https://arxiv.org/pdf/2401.01325
Abstract
대규모 언어 모델(LLMs)은 학습 시퀀스 길이보다 긴 컨텍스트를 일반화하는 데 어려움을 겪는다는 것이 잘 알려져 있습니다. 이는 추론 시 긴 입력 시퀀스를 처리하는 데 LLM을 사용하는 데 문제를 일으킵니다. 본 연구에서는 LLM이 미세 조정 없이도 긴 컨텍스트를 처리하는 내재적 역량을 지니고 있다고 주장합니다. 이를 위해 SelfExtend를 제안하여 LLM의 컨텍스트 윈도우를 확장하고, 그룹화된 주의력(grouped attention)과 인접한 주의력(neighbor attention)으로 이루어진 2단계 주의력 정보(bi-level attention information)를 생성합니다. 그룹화된 주의력은 멀리 떨어진 토큰들 간의 의존성을 포착하고, 인접한 주의력은 지정된 범위 내의 인접 토큰 간의 의존성을 포착합니다. 이 두 단계의 주의력은 추론 시 기존 모델의 자기 주의 메커니즘을 기반으로 계산됩니다. 코드 수정을 최소화하여 SelfExtend는 기존 LLM의 컨텍스트 윈도우를 미세 조정 없이 쉽게 확장할 수 있습니다. 여러 벤치마크에서 실험을 수행한 결과, SelfExtend는 LLM의 컨텍스트 윈도우 길이를 효과적으로 확장할 수 있음을 보여줍니다. 코드는 GitHub 링크에서 확인할 수 있습니다.
1. 도입
대부분의 기존 LLM(Zhao et al., 2023; Yang et al., 2023)의 컨텍스트 윈도우 길이는 고정된 길이의 학습 시퀀스로 훈련되기 때문에 제한적입니다. 이는 사전 학습 시 설정된 컨텍스트 윈도우 길이로 결정됩니다. 입력 텍스트의 길이가 추론 중에 사전 학습된 컨텍스트 윈도우를 초과하면 LLM의 동작은 예측할 수 없으며 성능이 크게 저하됩니다. 모델의 당혹도(perplexity, PPL)는 긴 입력 시퀀스로 인해 폭발적으로 증가합니다 (Xiao et al., 2023; Peng et al., 2023; Han et al., 2023; Chen et al., 2023b).
최근에는 사전 학습된 LLM의 컨텍스트 윈도우를 확장하는 다양한 방법이 개발되었습니다. 가장 간단한 접근법은 충분한 양의 긴 텍스트로 모델을 미세 조정하는 것입니다. 그러나 이러한 방법은 일반적으로 LLM이 긴 콘텐츠를 처리할 수 있는 능력이 부족하다는 암묵적인 가정에 기반하며, 이들을 확장하기 위해 미세 조정이 필요하다는 한계가 있습니다. 이는 자원 및 시간 소모가 많은 작업이며, 긴 텍스트 데이터의 부족으로 인해 미세 조정 접근법을 사용하는 데 어려움이 있습니다. 대부분의 현실 세계 데이터는 짧으며, 긴 텍스트는 종종 의미 있는 장기 의존성이 부족합니다.
이 논문에서는 LLM이 본질적으로 긴 컨텍스트를 처리할 수 있는 능력을 지니고 있다고 주장합니다. 우리의 주장은 인간이 어린 시절에 비교적 짧은 텍스트로 읽기와 쓰기를 배운다는 사실에서 비롯됩니다. 그러나 LLM이 긴 텍스트를 효과적으로 처리하지 못하는 이유는 위치적 O.O.D (Out-of-Distribution) 문제 때문입니다.
이를 해결하기 위해 우리는 SelfExtend를 제안하여 LLM의 본질적인 긴 컨텍스트 처리 능력을 이끌어냅니다. SelfExtend는 간단한 나눗셈 연산을 사용하여 보이지 않는 큰 상대적 위치를 사전 학습 중에 관찰된 위치로 매핑합니다. 이 방법은 추론 시에 LLM이 긴 컨텍스트를 자연스럽게 처리할 수 있도록 해줍니다.
