https://arxiv.org/pdf/2411.03284
https://github.com/David-Li0406/SMoA
간단 요약
SMoA (Sparse Mixture-of-Agents)는 다중 에이전트 기반의 대형 언어 모델(LLM) 성능을 향상시키기 위해 Sparse Mixture-of-Experts(SMoE) 개념에서 영감을 받아 제안된 새로운 프레임워크입니다. 기존의 MoA(Mixture-of-Agents)와의 주요 차이점과 향상된 방법에 대해 설명하겠습니다.
1. SMoA의 개념 및 목적
SMoA는 다중 에이전트 시스템에서 정보의 흐름을 희소화(sparsify)하여 각 에이전트 간의 상호작용을 줄여 성능을 높이면서도 연산 효율을 극대화하는 것을 목표로 합니다. 기존 MoA 구조는 각 층마다 여러 에이전트들이 입력을 동시에 처리하여 빠른 응답을 생성하지만, 높은 연산 비용과 낮은 다양성(diversity)이라는 문제점이 있었습니다. SMoA는 이에 대응하기 위해 희소성 있는 정보 교환과 다양한 역할 할당을 통해 성능과 효율성을 균형 있게 조율합니다.
2. SMoA의 주요 구성 요소
SMoA는 MoA 구조를 개선하기 위해 'Judge'와 'Moderator'라는 두 가지 새로운 역할을 도입했습니다.
- Judge (판정자): 각 층의 에이전트들이 생성한 응답 중 고품질의 응답만을 선택하여 다음 단계로 전달함으로써, 잡음을 줄이고 정보 전달 효율성을 높입니다.
- Moderator (조정자): 각 라운드가 끝날 때마다 응답 상태를 평가하여 중단할지 여부를 결정함으로써, 불필요한 연산을 줄이고 조기 종료(Early Stopping)를 통해 효율성을 높입니다.
3. 핵심 기술: Response Selection과 Early Stopping
- Response Selection: Judge 에이전트가 각 층에서 생성된 응답들 중 최적의 k개 응답을 선택하여, 다음 층에 전달합니다. 이를 통해 고품질 응답만 다음 단계로 이어지게 하여 전체 정보 흐름의 효율성을 극대화합니다.
- Early Stopping: Moderator 에이전트는 에이전트 간 충분한 합의가 도출되면 프로세스를 조기 종료할 수 있습니다. 이를 통해 필요 없는 계산을 피하고 효율을 극대화합니다.
4. 역할 할당(Role-playing)
SMoA는 다양한 역할 할당을 통해 각 에이전트에 특정한 역할을 부여함으로써 다양한 사고와 관점을 도입합니다. 이를 통해 응답 생성 과정에서 에이전트들이 다양한 해결책을 모색할 수 있도록 합니다.
5. 실험 결과와 효율성
실험 결과에 따르면, SMoA는 MoA와 유사한 성능을 유지하면서도 연산 비용을 크게 줄였습니다. 다양한 벤치마크에서 SMoA는 고품질의 응답을 제공하며, 특히 확장성과 안정성 면에서 뛰어난 잠재력을 보였습니다.
요약
SMoA는 기존의 다중 에이전트 모델이 가진 연산 비용 문제와 다양성 부족 문제를 해결하기 위해 제안된 프레임워크로, 성능 저하 없이 연산 효율성을 개선하는 데 중점을 둡니다.
초록 (Abstract)
다중 에이전트 시스템은 다양한 작업 및 응용 분야에서 대형 언어 모델(LLM)의 성능을 크게 향상시키는 것으로 입증되었습니다. 그러나 에이전트 간의 밀집된 상호작용은 효율성과 다양성을 저하시킬 수 있습니다. 이러한 문제를 해결하기 위해 희소 혼합 에이전트(SMoE)에서 영감을 받아, 다중 에이전트 LLM의 효율성과 다양성을 향상시키기 위한 희소 혼합 에이전트(SMoA) 프레임워크를 제안합니다. SMoA는 완전 연결 구조와 달리, 각 LLM 에이전트 간의 정보 흐름을 희소화하는 새로운 응답 선택(Response Selection) 및 조기 종료(Early Stopping) 메커니즘을 도입하여 성능과 효율성의 균형을 맞춥니다. 또한, 전문가 다양성 원칙을 적용하여 각 LLM 에이전트에 고유한 역할 설명을 할당해 다양하고 독창적인 사고를 장려합니다. 추론, 정렬, 공정성 벤치마크에 대한 광범위한 실험을 통해 SMoA가 기존의 혼합 에이전트 접근법과 유사한 성능을 유지하면서도 훨씬 낮은 계산 비용을 필요로 함을 입증했습니다. 추가 분석을 통해 SMoA는 더 안정적이고 확장 가능성이 높으며 하이퍼 파라미터 최적화를 통해 큰 잠재력을 가지고 있음을 확인했습니다. 코드와 데이터는 https://github.com/David-Li0406/SMoA 에서 제공될 예정입니다.
