https://arxiv.org/pdf/2410.03834
-
간단 요약
이 논문은 'GraphRouter'라는 새로운 방법론을 제안합니다. 이를 통해 다양한 LLM(Large Language Models) 중 적합한 모델을 선택하는 과정을 효율화하려고 합니다. GraphRouter는 그래프 구조를 활용하여 사용자의 질의와 LLM 간의 상호작용 데이터를 바탕으로 적합한 모델을 자동으로 선택합니다.
주요 내용 요약
-
기존 문제점: 기존 모델 선택 방식은 특정 모델들에 대해서만 작동하거나, 새 모델이 추가되면 재학습이 필요해 확장성과 일반화가 부족했습니다. 또한, 간단한 BERT 기반 임베딩 등을 사용해 질의나 모델 간의 문맥을 충분히 활용하지 못했습니다.
-
GraphRouter의 접근 방식: GraphRouter는 질의, 작업, LLM을 각각 노드로 구성하고 이들 사이의 상호작용을 그래프의 엣지로 표현합니다. 이후, 그래프 뉴럴 네트워크(GNN)를 통해 문맥 정보를 학습하여 각 질의에 가장 적합한 LLM을 예측할 수 있게 합니다.
-
주요 특징:
- 문맥 정보 활용: 그래프 구조를 통해 질의와 모델 간 상호작용 데이터를 학습하여, 더 나은 모델 선택을 가능하게 합니다.
- 새 모델 일반화: 기존 모델 학습에 사용하지 않은 새로운 LLM도 적은 데이터로 예측이 가능하도록 설계되어 있어 유연하게 확장할 수 있습니다.
-
성능: 실험 결과에 따르면 GraphRouter는 기존 모델 선택 방식보다 적어도 12.3% 이상의 성능 향상을 보였으며, 새 모델에 대해서도 재학습 없이 우수한 성능을 유지했습니다.
논문에서 제시한 한계점
이 연구는 그래프 구조의 상호작용을 효과적으로 활용할 수 있는 가능성을 보여주었으나, 다음과 같은 개선 가능성을 남기고 있습니다:
-
복잡한 그래프 신호 활용 부족: LLM의 세대 간 관계나 경로를 포함한 복잡한 그래프 정보를 추가할 경우 더 나은 성능이 기대되지만, 이는 본 연구 범위를 넘어섰습니다.
-
다중 에이전트 시스템: 복잡한 질의에 대해 여러 LLM을 선택하는 경우의 적용 가능성도 추후 연구로 제안하고 있습니다.
이 연구는 문맥적 정보를 활용한 효율적인 모델 선택의 가능성을 열어주며, 추후 다양한 상황에 적용할 수 있는 다각적 확장의 가능성을 제시하고 있습니다.
-
-
방법론 요약
GraphRouter 방법론에서 사용된 수식과 그 원리에 대해 자세히 설명하고, 이해를 돕기 위해 간단한 예시를 들어 설명드리겠습니다. 주요 수식들을 각 단계별로 나눠 설명드리겠습니다.
1. GraphRouter의 기본 개념: GNN을 통한 노드 및 엣지 임베딩
GraphRouter는 태스크 노드, 쿼리 노드, LLM 노드의 세 가지 노드를 가지고 있으며, 이들 간의 관계는 엣지로 표현됩니다. 각 노드와 엣지에는 임베딩이 할당되어, Graph Neural Network(GNN)를 통해 학습됩니다.
-
노드 임베딩 초기화:
- 태스크 노드: GPT-4와 같은 언어 모델을 사용하여 태스크를 설명하는 문장을 생성하고, 이를 통해 태스크 임베딩 를 만듭니다.
- 쿼리 노드: 쿼리 문장을 사전 학습된 언어 모델(BERT 등)을 통해 임베딩 으로 만듭니다.
- LLM 노드: LLM의 기능과 비용을 포함한 설명을 작성하고, 이를 임베딩하여 초기 임베딩 을 생성합니다.
- 임베딩이란? 임베딩(embedding)에 대해 설명하고, 임베딩이 왜 필요한지, 그리고 GraphRouter에서 어떻게 만들어지는지 차근차근 설명드리겠습니다.
1. 임베딩(Embedding)이란 무엇인가?
임베딩은 고차원의 데이터를 저차원 벡터로 변환한 것입니다. 텍스트, 이미지, 오디오와 같은 데이터는 컴퓨터가 바로 이해하기 어렵기 때문에, 이를 숫자 벡터로 표현해주는 임베딩을 사용합니다. 예를 들어, 텍스트 데이터를 임베딩 벡터로 변환하면, 단어 간의 의미적 유사성을 수치로 표현할 수 있게 되어 기계 학습 모델이 이를 쉽게 처리할 수 있습니다. 임베딩은 보통 언어 모델(예: BERT, GPT-3)이나 신경망을 통해 생성되며, 이 벡터는 단어, 문장, 문서 간의 의미적 관계를 담고 있어 특정 작업(예: 유사도 계산, 분류)에서 유용하게 사용됩니다.2. 임베딩이 왜 필요한가?
임베딩이 필요한 이유는 데이터의 의미를 벡터 형태로 추상화하여 기계가 쉽게 처리할 수 있게 하기 위해서입니다. 예를 들어, 텍스트 데이터의 경우 임베딩을 사용하여 다음과 같은 장점을 얻을 수 있습니다.-
유사성 측정 가능: 임베딩 벡터가 생성되면, 벡터 간의 거리(예: 유클리드 거리, 코사인 유사도)를 계산하여 텍스트 간의 의미적 유사성을 측정할 수 있습니다.
-
고차원 데이터의 차원 축소: 원래 텍스트 데이터는 단어 수나 문장 길이만큼 차원이 높아질 수 있습니다. 임베딩을 통해 고차원 데이터를 낮은 차원 벡터로 표현하여 계산 효율성을 높일 수 있습니다.
-
의미적 정보 보존: 임베딩 벡터는 단어 간의 맥락 정보를 담고 있기 때문에, 문장이나 단어의 의미적 관계를 학습할 때 유용합니다.
예를 들어, "사과"와 "배"라는 단어는 과일이라는 공통점이 있기 때문에 유사한 벡터로 표현됩니다. 하지만 "사과"와 "컴퓨터"는 의미적으로 관련이 적기 때문에 서로 다른 벡터를 가지게 됩니다. 이렇게 임베딩을 사용하면 모델이 단어의 의미와 관계를 더 잘 이해할 수 있게 됩니다.
3. 임베딩을 어떻게 만드는가?
임베딩은 일반적으로 사전 학습된 언어 모델(예: BERT, GPT)을 사용해 만듭니다. 텍스트를 모델에 입력하면, 이 텍스트에 대응하는 벡터가 모델에서 출력됩니다. 이 벡터가 바로 임베딩 벡터입니다.