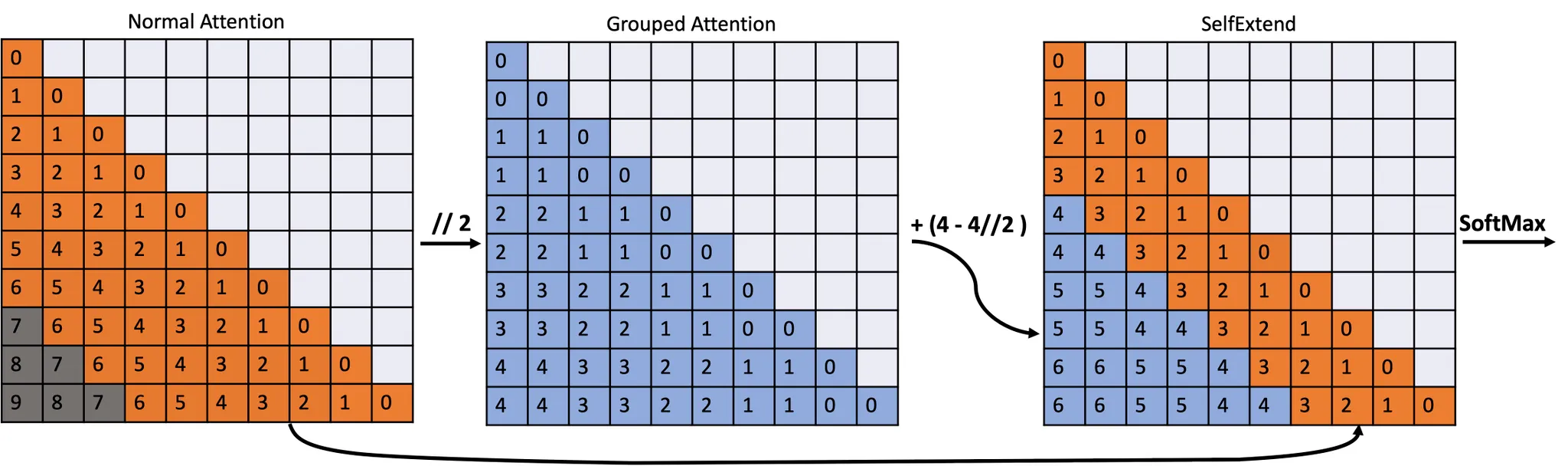
2. 기본 지식
- 위치 인코딩(Position Encoding): 트랜스포머 모델(Vaswani et al., 2017)은 위치 정보를 다양한 위치 임베딩 설계를 통해 통합합니다. 일반적으로 절대 위치 임베딩과 상대적 위치 인코딩으로 나눌 수 있습니다. 절대 위치 임베딩은 각 토큰의 절대 위치를 임베딩 벡터로 변환하고 단어 임베딩과 더해 모델에 전달합니다. 상대적 위치 인코딩은 토큰 간의 상대적 거리 정보를 사용하며 주의(attention) 층에 적용됩니다.
- RoPE(Rotary Position Embedding): RoPE는 쿼리 벡터(q)와 키 벡터(k)에 위치 정보를 통합하는 방식으로, 이들의 내적이 상대적 위치 정보를 포함하도록 합니다.
3. SelfExtend
SelfExtend는 LLM의 본질적인 긴 컨텍스트 처리 능력을 확장하기 위해 고안되었습니다. 기존 모델의 자기 주의 메커니즘을 활용하며, LLM의 추론 과정에서 긴 컨텍스트를 처리할 수 있도록 설계되었습니다. SelfExtend는 두 가지 유형의 주의력 메커니즘을 도입합니다:
- 그룹화된 주의력(Grouped Attention): 멀리 떨어진 토큰들 간의 관계를 관리합니다.
- 인접한 주의력(Neighbor Attention): 가까운 범위 내의 토큰들 간의 관계를 관리합니다.