1. 서론 (Introduction)
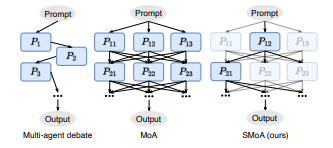
최근 몇 년간 대형 언어 모델(LLM)의 급속한 발전으로 질문 응답, 지식 발견, 대화 시스템 등의 다양한 자연어 처리(NLP) 작업에서 큰 진보가 이루어졌습니다. 이러한 대규모 모델들은 광범위한 훈련 데이터와 모델 크기 확장을 통해 성능이 크게 향상되었으나, 추가 확장은 수조 개의 토큰을 다시 훈련해야 할 정도로 비용이 매우 큽니다. 이를 극복하기 위해, 다중 에이전트 LLM이 탐구되어 각 에이전트가 고유한 목표와 작업에 집중할 수 있게 합니다.
다중 에이전트 LLM 시스템을 구현하기 위한 가장 기본적인 전략 중 하나는 계층 기반 구조로, 각 에이전트가 다중 라운드에 걸쳐 문제 해결을 위한 토론을 수행하도록 하는 방식입니다. 그러나 기존의 계층 기반 접근법은 각 질의에 대해 한 번에 한 에이전트만 처리하므로 실사용 사례에 효과적으로 적용되지 못합니다. 최근에는 혼합 에이전트(MoA) 접근법이 도입되어 계층당 여러 프로세서가 동시에 질의를 처리하고, 이를 종합하여 최종 응답을 생성하여 시간 효율성을 높입니다.
MoA는 처리 시간을 줄이는 데 도움이 되지만, 두 가지 중요한 문제점이 있습니다. 첫째는 높은 토큰 계산 비용으로, MoA의 동시 처리 특성상 전체 연산 수요가 증가하여 확장성이 제한되고 토큰 경제성이 저하됩니다. 둘째는 LLM 에이전트 간 다양한 사고의 부족입니다. MoA는 반복적인 응답 생성에 의존하여 다양한 사고가 필요한 작업에서 성능이 떨어집니다.
이러한 한계를 극복하고 다중 에이전트 LLM의 유용성을 높이기 위해, SMoE의 설계에서 영감을 얻어 희소 혼합 에이전트(SMoA)를 제안합니다. 완전 연결 구조와 달리, SMoA는 두 가지 새로운 에이전트를 통해 상호작용의 희소성을 도입합니다:
- Judge LLM: 다음 라운드를 위해 고품질 응답을 선택하는 역할.
- Moderator LLM: 정보 흐름을 제어하고 중단 시점을 결정하는 역할.
이를 통해 불필요한 데이터 처리를 줄이고, 성능과 효율성 간의 균형을 맞추어 더 나은 확장성을 제공합니다. SMoE의 전문가 다양성 원칙에서 영감을 얻어, 각 LLM 에이전트에 고유한 역할을 부여하여 다양한 사고를 촉진합니다.
기존의 다중 에이전트 LLM은 보통 하나 또는 두 가지 작업에 집중하였으나, 본 연구에서는 정렬, 추론, 안전성, 공정성 벤치마크에 걸친 다양한 다중 에이전트 LLM 전략을 철저히 평가하였습니다. 실험 결과, SMoA는 MoA와 유사한 성능을 유지하면서도 계산 비용이 훨씬 적게 들며, 실사용 문제 해결에서 더 안정적이고 신뢰할 수 있는 것으로 나타났습니다. SMoA는 특히 효율적이고 다양한 사고를 장려하며 MoA에 비해 확장 가능성이 더 높음을 확인했습니다.
요약 (Summary of Contributions)
- 기존 다중 에이전트 LLM 프레임워크의 주요 한계를 파악하고, 이를 해결하기 위해 새로운 SMoA 아키텍처를 제안합니다.
- 다양한 작업에 걸친 광범위한 실험을 통해, SMoA가 MoA와 유사한 성능을 유지하면서도 훨씬 적은 계산 자원을 사용하는 것을 입증했습니다.
- SMoA의 장점을 강조하며 다양한 다중 에이전트 접근법 간의 비교와 분석을 제공합니다.
2 관련 연구
2.1 다중 에이전트 LLM (Multi-agent LLMs)
다중 에이전트 LLM은 여러 LLM을 에이전트로 활용하여 협력적으로 문제를 해결하는 방안을 탐구하는 데 목적이 있습니다. 한 가지 연구 방향으로는 계층 기반 다중 에이전트 방법이 있으며, 이는 여러 LLM이 서로 토론하고 자신의 응답을 방어하도록 하는 방식입니다(Liang et al., 2023; Du et al., 2023; Chan et al.). 추가로, 여러 LLM들이 서로의 응답을 참고하고 자신의 연속적인 응답을 생성하도록 안내하는 혼합 에이전트 방식도 제안되었습니다(Zhang et al., 2023; Li et al., 2023b; Wang et al., 2024b). 이 두 가지 구조를 바탕으로, 코드 생성이나 생의학적 추론 같은 다양한 영역의 인간 작업 흐름을 모방하는 더 복잡한 구조들도 제안되었습니다.
