https://aclanthology.org/2025.emnlp-main.331.pdf
1. 서론 정리
1.1 문제 배경: LLM의 “불가능한 삼각형”
- LLM(ChatGPT, LLaMA 계열 등)은 수십억~수조 파라미터를 쓰면서 굉장히 좋은 성능을 내지만, ① 높은 계산 비용, ② 큰 지연(latency) 때문에 실제 서비스에는 부담이 큼.
Firewall Routing Blocking Leads…
- 특히:
- 온프레미스 → 여러 장의 고메모리 GPU 필요
- 클라우드 API → 더 강한 모델일수록 토큰 당 비용이 비쌈Firewall Routing Blocking Leads…
- 그래서 논문은 성능 / 효율 / 비용이 동시에 만족되기 어려운 상태를 “불가능한 삼각형(impossible triangle)”이라고 부르면서, 이걸 깨기 위한 전략으로 Hybrid Inference를 본격적으로 논의함.
Firewall Routing Blocking Leads…
핵심 아이디어:
“모든 쿼리에 ‘항상 70B’를 쓸 필요는 없고, 쉬운 쿼리는 1B~, 어려운 쿼리만 70B로 보내면 되지 않나?”
1.2 Hybrid Inference: Cascade vs Route
Hybrid Inference = 쿼리마다 적당한 모델을 선택해서 쓰는 전략. 크게 두 부류로 정리함.
Firewall Routing Blocking Leads…
- Cascade 방식
- 흐름:
-
약한 모델(weak)을 먼저 호출해 답을 생성
-
모델 자체의 confidence(확률 등)를 보고,
“불확실하면” 강한 모델(strong)으로 escalate
-
- 예: FrugalGPT, Gupta et al., Margin Sampling 등Firewall Routing Blocking Leads…
- 한계:
- 생성이 끝나기 전에 품질을 판단하는 게 어렵다 → 잘못 escalate/차단할 수 있음Firewall Routing Blocking Leads…
- 어쨌든 먼저 weak이 “full generation”을 해야 해서, 지연이 크게 늘어난다.Firewall Routing Blocking Leads…
- 흐름:
- Route 방식 (Routing)
- 가벼운 router 모델이 쿼리를 보고 처음부터 어느 모델로 보낼지 결정.Firewall Routing Blocking Leads…
- 방법:
- OOD 탐지, 정답 가능성 예측, preference pair 기반 라벨링 등.Firewall Routing Blocking Leads…
- RouteLLM, Hybrid LLM 등은 Arena preference / BARTScore 비교 등을 사용해 라벨 분포를 구성.Firewall Routing Blocking Leads…
- 한계:
- 도메인 특화 preference 데이터에 강하게 의존하거나, LLM이 스스로 매긴 점수로부터 인위적으로 라벨을 만드는 경우가 많음.
Firewall Routing Blocking Leads…
- 특히 dual-model(weak vs strong) 상황에서, strong이 항상 weak보다 좋다고 가정하고 라우팅을 설계하는 경우가 많아서 둘 다 못 푸는 “long-tail query” 처리는 거의 신경 못 씀.
Firewall Routing Blocking Leads…
- 도메인 특화 preference 데이터에 강하게 의존하거나, LLM이 스스로 매긴 점수로부터 인위적으로 라벨을 만드는 경우가 많음.
1.3 이 논문이 보는 핵심 문제
- Hard label 기반 라우팅의 한계
- 기존 dual-model 라우터들은
- “weak가 strong만큼 잘하면 weak 라벨 1, 아니면 0” 같은 hard 라벨로만 학습.Firewall Routing Blocking Leads…
- 하지만 LLM은 sampling에 따라 답이 바뀌는 확률적 모델이라,
- 한 번 sampling 해서 맞았다고 해서 “무조건 잘 푼다”고 보기 어렵고
- 반대로 한 번 틀렸다고 “무조건 못 푼다”고 보기에도 애매함.Firewall Routing Blocking Leads…
- → Hard label만으로는 fine-grained한 차이를 잘 못 반영.
- 기존 dual-model 라우터들은
- Long-tail query 문제
- strong/weak 둘 다 여러 번 샘플링해도 못 푸는 극도로 어려운 쿼리들이 있음.Firewall Routing Blocking Leads…
- 이런 쿼리를 strong에게 보내봐야 돈/시간만 쓰고, 실제 성능 향상은 거의 없음.