주요 기여
- 자연적인 긴 텍스트 처리 능력: 우리는 RoPE를 사용하는 LLM이 본질적으로 긴 텍스트를 처리할 수 있다고 주장합니다.
- SelfExtend 제안: 추론 시에 사용되지 않았던 상대적 위치를 학습된 위치로 매핑하는 SelfExtend를 제안합니다.
- 효과적인 성능: 다양한 실험에서 SelfExtend는 미세 조정 기반의 기존 모델들보다 우수하거나 동등한 성능을 보였습니다.
3.1 사전 분석 (Preliminary Analysis)
① 왜 LLM은 사전 학습된 컨텍스트 윈도우보다 긴 시퀀스에서 실패하는가?
상대적 위치 인코딩(RoPE)을 사용하는 사전 학습된 LLM의 경우, 시퀀스의 길이가 사전 학습된 컨텍스트 윈도우 길이보다 길어지면 LLM의 동작은 예측할 수 없게 됩니다. (Han et al., 2023; Chen et al., 2023b)의 연구에서 확인된 바와 같이, 새로운 상대적 위치를 마주치게 되면 주의력 분포는 사전 학습된 컨텍스트 윈도우 내부의 주의력 분포와 달라집니다. 우리는 이러한 실패의 원인이 상대적 거리에 관한 Out-of-Distribution (O.O.D.) 문제 때문이라고 주장하며, 이는 신경망이 O.O.D. 입력에 취약하다는 특성과 관련이 있습니다 (Shen et al., 2021).
② 위치적 O.O.D. 문제를 어떻게 해결할 수 있을까?
보이지 않는 상대적 위치를 사전 학습 시 본 위치로 매핑하는 것이 한 가지 간단하고 실현 가능한 방법입니다. 우리는 FLOOR(내림) 연산을 사용하여 보이지 않는 위치를 사전 학습된 컨텍스트 윈도우 내의 위치로 매핑합니다.
FLOOR 연산은 각 토큰의 원래 위치에 적용되며, 이로 인해 새로운 상대적 위치가 모두 사전 학습된 컨텍스트 윈도우 범위 내에 들어가게 됩니다. 이를 통해 모델이 미리 학습된 범위 내에서만 상대적 위치를 인식할 수 있도록 합니다.
③ 정확한 위치 정보 없이도 LLM이 작동할 수 있을까?
그렇지만 완벽하지는 않습니다. 우리는 PG-19 데이터셋에서 Llama-2-7b-chat에 FLOOR 연산을 적용하여 PPL(Perplexity)을 측정한 결과를 Figure 2에서 보여줍니다. 이 결과에서 LLM은 FLOOR 연산을 통해 사전 학습된 컨텍스트 윈도우보다 긴 시퀀스에서도 비교적 낮고 안정적인 PPL을 유지합니다. 이는 그룹화된 주의력이 효과적임을 보여줍니다.
④ 그룹화된 주의력으로 인한 성능 저하를 어떻게 복원할 수 있을까?
인접 영역에서 일반적인 주의력을 다시 도입해야 합니다. 인접 토큰은 다음 토큰을 생성하는 데 매우 중요하므로, 표준 주의력 메커니즘을 해당 토큰들에게 유지하는 것이 필요합니다. 이러한 인접 영역의 주의력은 언어 모델이 로컬 컨텍스트의 세부사항을 정확하게 파악하는 데 필수적입니다.
3.2 SelfExtend LLM 컨텍스트 윈도우 확장 방법 (SelfExtend LLM Context Window Without Tuning)
SelfExtend는 사전 학습된 모델을 미세 조정 없이 LLM의 자연스러운 긴 컨텍스트 처리 능력을 향상시킵니다. 두 가지 유형의 주의력을 활용합니다:
- 그룹화된 주의력: 멀리 떨어진 토큰들 간의 관계를 처리하며, 위치를 FLOOR 연산을 통해 관리합니다.
- 표준 주의력: 지정된 범위 내 인접 토큰들 간의 관계를 처리합니다.
