https://arxiv.org/pdf/2311.08692
간단 요약
이 논문은 "ZOOTER"라는 대규모 언어 모델(LLM)들의 효율적인 집합 방식을 제안하고 있습니다. ZOOTER는 주어진 입력 쿼리를 가장 적합한 LLM에 전달하여 컴퓨팅 효율을 극대화하려는 방법론입니다. 전통적인 모델 앙상블 방식에서는 여러 LLM이 각각의 출력을 생성하고 이를 평가하여 최적의 답변을 선택하는 방식으로 많은 계산 자원이 필요했습니다. 반면, ZOOTER는 보상 모델(reward model)을 이용해 쿼리를 가장 적절한 전문가 모델로 라우팅(routing)하는 방식을 사용하여 효율을 높였습니다.
논문 개요 및 동기
- 대규모 언어 모델의 전문성 활용: LLM들은 서로 다른 데이터로 사전 학습되기 때문에 특정 분야나 작업에서 각각의 모델이 가지는 잠재적인 전문성(expertise)이 다릅니다. 이 논문은 이러한 모델의 이질적인 전문성을 활용하여, 다양한 작업에서 최적의 성능을 얻기 위해 쿼리를 가장 적절한 모델에 라우팅하는 방식의 필요성을 강조합니다.
- 계산 효율성: 기존의 앙상블 방법(모든 모델이 출력을 생성하고 이를 보상 모델로 평가하여 순위를 매기는 방식)은 계산 부담이 컸습니다. 반면, ZOOTER는 각 쿼리를 사전에 가장 전문성 있는 모델에 보내도록 라우팅하여 연산 부담을 크게 줄였습니다【39†source】.
방법론 (ZOOTER)
ZOOTER는 보상 모델에서 얻은 정보로 모델의 전문성을 학습하고, 이를 바탕으로 쿼리를 해당 전문가 모델에 효율적으로 라우팅하는 시스템입니다. 구체적인 방법은 다음과 같습니다.
- 보상 모델을 통한 라우팅 학습:
- 먼저 다양한 쿼리 데이터셋에 대해 각 모델이 생성한 응답을 보상 모델로 평가합니다. 이 평가는 각 모델의 쿼리에 대한 상대적 우수성을 수치화한 "보상"으로 나타납니다.
- 이 보상 점수는 쿼리와 모델 간의 전문성 정도를 나타내므로, 이를 기반으로 ZOOTER는 "지식 증류(knowledge distillation)" 기법을 통해 라우팅 함수를 학습합니다. 이때, 보상의 확률 분포는 라우팅 함수의 훈련 데이터로 사용됩니다【39†source】.
- 태그 기반 레이블 보정:
- 보상 모델의 결과는 때때로 불확실성이 존재할 수 있습니다. 이를 보정하기 위해 ZOOTER는 태그 기반 레이블 보강(tag-based label enhancement)을 도입하여 보상 점수를 미세하게 조정합니다.
- 이 방법은 유사한 태그를 가진 쿼리들에 대해 보상 평균을 사용하여 훈련 데이터를 보정하고, 이를 통해 보상 모델의 불확실성을 줄이고 라우팅의 정확성을 높입니다
실험 결과
ZOOTER는 여러 LLM들의 앙상블보다 더 적은 계산 자원으로 높은 성능을 달성하였습니다. 다양한 벤치마크(AlpacaEval, FLASK, MT-Bench 등)에서 단일 모델 및 기존의 보상 모델 순위 방식과 비교하여 더 높은 성능을 보여주었습니다.
결론
이 논문은 LLM 앙상블의 잠재력을 재평가하고, 보상 모델로부터 학습한 정보를 통해 효율적인 라우팅 시스템을 구축함으로써 계산 비용을 절감하는 데 성공했습니다.
초록 (Abstract)
대형 언어 모델(LLM)의 상호보완적 잠재력은 다양한 도메인과 작업에서 이종적 전문성을 보유한 기성(off-the-shelf) LLM이 앙상블을 통해 일관되게 더 나은 성능을 달성할 수 있다는 가정을 기반으로 합니다. 기존의 LLM 앙상블 방법은 출력의 보상 모델을 기반으로 순위를 매기며, 이는 상당한 계산 비용을 초래합니다. 이러한 문제를 해결하기 위해, 우리는 LLM의 상호보완적 잠재력을 재조명하고, 기성 보상 모델을 활용하여 잠재적 전문성을 발굴하는 방식을 제안합니다.
