https://aclanthology.org/2025.emnlp-main.141.pdf
1. 서론 정리
1.1 문제 배경: LLM 추론 성능 vs 비용
- LLM은 모델 크기 + 프리트레이닝 데이터가 커질수록 추론 능력이 좋아진다는 scaling law 연구들이 많이 나와 있음.
- 하지만 대형 LLM은
- 추론 지연(latency) 크고
- 메모리 요구량 크고
- 상용 API 라이선스 비용도 비싸서 → 리소스 제약 환경(온디바이스, 사내 서버 등)에서 쓰기 힘듦.
그래서 자연스럽게 Knowledge Distillation이 솔루션 후보로 떠오름:
강력한 teacher LLM → 작고 효율적인 student LLM 으로 지식 전이해서
teacher의 상당 부분 능력을 유지하면서도, 효율성과 통제력을 회복하자.
1.2 기존 Distillation의 한계 (특히 Reasoning)
- 블랙박스 distillation = 토큰 수준 감독
- teacher는 API만 쓸 수 있고, 내부 로짓(access to logits)이 없으므로 보통 token-level next-token prediction으로만 지식을 전이.
- 이렇게 하면 teacher가 갖고 있는 전체 조건부 분포의 “얇은 단면만 보는 셈”이라, 복잡한 추론 능력을 온전히 가져오기 어렵다.
- teacher는 API만 쓸 수 있고, 내부 로짓(access to logits)이 없으므로 보통 token-level next-token prediction으로만 지식을 전이.
- 여러 reasoning path(CoT)를 쓰면 좋아지지만…
- 한 쿼리에 대해 teacher에서 여러 체인(CoT)을 샘플링해서 distillation 하면 단일 path만 쓸 때보다 성능이 꽤 좋아진다는 관찰이 있음.
- 이유: 서로 다른 reasoning trajectory가 teacher 추론 능력의 상보적인 측면을 담고 있기 때문.
- 한 쿼리에 대해 teacher에서 여러 체인(CoT)을 샘플링해서 distillation 하면 단일 path만 쓸 때보다 성능이 꽤 좋아진다는 관찰이 있음.
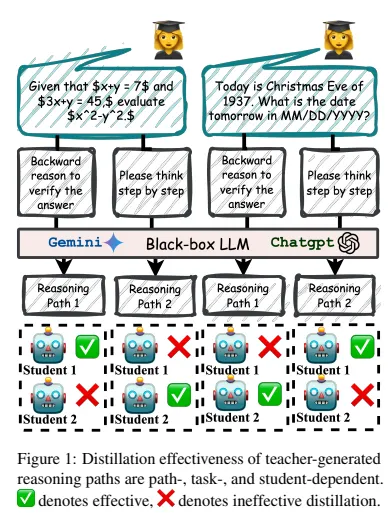
- 하지만 “모든 path를 그냥 다 학생에게 먹이는 것”은 서툰 전략
- 어떤 path는
- 최종 답이 틀리거나,
- 중간 단계에 spurious(쓸데없거나 잘못된 중간 추론) 을 포함하기도 함.
- 또, path의 “교육적 가치”는
- task마다 다르고,
- student 모델마다(구조/용량/프리트레인 데이터가 다르기 때문에) 다름.
- 예:
- 프로그램 스타일 설명은 알고리즘 문제엔 유용하지만, 단순 산술 문제에는 과한 정보.
- 긴 multi-hop chain은 복잡한 상식 추론엔 좋지만, 쉬운 문제에서는 “오버씽킹”을 유발.
- 어떤 path는
결론:
효과적인 distillation을 위해서는 reasoning path 선택이
- quality-aware (정답·논리 품질)
- task-aware (어떤 도메인/유형의 문제인지)
- student-aware (어떤 학생에게 맞는 스타일인지) 여야 한다.