임베딩 생성의 과정을 간단히 설명하면 다음과 같습니다:
-
텍스트 입력: 모델에 텍스트("태스크를 설명하는 문장")을 입력합니다.
-
모델 처리: 모델이 입력된 텍스트를 처리하면서 각 단어의 의미를 파악하고, 텍스트 전체에 대한 정보를 추출합니다.
-
임베딩 출력: 모델의 마지막 층에서 벡터 형태로 출력된 값이 해당 텍스트의 임베딩 벡터가 됩니다.
이 임베딩 벡터는 텍스트의 의미를 압축하여 표현한 값으로, 주로 128차원, 256차원, 512차원 등으로 표현됩니다.
4. GraphRouter에서 임베딩을 어떻게 사용하는가?
GraphRouter에서 임베딩은 각 태스크, 쿼리, LLM 노드를 표현하는 데 사용됩니다. 태스크 노드를 예로 들어보겠습니다.
-
태스크 설명 문장 생성: GraphRouter에서는 각 태스크에 대한 간단한 설명 문장을 생성합니다. 예를 들어, "질문 응답을 위한 태스크입니다"와 같은 문장을 생성할 수 있습니다.
-
임베딩 생성: 이 설명 문장을 사전 학습된 언어 모델(BERT 등)에 입력하여 임베딩 벡터를 얻습니다. 예를 들어, "질문 응답을 위한 태스크입니다"라는 문장을 BERT 모델에 입력하면, 이 문장은 768차원 벡터로 변환됩니다.
-
태스크 노드 표현: 이렇게 얻은 임베딩 벡터는 해당 태스크 노드의 초기 표현으로 사용됩니다. 이는 그래프 구조에서 태스크 노드가 쿼리나 LLM 노드와 연결될 때, 태스크의 의미를 전달하는 역할을 합니다.
이를 통해 GraphRouter는 태스크와 쿼리, LLM 간의 관계를 벡터 공간에서 유사성으로 계산할 수 있게 됩니다. 예를 들어, 질문 응답(QA) 태스크와 관련된 쿼리는 QA에 특화된 LLM과 연결될 가능성이 높아지며, 이러한 유사성을 바탕으로 LLM을 선택할 수 있습니다.
예시를 통한 이해
예를 들어, 두 개의 태스크가 있다고 가정해 보겠습니다.
-
태스크 1: "간단한 수학 문제를 해결하는 태스크입니다."
-
태스크 2: "긴 문서를 요약하는 태스크입니다."
각각의 태스크 설명 문장을 언어 모델에 넣으면, 태스크 1과 태스크 2에 대한 임베딩 벡터가 생성됩니다. 이러한 임베딩 벡터는 태스크의 성격을 반영하며, 각 태스크 노드를 그래프에서 표현하는 데 사용됩니다.
-
만약 특정 쿼리가 "간단한 덧셈 문제를 푸세요"라고 한다면, 이 쿼리도 임베딩으로 변환됩니다.
-
GraphRouter는 이 쿼리 임베딩과 태스크 1의 임베딩이 더 유사함을 인식하고, 수학 문제에 적합한 LLM을 선택하도록 유도할 수 있습니다.
이처럼 임베딩을 통해 태스크, 쿼리, LLM의 의미를 벡터로 표현하고, 이를 바탕으로 상호 유사성을 계산하여 적합한 LLM을 선택하게 됩니다.
-
-
엣지 초기화:
- 태스크-쿼리 엣지 : 초기 값으로 1을 할당하여 단순히 연결을 나타냅니다.
- LLM-쿼리 엣지 : 해당 쿼리에 대해 LLM의 성능과 비용을 결합한 초기값으로 설정됩니다.
2. GNN 레이어를 통한 노드 임베딩 업데이트
GraphRouter는 이종 그래프 신경망(Heterogeneous GNN)을 사용하여 다양한 노드와 엣지 유형을 처리합니다. GNN의 각 레이어에서는 이웃 노드에서 정보를 집계하고 이를 사용해 임베딩을 갱신합니다. 이를 수식으로 표현하면 다음과 같습니다:
이 수식을 하나씩 분해해서 설명드리겠습니다.
-
: 태스크 노드의 l번째 레이어에서의 임베딩입니다.
-
: 학습 가능한 가중치 매트릭스로, 태스크 노드의 정보를 조정하는 역할을 합니다.
-
CONCAT: 임베딩들을 이어 붙이는 연산입니다.
-
MEAN: 태스크 노드 의 이웃 노드 (쿼리 노드)의 임베딩을 평균내는 연산입니다.
-
RELU: 비선형 활성화 함수로, 입력값이 양수일 때는 그대로 반환하고 음수일 때는 0으로 반환합니다.
예시: 태스크 노드의 임베딩 업데이트
예를 들어, 태스크 노드 가 있고 이웃으로 쿼리 노드 과 가 있다고 가정해봅시다. 각 쿼리 노드의 이전 레이어 임베딩이 , 라면, 이들의 평균을 취해 임베딩을 계산하게 됩니다. 여기서, MEAN 연산을 통해 두 이웃의 임베딩을 평균내면, 결과는 다음과 같이 됩니다:
이를 RELU와 가중치 매트릭스 를 적용하여 태스크 노드 임베딩 를 업데이트합니다.
3. LLM 선택 문제를 위한 엣지 예측
GraphRouter는 LLM을 선택하는 문제를 엣지 예측 문제로 변환하여 해결합니다. 즉, 특정 쿼리에 대해 가장 적합한 LLM이 무엇인지 예측하는 작업입니다.
-
쿼리-태스크 결합 임베딩:
쿼리 노드와 태스크 노드의 임베딩을 결합하여, MLP(다층 퍼셉트론)를 사용해 새로운 결합 임베딩 를 만듭니다:
-
엣지 예측:
생성된 결합 임베딩 $h_{qt}^{(l)}$ 와 각 LLM 노드의 임베딩 $h_m^{(l)}$ 사이의 점곱(dot product)을 계산하여 가장 높은 값을 가지는 LLM을 선택합니다: $\hat{y} = \arg \max_m \left( \text{EdgePred}(h_{qt}, h_m) \right)$예시: 최적 LLM 예측
쿼리-태스크 결합 임베딩이 이고, 두 개의 LLM 후보 LLM1 과 LLM_2 의 임베딩이 각각 $h{m1}^{(l)} = [0.3, 0.6] , h_{m2}^{(l)} = [0.7, 0.4]$ 라고 가정합니다. 두 LLM 후보와의 점곱을 계산하여 최적 LLM을 찾습니다:
-
-
이 경우 가 가장 높은 점수를 가지므로, 최적 LLM으로 선택됩니다.