ZOOTER는 보상에 기반한 라우팅 방법으로, 학습 질의에 대한 보상을 추출하여 라우팅 함수를 학습하고, 각 질의를 해당 전문성을 가진 LLM에 정확히 분배합니다. 또한, 보상을 은(銀) 감독으로 사용할 때 발생할 수 있는 불확실성에서 비롯되는 노이즈를 줄이기 위해 태그 기반 레이블 강화(tag-based label enhancement)를 통합합니다. ZOOTER는 보상 모델 순위 매김 방식과 비교했을 때 소량의 라우팅 함수 계산만 추가적으로 요구하여 추론에서 계산 효율성을 보입니다.
우리는 ZOOTER를 다양한 도메인과 작업에서 26개의 하위 집합으로 구성된 포괄적인 벤치마크 컬렉션에서 평가했습니다. ZOOTER는 평균적으로 단일 최고 성능 모델을 능가하며, 작업의 44%에서 1위를 차지하며, 다수의 보상 모델 순위 매김 방식을 초과 성능을 보였습니다.
1. 서론 (Introduction)
인간의 선호도에 맞춰 조정된 대형 언어 모델(LLM)은 급속히 등장하고 있으며, 매일 새로운 모델이 발표되고 있습니다(Touvron et al., 2023a,b; Anil et al., 2023; Bai et al., 2023). 이러한 기성 LLM은 다목적 작업 해결을 위해 추가로 미세 조정되거나 인간의 선호도에 맞게 조정됩니다(Xu et al., 2023; Touvron et al., 2023b,a). 이들은 일반 작업(generalists) 또는 특정 작업(specialists)으로서의 역할을 수행합니다(Yuan et al., 2023a; Luo et al., 2023a,b; Roziere et al., 2023).
LLM은 다양한 데이터로 사전 학습(pretrained) 및 조정(aligned)되었기 때문에 다목적 하위 작업에서 서로 다른 강점과 약점을 보입니다(Jiang et al., 2023). 따라서, LLM 앙상블은 이러한 상호보완적 잠재력을 활용하여 단일 최고 성능 모델보다 더 나은 성능을 달성할 수 있습니다.
LLM 앙상블의 주요 과제 중 하나는 기존 LLM의 대규모 매개변수로 인해 발생하는 계산 효율성 문제입니다. 이전 연구(Jiang et al., 2023; Shnitzer et al., 2023)는 LLM의 출력 결과를 병합하여 앙상블을 구현하는 강력한 방법을 제공했으나, 이는 막대한 추론 비용을 초래하여 저자원(low-resource) 환경에서는 경쟁력이 낮습니다.
우리는 기성 LLM이 "일반 작업(generalists)"으로 조정되었더라도 다양한 도메인과 주제에서 이종적 전문성을 보유하고 있다는 간단하지만 아직 충분히 연구되지 않은 가정을 보다 깊이 탐구합니다. 이 가정이 강력히 성립된다면, 기성 LLM을 효율적으로 조합하여 추가적인 추론 비용 없이 해당 전문성을 보유한 모델에 질의를 할당할 수 있습니다. 이러한 효율적인 라우팅 전략은 각 질의에 대해 단일 모델만 추론하는 비용과 라우팅 함수의 비교적 적은 오버헤드만 요구합니다. 그러나 기성 LLM의 세부적인 전문성을 조사하고 라우팅 학습을 위한 감독 데이터를 생성하는 것은 주석 작업이 필요하여 어려움을 수반합니다.
ZOOTER 제안
이 문제를 해결하기 위해 우리는 ZOOTER를 제안합니다. ZOOTER는 효율적인 기성 LLM 조합을 위해 보상에 기반한 질의 라우팅 방법입니다. ZOOTER는 보상 모델(RM)에서 은 감독 데이터를 얻고 강화하여 라우터 학습에 활용하고, 질의를 사전에 적합한 "전문성"으로 분배합니다.
