를 통해 문제를 해결합니다. 이는 특정 문제나 작업을 정의하는 프롬프트 함수에 의해 처리되며, 정답을 예측하는 방식입니다.
- 다중 에이전트: 여러 언어 모델을 다양한 역할을 수행하는 에이전트로 구성합니다. 예를 들어, 한 모델은 물리학자로, 다른 모델은 수학자로 역할을 부여받아 서로 다른 관점에서 문제를 해결합니다. 각 에이전트는 자신의 역할에 맞는 프롬프트 함수를 사용하여 문제에 접근하고, 상호작용을 통해 최종 답을 산출합니다.
2. 협력적 Zero-shot 시나리오
- CoMM에서는 동일한 모델이 세 가지 역할을 수행하며, 두 명의 전문가(물리학자와 수학자)가 문제 해결을 하고, 요약자가 이를 종합하는 방식으로 작동합니다.
- 주어진 문제를 시스템 메시지로 변환하여 협력적 작업 환경을 설정한 후, 각 에이전트는 자신의 역할에 맞는 프롬프트를 사용해 문제를 분석합니다. 결과적으로, 전문가들이 독립적으로 문제를 해결한 후 요약자가 최종적으로 응답을 제시합니다.
3. 다중 추론 경로와 다중 회차 대화
- 다중 추론 경로: 각 에이전트는 고유의 추론 경로를 가지고 있으며, 각자의 전문성에 기반한 몇 가지 예제(few-shot)를 사용하여 학습합니다. 예를 들어, 물리학자와 수학자는 각자 다른 추론 과정을 통해 답을 찾고 이를 조합합니다.
- 다중 회차 대화: 특정 문제의 경우, 에이전트들이 여러 차례 대화를 통해 최종 답을 도출할 수 있습니다. 예를 들어, 첫 번째 전문가의 답변이 두 번째 전문가에게 전달되고, 필요한 경우 다시 첫 번째 전문가에게 전달되는 방식으로 반복됩니다.
4. 실험 결과와 성과
- 실험 결과에 따르면, CoMM은 대학 물리학 문제와 도덕적 시나리오 문제에서 기존의 단일 에이전트 방식보다 높은 성과를 보였습니다. 특히 다중 에이전트가 협력했을 때 문제 해결에서 더 효과적이었으며, 이는 각각의 에이전트가 특정 역할을 맡아 독립적으로 문제를 분석하고 해결하는 방식이 성과를 향상시키는 데 기여했음을 보여줍니다.
이러한 방법론은 복잡한 문제를 해결하기 위해 대형 언어 모델을 다중 에이전트로 활용함으로써, 모델의 제한된 성능을 보완하고 다양한 추론 경로를 통해 문제 해결 능력을 높이는 데 중요한 역할을 합니다.
초록
대규모 언어 모델(LLMs)은 적절한 프롬프트 기술을 사용하여 전통적인 자연어 처리 과제 및 기본적인 추론 과제를 해결하는 데 뛰어난 능력을 보였습니다. 그러나 복잡한 과학 문제를 해결하는 데 있어 그 능력에는 여전히 한계가 존재합니다. 본 연구에서는 협업 다중 에이전트 및 다중 추론 경로(CoMM) 프롬프트 프레임워크를 제안하여 LLM의 추론 능력 상한을 확장하는 것을 목표로 합니다. 구체적으로, LLM이 문제 해결 팀의 다양한 역할을 수행하도록 프롬프트를 설계하고, 이러한 역할 수행 에이전트들이 협력하여 대상 작업을 해결하도록 유도합니다. 특히, 다양한 역할에 대해 서로 다른 추론 경로를 적용하는 것이 다중 에이전트 환경에서 몇 가지 예제만으로 학습(few-shot learning)을 구현하는 효과적인 전략임을 발견했습니다. 실험 결과, 제안된 방법이 두 가지 대학 수준의 과학 문제에서 경쟁적인 기준선 대비 효과적임을 보여주었습니다. 추가 분석에서는 LLM이 독립적으로 다양한 역할 또는 전문가로 작동하도록 프롬프트를 설계하는 것이 필요하다는 것을 확인했습니다. 관련 코드는 다음 링크에서 제공됩니다: https://github.com/amazon-science/comm-prompt.