1.3 QR-Distill의 큰 그림
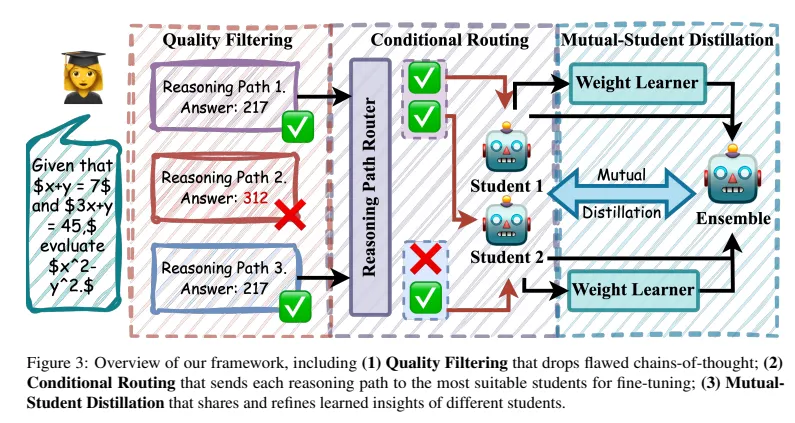
저자들은 이를 위해 QR-Distill (Quality-filtered Routing with Cooperative Distillation) 라는 프레임워크를 제안.
구성 요소는 크게 네 가지:
- Reasoning Path Generation
- 강력한 teacher LLM(Gemini)을 다양한 프롬프트 템플릿으로 여러 번 호출해 다양한 스타일의 reasoning path를 모은다.
- 강력한 teacher LLM(Gemini)을 다양한 프롬프트 템플릿으로 여러 번 호출해 다양한 스타일의 reasoning path를 모은다.
- Quality Filtering
- (1단계) 최종 답이 정답과 일치하지 않는 path 제거
- (2단계) LLM-as-a-judge 를 이용해 중간 단계가 헛소리/환각(spurious, hallucinated)이면 제거
- Conditional Routing
- 각 path를 encoder로 임베딩하고,
- trainable router(MLP+Gumbel-Softmax)가 현재 student 상태에 맞춰 path를 어떤 학생에게 줄지 선택.
- Mutual-Student Distillation (협력 distillation)
- 여러 학생(S1, S2, …)이 동시에 학습하면서,
- 같은 path에 대한 내부 representation을 서로 공유/정렬하는 feature-level distillation을 한다.
- 즉, teacher → students로만 배우는 것이 아니라 학생들끼리도 peer-teaching.
실험적으로는, 이 프레임워크가
- 기존 single-path distillation
- naive multi-path distillation (routing 없이 모든 path를 동일하게 사용) 보다 일관되게 더 좋은 성능을 보였고, ablation으로 각 모듈(QF, Routing, Collaboration)의 기여도도 확인.
2. 문제 설정 (Problem Setup)
2.1 데이터와 teacher/student 정의
- reasoning 데이터셋: [ ]
- (): 질문
- (): 정답 레이블.
- teacher 모델 (T):
- 블랙박스로 가정 (로짓에는 접근 못하고 출력만 얻을 수 있음).
- 목표:
- 더 작은 student 모델 (s) (실제 구현에서는 학생 S=2개: Mistral-7B, Gemma-7B)를 학습시켜 teacher의 reasoning 능력을 최대한 따라잡기.
- 더 작은 student 모델 (s) (실제 구현에서는 학생 S=2개: Mistral-7B, Gemma-7B)를 학습시켜 teacher의 reasoning 능력을 최대한 따라잡기.
2.2 Reasoning path가 포함된 증강 데이터
teacher를 여러 템플릿으로 호출해서 여러 reasoning path를 생성하고, 데이터셋을 확장:
- 증강된 데이터: [ ]
- 각 샘플의 path 집합: [ ]
- 한 질문당 (k)개의 서로 다른 reasoning path.
student는 이 () 를 이용해 훈련되고,
테스트 시에는 “간단한 instruction + 질문”(즉, zero-shot CoT prompt 비슷한 형태)만 받고 답을 생성한다.