핵심 기여
- 오픈소스 LLM의 상호보완적 잠재력을 재조명하여, LLM 앙상블의 효과를 입증하고 기성 RM의 보상이 모델 전문성의 은 감독으로 활용될 수 있음을 증명합니다.
- ZOOTER라는 효율적인 보상 기반 라우팅 방법을 제안하며, 기성 보상 모델로부터 보상을 추출하여 모델 전문성을 조사하고 태그 기반 레이블 강화를 통해 보상 모델의 불확실성을 완화합니다.
- 26개의 하위 집합으로 구성된 4개 그룹의 벤치마크에서 보상 모델 순위 매김 및 ZOOTER를 포함한 앙상블 방법을 포괄적으로 평가하며, ZOOTER가 보상 모델 순위 매김 방식보다 적은 계산 비용으로 더 효과적으로 LLM을 조합할 수 있음을 입증합니다.
2 관련 연구 (Related Works)
명령어 조정 및 정렬 (Instruction Tuning and Alignment)
명령어 조정(Instruction tuning)은 LLM이 다양한 명령어를 따르도록 돕는 기술로, 인간의 선호도에 LLM을 맞추기 위해 널리 활용되고 있습니다(Longpre et al., 2023; Chiang et al., 2023; Xu et al., 2023; Bai et al., 2023). 본 연구에서는 Llama-2-Chat(Touvron et al., 2023b), WizardLM(Xu et al., 2023), Vicuna(Chiang et al., 2023) 등 정렬된 LLM을 조합하는 데 중점을 두며, 이를 다양한 정렬 평가 작업에서 평가합니다.
대형 언어 모델 앙상블 (Large Language Model Ensemble)
LLM 앙상블은 오픈소스 LLM의 폭발적인 증가로 인해 떠오르는 주제입니다. LLM 앙상블은 기성 LLM을 통합하여 다양한 다운스트림 작업에서 일관되게 더 나은 성능을 달성하는 것을 목표로 합니다. 몇몇 연구에서는 LLM의 상호보완적 잠재력 가정을 탐구하고 이를 활용한 LLM 조합 방법을 제시합니다. 예를 들어:
- Jiang et al. (2023): 순위 매기기(pair ranker)와 생성 융합(generation fuser)으로 구성된 앙상블 프레임워크를 제안.
- Chen et al. (2023): 기성 LLM을 순차적으로 추론하며, 응답이 충분한 품질을 충족할 때까지 진행.
- Wang et al. (2023b): 데이터 분포에 대한 보완적 지식을 가진 전문가 모델의 출력을 융합하는 문제를 감독 학습으로 정의.
- Shnitzer et al. (2023): 다양한 벤치마크 데이터셋에서 모델 라우터 학습의 유용성과 한계를 보여줌.
이 연구들은 모두 보상 순위 매기기 또는 라우팅 전략을 활용해 LLM을 조합하는 데 중점을 두지만, ZOOTER는 두 가지 측면에서 이러한 동시 연구들과 차별화됩니다.
- 기존 연구들은 후보 모델의 프롬프트 표현을 얻기 위해 출력 생성 또는 추론 과정을 요구하여 상당한 계산 오버헤드가 발생합니다. ZOOTER는 미리 정의된 학습 질의 집합에 대한 보상을 증류(distill)하여 이러한 추론 오버헤드를 방지합니다.
- 기존 연구들은 정답 응답(golden responses)을 필요로 하며 특정 벤치마크에서 개발 및 평가되지만, ZOOTER는 질의만으로 개발 가능하며, 보다 다양한 정렬 작업을 목표로 합니다.
ZOOTER는 데이터와 계산의 효율성 측면에서 두각을 나타내며, 더 다양한 정렬 작업에서 평가되어 LLM의 상호보완적 잠재력을 포괄적으로 검증합니다.
보상 모델 기반 생성 (Reward Model Guided Generation)
LLM에서 보상 모델은 강화 학습(Schulman et al., 2017; Ouyang et al., 2022) 또는 선호 학습(Yuan et al., 2023b; Rafailov et al., 2023; Song et al., 2023)을 통해 정렬 성능을 개선하는 데 일반적으로 사용됩니다. 또한, 보상 모델은 생성 단계 동안 성능을 향상시킬 수도 있습니다.