2.2 희소 혼합 전문가 (Sparse Mixture-of-Experts)
SMoE(Shazeer et al., 2016; Chen et al., 2023; He et al., 2023, 2024)의 핵심 아이디어는 입력마다 소수의 전문가만 활성화하여 기존의 MoE 모델에 비해 계산 비용을 크게 줄이는 것입니다. 동적 라우팅(Rosenbaum et al., 2018) 및 해시 기반 라우팅(Roller et al., 2021) 같은 라우팅 기법들은 특정 전문가의 효율적 자원 활용을 최적화하도록 돕습니다. 또한, 전문가 간의 부하 균형(Fedus et al., 2022)은 특정 전문가의 과소 사용과 과도한 전문화를 방지하는 데 중점을 둡니다. 본 연구에서는 SMoE의 통찰을 빌려 SMoA 내 각 계층 사이의 정보 흐름을 희소화하고 역할 할당을 통해 에이전트 LLM의 다양성을 강화했습니다.
3 방법론 (Methodology)
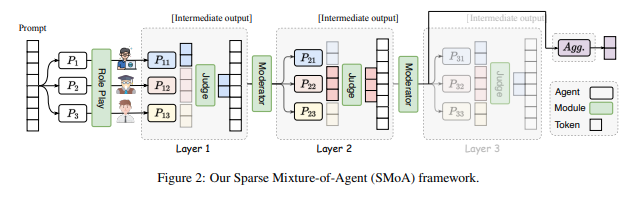
본 절에서는 MoA에 대한 기본 개념을 소개하고 이를 바탕으로 SMoA 설계의 원리와 세부 사항을 설명합니다. 그림 2는 SMoA의 전체 구조를 나타냅니다.
3.1 기초 개념: 혼합 에이전트 (Mixture-of-Agents)
다중 에이전트 LLM 시스템을 위한 MoA 구조는 여러 연구에서 채택되었으며, 본 연구에서는 Wang et al. (2024b)의 구현 및 정의를 따릅니다. 이 연구에서는 협업 과정에서 LLM에 두 가지 역할, 즉 제안자(proposer)와 집약자(aggregator)를 할당합니다. 제안자는 서로에게 유용한 참조 응답을 생성하는 데 중점을 두고, 집약자는 다른 모델의 응답을 하나의 고품질 응답으로 통합하는 데 능숙한 모델입니다.
특히, MoA 구조는 개의 계층으로 구성되며, 각 계층-i는 n 개의 제안자 로 구성됩니다. 한 계층에서 각 제안자 는 입력 텍스트를 처리하여 다음 계층을 위한 참조 응답을 생성합니다. 입력 x1 이 주어졌을 때, i번째 MoA 계층의 출력 는 다음과 같이 표현됩니다:
여기서 + 는 연결 연산을 의미하며, 는 이전 라운드의 출력을 기반으로 LLM에 생성하도록 지시하는 집합 및 통합 프롬프트를 의미합니다. 위 과정을 번 반복한 후, 집약자 가 최종 응답을 생성합니다:
3.2 희소 혼합 에이전트 (Sparse Mixture-of-Agents)
MoA 구조를 개선하고 성능과 효율성의 균형을 맞추기 위해 SMoE의 개념에서 영감을 받았습니다. SMoE는 입력 처리를 위해 선택된 일부 전문가만 활성화하여 계산 효율성을 최적화하면서 모델 성능을 유지하는 것이 특징입니다. 이를 바탕으로 SMoA 아키텍처에 두 가지 새로운 역할을 추가했습니다:
- Judge (판정자): 각 프로세서가 생성한 응답을 포괄적으로 평가하여 품질이 낮은 응답을 걸러내고, 품질이 높고 적절한 응답만을 다음 라운드에 전달합니다.
- Moderator (조정자): 각 프로세서의 전진 과정을 제어하는 에이전트로, 여러 프로세서가 합의에 도달했을 때 전진 과정을 중단하는 결정을 내립니다.
두 가지 새로운 에이전트를 기반으로 MoA 최적화를 위한 응답 선택(3.2.1절) 및 조기 종료(3.2.2절)를 제안합니다.
3.2.1 판정자를 활용한 응답 선택 (Response Selection with Judge)
MoA 프레임워크에서는 각 층의 프로세서가 주어진 입력에 대해 고유한 연속 응답을 생성하므로, 어떤 응답을 다음 층에 전달하거나 최종 출력 생성에 사용할지 결정하는 것이 중요합니다. 이를 해결하기 위해 SMoA는 중심적인 역할을 수행하는 판정자 에이전트 J 를 도입했습니다. J 는 현재 층에서 LLM이 생성한 출력을 평가하여 다음 라운드로 진행할 가장 적합한 응답을 선택합니다.
