https://arxiv.org/pdf/2309.17453
Introduction 섹션 전체
대규모 언어 모델(LLM)은 대화 시스템, 문서 요약, 코드 완성, 질의 응답과 같은 다양한 자연어 처리 애플리케이션에서 널리 사용되고 있습니다(Radford et al., 2018; Brown et al., 2020; Zhang et al., 2022; OpenAI, 2023; Touvron et al., 2023a; b). 사전 학습된 LLM의 잠재력을 완전히 활용하기 위해서는 효율적이고 정확하게 긴 시퀀스 생성을 수행할 수 있어야 합니다. 예를 들어, 이상적인 ChatBot은 최근 하루 종일의 대화 내용을 안정적으로 처리할 수 있어야 합니다. 그러나 LLM이 사전 학습에서 사용된 시퀀스 길이보다 더 긴 시퀀스에 대해 일반화하는 것은 매우 어렵습니다. 예를 들어, Llama-2의 경우 최대 4K 토큰까지 학습됩니다(Touvron et al., 2023b). 그 이유는 LLM이 사전 학습 중 주의(attention) 윈도우에 의해 제한되기 때문입니다. 윈도우 크기를 확장하려는 상당한 노력(Chen et al., 2023; kaiokendev, 2023; Peng et al., 2023)과 긴 입력을 처리하기 위한 학습 및 추론 효율성 개선(Chen et al., 2023; Dao, 2023; Pope et al., 2022; Xiao et al., 2023; Anagnostidis et al., 2023; Wang et al., 2021; Zhang et al., 2023b)에 대한 노력이 있었음에도 불구하고, 허용 가능한 시퀀스 길이는 여전히 본질적으로 유한하며 이는 지속적인 배포를 허용하지 않습니다.
이 논문에서 우리는 먼저 LLM 스트리밍 애플리케이션의 개념을 소개하고 다음과 같은 질문을 제기합니다:
LLM을 효율성과 성능을 희생하지 않고 무한한 길이의 입력에 대해 배포할 수 있을까요?
LLM을 무한한 입력 스트림에 적용할 때 두 가지 주요한 문제가 발생합니다:
- 디코딩 단계에서 Transformer 기반 LLM은 이전 토큰의 키와 값(KV) 상태를 모두 캐시하며(Figure 1 (a) 참조), 이는 과도한 메모리 사용과 디코딩 지연을 초래할 수 있습니다(Pope et al., 2022).
- 기존 모델은 길이 추론 능력이 제한되어 있습니다. 즉, 시퀀스 길이가 사전 학습 시 설정된 주의 윈도우 크기를 초과하면 성능이 저하됩니다(Press et al., 2022; Chen et al., 2023).
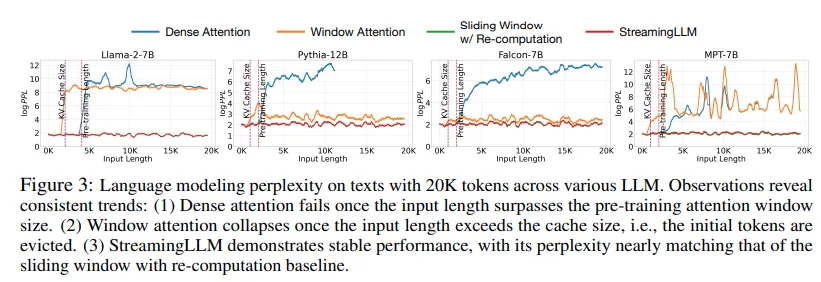
직관적인 접근 방식으로는 윈도우 주의(window attention)(Beltagy et al., 2020)(Figure 1 b)이 있으며, 최근 토큰의 KV 상태에 대해 고정 크기의 슬라이딩 윈도우를 유지합니다. 이는 캐시가 초기화된 후에는 일정한 메모리 사용과 디코딩 속도를 보장하지만, 시퀀스 길이가 캐시 크기를 초과하면 모델이 붕괴됩니다(Figure 3 참조). 또 다른 전략은 슬라이딩 윈도우 재계산(Figure 1 c 참조)으로, 각 생성된 토큰에 대해 최근 토큰의 KV 상태를 다시 구성합니다. 이 방식은 강력한 성능을 제공하지만, 윈도우 내에서의 이차 주의 계산으로 인해 매우 느리게 작동하므로 실제 스트리밍 애플리케이션에서 사용하기에 비실용적입니다.