1. 서론
GPT(Brown et al., 2020; OpenAI, 2023), LLaMA(Touvron et al., 2023a, b), PaLM(Chowdhery et al., 2022)과 같은 대규모 언어 모델(LLMs)은 추가적인 모델 파라미터 미세 조정 없이 많은 다운스트림 작업(Liu et al., 2021)을 해결하는 데 있어 탁월한 능력을 보였습니다. 그러나 LLM은 추론 및 수학적 문제, 특히 복잡한 과학 문제(Ma et al., 2023; Xu et al., 2023; Ling et al., 2023a)를 해결하는 데 한계를 보입니다. 이러한 한계를 고려할 때, 수십억 개의 파라미터를 가진 LLM을 미세 조정하는 데 드는 높은 비용을 줄이기 위해 많은 프롬프트 기법이 등장했습니다. 이는 LLM의 입력 쿼리를 세심하게 설계하여 원하는 출력을 효과적으로 얻는 과정입니다. 이러한 프롬프트 방법은 LLM의 파라미터를 직접 조작하지 않고도 사전 학습된 모델을 다운스트림 작업에 원활히 통합하여 원하는 모델 동작을 이끌어내는 장점이 있습니다(Sahoo et al., 2024).
이러한 다양한 프롬프트 접근법 중 일부는 추론 작업에 대해 중간 단계나 하위 문제를 통해 추론하도록 LLM을 유도합니다(Wei et al., 2022b; Wang et al., 2023b; Yao et al., 2023; Hao et al., 2023; Zhou et al., 2023). 또 다른 접근법은 LLM이 외부 도구를 활용하도록 유도합니다(Gao et al., 2023; Chen et al., 2023). 이러한 방법들은 LLM의 추론 및 수학적 능력의 상한을 확장했지만, 복잡한 과학 문제를 다루는 잠재력은 여전히 개선될 여지가 있습니다. 예를 들어, 그림 1의 대학 수준 물리 문제를 살펴보면, Chain-of-thought 프롬프트 기법도 여전히 지식적 오류(문제에 적합하지 않은 공식 사용)와 계산 오류(잘못된 계산)를 겪고 있음을 알 수 있습니다.
최근 에이전트 기반 프롬프트 방법은 LLM이 특정 역할을 수행하거나 지능형 에이전트로 행동하도록 유도하여 복잡한 문제 해결 능력을 더욱 강화했습니다. 예를 들어, Xu et al.(2023)은 LLM이 도메인 전문가로 작동하도록 프롬프트를 설계하여 도메인 관련 질문에 답변하도록 유도했습니다. Huang et al.(2022), Shinn et al.(2023), Madaan et al.(2023)은 LLM이 자가 반성(self-reflection)이나 자가 개선(self-refinement)을 통해 오류를 수정하도록 유도했습니다. Wang et al.(2023a), Sun et al.(2023)은 LLM이 특정 작업을 해결하기 전에 계획을 세우도록 프롬프트를 설계했습니다. Wang et al.(2023c)은 단일 에이전트가 서로 다른 역할을 다양한 페르소나로 수행하도록 유도했으며, Liang et al.(2023), Chan et al.(2023), Du et al.(2023)은 문제 해결을 위해 토론하는 다양한 역할을 수행하도록 LLM을 유도했습니다.
그림 1: 복잡한 과학 문제에서 Chain-of-thought(CoT)의 지식적 및 계산 오류 사례
질문: 레이저에서 나오는 빛이 0.5마이크로미터 간격으로 떨어져 있는 좁은 슬릿 한 쌍에 떨어졌고, 먼 화면에 1.0밀리미터 간격으로 밝은 간섭 무늬가 관찰되었습니다. 레이저 빛의 주파수를 두 배로 늘리면 밝은 간섭 무늬의 간격은 어떻게 될까요?