특히, SMoE에서의 Top-K 선택 개념을 차용하여, 입력 와 생성된 응답 후보 가 주어졌을 때, 판정자 J 는 최상의 k 개의 응답을 선택하여 다음 반복의 입력으로 결합합니다:
여기서 k 는 전체 에이전트 네트워크의 희소성을 제어합니다. 응답 선택을 도입함으로써, SMoA는 잡음을 크게 줄이고 특히 각 계층에 많은 LLM이 있는 경우 전체 정보 흐름의 효율성을 향상시킵니다. 이 방법은 생성의 효율성과 최종 출력의 품질 간의 균형을 맞추어, 판정자로서의 LLM의 잠재력을 활용합니다.
3.2.2 조정자를 활용한 조기 종료 (Early Stopping with Moderator)
MoA 프레임워크에서는 여러 계층의 LLM이 반복적으로 다수의 응답을 생성하고, 정제된 출력을 다음 계층에 전달합니다. 이 과정은 고정된 라운드 수로 제어되지만, 경우에 따라 고품질 응답이 일찍 도출되거나 다수의 프로세서가 합의에 도달하면 모든 계층을 거칠 필요가 없습니다. 이전 연구에서는 대부분의 에이전트가 동일한 응답을 산출하면 중단하는 규칙 기반 방법을 제안하였으나, 다양한 작업과 응용을 다룰 수 있는 일반적이고 동적인 접근법은 부족했습니다. 이를 해결하기 위해, SMoA는 각 층의 출력 상태를 동적으로 평가하여 조기 종료 여부를 결정하는 조정자 에이전트 M 을 도입하였습니다.
3.2.2 조정자와 함께하는 조기 종료 (Early Stopping with Moderator)
MoA 프레임워크에서 각 계층의 LLM은 반복적으로 여러 응답을 생성하고, 정제된 출력을 다음 계층에 전달합니다. 이 과정은 고정된 라운드 수로 제어되지만, 경우에 따라 고품질 응답이 일찍 생성되거나 대부분의 프로세서가 합의에 도달한 경우 모든 계층을 거칠 필요가 없습니다. 이전 연구에서는 대부분의 에이전트가 동일한 응답을 생성하면 중단하는 규칙 기반 방법을 제안하였지만(Liu et al., 2023), 다양한 작업과 응용에 적용 가능한 일반적이고 동적인 접근법은 부족했습니다. 이를 해결하기 위해 SMoA는 각 층의 출력 상태를 동적으로 평가하여 조기 종료 여부를 결정하는 조정자 에이전트 M 을 도입했습니다.
구체적으로, 각 라운드가 끝날 때마다 M 은 모든 응답을 바탕으로 평가 지시를 받아 정보 교환 과정을 중단하고 최종 응답을 직접 생성할지 여부를 제어하는 이진 신호를 생성합니다:
이때 True/False는 반복을 중단하고 최종 응답을 생성할지를 나타냅니다. 조정자 에이전트를 위한 프롬프트에서는 조기 종료 결정을 내리기 위해 품질, 합의 수준, 논란의 정도 등 세부 요소를 평가하도록 합니다(Chang, 2024). 조기 종료 방법은 협업 과정에 세밀한 조정을 적용하는 동적 제어 장치로서 작동하며, SMoA를 더 효율적이고 적응력 있는 프레임워크로 만들어 불필요한 계산을 최소화하면서도 고품질 결과를 제공합니다.
3.2.3 프로세서와 함께하는 역할 할당 (Role Playing with Processor)
SMoE의 또 다른 핵심 메커니즘은 전문가들 간의 다양성 원칙으로, 네트워크의 견고성과 부하 균형을 보장하는 데 목적이 있습니다. SMoA에서도 이러한 통찰을 차용하여, 각 프로세서 간의 다양성을 향상시키기 위해 개인화된 대화에서 널리 사용되는 역할 할당(role-playing) 기법을 도입했습니다(Wang et al., 2023; Li et al., 2023a). 구체적으로, 데이터셋 설명 D 및 작업 요구사항 T 에 기반하여 다양한 역할 설명을 생성하고, 각 제안자에게 시스템 프롬프트로 할당하여 후보 응답 생성 시 다양성을 증가시킵니다:
지면의 제한으로 인해 MoA와 SMoA에 대한 추가적인 지시와 예시는 부록 A에 상세히 제공됩니다.