SelfExtend는 기존 모델의 추론 단계에서 주의력 메커니즘을 변경하기 때문에 별도의 미세 조정이 필요하지 않습니다.
SelfExtend의 최대 확장 가능한 길이:
예를 들어, 사전 학습된 컨텍스트 윈도우 크기가 , 그룹 크기가 (G_s), 이웃 토큰의 창 크기가 일 때, SelfExtend를 사용하면 컨텍스트 윈도우의 최대 확장 길이는 다음과 같이 계산됩니다:
이 연산을 통해 LLM은 사전 학습된 컨텍스트 윈도우 길이를 넘어선 입력 시퀀스에 대해서도 효과적으로 대응할 수 있습니다.
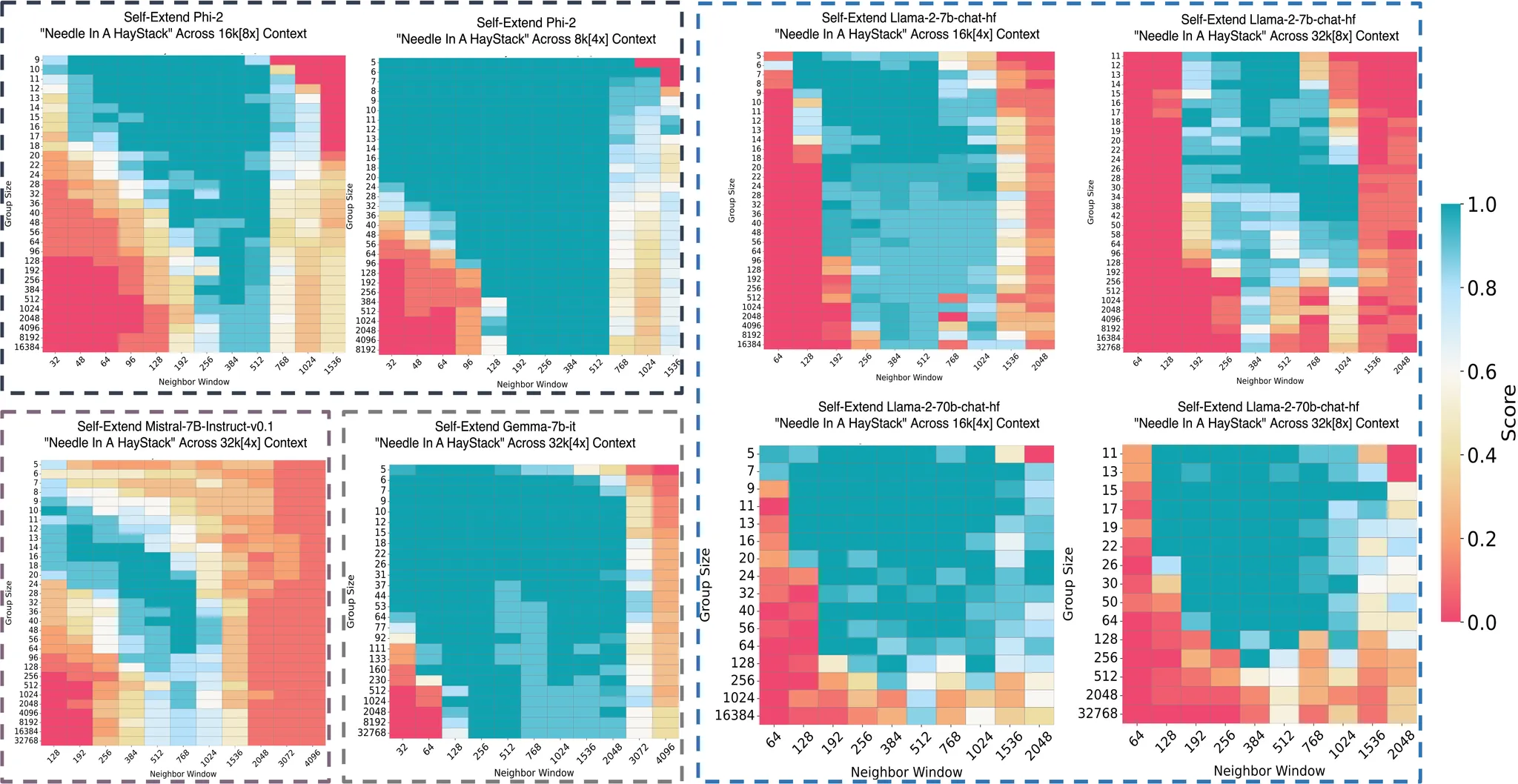