정답: 0.5 mm
CoT 응답: (생략된 과정 중 오류 확인)
연구 목적 및 주요 기여
이러한 연구를 바탕으로 우리는 협업 다중 에이전트(CoMM) 프레임워크를 제안합니다. 이 프레임워크는 LLM이 다양한 역할(도메인 지식 또는 작업 수행 책임)을 수행하도록 유도하여 문제를 해결합니다. 특히, 우리는 다중 에이전트 프레임워크에서 몇 가지 예제만으로 학습할 수 있는 다중 경로 추론 기법을 제안합니다. 여러 복잡한 대학 수준 과학 문제에 대한 실험 결과, 제안된 방법이 강력한 기준선을 크게 능가함을 보여주었습니다. 추가 분석에서는 하나의 에이전트가 여러 역할을 동시에 수행하도록 설계하는 것보다, 다중 에이전트를 포함한 협업이 더 효과적이라는 점을 확인했습니다.
2. 관련 연구
대규모 언어 모델(LLMs)은 많은 다운스트림 작업(Qu et al., 2020b; Chen et al., 2021; Xu et al., 2024c,b)을 해결하는 데 있어 놀라운 능력을 보여주며, 인공지능 일반화(Artificial General Intelligence)로 가는 길을 열었습니다. GPT-3(Brown et al., 2020)의 등장과 이를 통한 제로샷 및 소수샷(few-shot) 설정에서 다운스트림 작업 해결 능력(Wei et al., 2022a)이 두드러지며, 이를 기반으로 많은 디코더 전용 LLM들이 개발되었습니다(Ling et al., 2023b). 대표적인 예로 PaLM(Chowdhery et al., 2022), LLaMA(Brown et al., 2020; OpenAI, 2023), BLOOM(Workshop et al., 2023), Claude(Bai et al., 2022), OPT(Zhang et al., 2022), Mistral(Jiang et al., 2023), Falcon(Penedo et al., 2023) 등이 있습니다. 추론 속도와 경제적 비용을 고려하여, 본 연구에서는 모든 기준선 모델과 CoMM 접근법의 백본(backbone) 모델로 GPT-3.5를 선택했습니다.
LLMs의 다운스트림 작업 해결 능력을 극대화하기 위해(Yi and Qu, 2022; Chen et al., 2022; Qu et al., 2020a; Zhang et al., 2023; Yu et al., 2024; Xu et al., 2024a), 수십억 개에 이르는 파라미터를 조작하지 않고도 활용할 수 있는 다양한 프롬프트 기법이 등장했습니다(Li et al., 2023c). 이러한 프롬프트 방법 중, 일반적인 프롬프트는 Brown et al.(2020)을 따르며, 작업 설명과 예시(few-shot)를 프롬프트로 사용하여 다운스트림 작업을 해결합니다. LLM이 직접적으로 정답을 출력하는 데 어려움을 겪는 것을 완화하기 위해, 많은 프롬프트 기법들은 추론 과정을 중간 단계로 나누어(chain-of-thought, CoT) 예측하거나(Wang et al., 2023b; Yao et al., 2023; Hao et al., 2023; Zhou et al., 2023; Ling et al., 2024), 분해된 하위 문제를 먼저 해결하는 방식으로 과정을 단순화합니다. 또한, 부족한 계산 능력과 오래된 지식 기반 문제를 극복하기 위해, 일부 연구는 LLM이 외부 도구를 활용하도록 프롬프트를 설계합니다(Gao et al., 2023; Chen et al., 2023).