4 실험 (Experiment)
4.1 실험 설정
벤치마크: 각 방법의 정렬 수준, 추론 능력, 안전성과 공정성을 측정하기 위해 다양한 작업에서 평가를 수행했습니다. 정렬 수준 평가에는 Just-Eval(Lin et al., 2023) 벤치마크를 사용하며, 5개의 정렬 데이터셋(AlpacaEval2, MT-Bench, LIMA, HH-RLHF-redteam, MaliciousInstruct)을 포함합니다. 모든 샘플에 대해 GPT-4o로 응답을 평가했습니다. 추론에는 MMAU(Yin et al., 2024)를 사용하여 수학적 이해, 도구 사용, 코드 경연 등 도전적인 추론 작업을 포함하고, 공정성 평가에는 응답의 독성 및 편향성 검토를 위한 CEB(Wang et al., 2024c) 대화 데이터셋을 사용했습니다.
비교 방법:
- Self-Consistency (SC): 복잡한 추론 문제는 여러 사고 방식을 허용하여 고유한 정답을 도출할 수 있다는 직관에 기반하여 샘플 후 투표 방식을 따릅니다.
- Mixture-of-Agent (MoA): 3.1절에서 소개한 완전 연결 다중 에이전트 프레임워크를 사용하며, 실험에서는 (Wang et al., 2024b)의 구현을 따릅니다.
- Multi-agent Debating (MAD): 생성 과정에서 다양한 사고를 장려하기 위해 여러 에이전트가 토론하도록 유도하는 방법입니다.
- Sparse Mixture-of-Agent (SMoA): 응답 선택, 조기 종료, 역할 할당을 도입한 SMoA의 새로운 아키텍처입니다.
구현 세부사항: 주요 실험에서 공정한 비교를 위해 오픈 소스 모델만 사용하여 각 다중 에이전트 및 앙상블 방법을 구성했습니다. (Wang et al., 2024b)를 따라 Qwen1.5-72BChat, Qwen2-72B-instruct, WizardLM-8x22B, dbrx-instruct 모델을 사용하며, 추가로 OpenAI의 GPT-3.5와 GPT-4를 포함하여 포괄적인 평가를 수행했습니다. MoA와 SMoA의 경우, 프로세서 수는 4, 계층 수는 2로 설정했으며, SMoA의 응답 선택 수 k 는 2로 설정했습니다. 하이퍼파라미터에 대한 추가 분석은 5장에서 다루며, 더 많은 구현 세부사항은 부록 B에서 확인할 수 있습니다.
4.2 주요 결과 (Main Result)
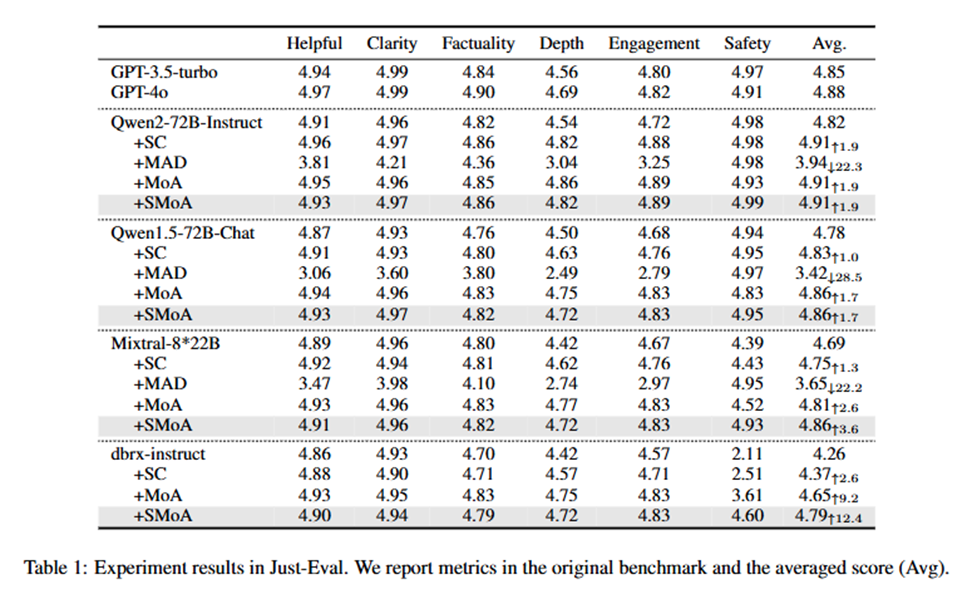
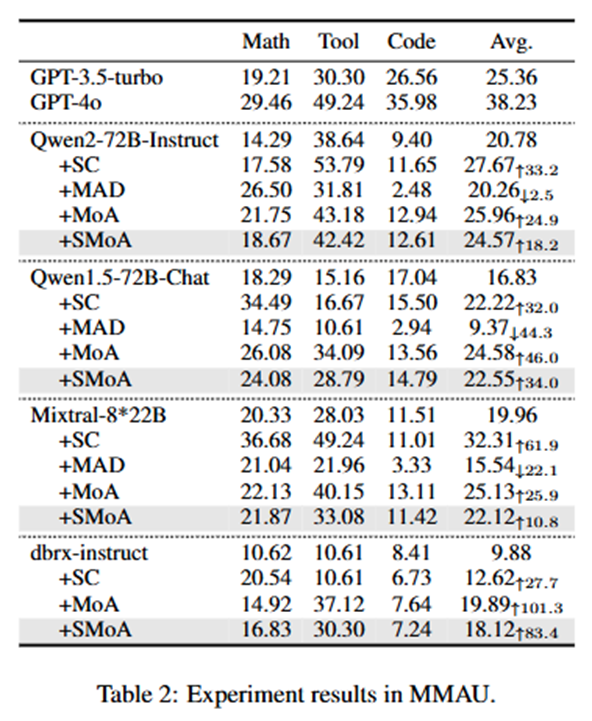
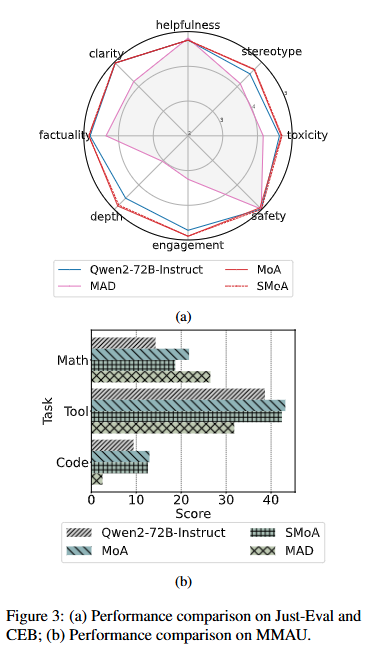