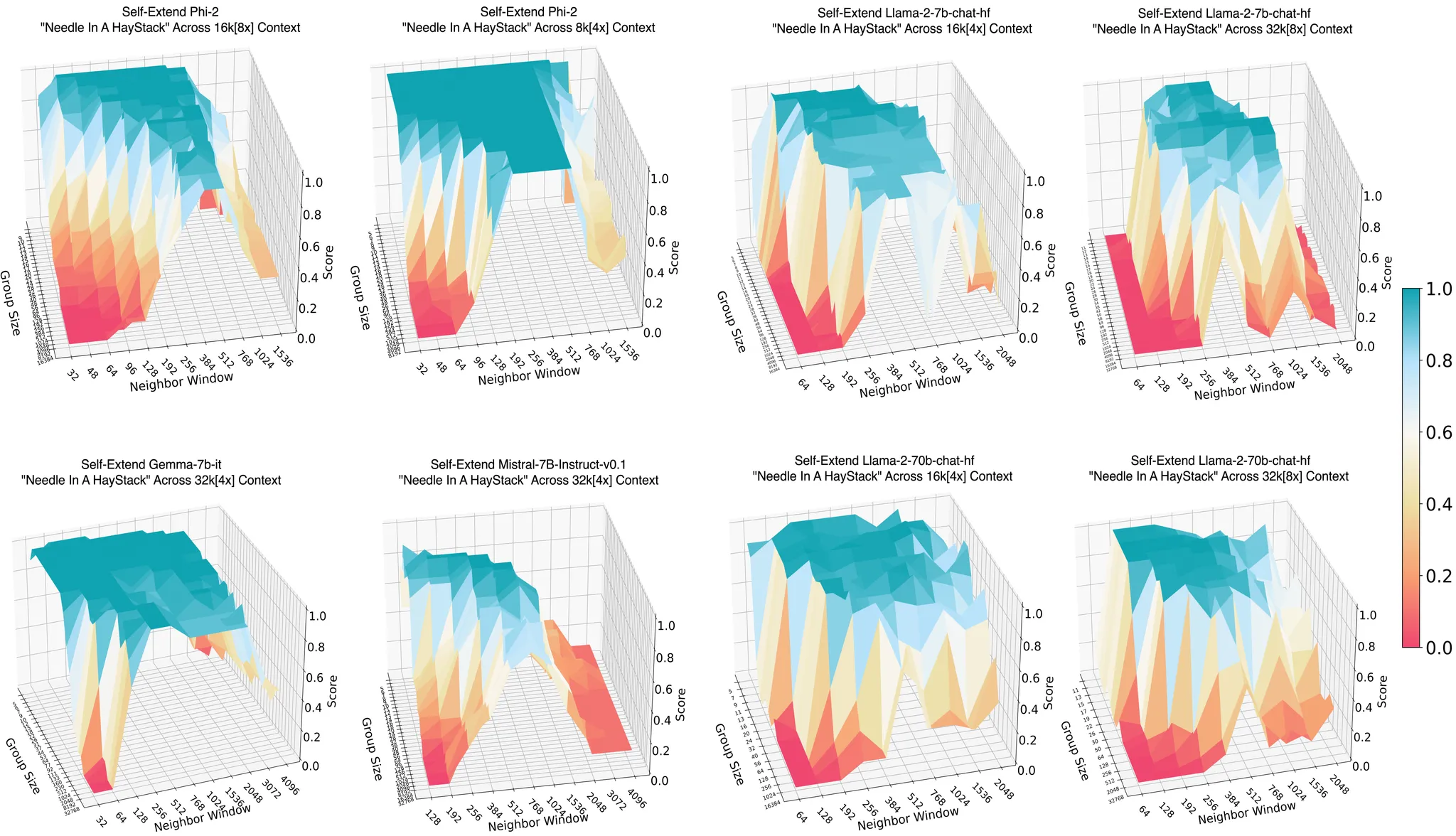
4. 실험 (Experiments)
4.1 언어 모델링 작업에서의 성능 (Performance on Language Modeling Tasks)
우리는 Llama-2, Mistral 등의 모델에 SelfExtend를 적용하여 PG19 데이터셋에서 언어 모델링 성능을 평가했습니다. PPL(Perplexity)을 측정한 결과, SelfExtend는 사전 학습된 컨텍스트 윈도우를 넘어선 테스트 시퀀스에서도 낮은 PPL을 유지하여 모델의 성능 저하를 방지했습니다.