- 기존 라우팅/하이브리드 기법은 이 long-tail을 자동으로 걸러내는 메커니즘이 거의 없음.
- 비용-성능 측정 지표의 문제
- RouteLLM에서 제안한 CPT(Call-Performance Threshold)는
- “아래 n%의 성능 격차”를 메우는 게 훨씬 쉬워서 지표가 부풀려질 수 있다고 지적.Firewall Routing Blocking Leads…
- 이 논문은 상대적으로 더 직관적인 APGR (Average Performance Gap Recovered)를 주요 지표로 사용.
- RouteLLM에서 제안한 CPT(Call-Performance Threshold)는
1.4 이 논문의 기여
논문은 크게 세 가지 기여를 주장함.
Firewall Routing Blocking Leads…
- Soft label 기반 라우터 학습 패러다임
- 여러 번 sampling한 결과를 활용해, weak가 strong만큼 좋을 “승률(Win Rate)”을 soft label로 계산하는 통합적 수식 제안.
- 이 수식 안에서 기존 hard label 학습은 특수한 경우(한 번만 샘플링한 경우)로 포함됨을 수학적으로 보여줌.Firewall Routing Blocking Leads…
- 여러 번 sampling한 결과를 활용해, weak가 strong만큼 좋을 “승률(Win Rate)”을 soft label로 계산하는 통합적 수식 제안.
- Hard Blocking / Soft Blocking으로 long-tail query 처리
- Pass Rate(pass@1)를 이용해서
- weak가 strong보다 잘하는 long-tail을 자동으로 찾아내고
- 아예 weak로 보내거나, soft label을 조정해서 strong 호출을 억제.
- Pass Rate(pass@1)를 이용해서
- 광범위한 실험으로 SOTA 성능 입증
- TriviaQA, GSM8K, HumanEval 등 여러 벤치마크에서 기존 RouteLLM, HybridLLM, Margin Sampling 등 대비 APGR 최대 +5.29% 향상을 보임.
- TriviaQA, GSM8K, HumanEval 등 여러 벤치마크에서 기존 RouteLLM, HybridLLM, Margin Sampling 등 대비 APGR 최대 +5.29% 향상을 보임.
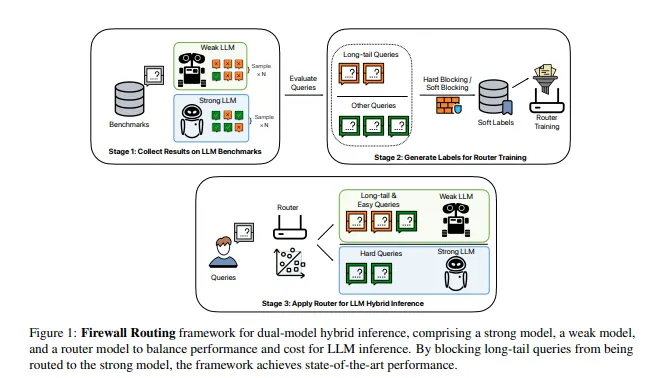
1. 전체 프레임워크 개요
Firewall Routing은 “강한 LLM + 약한 LLM + 라우터”로 구성된 dual-model hybrid inference 구조입니다.
- Strong LLM: 성능 좋지만 비싸고 느린 모델 (예: Llama3.1-70B)
- Weak LLM: 싸고 빠르지만 성능이 약간 떨어지는 모델 (예: Llama3.2-1B)
- Router: 쿼리의 난이도를 보고, 이 쿼리를 weak에 줄지, strong에 줄지 결정하는 작은 분류기 (여기서는 DeBERTa-v3-large)
프레임워크는 3단계로 진행됩니다:
- Stage 1: 벤치마크에서 결과 수집
- TriviaQA, GSM8K, HumanEval 등 벤치마크에 대해
- 강한 모델, 약한 모델 각각에 대해 n번 샘플링 (예: 32샘플) 을 돌려서 정답 여부를 저장.
- 여기서 얻는 건 각 쿼리 (x_i) 에 대해
- strong/weak의 pass rate (정답 확률)
- weak가 strong을 이기는 win rate 정보.
- TriviaQA, GSM8K, HumanEval 등 벤치마크에 대해
- Stage 2: 라우터 학습용 라벨 생성
- 위의 pass rate / win rate를 바탕으로
- 기본 Hard Label
- Soft Label (Win Rate 기반)
- Long-tail query를 다루는 Hard Blocking / Soft Blocking
- 을 사용해 연속값(soft label) 형태의 라벨을 만들고, 이를 binary classification 라우터 학습에 사용.