3. 방법론(Methodology) – 4단계 구조
논문 2장을 그대로 따라가면:
- Reasoning Path Generation (2.2)
- Quality Filtering (2.3)
- Conditional Routing (2.4)
- Mutual-Student Distillation (2.5)
- Training Objective (2.6)
순서대로 볼게요.
3.1 Reasoning Path Generation (다양한 추론 스타일 생성)
목표: teacher로부터 다양한 reasoning 스타일의 CoT를 뽑아내기.
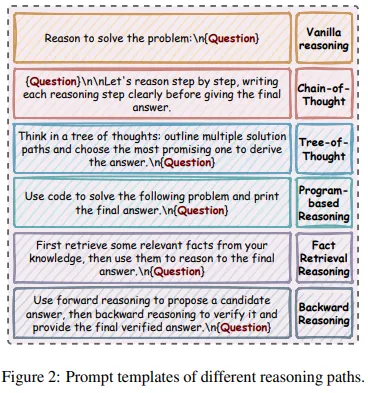
이를 위해 여러 종류의 프롬프트 템플릿을 설계해서 teacher에 넣습니다. 카테고리는:
- Vanilla Reasoning
- 그냥 “문제를 풀어라”에 가까운 일반적인 프롬프트.
- Chain-of-Thought Reasoning
- “step-by-step으로 생각해라” 식의 CoT 유도.
- Tree-of-Thought Reasoning (ToT)
- 여러 솔루션 후보를 나무 구조로 탐색하고, 가장 유망한 경로를 선택하도록 유도.
- Program-based Reasoning
- “파이썬 코드(혹은 유사 코드)를 작성해서 문제를 풀고, 결과를 출력하라” → 알고리즘/수학 문제에서 특히 유용.
- “파이썬 코드(혹은 유사 코드)를 작성해서 문제를 풀고, 결과를 출력하라” → 알고리즘/수학 문제에서 특히 유용.
- Backward Reasoning
- 정답 후보를 먼저 가정하고, 역방향으로 논리를 검증하는 backward reasoning.
- Fact-Retrieval Reasoning
- 먼저 관련 사실들을 떠올리고, 그 위에 추론을 이어가도록 유도 → 상식/지식 기반 QA에서 유리.
- 먼저 관련 사실들을 떠올리고, 그 위에 추론을 이어가도록 유도 → 상식/지식 기반 QA에서 유리.
논문 Figure 2(2페이지)는 이 템플릿들을 실제 프롬프트 문구와 함께 보여줍니다.
예: “Let’s reason step by step…”, “Use code to solve the following problem and print the final answer.” 등.
이렇게 해서, 각 질문 ()에 대해 teacher (T)로부터 다양한 스타일의 를 수집합니다.
3.2 Quality Filtering (품질 필터링)
생성된 path 중에는 틀린 답, 허위 중간 추론이 포함될 수 있으므로, distillation 전에 두 단계 필터링을 수행합니다.
단계 1: Incorrect Answers Removal (정답 기준 필터)
각 path ()에 대해:
- 최종 예측 답 ()를 파싱
- 정답 ()와 비교
- () 이면 → 해당 path 제거
- () 이면 → 일단 후보로 유지
이렇게 해서 최종 답은 맞지만, 중간 reasoning 품질은 아직 모르는 path들을 남깁니다.
단계 2: Spurious Reasoning Removal (LLM-as-a-judge)
남은 path들을 또 한 번 평가:
- 별도의 judge LLM (J)를 사용해서 각 reasoning path를 평가
- 중간 단계에 hallucinated / spurious step이 있는지
- 논리가 일관적인지 등을 판별
- “논리적으로 타당하다”고 판단된 path만 남깁니다.
이 과정을 거치면, 질문 (에 대해
정답이며 논리적으로도 괜찮다고 평가된 path들의 집합 () 를 얻게 됩니다.