요약
GraphRouter는 이종 그래프 신경망(GNN)을 통해 태스크, 쿼리, LLM 노드와 그들 간의 관계를 학습합니다. GNN 레이어를 통해 노드 임베딩을 업데이트하고, 엣지 예측을 통해 최적의 LLM을 선택하는 과정을 통해, GraphRouter는 상호작용 데이터를 효과적으로 활용하여 최적의 LLM을 예측합니다.
-
요약 (ABSTRACT)
급격하게 증가하는 다양한 대형 언어 모델(LLM)은 특정 쿼리에 적합한 LLM을 효율적으로 선택하는 데 있어 성능과 연산 비용 간의 균형을 고려해야 하는 어려움을 야기합니다. 현재 LLM 선택 방법들은 쿼리, 태스크, LLM 간의 맥락적 상호작용을 효과적으로 활용하지 못하거나 전이 학습 프레임워크에 의존하여 새로운 LLM이나 다양한 태스크에서 일반화하는 데 한계가 있습니다. 이러한 문제를 해결하기 위해, 우리는 태스크, 쿼리, LLM 간의 맥락 정보를 최대한 활용하여 LLM 선택 과정을 개선하는 새로운 귀납적 그래프 프레임워크인 GraphRouter를 제안합니다. GraphRouter는 태스크, 쿼리, LLM 노드를 포함하는 이질적 그래프를 구성하며, 상호작용은 엣지로 표현되어 쿼리의 요구 사항과 LLM의 기능 간의 맥락 정보를 효율적으로 포착합니다. 혁신적인 엣지 예측 메커니즘을 통해 GraphRouter는 잠재적 엣지의 속성(LLM 응답의 효과와 비용)을 예측할 수 있어, 재학습 없이 기존 및 새로 도입된 LLM에 적응하는 최적의 추천을 제공합니다. 세 가지 상이한 효과-비용 가중치 시나리오에 걸친 종합적인 실험에서 GraphRouter는 기존 라우터를 최소 12.3%의 성능 향상으로 능가했으며, 새로운 LLM 환경에서도 최소 9.5%의 성능 향상과 큰 연산 요구 감소를 달성했습니다. 본 연구는 맥락적이며 적응적인 LLM 선택을 위한 그래프 기반 접근 방식을 제시하며, 실무 적용에 대한 통찰을 제공합니다. GraphRouter의 코드는 곧 https://github.com/ulab-uiuc/GraphRouter에서 공개될 예정입니다.
서론 (INTRODUCTION)
대형 언어 모델(LLM) 분야는 빠르게 발전하고 있으며, 모델의 크기, 기능 및 연산 요구가 다양한 폭넓은 모델들이 등장하고 있습니다(Bang, 2023; Liu et al., 2023). 대체로 더 큰 모델이 더 나은 성능을 제공하지만, 높은 연산 비용으로 인해 복잡도가 낮은 많은 작업에는 비효율적입니다(Snell et al., 2024; Chen & Varoquaux, 2024). 또한, LLM은 서로 다른 쿼리와 태스크 유형에서 성능 차이를 보이며(Ahmed et al., 2024; Zhang et al., 2024), 특히 도메인 특화 LLM의 개발과 함께 그 차이가 더욱 두드러집니다(Singhal et al., 2022; Luo et al., 2022). 이러한 문제들은 사용자에게 필요한 성능과 비용 간의 균형을 맞추는 최적의 LLM 서비스를 추천하는 데 어려움을 야기합니다. 따라서 본 논문은 다음과 같은 중요한 연구 질문을 제기하고자 합니다: LLM의 방대한 생태계가 지속적으로 발전하는 상황에서, 다양한 사용자 쿼리와 이로부터 유추된 태스크에 맞춰 적절한 LLM을 추천하려면 어떻게 해야 하는가?
기존 연구들은 사용자 쿼리에 특정 LLM을 할당하기 위해 라우터를 개발하는 방안을 제안했습니다. 예를 들어, Hybrid LLM(Ding et al., 2024)은 특정 쿼리에 대해 소형 또는 대형 LLM을 선택하는 이진 스코어 라우터 함수를 훈련하여 비용과 성능을 균형 있게 맞추지만, 단 두 개의 LLM에 한정되어 현실적으로 다양한 LLM 요구를 충족하기에는 부족합니다. 다른 연구들(Dai et al., 2024; Chen et al., 2023)에서는 제한된 LLM 세트(대개 3~5개) 중에서 선택하는 문제를 해결하기 위해 더 발전된 라우터 모델을 소개했습니다. 예를 들어, FrugalGPT(Chen et al., 2023)는 BERT(Devlin, 2018)에 기반한 라우터 모델을 통해 더 큰 LLM으로 전환할지 여부를 결정하고, C2MAB-V(Dai et al., 2024)는 사용자가 탐색과 활용 사이에서 LLM을 선택하도록 하는 밴딧 기반 라우터를 구축했습니다. 그러나, Table 1에서 보듯이, 이들 방법에는 다음과 같은 몇 가지 제한점이 있습니다:
- 태스크, 쿼리, LLM 간의 상호작용에서 발생하는 맥락 정보를 완전히 활용하지 못하고, 쿼리를 구별하기 위해 기본적인 BERT 기반 임베딩과 LLM을 구별하기 위해 이름이나 인덱스만을 사용하는 점에서 일반화 성능이 제한됩니다.
- 전이 학습 프레임워크(Arnold et al., 2007; Joachims, 2003)에 의존하여, 새로운 LLM이 자주 등장하는 실제 상황에서 적합하지 않습니다. 새로운 LLM이 도입되면 소수의 상호작용 데이터를 활용한 재학습이 필요하며, 이는 많은 사용자에게 실시간으로 LLM을 추천하는 데 있어 비현실적인 과정입니다.
- 각 태스크에 대해 별도의 라우터를 훈련하여 다수의 태스크가 존재할 경우 연산 오버헤드와 복잡성이 증가합니다.
이러한 문제를 해결하기 위해, 우리는 GraphRouter라는 LLM 선택을 위한 그래프 기반 라우터를 제안합니다. GraphRouter는 귀납적 그래프 프레임워크를 활용하여 맥락 정보를 효과적으로 사용함으로써 새로운 LLM에 대해 일반화하고 다양한 태스크에 적응할 수 있습니다. 구체적으로, 서로 다른 쿼리와 태스크에 대한 맥락 정보를 충분히 활용하기 위해 GraphRouter는 태스크 노드, 쿼리 노드, LLM 노드의 세 가지 유형의 노드를 포함하는 이질적 그래프를 구축합니다. 그들 간의 상호작용 정보는 그래프 내 엣지로 표현됩니다. 예를 들어, 쿼리에 대한 LLM의 응답 보상(성능과 비용)은 쿼리 노드와 LLM 노드 간의 엣지로 모델링됩니다. 이를 통해, LLM-쿼리 쌍의 비용 및 성능을 예측하는 작업을 엣지 예측 작업으로 변환할 수 있습니다. 엣지 속성 예측 후, 사용자 요구에 맞는 성능과 비용을 기준으로 최적의 LLM을 추천합니다.