- 위의 pass rate / win rate를 바탕으로
- Stage 3: 실제 하이브리드 추론에서 사용
- 실제 inference에서는 라우터가 쿼리 (x)를 보고
- () (weak로 보낼 확률)를 출력
- 특정 threshold(또는 routing ratio)를 기준으로
- 약한 LLM 또는 강한 LLM 중 하나로 라우팅.
- 실제 inference에서는 라우터가 쿼리 (x)를 보고
핵심은:
(1) Win Rate / Pass Rate를 이용한 이론적인 soft label 수식 정립,
(2) long-tail 쿼리를 과감히 “weak으로만 보내서 strong 호출을 막는(=firewall) Hard/Soft Blocking” 입니다.
2. 3.1 Router Training Criterions
2.1 3.1.1 Hard Label로 학습하기
먼저 기존 하이브리드 라우팅의 전형적인 hard label 설계를 정리합니다.
- 쿼리 집합 (Q) 에서 임의의 쿼리 (x_i \in Q) 를 생각.
- 강한 모델의 greedy 응답: (S(x_i))
- 약한 모델의 greedy 응답: (W(x_i))
- 평가 함수 (\delta(\cdot) \in {0,1}):
- 정답이면 (1), 오답이면 (0).
이때, 약한 모델이 강한 모델보다 나쁘지 않으면, 그 쿼리는 약한 모델로 보내도 된다, 라는 기준으로 이진 라벨을 정의합니다.
[
]
- () 이면
- 강한 모델이 맞았든 틀렸든, 약한 모델이 그 이상이므로
- () → 이 쿼리는 weak으로 보내도 된다.
- 반대로 strong이 weak보다 분명히 더 잘하면
- () → strong으로 라우팅해야 한다.
라우터는 확률 () 를 출력하는 binary classifier로 두고,
이를 “weak으로 보낼 확률”로 해석합니다.
이때 학습 로스는 binary cross-entropy:
[
]
- ()가 클수록 “weak으로 보내라”는 신호를 주는 것.
- Hard Label 방식의 한계:
- 한 번의 greedy 결과만 보고 판단 → LLM의 생성 변동성을 반영하지 못함.
- 약한 모델과 강한 모델이 비슷한 실력을 가진 구간에서는, “어느 쪽이 더 좋은지”가 샘플링에 따라 들쑥날쑥한데, hard label은 그 미묘함을 표현 못 함.
2.2 3.1.2 Soft Label로 학습하기 (Win Rate)
여기부터가 이 논문 방법론의 핵심입니다.
(1) Multiple sampling 세팅
단일 greedy가 아니라, 각 쿼리에 대해 여러 번 샘플링을 합니다.
- 한 쿼리 (x_i) 에 대해:
- strong의 샘플들: [ ]
- weak의 샘플들: [ ]
- strong의 샘플들: [ ]
- 각각 정답 여부: [ ]
- 매 샘플링 (j)에서, “weak이 strong보다 나쁘지 않으면 1”인 임시 라벨: [ ]
- 즉, 각 샘플링마다 hard label을 하나씩 얻는 셈.
이렇게 하면 쿼리 하나 (x_i)에 대해
[
]
이라는 n개의 (입력,라벨) 쌍을 만들 수 있습니다.
그런데 이걸 그대로 hard label BCE에 넣으면:
- 같은 (x_i)에 대해 (y_i^j) 값들이 제각각 나올 수 있어서 noisy.
- 데이터 수가 n배로 늘어나서 학습 비용이 커짐.
(2) Win Rate (r_i) 정의
그래서 논문은 이 다중 샘플링 결과를 요약한 soft label로 만드는 아이디어를 제안합니다.
[
]
- 의미: weak가 strong보다 “나쁘지 않은” 비율 (확률) → 쉽게 말해, 이 쿼리에서 weak의 win rate.
- (r_i = 1)이면 거의 항상 weak가 strong 이상, (r_i = 0)이면 항상 strong이 우세.
이제 여기서 중요한 관찰:
“사실, 여러 샘플 ()로 학습하는 hard-label BCE는,
결국 ()를 soft label로 쓰는 BCE와 동일한 형태로 쓸 수 있다.”