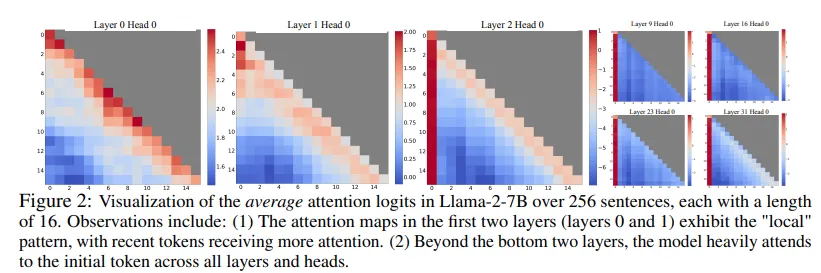
윈도우 주의의 실패를 이해하기 위해 우리는 자기회귀 LLM의 흥미로운 현상을 발견했습니다: 놀랍게도 많은 주의 점수가 초기 토큰에 할당되며, 이는 언어 모델링 작업과의 관련성에 관계없이 나타납니다(Figure 2 참조). 우리는 이러한 토큰을 "주의 싱크(attention sinks)"라고 부르며, 비록 의미적인 중요성이 없지만 상당한 주의 점수를 얻습니다. 그 이유는 Softmax 연산에 기인하며, 이 연산은 모든 컨텍스트 토큰에 대해 주의 점수가 합산되어 1이 되도록 요구합니다. 따라서 현재 쿼리가 이전 많은 토큰에 대한 강한 매치가 없더라도, 모델은 이러한 불필요한 주의 값을 어느 곳에든 할당하여 합산이 1이 되도록 해야 합니다. 초기 토큰이 싱크 토큰이 되는 이유는 직관적으로 이해할 수 있습니다: 초기 토큰은 자기회귀 언어 모델링 특성으로 인해 거의 모든 이후 토큰에 대해 보이기 때문에 주의 싱크로 더 쉽게 훈련됩니다.
이러한 통찰을 기반으로 우리는 StreamingLLM을 제안합니다. 이는 주의 윈도우를 사용하여 훈련된 LLM이 효율성과 성능을 유지하면서 무한한 길이의 텍스트에서 동작할 수 있도록 하는 간단하고 효율적인 프레임워크입니다. StreamingLLM은 주의 싱크가 높은 주의 값을 가지며 이를 유지하면 주의 점수 분포를 정상에 가깝게 유지할 수 있다는 사실을 활용합니다. 따라서 StreamingLLM은 주의 싱크 토큰의 KV(최소 4개의 초기 토큰만으로 충분함)와 슬라이딩 윈도우의 KV를 함께 유지하여 주의 계산을 앵커링하고 모델의 성능을 안정화합니다. StreamingLLM을 통해 Llama-2-[7, 13, 70]B, MPT-[7, 30]B, Falcon-[7, 40]B, Pythia-[2.9, 6.9, 12]B 등의 모델이 400만 토큰 이상을 안정적으로 모델링할 수 있으며, 더 많은 토큰을 처리할 가능성도 있습니다. 유일하게 가능한 베이스라인인 슬라이딩 윈도우 재계산과 비교하여, StreamingLLM은 최대 22.2배의 속도 향상을 달성하여 LLM의 스트리밍 사용을 실현합니다.
3 STREAMINGLLM
Window Attention 기법의 한계와 Attention Sink의 발견
윈도우 어텐션 기술은 추론 시 효율적이지만, 언어 모델링에서 매우 높은 perplexity를 유발합니다. 따라서 스트리밍 애플리케이션에서 사용할 경우 모델의 성능이 적합하지 않습니다. 이 섹션에서는 Attention Sink의 개념을 사용하여 윈도우 어텐션의 실패 원인을 설명하고, 이를 StreamingLLM의 영감으로 활용한 내용을 제시합니다.