실제 상황에서는 새로운 LLM이 빈번히 개발되므로 효과적인 프레임워크는 이러한 진화하는 모델을 수용할 수 있는 능력도 갖춰야 합니다. GraphRouter를 새로운 LLM에 대해 일반화할 수 있도록, 두 가지 주요 측면에서 노력을 기울였습니다. 입력 측면에서, 우리는 GPT-4o와 같은 생성형 LLM을 활용하여 각 LLM의 강점, 토큰 가격, 컨텍스트 길이와 같은 주요 세부 사항을 기술하는 텍스트를 생성했습니다. 이를 바탕으로, 우리는 중간 크기의 사전 학습된 언어 모델(BERT(Devlin, 2018) 등)을 사용하여 각 LLM에 대한 초기 임베딩을 생성합니다. 이 접근 방식은 1-hot 인코딩을 직접 사용하는 것보다 유리하며, 새로운 LLM에 대해 귀납적이고 더 많은 정보를 담은 초기 임베딩을 생성할 수 있습니다. GraphRouter 모델 측면에서는, 이종 GNN을 개발하여 다른 유형의 이웃 노드로부터 정보를 집계합니다. 적은 샘플 데이터가 주어지면, 학습된 GraphRouter가 재학습 없이도 새로운 LLM 노드에 일반화할 수 있음을 검증했습니다.
요약
우리의 주요 기여는 다음과 같습니다:
- 우리의 지식에 따르면, LLM 선택을 위한 그래프 관점의 라우터 구축은 최초로, 이는 그래프 강화 LLM 연구에 새로운 통찰을 제공합니다.
- 태스크, 쿼리, LLM 간의 맥락 정보를 완전하게 활용하는 귀납적 그래프 프레임워크를 제안하여, 재학습 없이도 새로운 LLM에 일반화하고 다양한 태스크에 적응할 수 있습니다.
- 서로 다른 성능과 비용 절충 시나리오를 갖춘 세 가지 실험 설정에서, GraphRouter는 최소 12.3%의 성능 향상으로 기존 모델을 능가했습니다. 또한 테스트 데이터에서 새로운 LLM이 도입되는 경우, 재학습 시간을 절약할 뿐만 아니라 최소 9.5%의 성능 향상을 달성했습니다.
2 GraphRouter: LLM 선택을 위한 그래프 기반 라우터
2.1 기초 개념 (Preliminaries)
이 섹션에서는 LLM 선택 문제를 소개합니다. Figure 1의 왼쪽에 표시된 것처럼, 이 과정은 여러 단계를 포함하며, 그 중 라우터가 가장 중요한 구성 요소입니다. 라우터는 먼저 태스크 정보를 포함한 사용자 쿼리를 수신합니다. 라우터의 목표는 사용자 쿼리에 포함된 정보를 기반으로 최적의 성능과 최소 비용(LLM API 비용)을 달성할 수 있는 적절한 LLM을 선택하는 것입니다. 계산이 완료된 후, 라우터는 사용자 쿼리에 응답할 적합한 LLMn을 선택합니다. 마지막으로, 응답은 성능 및 비용과 함께 사용자에게 반환됩니다. 이러한 상호작용 과정은 태스크, 쿼리, 선택된 LLM, 응답, 성능 및 비용에 대한 정보를 포함한 풍부한 맥락적 데이터를 생성합니다. 이 데이터를 오른쪽에 표시된 표 형태로 정리합니다.
표 1: GraphRouter와 기존 방법을 세 가지 관점(맥락 정보, 새로운 LLM에 대한 일반화, 다중 태스크 지원)에서 비교한 것입니다. 다른 접근 방식과 비교하여, GraphRouter는 맥락 정보를 최대한 활용할 수 있는 귀납적 그래프 프레임워크를 도입하여, 새로운 LLM에 일반화되고 다양한 태스크에 적응할 수 있도록 설계되었습니다.
| 방법 | 맥락 정보 | 새로운 LLM에 대한 일반화 | 다중 태스크 지원 |
|---|---|---|---|
| Hybrid LLM (Ding et al., 2024) | 인덱스 | ✗ | ✗ |
| FrugalGPT (Chen et al., 2023) | LLM 이름 | ✗ | ✗ |
| C2MAB-V (Dai et al., 2024) | 원-핫 임베딩 | ✗ | ✗ |
| GraphRouter | 그래프 기반 맥락 정보 | ✓ | ✓ |
그림 1: GraphRouter의 LLM 선택 프로세스 개요. 왼쪽 섹션에 나와 있듯이,LLM 선택 프로세스는 사용자가 특정 작업에 속하는 쿼리를 입력하는 것으로 시작합니다.
라우터가 쿼리와 작업을 수신하면 입력을 분석하고 생성에 가장 적합한 LLMn을 선택합니다. 그런 다음 LLMn을 사용하여 응답을 생성합니다. 마지막으로 이 응답은 측정된 효과 및 비용과 함께 사용자에게 반환됩니다. 그림의 오른쪽은 작업, 사용자 쿼리, 선택된 LLM, 응답, 성능 및 비용과 같은 상황적 정보가 포함된 예시적 상호 작용 기록을 표로 보여줍니다. 그런 다음 이러한 상황화된 데이터를 사용하여 라우터를 학습합니다.
2.2 동기 부여 예시 (Motivating Examples)
전통적인 LLM 선택 방법(Ding et al., 2024; Chen et al., 2023; Dai et al., 2024)은 일반적으로 ID 또는 이름 정보를 사용하여 LLM 정보를 모델링하지만, 이는 LLM과 쿼리 간의 상호작용에서 생성되는 맥락 정보를 효과적으로 활용하지 못합니다(2.1절에서 소개된 맥락 정보). 여기서는 몇 가지 예를 통해 맥락 정보의 중요성을 설명합니다.
-
다양한 쿼리에 대한 LLM 성능 차이 포착
우리는 먼저, 맥락 정보가 중요한 이유로 LLM들이 다양한 쿼리에 응답하는 능력의 변동성을 포착한다는 점을 주장합니다. Figure 3에서 볼 수 있듯이, 쿼리에 응답하는 여러 LLM의 성능은 크게 차이가 날 수 있습니다. 따라서, LLM이 쿼리를 처리하는 성능 패턴을 이해하는 것이 LLM 선택에 중요하며, 이러한 패턴은 쿼리와 LLM 간의 맥락 정보에 내재되어 있습니다. 또한, Figure 2에서는 일부 작은 LLM이 특정 쿼리에서 더 큰 LLM보다 더 나은 성능을 보이는 경우도 확인할 수 있습니다. 예산이 무제한이고 비용이 높은 가장 큰 LLM에 무작정 의존하더라도 최적의 성능을 달성할 수 없는 경우가 있습니다. 이는 LLM이 쿼리를 처리하는 다양한 능력을 맥락 정보 기반으로 포착하는 것이 중요함을 강조합니다.