전체 비교
각 데이터셋에서 서로 다른 방법들의 성능을 비교했습니다 (표 1, 2, 3). Just-Eval에서 SC, MoA 및 SMoA는 베이스라인 성능을 크게 개선한 반면, MAD는 성능이 하락했습니다. 특히, SMoA와 MoA는 강력한 GPT-4o 모델과 비교했을 때도 정렬 작업에서 유사한 결과를 나타냈습니다. MMAU 데이터셋에서는 SC가 탁월한 성능을 보여 베이스라인을 크게 향상시켰으며, MoA와 SMoA도 일관된 개선을 제공했지만, MAD는 긍정적인 결과를 보여주지 못했습니다. CEB 데이터셋에서는 SMoA가 독성 및 고정관념을 줄이는 데 있어 최상의 결과를 보여 네 가지 베이스라인 LLM 중 세 가지에서 최상의 결과를 달성했습니다. MoA와 SC가 그 뒤를 이었고, MAD는 다시 한 번 베이스라인 성능을 떨어뜨렸습니다.
요약하면:
- MoA와 SMoA는 모든 세 가지 작업에서 일관되고 유사한 개선을 제공합니다.
- SC는 추론 작업에서 MoA와 SMoA를 능가하지만 정렬과 공정성에서는 뒤처집니다.
- MAD는 거의 모든 작업에서 성능 하락을 유발한 가장 비효율적인 방법입니다.
다중 에이전트 방법 비교
각 다중 에이전트 방법을 보다 세부적으로 이해하기 위해 Qwen2-72B-Instruct를 사용하여 직접 비교를 제공했습니다 (그림 3a와 3b). 그림 3a에서 Just-Eval과 CEB 데이터셋을 사용하여 정렬 및 공정성 속성을 분석했습니다. MoA와 SMoA는 깊이와 참여도 면에서 단일 에이전트 베이스라인을 개선하는 동시에 고정관념과 독성을 줄였습니다. 흥미롭게도, MAD는 유용성과 안전성 면에서 경쟁력을 보이지만 다른 모든 면에서 베이스라인보다 저조한 성과를 보였습니다. 이는 토론 방식의 이분법적 특성이 실제 시나리오에서 다양한 사고를 제한할 수 있음을 시사합니다.
그림 3b에서는 각 방법의 추론 능력을 MMAU의 세 가지 하위 집합에서 평가했습니다. MoA는 모든 작업에서 일관되게 단일 LLM 베이스라인의 성능을 향상시켰습니다. SMoA의 개선 폭은 MoA보다 약간 적었지만, 여전히 일관된 향상을 제공했습니다. 그러나 MAD는 수학적 이해를 크게 향상시키는 반면 도구 및 코드 하위 집합에서는 성능을 감소시켰습니다. 이를 바탕으로, 계층 기반 아키텍처(MoA 및 SMoA)가 다중 에이전트 LLM에 대해 토론 기반 접근법보다 더 안정적이고 신뢰할 수 있음을 확인했습니다.
5 추가 분석 (Further Analysis)
응답 수는 SMoA의 중요한 하이퍼파라미터입니다.