3.3 Conditional Routing (조건부 라우팅)
Quality Filtering 이후에도,
- 같은 질문에 대해 여러 개의 괜찮은 path가 남고,
- 각각이 어떤 학생에게 더 잘 맞는지는 다를 수 있습니다.
그래서, 각 reasoning path를 “어느 student에게 가르칠지”를 학습하는 라우터를 도입합니다.
3.3.1 Path 임베딩
Quality-filtered path () (편의상 ())에 대해,
사전학습 encoder(논문에서는 RoBERTa-base)를 사용해 고정 차원 벡터로 만듭니다:
[
\tag{1}
]
여기서
- (): path (j) 의 표현
- (d): 히든 차원
3.3.2 Router MLP + Gumbel-Softmax
각 path 표현 ()는 MLP 기반 라우터에 들어갑니다:
- 먼저 MLP로 학생 수 (S) 차원의 로짓을 생성: [ ]
- 그 다음 Gumbel-Softmax를 사용해 “어떤 학생에게 할당할지”를 나타내는 one-hot 벡터를 샘플링:
[
\tag{2}
]
- ()이면 → path ()는 student (s)에게 할당
- (S): student 수 (논문 실험에서는 2명: Mistral, Gemma)
Gumbel-Softmax를 쓰는 이유:
- “argmax로 hard assignment”를 하고 싶지만,
- 그럼 gradient가 끊기므로,
- Gumbel-Softmax를 이용해 미분 가능하면서도 거의 one-hot에 가까운 샘플링을 하려는 것.
3.3.3 Entropy Regularization (라우팅 균형)
문제점: 라우터가 학습 과정에서
- 항상 같은 학생에게만 path를 보내거나
- 반대로 아무에게도 안 보내는 등 편향된 사용이 생길 수 있음.
이를 막기 위해 엔트로피 기반 정규화를 도입:
-
한 질문 ()에 대해, 모든 path (j), 모든 학생 (s)에 대해
- 할당값을 평균낸 스칼라 () 정의:
(실제로는 “전체 할당의 평균 확률” 정도로 보면 됨)
-
이 ()에 대해 이진 엔트로피를 maximize:
- ()가 0이나 1에 가까우면 entropy가 작으므로,
- 이 loss를 더하면 “너무 치우친 라우팅(항상 한쪽만 고르기)”에 페널티가 들어감.
결과적으로, router는
- 학생들 사이에 path를 좀 더 고르게 배분하려고 학습되고,
- 각 student에게 다양한 스타일의 reasoning path가 들어가게 됨.
3.4 Mutual-Student Distillation (학생 간 협력 Distillation)
여기까지 하면, 각 학생 (S_s)는
router가 보내주는 부분집합 path에 대해서 teacher supervised SFT만 하는 구조입니다.
하지만:
- 특정 학생은 특정 reasoning 스타일만 주로 보게 될 수 있고,
- 이렇게 되면 학생마다 커버하는 reasoning 영역이 편향될 수 있음.
- 또한, teacher와 학생 사이의 gap을 줄이기 위해 학생들끼리 자기들이 학습한 representation을 공유하는 것이 도움이 될 수 있음.
그래서 Mutual-Student Distillation을 도입.
3.4.1 학생별 hidden representation & projection
- 학생 (s)가 path ()에 대해 forward 했을 때,
- 마지막 레이어 hidden state: [ ]
- (T): 토큰 수
- (d): hidden 차원
- 마지막 레이어 hidden state: [ ]
- 이를 학생별 projection head로 공유 표현 공간으로 사상:
- ()는 여전히 (') 꼴(혹은 유사)로, “학생 s의 시각으로 본 reasoning path representation”이라고 볼 수 있음.