-
단일 LLM이 태스크에 따라 달라지는 성능 차이 포착
맥락 정보의 또 다른 중요한 점은 단일 LLM이 다양한 태스크에서 쿼리에 어떻게 응답하는지에 대한 차이를 포착할 수 있다는 점입니다. Figure 3과 Figure 4에서 볼 수 있듯이, 특정 LLM(예: Mixtral-8x7B, Jiang et al., 2024)은 두 가지 다른 태스크에서 상당히 다른 성능을 보입니다. 이 두 가지 예는 LLM과 태스크에 따라 성능이 크게 달라질 수 있음을 시사합니다. 이는 LLM의 능력을 이해하는 것 외에도, 라우터가 각 태스크의 차이점과 유사성을 이해해야 함을 의미합니다. 그러나 이러한 LLM 및 태스크의 중요한 속성은 이름이나 ID만으로는 충분히 표현되지 않기 때문에, 태스크, 쿼리 및 LLM 간의 상호작용을 포함하는 맥락 정보를 효과적으로 활용해야 합니다.
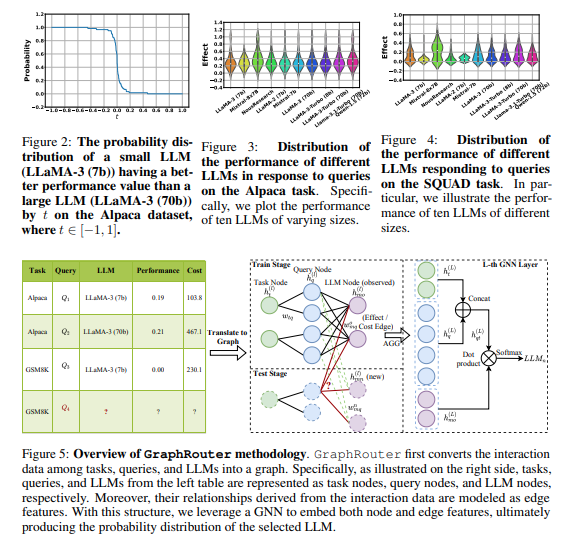
2.3 GraphRouter 프레임워크
방법 개요 (Method Overview)
Figure 5에 표시된 것처럼, GraphRouter는 먼저 태스크, 쿼리, LLM 간의 상호작용 데이터를 그래프로 변환합니다. 구체적으로, Figure 5의 오른쪽에서 볼 수 있듯이, 왼쪽 표의 태스크, 쿼리, LLM을 각각 태스크 노드, 쿼리 노드, LLM 노드로 모델링하고, 상호작용 데이터에서 파생된 관계는 엣지 특성으로 표현됩니다. 우리는 GNN을 사용하여 노드와 엣지 특성을 임베딩하고, 이를 학습 및 테스트에 활용합니다.
노드/엣지 초기화 (Initialize Node/Edge Features)
Figure 5에 따라, 우리는 세 가지 유형의 노드(태스크 노드 , 쿼리 노드 , LLM 노드 )와 두 가지 유형의 엣지(태스크-쿼리 엣지 및 LLM-쿼리 엣지 )를 정의합니다. 태스크, 쿼리, LLM의 고유한 차이점을 고려하여 노드를 초기화할 때 각기 다른 전략을 채택합니다. 태스크 노드를 초기화할 때는 GPT-4o와 같은 추가 LLM을 사용하여 태스크에 대한 설명을 생성하고, 이 설명을 인코딩하여 임베딩 를 얻습니다. 더 구체적으로, 우리는 설명을 중간 크기의 사전 학습된 언어 모델(예: BERT)에 입력한 후 평균 출력 토큰 임베딩을 취합니다. 쿼리 노드의 초기화는 동일한 PLM을 사용하여 쿼리를 임베딩한 로 얻습니다.
LLM 노드 초기화는 전통적으로 LLM의 이름이나 ID를 사용하여 이루어지지만, 이는 새로운 LLM에 일반화하는 능력을 제한하고 중요한 배경 정보를 놓치는 단점이 있습니다. 여기서는 프롬프트 기반 접근 방식을 채택하여 각 LLM의 기능을 설명하는 프롬프트를 설계하고, 설명에 각 LLM의 비용 정보를 추가합니다. 이 설명을 사용해 태스크 임베딩을 얻는 방식과 유사하게, 동일한 PLM을 사용해 초기 임베딩 을 계산합니다. 다양한 태스크와 LLM에 대해 생성한 설명은 부록 A에서 확인할 수 있습니다.
태스크-쿼리 엣지의 경우, 초기 값으로 1을 할당합니다. LLM-쿼리 엣지는 상호작용 데이터에서 성능과 비용 정보를 함께 고려하여, 성능과 비용을 연결한 값을 초기 특성으로 할당합니다.
이종 GNN을 통한 예측 (Predict via a Heterogeneous GNN)
우리는 Figure 5에 표시된 것처럼, 이종 GNN을 사용하여 태스크 노드, 쿼리 노드 및 LLM 노드에 대한 예측 모델 을 구현합니다. 다양한 유형의 노드와 엣지를 집계하기 위해, 우리는 서로 다른 학습 가능한 가중치를 사용하는 이종 집계를 적용합니다. GNN의 목표는 로컬 네트워크 이웃의 반복적이고 가중된 집계를 통해 표현력 있는 노드 임베딩 을 학습하는 것입니다. l번째 반복의 GraphConv(·) 또는 l번째 레이어의 노드 임베딩 업데이트는 다음과 같이 표현됩니다.
여기서 는 l번째 반복 후의 노드 임베딩이며, 는 각각 위에서 설명한 로 초기화됩니다. 는 v의 직접 이웃을 나타내며, 는 학습 가능한 매개변수입니다.
태스크, 쿼리, LLM 노드 임베딩이 업데이트된 후, 우리는 쿼리-태스크 결합 임베딩을 로 얻습니다. LLM 선택 문제는 엣지 예측 문제로 모델링되며, 학습 데이터는 다음과 같은 방식으로 생성됩니다. 각 쿼리에 대해 서로 다른 LLM이 달성한 성능(3.4절에서 설명한 최적의 보상)을 기반으로 학습 세트에서 최적의 LLM을 결정하고, 그 쿼리에 대해 최적의 LLM이 아닌 경우 엣지 레이블을 0으로, 최적의 LLM인 경우 1로 설정합니다. 이로써, LLM 예측은 다음과 같은 형태의 EdgePred(·)를 통해 이루어집니다.