(3) Hard-label BCE를 Win Rate 기반 BCE로 재표현
원래 multiple sampling을 그대로 반영한 BCE는:
[
]
이를 전개하면, 쿼리 (x_i) 별로 정리해서
[
]
이 됩니다. (논문에서 실제로 이 식을 유도해서 보여줌)
요약하면:
- 여러 샘플에 대한 hard-label BCE = “soft label = win rate ()” 를 쓴 BCE와 동치.
- 기존 Hard Label 방식(0/1라벨)은 ()인 특수한 경우로 들어갑니다.
즉, 이 논문은
“라우터 학습을 Win Rate 기반 soft label BCE의 일반적 프레임으로 바라볼 수 있고,
기존 Hard Label은 그 안의 특수 케이스다.”
라는 이론적 관점을 정리한 뒤,
이 (r_i) 자리에 더 잘 설계된 soft label (특히 long-tail 대응)을 넣는 것이 핵심이라고 주장합니다.
3. 3.2 Blocking Long-tail Queries
여기서는 “강한 모델도 잘 못 푸는 진짜 어려운(long-tail) 쿼리”를 어떻게 다룰 것인지가 핵심입니다.
직관:
- 어떤 쿼리는 strong을 여러 번 샘플해도 계속 틀림.
- 그런 쿼리를 strong에 계속 보내는 것은
- 비용만 많이 들고
- 성능 개선도 없음.
- 차라리 애초에 그런 쿼리는 weak으로만 보내고 strong 호출을 막자 → Firewall(차단)
이를 위해 Pass Rate와 Hard / Soft Blocking을 정의합니다.
3.1 Pass Rate 정의
한 쿼리 (x_i)에 대해, 임의의 모델 (R) (strong 또는 weak)를 n번 샘플링했다고 하자:
- (): 모델 R의 샘플
- 정답 여부: ()
이때 Pass Rate는
[
]
- (pr_w(x_i)): weak 모델의 pass rate
- (pr_s(x_i)): strong 모델의 pass rate
3.2.1 Hard Blocking
Hard Blocking의 아이디어는:
“long-tail 쿼리 = weak가 strong보다 낫거나 비슷해서, strong을 써도 의미 없는 쿼리”로 정의하고,
그런 쿼리는 무조건 weak으로 보내자 (soft label=1).
(1) Long-tail 쿼리 집합 정의
쿼리 집합 (Q)를 두 그룹으로 나눕니다:
- (Q_u): long-tail 쿼리
- (Q_s = Q - Q_u): 그 외 쿼리
조건은 다음과 같습니다:
- 즉, long-tail 쿼리란
- pass rate 수준에서 weak가 strong보다 더 좋거나 같은 쿼리.
- LLM 간 complementary behavior (약한 모델이 의외로 더 잘하는 문제들)와도 연결.
(2) Hard Blocking의 soft label 설계
위 분할을 기반으로, 라우터 학습용 soft label (label_i)를 다음과 같이 정의합니다:
- (x_i)가 일반 쿼리 ((Q_s))이면
- weak의 pass rate (pr_w(x_i)) 를 soft label로 사용.
- (x_i)가 long-tail ((Q_u))이면
- 무조건 weak으로 보내라고, soft label을 1로 고정.
이렇게 하면:
- long-tail 쿼리는 strong에 안 보내게 firewall 처리가 되고,
- 그 외 쿼리는 weak의 pass rate를 반영한 soft label로 more fine-grained 라우팅 학습.
(3) 비용 절감을 위한 변형 (Hard Blocking w/o Strong Model Sampling)
Pass Rate를 정확히 계산하려면, 원래 strong/weak에서 n번 샘플링이 필요해서 비용이 큽니다.
그래서 논문은 강한 모델에 대해서는 greedy 1샘플만 쓰는 변형도 제안합니다.
조건:
이 수식은 Hard Blocking의 비용 절감 변형 버전에서 사용되는 조건으로, strong 모델의 greedy 응답 결과만으로 long-tail 쿼리를 구분하는 방법을 나타냅니다.
- strong의 greedy 응답이 틀리면 long-tail ((Q_u))
- strong의 greedy 응답이 맞으면 일반 쿼리 ((Q_s))
이렇게 하면 strong에 대해 n번 샘플링을 하지 않아도 long-tail / non-long-tail을 나누는 저렴한 Hard Blocking variant를 만들 수 있고, 실험적으로 성능도 꽤 괜찮다고 보고합니다.