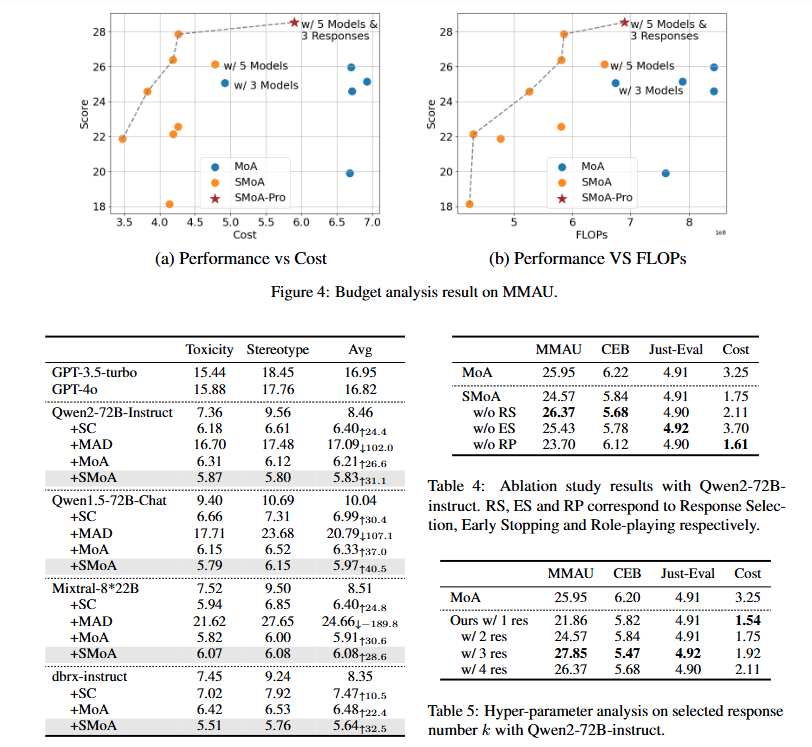
응답 선택에 대한 소거 연구를 진행했으며, 그 결과는 표 4에 나와 있습니다. 결과에 따르면 응답 선택이 효율성을 향상시키지만 MMAU와 CEB에서 성능이 감소하는 경향이 있습니다. 이에 대한 영향을 더 잘 이해하기 위해 선택된 응답 수 k 에 대한 하이퍼파라미터 분석을 수행했습니다. 그림 5에서 보듯이 모델 성능은 k 가 증가할 때 초기에는 개선되다가 ( k = 1, 2, 3 ) k = 4 에서는 감소하는 패턴을 보입니다. 모델이 세 데이터셋 모두에서 최적 성능을 달성한 값은 k = 3 으로, 이는 선택된 참조 응답의 정보성 및 품질 사이의 균형을 나타냅니다. 이러한 결과는 선택된 응답 수가 SMoA에서 효율성과 성능을 균형 있게 유지하는 데 중요한 하이퍼파라미터임을 강조합니다.
조기 종료는 성능의 약간의 희생을 통해 큰 효율성 향상을 제공합니다.
표 4에서 조기 종료에 대한 소거 결과는 이 메커니즘이 제거될 때 세 가지 데이터셋에서 약간의 성능 저하가 발생함을 보여줍니다. 그러나 비용은 평균 1.75에서 3.70으로 급증하여 SMoA의 효율성을 높이는 데 조기 종료가 얼마나 중요한 역할을 하는지 나타냅니다. 또한, 조기 종료를 제거할 경우 추가 프롬프트 토큰으로 인해 MoA보다 높은 비용이 발생합니다 (3.70 대 3.25). 이는 역할 할당 및 응답 선택을 위한 추가 프롬프트 토큰 필요성에 기인합니다. SMoA 프레임워크에서 조기 종료의 중요성을 강조합니다.
역할 할당이 가져오는 발산적 사고는 추론 능력과 공정성에 도움이 됩니다.
역할 할당 모듈을 제거하면 (표 4), LLM의 추론 및 공정성 능력과 밀접한 관련이 있는 MMAU 및 CEB에서 성능이 크게 저하됨을 확인할 수 있습니다. 이는 역할 할당 과정이 가져오는 발산적 사고가 다중 에이전트 LLM에 큰 이점을 제공함을 시사합니다. 이 발견은 이전의 추론(Wang et al., 2022) 및 공정성(Han et al., 2021; Saunders et al., 2022)에 관한 연구 결과와도 일치합니다. 또한, 4.2절의 결과와 함께, 역할 할당이 다중 에이전트 LLM이 문제를 포괄적으로 분석하고 해결하는 데 이분법적 토론보다 더 효과적임을 결론지을 수 있습니다.
SMoA는 확장 가능성에서 더 큰 잠재력을 보여줍니다.