복잡한 문제 해결 능력을 더욱 강화하기 위해, LLM이 특정 역할을 수행하도록 유도하는 에이전트 기반 방법이 주목받고 있습니다. 이 중 단일 에이전트(single-agent) 방법은 하나의 LLM 인스턴스만 사용합니다. 예를 들어, ExpertPrompt(Xu et al., 2023)은 LLM이 도메인 전문가로 작동하도록 프롬프트를 설계하여 도메인 관련 질문에 답하도록 유도합니다. EmotionPrompt(Li et al., 2023a)는 감정적 프롬프트를 활용하여 에이전트 성능을 개선합니다. Huang et al.(2022), Shinn et al.(2023), Madaan et al.(2023)은 LLM이 자가 반성(self-reflection) 또는 자가 개선(self-refinement)을 통해 오류를 수정하도록 유도합니다. Wang et al.(2023a), Sun et al.(2023)은 특정 작업을 해결하기 전에 LLM이 계획을 수립하도록 프롬프트를 설계했습니다. Wang et al.(2023c)은 하나의 에이전트가 다양한 페르소나로 여러 역할을 수행하도록 프롬프트를 설계했습니다.
또 다른 에이전트 기반 접근법은 다중 에이전트(multi-agent)를 사용하는 방법입니다. 예를 들어, Liang et al.(2023), Chan et al.(2023), Du et al.(2023)은 문제 해결을 위해 LLM이 서로 다른 역할을 수행하며 토론하도록 프롬프트를 설계했습니다. ChatEval(Chan et al., 2023)은 다중 에이전트를 사용하여 자동으로 LLM을 평가하는 데 활용되었습니다. MathChat(Wu et al., 2023b)은 사용자와 LLM 에이전트 간의 상호작용을 통해 수학 문제를 해결하기 위한 대화형 프레임워크를 제안했습니다. Park et al.(2023)과 Li et al.(2023b)은 인간 행동을 시뮬레이션하기 위해 서로 다른 에이전트로 LLM이 작동하도록 설계했습니다.
본 연구는 이러한 기존 연구와 밀접한 관련이 있지만, 복잡한 추론 문제에서 협업 프레임워크를 통해 LLM이 서로 다른 도메인 전문가 역할을 수행하도록 유도하는 것을 목표로 합니다. 특히, 다중 에이전트 프레임워크 내에서 소수의 예제(few-shot)를 어떻게 효과적으로 통합할 수 있는지를 탐구합니다.
오픈소스 응용 사례와 본 연구의 차별성
에이전트 기반 프롬프트 방법 외에도 많은 오픈소스 응용 사례가 등장했습니다. 예를 들어, AutoGPT(Wu et al., 2023a)는 AI 에이전트로 작동하며 주어진 목표를 달성하기 위해 이를 하위 작업으로 나누고 인터넷 및 기타 도구를 활용하는 자동 루프를 실행합니다. AutoGen(Wu et al., 2023a)은 다중 에이전트 간 대화를 기반으로 LLM 응용 프로그램을 구축하기 위한 프레임워크를 설계했습니다. MetaGPT(Hong et al., 2023)는 소프트웨어 프로젝트에서 제품 관리자, 아키텍트, 프로젝트 관리자 및 엔지니어 역할을 수행하는 다중 에이전트를 설계했습니다. SkyAGI(Park et al., 2023)는 LLM의 인간 행동 시뮬레이션 능력을 제공합니다.
이러한 다중 에이전트 프레임워크를 공유하면서도, 본 연구는 해당 프레임워크의 효과를 탐구하는 데 중점을 둡니다. 즉, 다중 에이전트의 필요성을 확인하고, 다중 에이전트가 협력하여 작업을 수행하도록 유도하는 방법을 제시합니다.
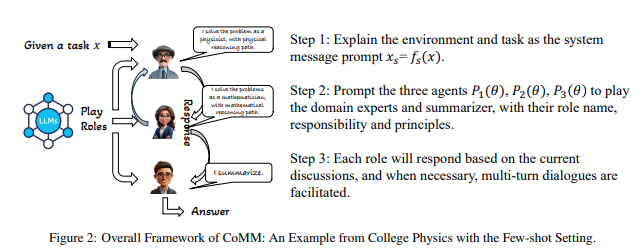
3. 방법론
본 섹션에서는 먼저 단일 에이전트 프롬프팅 프레임워크를 공식적으로 정의한 후, 다중 에이전트 프롬프팅 프레임워크의 공식 정의와 이를 제로샷 및 소수샷(CoMM) 설정에 적용하는 방법을 소개합니다.