Perplexity 급증 지점 식별
Figure 3은 20K 토큰 텍스트에 대한 언어 모델링의 perplexity를 보여줍니다. 텍스트 길이가 캐시 크기를 초과할 때 perplexity가 급증하는 것을 확인할 수 있는데, 이는 초기 토큰이 제외되기 때문입니다. 이는 초기 토큰이 예측 토큰과의 거리에 상관없이 LLM의 안정성을 유지하는 데 중요하다는 것을 나타냅니다.
왜 초기 토큰의 KV를 제거하면 LLM이 문제가 발생하는가?
Figure 2에서 Llama-2-7B 모델의 모든 층과 헤드에서 attention 맵을 시각화한 결과, 하위 두 층을 제외하고 모델이 모든 층과 헤드에서 초기 토큰에 지속적으로 집중하는 것을 발견했습니다. 이는 초기 토큰의 KV를 제거하면 SoftMax 연산에서 분모의 상당 부분이 제거되어 attention 점수 분포가 정상적인 추론 환경과 크게 달라진다는 것을 의미합니다.
SoftMax 함수의 설명
SoftMax 함수는 다음과 같이 표현됩니다:
초기 토큰의 중요성에 대한 두 가지 가능한 설명이 있습니다:
- 초기 토큰의 의미가 중요한 경우
- 모델이 절대 위치에 대한 편향을 학습한 경우
이 두 가지 가능성을 구분하기 위해 첫 4개의 토큰을 줄바꿈 토큰 “\n”으로 대체하는 실험을 수행했습니다. 그 결과 모델은 여전히 이 초기 줄바꿈 토큰에 상당한 주의를 기울였습니다. 또한, 이 토큰을 다시 도입하면 원래의 초기 토큰을 사용할 때와 유사한 수준의 언어 모델링 perplexity가 회복되었습니다. 이는 시작 토큰의 절대적 위치가 의미적 가치보다 더 중요하다는 것을 시사합니다.
LLMs의 Attention Sink 현상에 대한 설명
왜 LLM들은 Llama-2, MPT, Falcon, Pythia와 같은 모델들이 초기 토큰을 "attention sinks"로 삼는 것일까요? 그 이유는 자기회귀 언어 모델링의 순차적 특성 때문입니다. 초기 토큰은 모든 이후 토큰에게 보이는 반면, 이후 토큰들은 제한된 수의 후속 토큰에게만 보입니다. 따라서 초기 토큰은 불필요한 attention을 수용하는 데 더 쉽게 훈련될 수 있습니다.
Figure 2에서 4개의 초기 토큰을 attention sinks로 도입하면 LLM의 성능이 회복되는 것이 관찰되었으며, 단순히 1~2개의 토큰을 추가하는 것만으로는 완전한 회복이 이루어지지 않았습니다. 이는 모델이 사전 학습 중 모든 입력 샘플에 대해 일관된 시작 토큰을 포함하지 않았기 때문입니다. Llama-2의 경우 각 단락 앞에 "s" 토큰을 추가하지만, 이는 주로 임의의 토큰이 첫 번째 위치에 놓이게 되어 모델이 여러 초기 토큰을 attention sinks로 사용하게 됩니다. 우리는 모든 학습 샘플에 안정적인 학습 가능한 토큰을 도입하면 단일한 attention sink로 작용할 수 있다고 가정하고, 이를 3.3절에서 검증할 것입니다.
3.2 Attention Sink를 활용한 Rolling KV Cache
LLM 스트리밍을 이미 학습된 모델에 적용하기 위해 우리는 윈도우 어텐션의 perplexity를 복구할 수 있는 간단한 방법을 제안합니다. 이는 모델의 세부적인 fine-tuning 없이도 가능합니다. 현재의 슬라이딩 윈도우 토큰과 함께 몇 개의 초기 토큰의 KV를 attention 계산에 다시 도입하는 것입니다. StreamingLLM의 KV 캐시는 두 부분으로 나뉩니다:
- Attention sinks (4개의 초기 토큰): attention 계산을 안정화합니다.