3.4.2 학생별 competence score (가중치 계산)
각 학생이 이 path에 대해 얼마나 잘 알고 있는지(competence) 를 스칼라로 추정:
-
토큰 차원을 평균:
[
]
-
student-specific 선형 회귀 + softmax로 학생 간 가중치 계산:
- ()는 “path ()에 대해 student (s)의 신뢰도/기여도”
- 모든 s에 대해 softmax이므로 ().
3.4.3 Ensemble representation & mutual loss
학생별 표현을 가중 평균해서 ensemble representation을 만듭니다:
그 다음, 각 학생 (s)가 이 ensemble에 맞추도록 평균제곱오차(MSE) 로 정렬:
- 즉, ensemble representation을 하나의 “가상의 teacher(동료 집단)”로 보고,
- 각 학생이 자신의 representation을 ensemble에 가깝게 만들도록 학습.
이렇게 하면:
- 특정 path에 대해 잘 배우는 학생이 ensemble을 끌어올리고,
- 다른 학생들은 그 정보에 feature space 수준에서 맞추면서 지식을 공유하게 됨.
- 특히 약한 학생(Gemma)이 상대적으로 더 강한 학생(Mistral)에게서 이득을 많이 보게 되고, 실험에서도 그런 현상이 관찰됩니다.
3.5 Training Objective (전체 학습 목표)
최종 loss는 세 가지 항을 합친 형태:
- (): student (s)에 대한 SFT / distillation loss
- router가 student (s)에게 할당한 reasoning path들에 대해 teacher가 생성한 텍스트를 target으로 하는 토큰 단위 cross-entropy (일반적인 SFT).
- router가 student (s)에게 할당한 reasoning path들에 대해 teacher가 생성한 텍스트를 target으로 하는 토큰 단위 cross-entropy (일반적인 SFT).
- (): routing 균형을 위한 엔트로피 정규화 (식 (4))
- (): mutual-student distillation loss (식 (8))
- (): 정규화 항의 가중치.
요약하면,
각 학생은 “자기에게 라우팅된 reasoning path”에 대해 teacher 텍스트를 따라가도록 SFT를 하고,
라우터는 entropy regularization으로 다양한 path를 적절히 나누도록 학습되며,
학생들끼리는 mutual loss를 통해 feature space에서 서로 representation을 share한다.
4. (간단히) 주요 결과 요약
논문은 5개 reasoning 벤치마크(SQA, ARC, MATH, ANLI, Date)에서
Gemini(teacher), Mistral-7B & Gemma-7B(student)로 실험합니다.
4.1 기본 성능 (Table 1)
- QR-Distill은 모든 데이터셋, 두 학생 모델에서 기존 모든 distillation 기법보다 우수.
- Zero-shot student 대비:
- Mistral: 평균 +41.44%p 향상
- Gemma: 평균 +63.33%p 향상
- single-path distillation 대비: 평균 +24.32%p
- multi-path(라우팅 없음) 대비: 최대 +13.36%p 성능 향상.
특히 약한 학생(Gemma)이 더 큰 이득을 보는 경향이 나타나고,
Date 데이터셋에서는 Gemma가 Mistral보다 더 좋은 성능까지 내는 흥미로운 결과도 있습니다.
4.2 Ablation (Table 2)
- Quality Filtering(QF), Routing, Collaboration(Collab)을 하나씩 제거해가며 ablation.
- 결과:
- 어느 한 모듈을 빼도 성능 하락 → 세 모듈 모두 기여.
- QF가 특히 기여도가 크고,
- Mutual Distillation은 Gemma(더 약한 모델)에서 더 큰 향상을 줌.
5. 한 줄로 정리하면
QR-Distill은
(1) 강한 teacher로부터 다양한 스타일의 reasoning path를 생성하고,
(2) 정답/논리 품질로 필터링한 뒤,
(3) 개별 student의 상태에 맞춰 path를 라우팅해서,
(4) 여러 student 사이의 협력 distillation으로 부족한 부분을 상호 보완하는
“Quality-filtered Routing + Collaborative Distillation” 프레임워크입니다.