단일 에이전트 프롬프팅
주어진 언어 모델 와 입력 텍스트 x 가 있을 때, 단일 에이전트 프롬프팅은 라는 함수를 입력 텍스트에 적용하여 를 생성합니다. 이 함수는 일반적으로 대상 문제 또는 작업을 정의합니다. 이후, 언어 모델은 하나의 문제 해결 에이전트로서 작동하며 를 통해 정답 y 를 예측합니다.
- 제로샷 설정에서는 프롬프팅 함수 가 예제 데모를 포함하지 않습니다.
- 소수샷 설정에서는 프롬프팅 함수에 몇 가지 예제가 포함됩니다.
다중 에이전트 프롬프팅
다중 에이전트 프롬프팅에서는 n 개의 언어 모델 이 프레임워크 내에서 서로 다른 역할이나 에이전트로 작동합니다. 이러한 언어 모델은 동일할 수도 있고( ) 다를 수도 있습니다($( \theta_1 \neq \theta_2 \neq ... \neq \theta_n$ ).
입력 텍스트 x 에 대해, 각 에이전트 i 는 에이전트의 역할에 맞게 입력 작업 또는 문제를 포맷하는 자체 프롬프팅 함수 를 가집니다.
이 에이전트들의 상호작용은 비매개변수 함수 로 정의됩니다. 여기서 , 는 에이전트 i 의 출력이며, y 는 최종 정답입니다.
협업 제로샷 시나리오
협업 다중 에이전트 설정에서, 여러 에이전트는 동일한 언어 모델에서 파생되며 에이전트 수는 3개로 제한됩니다. 따라서 에이전트는 로 구성되며, 이 중 와 는 문제 해결 전문가, 는 요약자로 작동합니다(그림 2 참조).
입력 문제 x 에 대해, 프롬프팅 함수는 협업 팀 환경을 정의하는 시스템 메시지 로 변환합니다. 각 에이전트에 대해 프롬프팅 함수는 해당 역할을 정의하고 이에 따라 솔루션을 제공하도록 유도합니다.
- 첫 번째 전문가 에이전트의 경우, 프롬프팅 함수는 문제와 시스템 메시지를 포맷하여 를 생성하고, 언어 모델은 이를 기반으로 출력을 생성합니다.
- 두 번째 전문가 에이전트는 문제, 시스템 메시지 및 첫 번째 에이전트 출력 을 포함하여 를 생성하고, 이를 기반으로 출력을 생성합니다.
- 세 번째 요약자는 두 전문가의 출력을 포함하여 를 생성하고, 최종 정답 를 출력합니다.
특정 입력 작업에서는 여러 차례의 반복적 논의가 필요할 수 있습니다. 이 경우, 두 번째 전문가 에이전트의 출력은 첫 번째 에이전트로 다시 순환하여 입력 프롬프트로 사용되고, 이러한 논의 과정을 반복합니다(그림 2 참조).
협업 소수샷 시나리오
다중 에이전트 설정에서 소수샷 예제를 다양한 에이전트에 추가하는 것은 간단하지 않습니다. 어느 에이전트에게 소수샷 예제를 제공해야 할까요? 본 연구에서는 소수샷 예제를 서로 다른 에이전트에 제공하는 다중 경로 추론(multi-path reasoning) 접근법을 채택합니다.
- 구체적으로, 각 에이전트는 소수샷 예제에서 자신의 전문성에 기반한 추론 경로를 가집니다. 공식적으로, 두 전문가의 프롬프팅 함수는 와 로 정의되며, 여기서 과 는 예제를 나타냅니다.
- 그림 2의 예를 보면, 소수샷 예제는 물리학자와 수학자 에이전트 모두에게 추가되지만, 서로 다른 추론 경로를 따릅니다. 자세한 내용은 부록 A에서 확인할 수 있습니다.