GraphRouter의 학습 과정에 대한 자세한 내용은 Algorithm 1에 요약되어 있으며, 세부 사항은 다음과 같습니다. 또한, GraphRouter의 테스트 단계에서는 쿼리 노드와 최대 엣지 로짓을 갖는 LLM 노드를 최적의 LLM으로 식별하며, 이는 다음과 같이 계산됩니다.
새로운 LLM 환경에서의 GraphRouter (GraphRouter for New LLMs Setting)
전통적인 라우터는 각 새로운 LLM과의 상호작용을 통해 재학습이 필요하므로, 소수의 샘플로는 새로운 LLM에 직접 일반화할 수 없습니다. 이는 실제로 빠르게 변화하는 LLM 환경에 대응하기에 불충분합니다. 실제 환경에서의 우리의 프레임워크와 베이스라인을 테스트하기 위해, (Cao et al., 2023; Fey et al., 2023)을 따르며, 학습 세트에서 균일하게 샘플링된 쿼리에 대한 새로운 LLM의 상호작용 데이터를 포함하는 보조 데이터를 구성했습니다. 이 보조 데이터는 학습 과정에는 포함되지 않지만, 테스트 단계에서 몇 개의 예시로 사용됩니다.
3 실험 설정 (Experimental Setup)
3.1 데이터셋 및 LLM 설명
우리는 네 가지 다른 유형의 태스크에서 데이터를 선택했으며, 해당 통계는 표 2에 요약되어 있습니다.
알고리즘 1: GraphRouter의 학습
- 필요한 요소: 데이터셋 , 매개변수화된 이종 GNN , 태스크-쿼리 엣지 가중치 및 LLM-쿼리 엣지 가중치 , GNN 레이어 수 L .
- PLM을 사용하여 태스크 노드, 쿼리 노드 및 LLM 노드의 초기 임베딩 을 초기화합니다.
- 각 반복 i 에 대해:
- 샘플된 미니 엣지 배치 M 에서 Dtrain의 엣지를 마스킹하여 M 의 엣지 레이블 을 얻습니다.
- 각 레이어 에서 L 까지:
- 와 함께 GraphConv(·)을 사용하여 노드 임베딩을 업데이트합니다.
- 를 사용하여 예측 을 계산합니다.
- 손실 기준을 통해 역전파합니다.
선택된 데이터셋 및 LLM 설명
- Alpaca (Taori et al., 2023): 하이브리드 질문-응답(QA) 데이터셋으로, Alpaca 모델의 파인 튜닝을 위해 52k 샘플을 포함하고 있습니다. 이 데이터셋은 몇 가지 수동 지침을 주고 언어 모델에 훈련 인스턴스를 생성하도록 하는 self-instruct(Wang et al., 2022) 프레임워크를 통해 자동 생성되었습니다.
- GSM8K (Cobbe et al., 2021): 8.5k개의 다단계 수학적 추론 문제를 포함하여 모델의 복잡한 수학적 추론 능력을 평가합니다.
- SQUAD (Rajpurkar, 2016): Wiki 기사 기반의 대중 제공 독해 데이터셋으로, 500개 이상의 기사와 연결된 100k 이상의 QA 쌍을 포함합니다.
- Multi-News (Fabbri et al., 2019): 여러 문서 요약을 위한 벤치마크로, newser.com에서 수집된 뉴스 기사와 전문가가 작성한 요약으로 이루어진 56k 뉴스 기사-요약 쌍을 포함합니다.
또한, 우리는 다양한 크기의 LLM 10개를 도입했으며, 해당 통계는 표 3에 나와 있습니다. 모든 LLM과 토큰 비용은 Together API를 통해 접근했습니다.
3.2 데이터 전처리 및 분할
위 데이터셋과 LLM을 사용하여, 2.1절에서 설명한 멀티태스크 상호작용 데이터셋을 구축했습니다. 구체적으로, 먼저 네 가지 태스크의 모든 데이터셋을 결합했습니다. 각 쿼리에 대해, 3.1절의 열 개 LLM을 사용하여 응답을 생성하고, 이를 태스크별로 제시된 성능 측정 기준(표 2 참조)으로 평가하여 성능을 계산했습니다. 또한, 입력 및 출력 토큰 수와 LLM별 비용을 기준으로 비용을 계산했습니다. 여기서, 토큰 수 계산은 GPT-2를 사용했습니다(Chen et al., 2023 참조).
멀티태스크 상호작용 데이터셋을 얻은 후, 이를 실험 설정에 따라 분할했습니다. 주로 두 가지 주요 설정이 있습니다. 첫 번째는 표준 설정으로, 모든 LLM이 학습 및 테스트 세트에서 볼 수 있으며, 일부 새로운 쿼리만 테스트 세트에 등장합니다. 데이터는 쿼리별로 70%:10%:20%의 비율로 학습, 검증 및 테스트 세트로 나누어집니다.
두 번째 설정은 새로운 LLM 환경입니다. 여기서는 표 3의 첫 여섯 개 LLM만 관찰 가능하며, 나머지 네 개는 새로운 LLM으로 간주합니다. 따라서, 표준 설정을 기반으로 하여 학습 및 검증 세트에서 후자 네 개 LLM과 관련된 데이터를 제거하고, 테스트 세트는 표준 설정 그대로 유지합니다. 또한 (Cao et al., 2023; Fey et al., 2023)을 따르며, 학습 세트에서 균일하게 샘플링된 80개의 쿼리에 대한 새로운 LLM의 상호작용 데이터로 구성된 보조 데이터셋을 생성했습니다. 이 보조 데이터셋은 학습 과정에는 포함되지 않지만, 테스트 단계에서 몇 개의 예시로 사용됩니다.
3.3 기준 방법 (Baseline Methods)
우리는 다음 기준 방법들과 GraphRouter 모델을 비교했습니다.
- 규칙 기반 기준:
- Largest LLM: 항상 가장 큰 LLM을 선택합니다.
- Smallest LLM: 항상 가장 작은 LLM을 선택합니다.
- 프롬프트 기반 기준:
- Prompt LLM: 쿼리, 후보 모델, 목표(예: 효과성 우선)를 프롬프트에 직접 포함하여 외부 LLM(e.g., GPT-4)에 입력해 후보군에서 가장 적합한 LLM을 선택하도록 합니다.
- LLM 선택을 위한 대표적 라우터 모델:
- Hybrid LLM (Ding et al., 2024): 소형 및 대형 LLM을 사용할 때, 사전 학습된 언어 모델을 훈련하여 쿼리를 소형 또는 대형 모델로 할당합니다. 우리는 소형 및 대형 LLM으로 각각 LLaMA-2(7b) 및 Llama-3.1-Turbo(70b)를 사용하며, 사전 학습된 언어 모델로는 DeBERTa(He et al., 2020) 대신 RoBERTa(Liu, 2019)를 사용하여 더 나은 성능을 확인했습니다.