3.2.2 Soft Blocking
Soft Blocking은 Hard Blocking보다 좀 더 수식적으로 정교한 soft label 설계입니다.
핵심 아이디어:
- 앞에서 한 Win Rate (r_i)는
- “weak가 strong보다 나쁘지 않을 확률”이지만,
- 식 (2)에서 (r_i)는 단일 스칼라로 들어가 노이즈가 있을 수 있는 지표.
- Pass Rate (pr_w(x_i), pr_s(x_i))를 독립적인 사건의 확률로 보고,
- “strong이 weak보다 분명히 낫지 않은 사건”의 확률을 구해 soft label로 쓰자.
(1) 사건 정의
두 모델의 성능을 “독립 사건”처럼 다루면 다음 두 가지 조건을 고려할 수 있습니다:
- weak가 맞는 경우:
- 이 경우 이미 weak가 충분히 잘하므로, 굳이 strong을 쓸 필요 없음.
- 확률: (pr_w(x_i))
- weak가 틀렸지만, strong도 틀린 경우:
- 이런 쿼리는 “둘 다 못 푸는 long-tail”
- strong을 써도 이득이 없으므로 weak에 두는 것이 낫다.
- 확률: ((1 - pr_w(x_i)) \cdot (1 - pr_s(x_i)))
이 두 사건 중 하나라도 발생하면,
“strong이 weak를 명확히 압도하지 못하는 상황”이라고 볼 수 있어서
그 쿼리는 weak으로 보내는 쪽이 합리적입니다.
그래서 Soft Blocking의 soft label을 다음과 같이 정의:
- 첫 줄: “weak 맞음” + “weak도 틀리고 strong도 틀림”
- 둘째 줄: 위 식을 정리한 형태.
이 (label_i)는:
- “strong이 weak보다 분명히 낫지 않은 빈도”를 반영한 soft label
- long-tail 쿼리에도 잘 작동 (Figure 2에서 시각화)
(2) 최종 라우터 학습
최종적으로, 논문은 식 (2)의 Win Rate 기반 BCE에서 (r_i) 대신 이 (label_i)를 넣어 사용합니다:
여기서 (label_i)는
- Hard blocking일 때: 식 (5)
- Soft blocking일 때: 식 (7)
을 사용합니다.
4. 방법론 정리 (발표용 포인트)
발표나 정리할 때 강조하면 좋은 포인트를 bullet로 정리하면:
- 문제 설정
- Dual-model hybrid inference (weak + strong)에서
- 어떤 쿼리를 약한 모델, 어떤 쿼리를 강한 모델에 줄지 결정하는 라우터가 필요.
- 기존 Hard Label 방식은 greedy 단일 샘플, 0/1 라벨만으로 학습되어
- LLM의 샘플링 변동성, long-tail 쿼리 처리를 잘 반영하지 못함.
- Dual-model hybrid inference (weak + strong)에서
- Win Rate 관점의 Soft Label 일반화
- 쿼리마다 multiple sampling을 수행하고
- weak가 strong보다 나쁘지 않은 비율 (r_i) = win rate 정의.
- multiple hard label BCE를 전개하면,
- 결국 (r_i)를 soft label로 사용하는 BCE로 재표현 가능 (식 (2)).
- 따라서:
- “라우터 학습 = Win Rate 기반 soft label BCE”라는 통합 뷰.
- 기존 Hard Label은 (r_i \in {0,1})인 특수 케이스.
- 쿼리마다 multiple sampling을 수행하고
- Long-tail 쿼리 Firewall (Blocking)
- Hard Blocking
- Pass Rate를 이용해 weak가 strong보다 나쁘지 않은 쿼리를 long-tail로 정의.
- long-tail 쿼리에는 soft label=1 (무조건 weak로 보내기).
- 변형: strong은 greedy 1샘플만으로 long-tail 분리 (비용 절약).
- Soft Blocking
- Pass Rate (pr_w, pr_s)를 독립 사건으로 보고
- “weak이 맞거나, 둘 다 틀리는 경우”의 확률을 soft label로 정의 [ label_i = 1 - (1 - pr_w(x_i))pr_s(x_i) ]
- strong이 weak를 확실히 이기는 영역은 자연스럽게 label이 작아져 strong 라우팅.
- Hard Blocking
- 최종 라우터 학습
- DeBERTa-v3-large + linear head로 라우터 구성.