4. 실험
이 섹션에서는 복잡한 과학 문제를 평가하기 위한 데이터셋과 벤치마크를 먼저 소개합니다. 이후 비교를 위한 강력한 기준선 프롬프팅 방법을 소개하고, 마지막으로 벤치마크에서 제안된 방법과 기준선의 결과를 제시합니다.
4.1 데이터셋
- College Physics 이 데이터셋은 Massive Multitask Language Understanding (MMLU)에서 제공되며, 다양한 도메인 지식을 포함한 57개 과목을 다룹니다. 주로 대학 수준의 물리학 문제를 포함하며, LLM이 만족스러운 성능을 내기에는 여전히 도전적인 데이터셋입니다. 그림 3의 예시와 같이, LLM은 여전히 부족한 지식과 계산 능력 문제를 겪고 있습니다.
- Moral Scenarios 이 데이터셋 역시 MMLU(Hendrycks et al., 2020)에서 제공되며, 고급 수준의 전문 사회과학 문제를 다룹니다. 이 문제는 LLM에게 매우 도전적이며, 많은 언어 모델에서 최악의 성능을 보이는 작업 중 하나입니다(Ma et al., 2023).
두 데이터셋 모두 객관식 질문으로 구성되어 있으며, 비교를 위한 지표로 정확도(Accuracy)를 사용합니다.
4.2 기준선
- Standard 프롬프팅 (Brown et al., 2020) 이 방법은 작업에 특화된 학습이나 예제 없이, 프롬프팅을 통해 사전 학습된 모델만으로 작업을 수행한 최초의 연구입니다.
- 제로샷 설정에서는 문제를 "Q: {질문} A:" 형식으로 포맷합니다.
- 소수샷 설정에서는 예제 n 개를 포함해 "Q: {질문 예제 1} A: {답변 예제 1} ... Q: {질문 예제 n } A: {답변 예제 n } Q: {질문} A:" 형식으로 프롬프팅합니다.
- Chain-of-thought (CoT) (Wei et al., 2022b) Standard 프롬프팅을 개선하여, 최종 출력에 이르는 일련의 중간 추론 단계를 추가합니다. LLM이 긴 예측 과정을 통해 더 나은 정답에 도달할 가능성이 있다고 가정합니다.
- 제로샷 설정에서는 Wang et al.(2023a)의 Zero-shot-CoT를 따라 "Let’s think step by step" 문구를 정답 전에 추가합니다.
- 소수샷 설정에서는 "Q: {질문 예제 1} A: Let’s think step by step. {체인 기반 답변 예제 1} ... Q: {질문} A: Let’s think step by step." 형식을 사용합니다.
- Thought Experiment (Thought) (Ma et al., 2023) 반사실적(reasoning with counterfactuals) 추론을 활용하여 도덕적 추론을 강화하는 프레임워크입니다. 이 방법은 다중 에이전트와 다단계 프롬프팅을 사용하며, 각 단계에서 특정 작업을 해결하도록 LLM을 유도합니다. 특히, 가상의 상황을 상상하고 이에 따른 결과를 고려하는 방식으로 문제를 해결합니다.
4.3 실험 설정
- 백본 모델 공정한 비교를 위해 모든 실험에서 GPT-3.5-turbo-0613 모델을 사용하였으며, 온도(temperature)는 0으로 설정했습니다.
- College Physics 설정
- 첫 번째 에이전트 : 물리학자 역할
- 두 번째 에이전트 : 수학자 역할
- 세 번째 에이전트 : 요약자 역할
- 제로샷 설정에서는 예제를 제공하지 않았으며, 소수샷 설정에서는 두 전문가에게 각기 다른 추론 경로(물리학자 및 수학자 역할)를 가진 동일한 5개의 예제를 제공했습니다. 그룹은 한 번만 논의하도록 설정되었습니다.