- Cobbe et al. (2021); Uesato et al. (2022); Lightman et al. (2023): 보상 모델을 사용해 여러 수학적 추론 경로를 순위 매겨 언어 모델의 수학적 추론 능력을 개선.
- Liu et al. (2023): 보상 모델을 활용하여 보상 중심 디코딩(reward-guided decoding)을 공식화.
이러한 성공적인 보상 모델 활용 사례에 영감을 받아, ZOOTER는 기성 보상 모델을 활용해 LLM의 잠재적 전문성을 조사합니다.
3 방법 (Methods)
우리는 먼저 LLM의 상호보완적 잠재력을 재검토합니다(§3.1). 이후 ZOOTER를 효율적인 LLM 앙상블 방법으로 소개합니다(§3.2).
3.1 LLM의 상호보완적 잠재력
이 섹션에서는 기성 LLM이 다양한 도메인과 주제에서 이종적 전문성을 보유하고 있다는 가정에 대한 기본 개념을 설명합니다. 또한, 두 가지 LLM 앙상블 전략인 보상 모델 순위 매기기(Reward Model Ranking, RMR)와 질의 라우팅(Query Routing)을 간단히 소개합니다.
상호보완적 잠재력 가정 (Complementary Potential Assumption)
LLM 집합 와 다운스트림 질의 집합 가 주어졌을 때, MM에 속한 각 에 대해 가 에서 다른 모든 LLM보다 일관되게 더 나은 성능을 낼 수 있는 비공집합(non-empty subset)이 존재한다고 가정합니다. 이는 다음과 같은 관계를 만족합니다:
여기서 P는 성능을 평가하기 위한 임의의 선호도(preference) 또는 지표(metric)를 나타냅니다. 본 연구에서는 이러한 가정을 더욱 강화하여 LLM 간의 상호보완성이 서로 다른 도메인 및 작업에서의 전문성을 드러낸다는 것을 보이고, 이를 통해 질의를 분류하고 각 범주에 최적의 LLM을 선택할 수 있음을 목표로 합니다.
보상 모델 순위 매기기 (Reward Model Ranking)
RMR은 LLM의 상호보완적 잠재력을 활용하여 앙상블 성능을 극대화하는 방법입니다. RMR은 보상 함수 를 사용하여 각 질의에 대해 최적의 모델을 선택하도록 추정합니다(Jiang et al., 2023). 그러나 RMR은 모든 후보 모델에서 출력을 생성한 후 이를 순위 매기는 방식이므로 상당한 계산 비용을 초래합니다.
질의 라우팅 (Query Routing)
질의 라우팅은 기존 RMR 방법에 비해 효율성 문제를 완화합니다. 일반적으로 질의 라우팅은 다음과 같은 라우팅 함수 를 찾으려고 합니다:
라우팅 함수는 출력 생성 없이 질의를 기반으로 질의를 분배합니다. LLM의 상호보완적 잠재력이 성립한다면, 라우팅 함수는 질의 가 특정 LLM의 전문성 집합 에 속할 확률을 예측합니다.
3.2 ZOOTER
ZOOTER는 효율적인 LLM 앙상블을 위해 보상에 기반한 질의 라우팅 방법입니다. ZOOTER는 보상 모델 순위 매기기를 학습하여 각 모델의 잠재적 전문성을 해석합니다.
ZOOTER 구조 및 작동 방식
ZOOTER는 다음과 같은 과정을 통해 작동합니다(그림 2 참조):
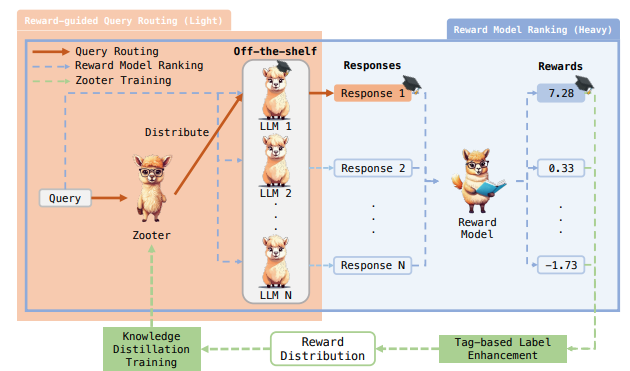
- 학습 단계:
- 다양한 질의를 포함한 학습 세트에서 모든 후보 LLM이 응답을 생성하도록 합니다.