4.2 Synthetic Long Context Task에서의 성능 (Performance on Synthetic Long Context Tasks)
우리는 합성된 긴 컨텍스트 작업인 패스키 검색 작업(Passkey Retrieval Task)을 통해 SelfExtend의 성능을 평가했습니다. 이는 긴 무의미한 텍스트 시퀀스 내에서 간단한 패스키(예: 5자리의 랜덤 숫자)를 검색하는 작업입니다. 실험 결과, SelfExtend는 모든 테스트된 길이와 깊이에서 100% 정확도의 패스키 검색 정확도를 달성했습니다.
4.3 실제 환경에서의 긴 컨텍스트 작업 성능 (Performance on Real-World Long Context Tasks)
실제 환경에서 긴 컨텍스트 작업을 평가하기 위해 LongBench 및 L-Eval이라는 두 개의 벤치마크를 사용했습니다. 모든 벤치마크 및 데이터셋에서 SelfExtend는 긴 컨텍스트를 요구하는 작업에서 다른 모델들을 능가하는 성능을 보였습니다.
4.4 짧은 컨텍스트 작업에서의 성능 (Performance on Short Context Tasks)
우리는 Hugging Face Open LLM 리더보드의 짧은 컨텍스트 작업을 통해 SelfExtend가 짧은 컨텍스트에서도 성능을 유지할 수 있는지 평가했습니다. SelfExtend는 긴 컨텍스트 작업뿐만 아니라 짧은 컨텍스트 작업에서도 기존의 성능을 유지하는 것으로 나타났습니다.
4.5 그룹 크기와 이웃 윈도우 크기에 대한 Ablation Study
우리는 그룹 크기와 이웃 윈도우 크기가 SelfExtend의 성능에 미치는 영향을 실험했습니다. 그룹 크기가 너무 작거나 너무 클 경우 성능이 떨어질 수 있다는 것을 확인했습니다. 이 결과는 SelfExtend의 성능 최적화에 있어 그룹 크기와 이웃 윈도우 크기를 적절히 설정하는 것이 중요하다는 것을 보여줍니다.
5. 결론 및 논의 (Conclusion and Discussion)
이 논문에서는 LLM이 긴 시퀀스를 처리할 수 있는 내재적 능력을 지니고 있다고 주장하며, 이를 이끌어내기 위해 SelfExtend를 제안했습니다. 이 방법은 미세 조정 없이도 LLM의 긴 컨텍스트 처리 능력을 효과적으로 향상시킬 수 있습니다.
한계점:
SelfExtend는 단순 구현에서는 모든 쿼리-키 쌍에 대한 추가적인 주의력을 수행하기 때문에 계산 비용이 증가할 수 있습니다. 그러나 Flash Attention과 같은 최적화 기술을 활용하면 이 비용은 선형으로 감소시킬 수 있습니다.
미래 연구 방향:
단순한 FLOOR 연산을 대체할 수 있는 더 정교한 매핑 방법을 연구할 계획이며, 이를 통해 LLM의 긴 컨텍스트 이해 및 확장 능력을 향상시키고자 합니다.