- Moral Scenarios 설정
- 첫 번째 에이전트 : 작업 분해자
- 두 번째 에이전트 : 하위 문제 해결자
- 세 번째 에이전트 : 요약자
- 소수샷 설정에서는 각 전문가에게 5개의 예제를 제공하였으며, 첫 번째 에이전트는 CoT 추론 경로를 따르고, 두 번째 에이전트는 Thought 추론 경로를 따르며, 세 번째 에이전트는 요약 역할을 맡습니다. 그룹은 두 번 논의하도록 설정되었습니다.
4.4 주요 결과
주요 실험 결과는 표 1에 나와 있습니다. 제안된 CoMM 접근법이 제로샷 및 소수샷 설정 모두에서 최첨단 기준선을 능가하는 것을 확인할 수 있습니다.
- 제로샷 설정에서 평균 3.84%의 절대적인 성능 향상을 보였으며,
- 소수샷 설정에서는 평균 8.23%의 성능 향상을 기록했습니다.
CoMM은 특히 더 복잡한 College Physics 데이터셋에서 더 높은 성능 향상을 보였으며, 복잡한 문제를 해결하는 데 있어 CoMM의 효율성을 보여줍니다.
추가 분석
- 표 2: 단일 에이전트 vs. 다중 에이전트 성능 비교
- Moral Scenarios: 제로샷에서 24.46% 향상, 소수샷에서 22.35% 향상
- College Physics: 제로샷에서 12.74% 향상, 소수샷에서 7.85% 향상
- 표 3: 단일 전문가 vs. 다중 전문가(CoMM) 비교 (College Physics)
- 물리학자 또는 수학자 단일 전문가보다 다중 전문가(CoMM) 접근법이 더 높은 성능을 기록하였습니다.
- 특히 소수샷에서 CoMM은 4.91%의 추가 성능 향상을 달성했습니다.
5. 분석
이 섹션에서는 다중 요소의 필요성을 실증적 증거로 보여줍니다. 여기에는 다중 에이전트, 다중 전문가, 다중 경로 추론, 다중 턴 논의의 필요성이 포함됩니다.
5.1 다중 독립 에이전트가 필요한가?
CoMM 접근법은 여러 LLM 인스턴스가 다른 에이전트 역할을 수행하도록 프롬프팅합니다. 그러나 왜 하나의 LLM 인스턴스가 여러 역할을 동시에 수행하도록 프롬프팅하지 않는가? 이는 Wang et al.(2023c)에서 제안된 다중 에이전트 프레임워크와 유사합니다.
CoMM에서 사용된 동일한 프롬프팅 텍스트를 단일 LLM 인스턴스에 적용하여 실험한 결과가 표 2에 나와 있습니다. 다중 에이전트(CoMM)의 성능은 단일 에이전트 접근법을 모든 벤치마크와 설정에서 유의미하게 능가했습니다. 이는 단일 LLM 인스턴스가 자기 일관성을 유지하려는 경향이 있어, 다양한 역할을 전환하도록 프롬프팅하면 모델이 혼란스러워져 올바른 예측을 방해한다고 가설을 세울 수 있습니다. 우리의 결과는 Xu et al.(2023)의 발견과 일치합니다.
5.2 다중 도메인 전문가가 필요한가?
College Physics 벤치마크에서 LLM은 물리학자와 수학자라는 두 명의 전문가 역할을 수행하도록 프롬프팅되었습니다. 이는 문제를 협력적으로 해결하면서 물리학자는 물리학 도메인 지식을 이끌어내고, 수학자는 계산 오류를 극복하도록 하기 위함입니다.
표 3에 따르면, 단일 전문가 접근법은 성능이 낮으며 CoT 기준선도 능가하지 못했습니다. 추가로, 동일한 전문성을 가진 다중 전문가 역할을 수행하도록 프롬프팅한 결과, 단일 전문가 접근법보다는 성능이 향상되었지만, 서로 다른 전문성을 가진 다중 전문가 설정보다 낮은 성능을 보였습니다. 결과적으로, 다중 전문가 협력 프레임워크의 필요성과 효과성이 실증되었습니다.
5.3 다중 턴 논의가 필요한가?