- Loss는 항상 BCE 형태:
- Hard Label, Win Rate, Hard Blocking, Soft Blocking 모두 “soft label만 다를 뿐, 같은 BCE 구조 안에서 비교 가능”.
- Hard Label, Win Rate, Hard Blocking, Soft Blocking 모두 “soft label만 다를 뿐, 같은 BCE 구조 안에서 비교 가능”.
3. 실험 설정
3.1 데이터셋
- TriviaQA: 상식 기반 QA.
- GSM8K: 수학(word problem) 추론.
- HumanEval: 코드 생성/정확도 평가.
세 데이터셋 모두 generative task로, pass rate(정답률)과 하이브리드 라우팅 성능을 측정.
3.2 모델 구성
- Weak LLM:
- 주 구성: LLaMA 3.2 1B
- Generalization 실험: LLaMA 3.2 3B
- Strong LLM:
- LLaMA 3.1 70B
- Router:
- 기본: DeBERTa-v3-large (~300M)
- 대조: LLaMA 3.2 1B를 router로 쓴 경우도 비교.
3.3 평가 지표
- Pass Rate: 각 라우팅 방식이 특정 routing ratio(예: strong 20%, 50%, 80%)에서 거둔 정답률.
- APGR (Average Performance Gap Recovered)
- 0%, 10%, …, 100% routing ratio에 대해, “weak-only 성능”과 “strong-only 성능” 사이의 gap 중에서, 라우팅으로 얼마나 복구했는지 평균.
- 0~100% 사이 값으로 나타나며 높을수록 좋음.
- 0%, 10%, …, 100% routing ratio에 대해, “weak-only 성능”과 “strong-only 성능” 사이의 gap 중에서, 라우팅으로 얼마나 복구했는지 평균.
4. 주요 결과 정리
4.1 기본 설정: 1B(weak) + 70B(strong) (Table 1)
- Table 1: LLaMA 3.2 1B (weak) + LLaMA 3.1 70B (strong)에서의 zero-shot hybrid 성능.
비교 대상:
- Linear Interpolation (Random routing 근사)
- Hybrid LLM
- RouteLLM (MF)
- Margin Sampling
- Ours (Hard Block, Soft Block)
결과 (APGR 기준):
- Firewall Routing(Hard/Soft Block)이
- TriviaQA: 기존 최고 대비 +3.72% APGR 향상
- GSM8K: +5.29% APGR 향상
- HumanEval: +2.42% APGR 향상.
- Pass Rate 측면에서도, 20%, 50%, 80% routing ratio 전반에 걸쳐 기존 라우팅보다 조금씩 높은 정확도를 달성.
해석 포인트:
- 단순히 APGR만 높은 게 아니라, “strong을 적게 쓰는 구간(20% 정도)부터 많이 쓰는 구간(80%)까지” 전체 곡선이 baseline보다 위에 있음 → 예산/지연 조건이 바뀌어도 튜닝 가능한 좋은 trade-off 곡선을 제공.
4.2 Generalization 실험: 3B(weak) + 70B(strong) (Table 2)
- 여기서는 라우터를 1B+70B 조합으로 학습해놓고, 그대로 3B+70B 조합에 적용 (재학습 없이).
결과:
- Soft Blocking 기반 Firewall 라우팅은
- TriviaQA: APGR +4.16%
- GSM8K: +4.88%
- HumanEval: +0.43% 만큼 기존 라우팅보다 개선.
해석:
- 다른 weak 모델(3B)로 바꿔도 라우터를 재학습할 필요 없이 그대로 잘 동작 → 라우터가 단순히 “모델 ID”에 overfit된 게 아니라, 쿼리 난이도/특성을 학습했다는 주장에 힘을 실어줌.
4.3 Ablation: Router 백본 및 Label 설계 (Table 3, 4)
4.3.1 Router 백본 비교 (Table 4)
- 비교: DeBERTa-v3-large vs LLaMA 3.2 1B (causal LLM router).
- 결과:
- DeBERTa-v3-large가 LLaMA 1B router보다 TriviaQA, GSM8K, HumanEval의 APGR에서 전반적으로 더 좋음.
- HumanEval에서 LLaMA 1B가 약간 나은 면도 있지만, 전체적으로 DeBERTa가 더 안정적.