- FrugalGPT (Chen et al., 2023): 사전 학습된 언어 모델을 사용하여 주어진 쿼리에 대해 모든 LLM의 생성 결과 점수를 예측하고, 주어진 비용 내에서 가장 높은 점수를 가진 LLM을 선택합니다. RoBERTa(Liu, 2019)를 라우터의 백본 모델로 사용했습니다.
- C2MAB-V (Dai et al., 2024): LLM을 각각 하나의 "팔"로 간주하고, 더 나은 솔루션을 탐색하기 위해 탐색 메커니즘을 구현하는 밴딧 기반 모델을 사용합니다.
- 최적 해로 설정한 기준:
- Oracle: 보상을 극대화하는 이론적 상한을 정의하여, 각 쿼리가 최적의 LLM에 오라클 정보로 라우팅되도록 설정합니다.
3.4 지표 (Metrics)
표 3에 제시된 LLM의 통계와 Together API를 통한 비용을 기준으로, 우리는 GraphRouter와 기준 모델들의 성능을 평가하기 위해 세 가지 지표를 사용했습니다.
- 성능 (Performance): 각 방법이 다양한 쿼리에 대해 제공하는 응답의 평균 품질을 평가하기 위한 지표로, 3.2절 및 표 2에서 설명한 대로 계산됩니다.
- 비용 (Cost): 쿼리에 응답할 때의 평균 LLM 추론 비용을 평가하기 위한 지표로, 3.2절에 설명되어 있습니다.
- 보상 (Reward): 성능과 비용 간의 균형을 얼마나 잘 맞추는지를 측정하는 지표입니다. 사용자는 성능과 비용에 대해 다양한 우선순위를 가질 수 있기 때문에, 우리는 세 가지 시나리오를 정의했습니다: 성능 우선 (Performance First), 균형 (Balance), 비용 우선 (Cost First). 이 시나리오는 각각 높은 성능을 우선시하거나, 성능과 낮은 비용을 동등하게 고려하거나, 낮은 비용을 우선시하는 상황을 나타냅니다. 성능과 비용의 영향을 제거하기 위해, 먼저 성능과 비용을 정규화한 후, 보상을 다음과 같이 정의했습니다: . 세 가지 시나리오에서 와 의 값을 각각 (1, 0), (0.5, 0.5), (0.2, 0.8)로 설정했습니다.
3.5 구현 세부사항 (Implementation Details)
훈련 단계에서는, 그래프 신경망을 32차원 숨겨진 차원의 2층 그래프 주의 신경망(GAT)으로 설정했습니다. 배치 크기는 32이며, 최대 학습 에포크는 1000으로 설정했습니다. 모델 학습에는 Adam 최적화기(Diederik, 2014)를 사용하며, LambdaLR 스케줄러로 학습률을 1e-3에서 점진적으로 감소시켰습니다. 제안된 방법은 PyTorch와 PyG를 사용하여 구현했으며, 모든 실험은 NVIDIA A100 Tensor Core GPU에서 진행했습니다. LLM의 응답은 Together AI의 API 호출을 통해 얻었습니다.
4 실험 결과 (Experimental Results)
4.1 기존 기준 모델과의 비교 (Comparison with Existing Baselines)
표 4에 제시된 바와 같이, 우리는 세 가지 시나리오에서 GraphRouter를 일곱 가지 기준 모델과 비교했습니다. GraphRouter는 기존 라우터를 지속적이고 현저히 능가하여, 가장 강력한 기준 모델에 비해 최소 12.28%의 보상 지표 향상을 달성했습니다. 또한, GraphRouter는 최적 해(표 4의 Oracle) 대비 최소 88.89%의 성능을 달성하여, 프레임워크의 우수성을 추가로 입증했습니다. 한편, 규칙 기반 LLM 두 개와 비교했을 때, GraphRouter는 성능과 비용 간의 더 나은 균형을 이루어 보상에서 더 높은 효과를 얻었습니다. Prompt LLM, Hybrid LLM (Ding et al., 2024), FrugalGPT (Chen et al., 2023)의 효과를 분석한 결과, 충분한 맥락화된 정보를 제공하지 않는 한, LLM 및 훈련된 중간 크기 언어 모델도 쿼리와 후보 LLM을 효과적으로 이해하기 어려운 점을 확인했습니다. 이 비교와 결과는 최적의 LLM을 선택하는 데 있어 맥락 정보를 효과적으로 사용하는 것이 중요하다는 우리의 주장을 뒷받침합니다.
4.2 새로운 LLM에 대한 일반화 능력 (Generalization Ability to New LLMs)
GraphRouter의 새로운 LLM에 대한 일반화 능력을 검증하기 위해, 우리는 3.2절에서 설명한 대로 Balance 시나리오에서 실험을 수행했습니다. 다른 기준 모델과 비교하기 위해, 보조 데이터셋을 그들의 학습 데이터셋에 추가했습니다. 구체적으로, 우리는 GraphRouter (few-shots)를 HybridLLM, FrugalGPT, C2MAB-V 및 GraphRouter (trained)와 보상 및 시간 비용(학습 시간 + 추론 시간)에서 비교했습니다. 결과는 표 5에 나와 있습니다. 가장 높은 비용을 지닌 C2MAB-V (Dai et al., 2024)와 비교했을 때, GraphRouter (few-shots)는 보상에서 거의 10%의 성능 향상을 달성했을 뿐만 아니라 시간 비용을 99% 이상 크게 줄였습니다. 보상 향상 및 시간 비용 절감 비율은 다른 기준 모델을 크게 초과했습니다. 또한, GraphRouter (trained)와 비교했을 때, 시간 비용을 크게 절감하면서도 성능 손실은 미미했습니다. 이러한 관찰 결과는 GraphRouter가 새로운 LLM에 대해 효과적이고 효율적으로 일반화할 수 있음을 보여줍니다.
표 5에 따르면, 다양한 방법을 few-shot 설정에서 보상, 시간 비용, 가장 높은 비용을 지닌 방법(C2MAB-V)에 대한 보상 향상 비율 및 시간 비용 절감률로 비교한 결과는 다음과 같습니다.
| 방법 | 보상 | 보상 향상 (%) | 시간 비용 | 시간 비용 절감률 (%) |
|---|---|---|---|---|
| HybridLLM | 0.01 | -94.71 | 273.45 | 49.57 |
| FrugalGPT | 0.171 | -9.52 | 63.15 | 88.35 |
| C2MAB-V | 0.189 | 0.00 | 542.25 | 0.00 |
| GraphRouter (few-shots) | 0.207 | 9.52 | 3.00 | 99.45 |
| GraphRouter (Trained) | 0.219 | 15.87 | 30.00 | 94.47 |
4.3 절편 연구 (Ablation Studies)
GraphRouter는 GNN 크기에 따라 어떻게 성능이 달라지는가?