CoMM 프레임워크는 다중 턴 논의를 지원하여, 에이전트들이 최종 답변에 도달하기 위해 여러 차례 논의할 수 있습니다. 다중 턴 논의의 필요성을 평가하기 위해 한 번의 논의와 두 번의 논의를 비교한 결과가 표 4에 나와 있습니다.
- Moral Scenarios 데이터셋에서는 두 번의 논의가 더 나은 성능을 보였습니다.
- 반면, College Physics 데이터셋에서는 한 번의 논의가 더 나은 성능을 보였습니다.
이는 물리학 문제의 경우 간결하고 명확한 추론 경로가 요구되며, 과도한 논의는 혼란과 환상을 초래해 문제 해결에 도움이 되지 않을 수 있다는 가설을 제시합니다. 반면, 사회과학 문제는 철저한 논의를 통해 합의에 도달하는 방식이 자연스럽게 더 적합합니다.
6. 사례 연구
- College Physics 사례 연구 그림 3에서는 물리학 문제(그림 1과 동일한 문제)에 대한 CoMM의 추론 결과를 보여줍니다. CoT 접근법은 잘못된 지식과 계산 오류를 포함하지만, CoMM 프레임워크에서는 물리학자 에이전트가 계산 오류를 범한 후 수학자 에이전트가 이를 수정하며 최종적으로 올바른 답에 도달합니다. 물리학자 에이전트는 물리학 도메인 지식을 제공하고, 수학자 에이전트는 이를 기반으로 계산을 수정하며, 요약자 에이전트는 논의 내용을 바탕으로 최종 답변을 제공합니다.
- Moral Scenarios 사례 연구 그림 4에서는 소수샷 설정에서의 Moral Scenarios 문제를 다룹니다. CoT 기준선은 "쓰레기통에 개의 배설물을 버리는 행동"의 도덕적 정당성을 올바르게 판단하지 못했습니다. CoMM 초기 단계에서는 CoT 추론자와 Thought 추론자 모두 도덕적 측면을 정확히 평가하지 못했으나, 첫 번째 논의 이후 두 추론자가 초기 평가를 수정하며 도덕적으로 올바르다고 판단했습니다. 요약자는 이를 확인하고 최종 답변을 제공합니다. 이 사례는 CoMM의 반복적이고 협력적인 추론이 도덕적 판단 문제를 해결하는 데 효과적임을 보여줍니다.
7. 결론
본 연구는 CoMM 프롬프팅 프레임워크를 통해 LLM의 추론 능력을 개선한 주요 성과를 강조합니다. 다중 에이전트와 다중 경로 추론 접근법을 활용하여 LLM이 문제 해결 팀 내에서 다양한 역할을 수행하도록 유도하며, 복잡한 과학 문제를 해결하기 위한 협업 환경을 조성했습니다. 두 가지 대학 수준 과학 과제에서의 실험 결과는 제안된 방법의 효율성을 입증했으며, 다중 에이전트 환경에서의 소수샷 프롬프팅 가능성을 보여주었습니다. 또한, 분석 결과는 독특한 역할 수행이 더욱 세밀하고 정교한 문제 해결 전략을 달성하는 데 필수적임을 나타냅니다. 본 연구는 LLM을 복잡하고 전문화된 작업에 적용하는 AI 추론의 발전 가능성을 열어줍니다.
8. 한계점
CoMM 프레임워크는 LLM의 추론 능력 상한을 확장했지만, 여전히 한계가 존재합니다. 제안된 프레임워크는 전문가와 추론 예제를 정의하기 위한 작업별 설계가 필요합니다. 이는 모든 CoT 스타일 접근법(Wei et al., 2022b)에서 공통적인 한계입니다. 예를 들어, CoT 접근법은 체인 기반 추론 단계를 포함한 소수샷 예제를 설계해야 하며, Thought 기준선(Ma et al., 2023)은 특정 추론 실험 설계를 요구하고, 단일 벤치마크(MMLU의 Moral Scenarios)에서만 작동합니다. CoMM 프레임워크의 자동화된 프롬프팅 설계는 향후 연구 과제로 남겨둡니다.