- Rolling KV Cache: 언어 모델링에 중요한 최근 토큰을 유지합니다.
StreamingLLM의 설계는 유연하며 RoPE(Su et al., 2021)와 ALiBi(Press et al., 2022)와 같은 상대적 위치 인코딩을 사용하는 모든 자기회귀 언어 모델에 통합될 수 있습니다.
3.3 Attention Sink를 사용한 LLM의 사전 훈련
Vanilla attention과 zero token을 추가하는 방법, 그리고 학습 가능한 sink token을 사전 훈련 중에 도입하는 것의 비교를 수행했습니다. Table 3에 따르면, attention sink를 포함한 학습 방법이 스트리밍 perplexity를 안정화하는 데 가장 효과적이며, 모델 성능을 향상시킵니다. 이러한 결과를 바탕으로 우리는 미래의 LLM 학습에서 sink token을 모든 샘플에 도입할 것을 권장합니다.
4. 실험 및 결과
4.1 LLM 패밀리와 스케일에 따른 긴 텍스트 언어 모델링
우리는 최근에 주목받는 네 가지 모델 패밀리인 Llama-2 (Touvron et al., 2023b), MPT (Team, 2023), PyThia (Biderman et al., 2023), 그리고 Falcon (Almazrouei et al., 2023)을 사용하여 StreamingLLM을 평가했습니다. Llama-2, Falcon, 그리고 Pythia는 RoPE(Su et al., 2021)를 사용하고, MPT는 ALiBi (Press et al., 2022)를 사용합니다. 이는 최근 연구에서 가장 영향력 있는 두 가지 위치 인코딩 기술입니다. 이러한 다양한 모델을 선택함으로써 우리의 결과의 타당성과 강건성을 보장합니다. 우리는 StreamingLLM을 dense attention, window attention, 그리고 재계산이 포함된 슬라이딩 윈도우와 같은 기존의 베이스라인과 비교 평가했습니다. StreamingLLM과 관련된 모든 실험에서 별도로 명시되지 않는 한 기본적으로 4개의 초기 토큰을 attention sinks로 사용했습니다.
우선, PG19 테스트 세트(Rae et al., 2020)를 사용하여 StreamingLLM의 언어 모델링 perplexity를 평가했습니다. PG19 테스트 세트는 100권의 긴 책으로 구성되어 있습니다. Llama-2 모델의 캐시 크기는 2048로 설정되었고, Falcon, Pythia, 그리고 MPT 모델의 경우에는 1024로 설정되었습니다. 이는 시각화를 명확하게 하기 위해 사전 학습 윈도우 크기의 절반으로 설정되었습니다.
Figure 3은 StreamingLLM이 20K 토큰에 걸친 텍스트에서 perplexity 측면에서 Oracle 베이스라인(재계산이 포함된 슬라이딩 윈도우)과 일치할 수 있음을 보여줍니다. 한편, dense attention 기법은 입력 길이가 사전 학습 윈도우를 초과하면 실패하며, window attention 기법은 입력 길이가 캐시 크기를 초과하여 초기 토큰이 제거될 때 문제가 발생합니다. Figure 5는 StreamingLLM이 다양한 모델 패밀리와 스케일에서 4백만 개 이상의 토큰에 대한 텍스트를 안정적으로 처리할 수 있음을 보여줍니다.
4.2 Sink Token을 사용한 사전 훈련의 결과
모든 사전 훈련 샘플에 sink token을 도입하면 스트리밍 LLM의 성능이 향상된다는 우리의 제안을 검증하기 위해, 동일한 조건에서 1억 6천만 개의 파라미터를 가진 두 개의 언어 모델을 훈련했습니다. 하나의 모델은 기존 훈련 설정을 따랐고, 다른 모델은 모든 훈련 샘플의 시작에 sink token을 도입했습니다.