- 생성된 응답에 대해 기성 보상 모델을 사용해 스칼라 보상을 부여합니다(파란색 점선).
- 태그 기반 선행 정보(tag-based prior)를 활용하여 보상을 부드럽게 하고 잡음을 제거합니다.
- 정규화된 보상 분포를 지식 증류(knowledge distillation) 학습의 감독 신호로 사용합니다(녹색 점선).
- 추론 단계:
- 라우팅 함수는 입력 질의를 가장 적합한 전문성을 가진 LLM으로 분배합니다.
- 선택된 LLM이 전문적인 응답을 생성합니다.
ZOOTER는 라우팅 함수의 소량 계산 오버헤드만 추가적으로 요구하며, 단일 LLM만 추론하기 때문에 계산 효율성이 뛰어납니다.
핵심 구성 요소
-
보상 증류 (Reward Distillation):
질의 라우팅은 질의 q가 특정 LLM의 전문성 집합 Q_m에 속할 확률을 예측하는 라우팅 함수 Z를 학습하는 것을 목표로 합니다. 이를 위해 정규화된 보상을 사용하여 다음과 같이 라우팅 함수를 정의합니다:
- 여기서, 는 특정 질의와 모델 에 대한 보상 값을 나타냅니다.
- 학습 손실은 Kullback-Leibler 발산(KL-divergence)으로 정의됩니다:
-
태그 기반 레이블 강화 (Tag-based Label Enhancement):
보상 증류 과정에서 보상 모델의 불확실성으로 인해 잡음이 발생할 수 있습니다(Gleave and Irving, 2022). 이를 완화하기 위해 질의에 태그를 부여하고, 태그별 보상(tag-wise rewards)을 다음과 같이 계산합니다:
- 각 질의의 보상은 태그 기반 보상과 샘플 수준 보상의 선형 결합으로 강화됩니다:
- 강화된 보상 는 KL 발산 손실 학습에 사용됩니다.
- 각 질의의 보상은 태그 기반 보상과 샘플 수준 보상의 선형 결합으로 강화됩니다:
이러한 설계를 통해 ZOOTER는 LLM 앙상블의 효율성을 높이고, 보다 다양한 작업에서 전문성을 효과적으로 활용할 수 있습니다.
4 실험 (Experiments)
이 섹션에서는 실험 설정(§4.1), 주요 결과(§4.2), ZOOTER 분석(§4.3)을 보고합니다.
4.1 실험 설정 (Experimental Setup)
후보 LLMs
질의 라우팅을 위해 동일한 13B 크기의 LLAMA 기반 LLM 6개를 선택했습니다.
(a) WizardLM: EVOLINSTRUCT로 확장된 질의 및 응답으로 정렬된 모델(Xu et al., 2023).
(b) WizardCoder: WizardLM과 동일한 기술을 사용하여 코딩 전문가로 정렬된 LLM(Luo et al., 2023b).
(c) WizardMath: 수학 전문가 모델로, 질의 증강, ChatGPT 보상 및 PPO 최적화로 정렬(Luo et al., 2023a).
(d) Vicuna: 사용자와 독점 챗봇 간의 대규모 대화 데이터를 사용해 정렬(Chiang et al., 2023).
(e) OpenChat: ShareGPT 데이터 세트의 선택된 데이터와 추가 학습 전략으로 정렬(Wang et al., 2023a).
(f) Llama-2-Chat: 감독 학습과 다중 회차 거절 샘플링으로 정렬(Touvron et al., 2023b).
ZOOTER와 기존 방식 모두 이 6개의 후보 모델을 기반으로 실험 및 평가를 수행했습니다.
