long context
1.RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval
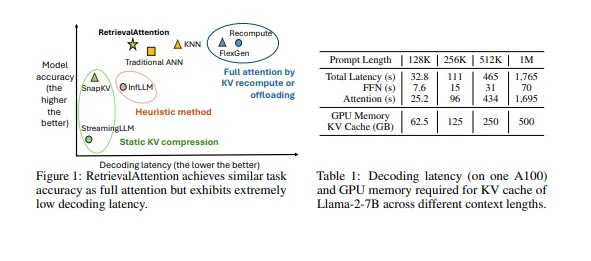
이 논문은 RetrievalAttention이라는 방법을 제안하여, 긴 컨텍스트를 처리하는 대형 언어 모델(LLM)의 추론 효율성을 높이기 위한 새로운 접근 방식을 설명합니다. 이에 대한 정리 및 번역
2024년 11월 27일
2.Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
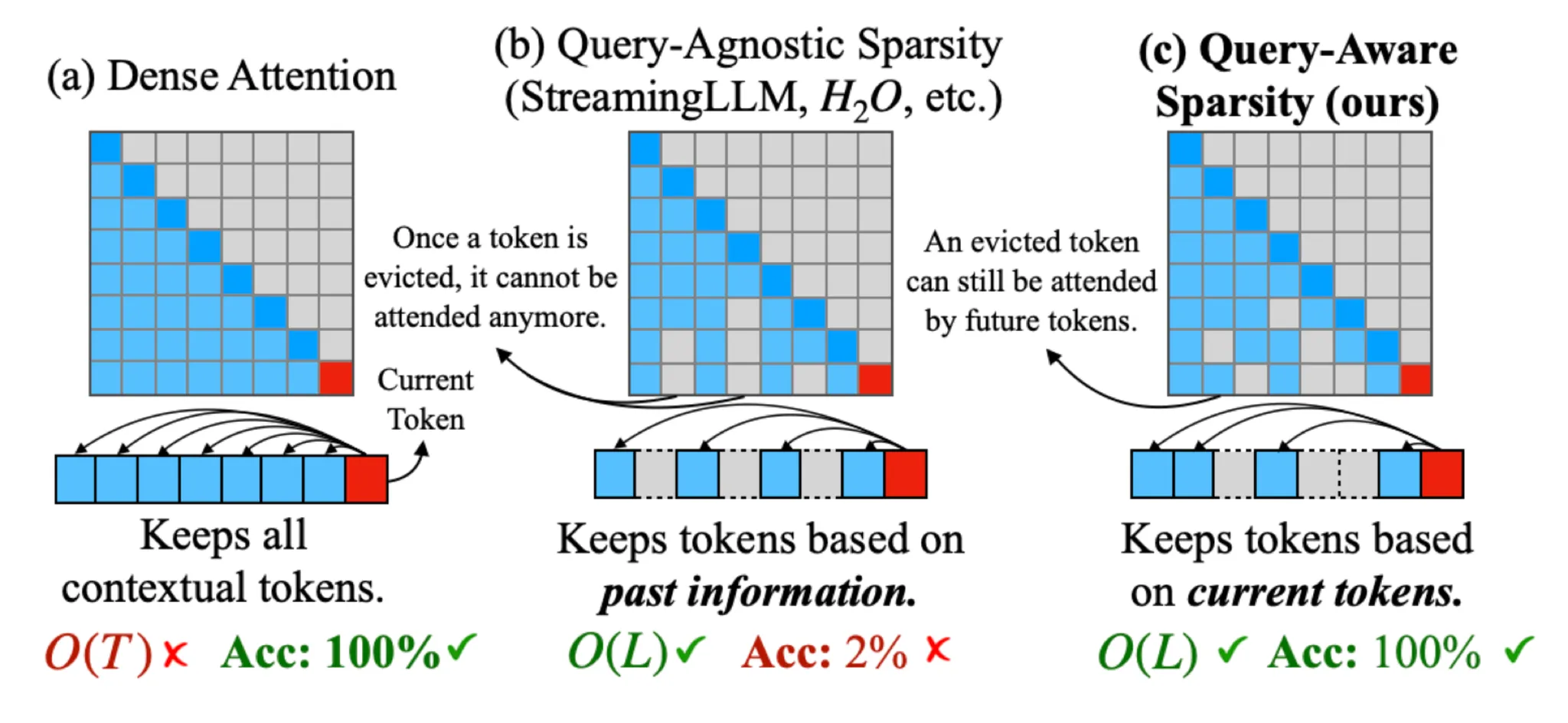
쿼리 인식형 KV 캐시 선택 알고리즘인 Quest를 제안합니다. Quest는 KV 캐시 페이지에서 최소 및 최대 Key 값을 추적하고, Query 벡터를 사용하여 주어진 페이지의 중요도를 추정합니다.