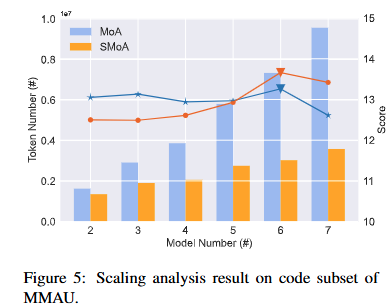
확장 가능성은 다중 에이전트 LLM 시스템을 평가하는 데 중요한 요소입니다(Qian et al., 2024). 이를 다루기 위해, 추가 LLM 프로세서를 포함하여 SMoA와 MoA의 확장 가능성을 비교하는 확장 분석을 수행했습니다. 구체적으로, 추가 LLM 프로세서(deepseek-llm-67b, Llama3-70b-chat, WizardLM2-8x22B)를 통합하여 성능과 토큰 비용 추세를 모니터링했습니다. 그림 5에서 보듯이, 완전 연결 MoA에서는 토큰 수가 급격히 증가하여 많은 프로세서 에이전트를 도입할수록 큰 계산 비용이 발생했습니다. 반면, SMoA는 효율성을 유지하고 프로세서 수가 증가해도 더 적절한 토큰 활용을 보여줬습니다. SMoA는 적은 토큰을 사용하면서도 MoA보다 더 나은 성능을 발휘하여, SMoA가 더 많은 에이전트를 사용해도 효율적으로 확장할 수 있는 잠재력을 가지고 있음을 강조했습니다.
SMoA는 성능-효율성의 최전선에 있습니다.
그림 4에서 MMAU 데이터셋의 평균 추론 비용과 성능 점수를 플롯하여, 과도한 비용 없이 높은 성능을 제공하는 비용 효율적인 모델을 식별하는 데 도움을 주었습니다. 그래프는 비용과 성능 간의 최적 균형을 이루는 "파레토 최전선"을 나타냅니다. 이 최전선에 가까운 모델은 더 나은 성능을 낮은 비용으로 제공하여 더 바람직합니다. 특히, SMoA는 훨씬 적은 토큰을 사용하면서 최상의 성능을 달성했습니다. 유사한 계산 비용과의 공정한 비교를 위해, SMoA와 MoA에 대한 프로세서 에이전트 수를 조정하고, SMoA-Pro를 소개하여 에이전트와 선택된 응답 수를 늘렸습니다. 결과적으로 SMoA의 구성은 성능-효율성의 최전선에 위치하게 됨을 결론지었습니다.
5.1 사례 연구 (Case Study)
표 6에 예시를 제시하여 응답 선택(Response Selection)과 조기 종료(Early Stopping)의 효과를 더 명확하게 설명합니다. Qwen2-72B-Instruct와 Qwen1.5-72B-Chat의 응답은 정확하지만, Mixtral-8x22B-Instruct-v0.1과 dbrx-instruct의 응답은 부정확합니다. 판정자 에이전트는 올바른 응답을 성공적으로 선택하고 잘못된 응답을 필터링하여 집약 과정 중 잠재적인 오도 가능성을 방지합니다. 또한, 조정자 에이전트는 현재 응답 상태에 기반하여 조기 종료를 유도하여 SMoA의 시간 및 계산 자원 효율성을 향상시킵니다. 더 많은 사례는 부록 D에 포함되어 있습니다.
종합적으로, SMoA는 추론 오류(Tong et al., 2024; An et al., 2023)를 식별하고 안전하지 않은 콘텐츠(Tan et al., 2024b; Beigi et al., 2024b) 또는 잘못된 정보(Jiang et al., 2024b; Yang et al., 2023; Beigi et al., 2024a)를 필터링하며 정보 교환 과정을 조정하는 데 뛰어난 성능을 발휘합니다.
6 결론 (Conclusion)
이 논문에서는 다중 에이전트 LLM 시스템의 효율성과 다양성을 향상시키기 위해 설계된 SMoA 아키텍처를 제안합니다. 이 접근법은 희소성을 활용하여 현재 계층 기반 다중 에이전트 방법에서 일반적으로 사용되는 완전 연결 구조를 최적화합니다. 다양한 벤치마크와 모델을 통해 포괄적인 비교와 분석을 제공하며, SMoA가 효율성을 개선하고 다양한 사고를 장려할 뿐만 아니라 기존 MoA보다 더 큰 확장 가능성을 제공함을 보여줍니다.
한계 (Limitation)
이 연구에서 우리는 다중 에이전트 LLM 시스템의 기본 구조인 계층 기반 다중 에이전트 LLM에 희소성을 도입했습니다. 최근에는 네트워크 기반 다중 에이전트 구조(Zhuge et al.; Qian et al., 2024)가 등장하고 있으며, 본 연구에서는 공간 제한으로 인해 이러한 방법에 SMoA를 적용하지 않았으며, 이는 향후 연구 과제로 남겨두었습니다. 또한, SMoA는 각 프로세서의 입력 토큰을 줄이지만 참조 생성을 위해 모든 프로세서를 활성화합니다. 향후 연구의 유망한 방향은 계층 기반 다중 에이전트 LLM을 위한 희소 활성화의 효과적인 전략을 탐구하는 것입니다.