학습 데이터셋
ZOOTER의 일반화 능력을 극대화하기 위해 오픈소스 데이터를 활용한 다양한 명령어 데이터셋을 생성했습니다.
- Lu et al. (2023)이 개발한 로컬 태거를 사용하여 13개의 데이터셋에서 오픈소스 데이터를 수집하고 태깅.
- 평가의 신뢰성을 위해, 벤치마크와 6그램 중복(overlap)이 있는 샘플을 제거하여 데이터 누출 방지.
- 고유 태그당 10개의 샘플을 랜덤 선택하여 47,986개의 명령어와 6,270개의 태그를 포함하는 DIVINSTRUCT 데이터셋 생성.
세부 통계는 부록(Appx. §A)에 포함되어 있습니다.
벤치마크
ZOOTER를 다양한 다운스트림 작업에서 종합적으로 평가하기 위해 네 가지 벤치마크 그룹을 포함했습니다.
- 정렬 벤치마크 (GPT-4 평가 포함)
- AlpacaEval: Koala, Vicuna 등에서 5개의 하위 집합으로 구성, 805개 샘플 포함(Li et al., 2023b).
- FLASK: 10개의 도메인에서 정렬을 세밀하게 평가(Ye et al., 2023).
- MT-Bench: 수학 및 코딩을 포함한 8가지 측면에서 다중 회차 평가(Chiang et al., 2023).첫 번째 회차 질의로 학습 및 라우팅을 수행하고 다중 회차 방식으로 평가.
- 추가 벤치마크 (인간 평가 포함)
- MMLU (Hendrycks et al., 2021): 다양한 과목에서 다중 선택 테스트.
- GSM8K (Cobbe et al., 2021): 초등학교 수준의 수학 문제.
- HumanEval (Chen et al., 2021): 코드 생성 평가.
평가지표 (Metrics)
다양한 벤치마크의 점수 범위가 다르므로, 다음 두 가지 지표를 사용했습니다.
-
평균 작업 순위(MTR): 모든 하위 집합에서 모델의 평균 순위를 나타냄. 낮을수록 좋음.
-
향상률(Uplift Rate): 벤치마크 하위 집합에서 평가된 모델이 최고 성능을 달성한 비율. 높을수록 좋음.
총 26개 평가 하위 집합에서 이 두 지표를 보고했습니다.비교군 (Baselines)
ZOOTER를 기존의 보상 모델 순위 매기기(RMR) 방법과 비교했습니다.
- 최신 RMR 모델: OASSISTRM, AUTO-J (Li et al., 2023a), ULTRARM (Cui et al., 2023), QWENRM (Bai et al., 2023), Oracle 순위.
- LLM-Blender(Jiang et al., 2023)의 페어 순위 매기기를 RMR 방법 중 하나로 고려.
- GPT-3.5-turbo 및 GPT-4와 같은 독점 모델의 성능도 참조로 보고.
구성 (Configurations)
- 라우팅 함수는 mdeberta-v3-base를 기반으로 학습.
- QwenRM으로 학습 질의에 보상을 생성하여 라우팅 함수의 감독 신호로 사용.
- 8개의 A100 GPU에서 모든 학습 및 추론 실행.
- MMLU, GSM8K, HumanEval에서 탐욕 디코딩(greedy decoding) 사용.
결과 및 분석
다음 섹션에서는 주요 결과와 ZOOTER의 성능 분석을 보고합니다.
4.2 결과 (Results)
주요 결과 요약
표 1에서 주요 결과를 제시합니다. 우리는 6개의 라우팅 후보 모델의 성능을 벤치마크에서 평가했으며, 평균적으로 가장 우수한 모델(BMA)은 LLAMA-2-CHAT로 나타났습니다. ZOOTER는 태그 기반 레이블 강화에서 β=0.3\beta = 0.3을 사용하여 평가되었습니다. 결과는 두 가지 측면에서 분석됩니다.
상호보완적 잠재력 (Complementary Potential)
우리는 5개의 기성 보상 모델을 사용한 보상 모델 순위 매기기(RMR)를 평가했습니다.
- UltraRM: 모든 벤치마크에서 가장 우수한 성능을 기록하며, 평균 작업 순위(MTR)는 1.53으로, 전체 하위 작업의 72%에서 최고 성능을 달성.