2024년 11월 28일
3.LLM Maybe LongLM: SelfExtend LLM Context Window Without Tuning
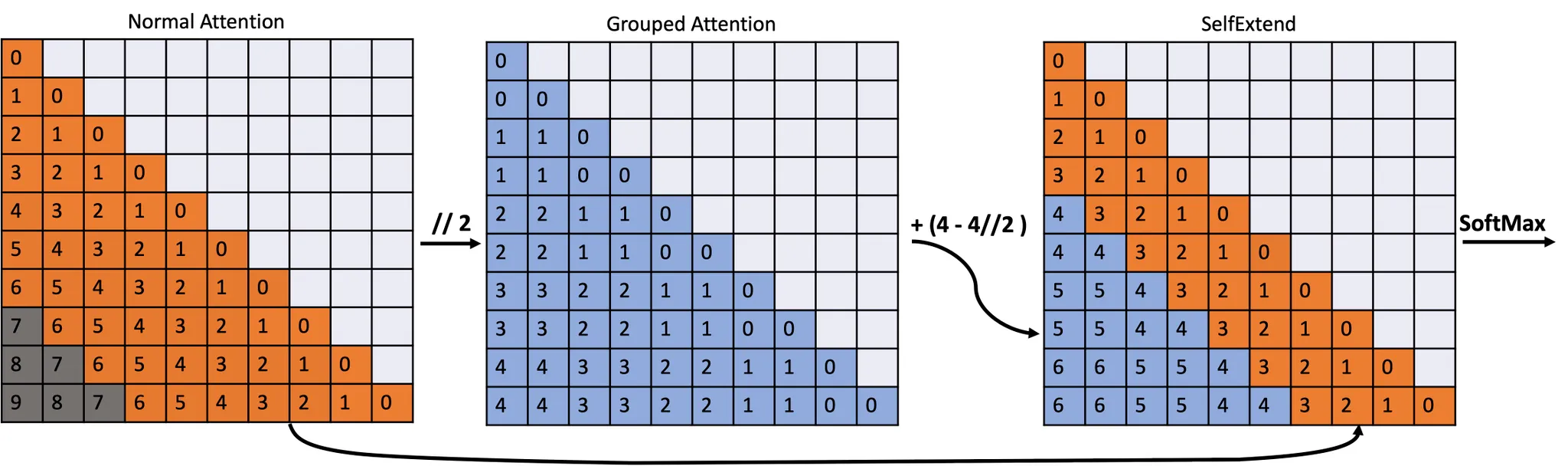
SelfExtend를 제안하여 LLM의 컨텍스트 윈도우를 확장하고, 그룹화된 주의력(grouped attention)과 인접한 주의력(neighbor attention)으로 이루어진 2단계 주의력 정보(bi-level attention information)를 생성
2024년 11월 28일
4.EFFICIENT STREAMING LANGUAGE MODELS WITH ATTENTION SINKS
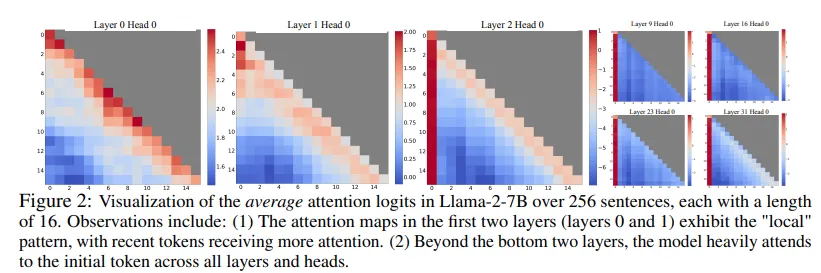
StreamingLLM을 제안합니다. StreamingLLM은 주의 싱크가 높은 주의 값을 가지며 이를 유지하면 주의 점수 분포를 정상에 가깝게 유지할 수 있다는 사실을 활용합니다.
2024년 11월 28일
5.Inference Scaling for Long-Context Retrieval-Augmented Generation

이 논문은 긴 컨텍스트(long-context)를 다루는 Retrieval-Augmented Generation (RAG) 시스템에서 추론(inference)의 확장 문제를 해결하는 방법을 제시합니다.
2026년 1월 9일
6.Chain of Agents: Large Language Models Collaborating on Long-Context Tasks
긴 문맥(long-context) 처리 문제를 해결하기 위해 다중 에이전트 협업 프레임워크인 Chain-of-Agents (CoA) 를 제안한 논문입니다.
2026년 1월 9일