- DeBERTa-v3-large가 LLaMA 1B router보다 TriviaQA, GSM8K, HumanEval의 APGR에서 전반적으로 더 좋음.
- 해석:
- router를 weak LLM보다 더 큰 LLM으로 쓸 필요가 없다는 주장 뒷받침.
- 비용/지연을 생각하면, 작은 encoder 기반 router(DeBERTa)가 성능/비용 양쪽에서 우수.
4.3.2 Label 설계 Ablation (Table 3)
- 라벨 전략들:
- weak pass rate만 사용 (label = pr_w)
- strong pass rate만 사용 (label = f(pr_s))
- hard label (단일 greedy decoding 정오)만 사용
- Hard Blocking / Soft Blocking (제안 방법)
- Hard Blocking without Strong Sampling (Eq.6 기반):
- strong은 한 번만 greedy로 돌린 값으로 long-tail 구분 → 샘플링 비용 감소.
- 결과:
- weak pass rate만 사용하는 경우: random routing보다 약간 나아지는 수준 → weak 혼자서는 라우팅 신호가 약함.
- strong pass rate만 사용하는 경우: 쿼리 난이도를 잘 반영해서 그보다는 향상.
- hard label (greedy) 추가: discrete supervision이 도움이 되어 추가 개선.
- Hard/Soft Blocking: 가장 높은 APGR과 좋은 pass rate 달성.
- Hard Blocking without Strong Sampling: full sampling을 하지 않고도 유사 성능 달성 → 라벨 생성 비용을 크게 줄이면서도 효과적.
- weak pass rate만 사용하는 경우: random routing보다 약간 나아지는 수준 → weak 혼자서는 라우팅 신호가 약함.
요약 포인트:
“Weak만 보고 라우팅하면 신호가 약하다. Strong의 pass rate, 그리고 weak/strong의 joint behavior를 soft label로 잘 설계할수록 라우팅 성능이 크게 오른다.”
4.4 Latency 및 비용 분석
논문 후반부에서 라우팅 비율에 따른 지연 시간과 speedup을 상세 분석함.
- 환경:
- Strong: LLaMA 3.1 70B
- Weak: LLaMA 3.2 1B 또는 3B
- Router: DeBERTa-v3-large
- 측정 결과:
- weak 1B:
- 0% strong 호출 → 약 0.90s
- 50% strong 호출 → 약 29.38s
- 100% strong-only → 약 57.85s
- speedup:
- 50% routing ratio에서 약 1.97× 속도 향상 (strong-only 대비).
- 20% routing ratio에서는 4.58×, 80%에서는 1.25× 등.
- weak 1B:
- 중요한 관찰:
- weak(1B/3B)와 router는 strong 70B에 비해 계산량이 매우 작아서,
- 전체 latency는 사실상 “strong 호출 비율의 선형 보간”에 가깝다.
- 즉, strong 호출 비율을 얼마나 줄이느냐가 곧 latency 절감 비율을 거의 결정.
- weak(1B/3B)와 router는 strong 70B에 비해 계산량이 매우 작아서,
5. 발표/정리용 한 줄 요약
- 문제의식
- LLM inference에서 성능-비용-지연 “불가능 삼각형” 극복을 위해, query마다 weak/strong을 고르는 hybrid inference가 중요.
- 기존 Cascade/Route 방식은
- Hard label 기반, 편향된 preference data, long-tail query 처리 미흡 등 한계가 있음.
- LLM inference에서 성능-비용-지연 “불가능 삼각형” 극복을 위해, query마다 weak/strong을 고르는 hybrid inference가 중요.
- 핵심 아이디어
- Benchmark에서 여러 번 샘플링해 weak vs strong의 Win Rate를 soft label로 만들고,
- Pass Rate 기반 Hard/Soft Blocking으로 둘 다 힘든 long-tail은 아예 weak로 보내도록 차단.
- 결과
- LLaMA 3.2 1B/3B + LLaMA 3.1 70B 조합에서 RouteLLM, HybridLLM, Margin Sampling 등 대비 APGR 최대 +5.29% 향상.
- Router는 DeBERTa-v3-large 정도의 encoder로도 충분하며, 50% routing ratio에서 약 2배 속도 향상을 달성하면서 strong-only에 가까운 성능 유지.
- LLaMA 3.2 1B/3B + LLaMA 3.1 70B 조합에서 RouteLLM, HybridLLM, Margin Sampling 등 대비 APGR 최대 +5.29% 향상.