- QwenRM: UltraRM과 유사한 성능을 보여주었으며, 파라미터 크기가 더 작아 효율적.
- 그 외 Auto-J, LLM-Blender, OAssistRM 순으로 성능을 보임.
- Oracle ranker: 모든 후보 모델 및 GPT-4를 초과하는 성능을 보여줌.
이 결과는 기성 LLM의 상호보완적 잠재력을 강력히 뒷받침하며, ZOOTER가 기성 보상 모델에서 은(銀) 감독 신호를 학습하여 라우팅 함수를 훈련한다는 핵심 동기를 뒷받침합니다. 그러나 RMR은 MMLU, GSM8K, HumanEval과 같은 특정 벤치마크에서 한계를 보였으며, 이는 지식, 수학, 코딩 문제의 정확한 판단이 여전히 어려움을 겪고 있음을 나타냅니다.
ZOOTER 성능 (Zooter Performance)
- BMA 대비 성능: ZOOTER는 AlpacaEval, MT-Bench, Benchmarks에서 BMA를 초과하며, FLASK에서는 유사한 성능을 달성.
- MT-Bench에서의 향상: ZOOTER는 BMA 대비 0.39 더 높은 성능을 보임.
- 상위 1위 비율: ZOOTER는 44%의 하위 작업에서 상위 1위를 달성, BMA는 31%에 그침.
- 효율성: ZOOTER는 86M의 라우팅 함수만 추가적으로 사용하여 계산 오버헤드를 크게 줄임.
ZOOTER는 OAssistRM, LLM-Blender, Auto-J를 사용한 RMR 대비 계산 오버헤드에서 더 우수하며, AlpacaEval에서 QwenRM 기반 RMR보다도 성능이 우수했습니다. 그러나, 전반적으로 ZOOTER와 QwenRM 기반 RMR 간에는 여전히 격차가 존재합니다.
4.3 분석 (Analysis)
보상 모델의 불확실성 (RM Uncertainty)
- 불확실성 존재: RM의 스칼라 보상에는 불확실성이 포함될 수 있으며, 이는 라우팅 훈련 시 잡음을 유발할 가능성이 있습니다.
- MT-Bench 분석: QwenRM의 보상 엔트로피(entropy)와 MT-Bench 점수 간의 관계를 분석한 결과, 낮은 보상 엔트로피를 가진 샘플이 더 높은 점수를 보이는 경향을 확인.
- 태그 기반 레이블 강화의 필요성: 높은 엔트로피는 보상에 대한 불확실성을 나타내며, 이는 태그 기반 선행 정보를 사용하여 조정할 필요성을 설명합니다.
레이블 강화 (Label Enhancement)
- β\beta 조정: 태그 기반 레이블 강화에서 β\beta는 샘플 수준 보상과 태그 수준 보상 간의 균형을 나타내는 하이퍼파라미터.
- : 모든 벤치마크에서 가장 우수한 성능을 기록.
- 샘플 수준 보상()만 사용하는 경우 태그 수준 보상()에 비해 성능이 저하됨.
- 결론: 태그 기반 레이블 강화는 보상 증류 성능을 향상시키며, RM의 불확실성으로 인한 잡음을 효과적으로 완화함.
5 결론 (Conclusion)
본 연구에서는 오픈소스 LLM의 상호보완적 잠재력과 기성 보상 모델의 보상 모델 순위 매기기를 재검토하며, LLM 앙상블의 효과를 입증했습니다. 우리는 ZOOTER라는 효율적인 보상 기반 라우팅 방법을 제안하여, 기성 LLM을 조합하는 데 활용했습니다.
종합적인 평가 결과, ZOOTER는 평균적으로 단일 최고 성능 모델을 초과했으며, 보상 모델 순위 매기기를 사용한 앙상블 모델조차도 상당히 적은 계산 오버헤드로 능가할 수 있음을 보여주었습니다.
앞으로의 연구 방향으로는 각 LLM의 잠재적 전문성을 심층적으로 해석하는 데 중점을 두는 것이 가치 있을 것입니다.