Figure 6은 sink token이 있는 모델과 없는 모델의 사전 훈련 손실 곡선을 보여주며, 두 모델 모두 유사한 수렴 동향을 나타냅니다. 또한 Table 4에서 볼 수 있듯이, sink token을 포함한 모델이 다양한 NLP 벤치마크에서 기존 모델과 유사한 성능을 보였습니다.
4.3 Instruction-Tuned 모델을 사용한 스트리밍 질의응답 실험 결과
StreamingLLM의 실제 활용 가능성을 보여주기 위해, 실제 시나리오에서 자주 사용되는 Instruction-Tuned LLM을 사용하여 다중 라운드의 질의응답을 시뮬레이션했습니다. ARC-[Challenge, Easy] 데이터셋의 모든 질문-답변 쌍을 연결하여 Llama-2-[7,13,70]B-Chat 모델에 연속적으로 입력하고, 각 답변 위치에서 모델의 완성도를 평가했습니다.
Table 5에서 볼 수 있듯이, dense attention은 메모리 부족 오류(OOM)로 인해 실패하여 이 설정에 적합하지 않았습니다. 반면에 window attention 방법은 효율적으로 작동했지만, 입력 길이가 캐시 크기를 초과하면 정확도가 떨어졌습니다. 반면에 StreamingLLM은 스트리밍 형식을 효율적으로 처리하여 one-shot, sample-by-sample 베이스라인과 일치하는 정확도를 달성했습니다.
4.4 Ablation Study
초기 토큰의 수: Table 2에서 초기 토큰 수를 다양하게 추가하여 스트리밍 perplexity에 미치는 영향을 분석했습니다. 결과적으로 단순히 1개 또는 2개의 초기 토큰을 도입하는 것은 불충분하다는 것이 드러났으며, 4개의 초기 토큰이 충분하며 그 이후로 추가적인 토큰은 미미한 효과만을 보여줬습니다.
캐시 크기: Table 6에서 StreamingLLM의 perplexity에 대한 캐시 크기의 영향을 평가했습니다. 캐시 크기를 늘린다고 해서 반드시 언어 모델링 perplexity가 감소하지는 않았으며, 이는 이러한 모델들이 전체 컨텍스트를 최대한 활용하지 못할 수 있음을 시사합니다.
4.5 효율성 결과
우리는 StreamingLLM의 디코딩 지연 시간과 메모리 사용량을 재계산이 포함된 슬라이딩 윈도우와 비교 평가했습니다. Figure 10은 캐시 크기가 증가함에 따라 StreamingLLM의 디코딩 속도가 선형적으로 증가하는 반면, 재계산이 포함된 슬라이딩 윈도우 베이스라인은 이차적으로 증가하는 것을 보여줍니다. 이로 인해 StreamingLLM은 토큰당 최대 22.2배의 속도 향상을 달성했습니다. 또한 StreamingLLM은 지연 시간이 감소함에도 불구하고 재계산 베이스라인과 유사한 메모리 사용량을 유지했습니다.
5. 결론
스트리밍 애플리케이션에서 LLM을 배포하는 것은 시급하지만, 효율성 제한과 긴 텍스트 처리 시 성능 저하 문제가 있습니다. 윈도우 어텐션은 부분적인 해결책을 제공하지만, 초기 토큰이 제외될 때 성능이 급격히 떨어집니다. 우리는 이러한 토큰들이 "attention sinks"로 작용한다는 점을 인식하고, 이를 해결하기 위해 StreamingLLM이라는 간단하고 효율적인 프레임워크를 도입했습니다. 이 프레임워크는 LLM이 무한한 텍스트를 처리할 수 있게 해주며, 추가적인 학습 없이 최대 4백만 개의 토큰을 효율적으로 모델링할 수 있습니다. 더욱이, 사전 훈련 단계에서 전용 sink token을 도입함으로써 스트리밍 성능을 향상시킬 수 있음을 보여주었습니다.