GNN의 크기는 GNN 알고리즘을 설계할 때 중요한 요소로, 성능에 영향을 줄 뿐만 아니라 크기가 너무 클 경우 추가적인 연산 오버헤드를 유발할 수 있습니다. GraphRouter의 최적 GNN 크기를 찾기 위해, 우리는 GNN 크기를 16에서 80까지 다양하게 조정해 실험을 진행했으며, 결과는 Figure 6에 나와 있습니다. 그래프에서 볼 수 있듯이, GraphRouter의 보상(Reward)은 크기가 증가함에 따라 처음에는 개선되다가, 크기가 32일 때 최고치를 기록한 후 다시 감소하는 경향을 보였습니다.
GNN 레이어 수가 GraphRouter의 성능에 미치는 영향은?
GNN의 레이어 수는 GNN의 표현력에 중요한 영향을 미칩니다. 얕은 GNN은 깊은 맥락 정보를 학습하는 데 한계가 있으며, 반면에 너무 깊은 GNN은 과도한 평활화와 과적합 문제를 일으킬 수 있습니다. 또한, 레이어 수가 증가할수록 계산 비용도 증가합니다. GraphRouter의 최적 레이어 수를 찾기 위해, 0에서 5까지의 레이어 수로 실험을 진행했으며, 결과는 Figure 7에 나와 있습니다. 그래프에 따르면, 레이어 수가 증가함에 따라 처음에는 보상이 개선되었지만, 레이어 수가 2일 때 최고 보상을 기록한 후 다시 감소하는 경향을 보였습니다.
5 추가 관련 연구 (Additional Related Works)
LLM 선택
LLM의 파라미터 수가 증가함에 따라 추론 비용도 급격히 증가하고 있습니다. 이를 최적화하기 위해, 여러 연구에서는 모델 전환 방식을 도입하여 문제를 완화하고자 했습니다. 예를 들어, Zhu et al. (2023)은 소형 및 대형 LLM이 주어졌을 때, 사전 학습된 언어 모델을 미세 조정하여 소형 LLM만으로 충분한지 예측하도록 했습니다. HybridLLM (Ding et al., 2024)은 학습 데이터 변환을 통해 불균형한 레이블의 영향을 보완하여 이를 개선했습니다. Chen et al. (2023)은 쿼리와 LLM 인덱스에 대한 신뢰도 점수를 예측하도록 라우터를 학습했으며, Sakota et al. (2024)은 추가적인 비용 또는 성능 제약이 존재하는 시나리오를 수용하도록 라우터의 학습 목표를 일반화했습니다. 기존 접근법과 달리, GraphRouter는 쿼리-모델 상호작용 외에도 쿼리-쿼리, 모델-모델 관계를 함께 모델링하여 학습 데이터의 정보를 완전히 활용합니다. 이를 통해, 태스크, 쿼리 및 모델에 대한 효과적인 표현을 학습하고 더 나은 일반화 성능을 제공합니다.
관계 모델링을 위한 그래프 사용
그래프는 복잡한 관계 모델링에서 큰 잠재력을 보여주고 있으며(Fey et al., 2023; Cao et al., 2023), 이는 추천 시스템 및 소셜 네트워크와 같은 분야에서 널리 응용되고 있습니다. 특히, 이종 그래프 신경망(HeterGNNs)은 복잡한 그래프 데이터를 처리하기 위해 제안되었으며, 최근에는 GNN의 제로샷 또는 소수 샷 학습 능력을 탐구하여 더 복잡한 실제 문제를 해결하려는 연구가 진행되고 있습니다. 이 연구에 기반하여, 우리는 GNN의 맥락적 이종 관계 표현 능력과 제로샷 가능성을 LLM 선택 문제에 통합했습니다.
6 결론 및 논의 (Conclusion and Discussion)
결론 (Conclusion)
우리는 다수의 LLM을 이용한 추론 시 LLM 라우팅을 위한 그래프 귀납적 프레임워크인 GraphRouter를 제안했습니다. 이 연구는 LLM 라우팅 문제를 쿼리 노드와 LLM 노드 간의 엣지 예측 문제로 재구성하여 이를 해결한 최초의 연구입니다. 우리는 그래프 구조를 통해 상호작용 데이터에서 맥락 정보를 완전히 포착하여 태스크, 쿼리 및 그래프 표현을 효과적으로 학습했습니다. 네 가지 오픈 도메인 QA 데이터셋을 기반으로 한 실험과 세 가지 시나리오에서 GraphRouter가 기존 LLM 선택 기준을 능가함을 증명했으며, 이상적 솔루션(Oracle)에 근접한 성능을 보여주었습니다. 또한, 테스트 시 새로운 LLM이 도입되는 더 어려운 환경에서도 GraphRouter의 강력한 일반화 능력을 입증했습니다. 우리는 GraphRouter가 상호작용 데이터를 그래프로 통합하는 접근 방식과 함께 향후 LLM 라우팅 연구를 촉진할 수 있기를 기대합니다.
제한사항 (Limitations)
본 연구는 LLM 선택 과정에서 과거 상호작용 데이터를 그래프로 모델링하여 성능을 향상할 수 있는지를 탐색하는 초기 연구로, 더 복잡한 그래프 신호나 LLM 계보(예: LLaMA2 → LLaMA3 → LLaMA3.1)와 같은 분류 체계를 활용할 경우 GraphRouter의 성능을 더욱 개선할 수 있다는 점을 인지하고 있습니다. 이러한 추가 연구는 본 연구의 범위를 벗어나며, 향후 연구 과제로 남겨 둡니다.
향후 연구 (Future Work)
앞으로 탐구할 몇 가지 흥미로운 주제는 다음과 같습니다:
- 복잡한 쿼리에 답변할 때, Chain-of-Thought, Tree-of-Thought와 같은 프롬프트 방법이 LLM의 추론 능력을 강화하기 위해 널리 사용됩니다. 이러한 방법이 매우 많기 때문에, 생성 결과를 예측하고 최적의 방법을 선택하는 것은 여전히 큰 도전 과제입니다. 프롬프트 방법 선택은 LLM 선택과 유사하므로, GraphRouter를 이 작업에도 적용할 수 있는지 탐구하는 것은 흥미로운 주제입니다.
- 다중 에이전트 시스템에서 특정 쿼리와 태스크에 대해 각 모듈에 적합한 LLM을 선택하는 것이 중요합니다. 다수의 LLM을 동시에 선택하는 이 도전적인 과제에서 GraphRouter와 같은 귀납적 그래프 프레임워크가 우수한 성과를 낼 수 있는지 실험해보는 것도 가치 있을 것입니다.
