https://arxiv.org/pdf/2406.15319
요약
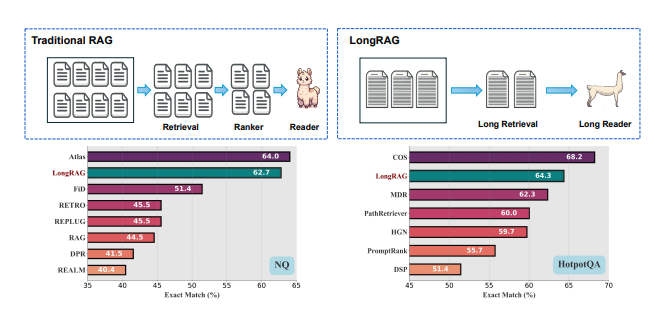
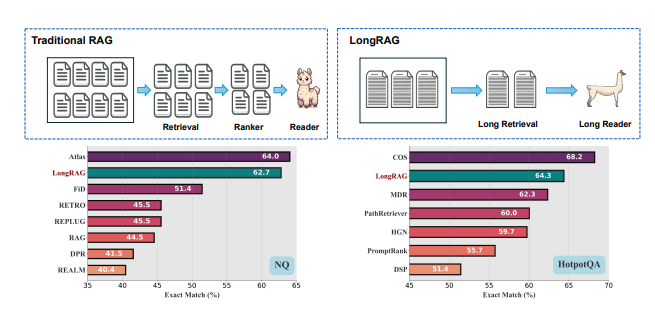
전통적인 RAG(검색 보강 생성) 프레임워크에서 기본 검색 단위는 일반적으로 짧습니다. 일반적인 검색기(DPR 등)는 보통 100단어 정도의 Wikipedia 문단과 함께 작동합니다. 이러한 설계는 검색기가 방대한 말뭉치에서 "바늘" 같은 단위를 찾아야 하게 만듭니다. 반면, 독자는 짧게 검색된 단위에서 답을 생성하기만 하면 됩니다. 이처럼 불균형한 '무거운' 검색기와 '가벼운' 독자 설계는 최적화되지 않은 성능으로 이어질 수 있습니다. 짧은 단위의 문맥 정보 손실은 검색 단계에서 잘못된 부정적인 결과(정확한 정보가 아닌 정보를 포함) 발생 가능성을 높일 수 있습니다. 또한, 독자는 최근 LLM(대형 언어 모델) 기술의 발전을 충분히 활용하지 못할 수 있습니다. 이러한 불균형을 완화하기 위해, 우리는 새로운 프레임워크인 LongRAG을 제안합니다. 이는 '긴 검색기'와 '긴 독자'로 구성됩니다. 두 개의 Wikipedia 기반 데이터셋(NQ와 HotpotQA)에서 LongRAG는 관련된 문서들을 그룹화하여 단위를 기존보다 30배 길게(4,000 토큰 단위) 처리하여 Wikipedia 말뭉치를 구성합니다. 이로 인해 총 단위 수가 2,200만 개에서 60만 개로 크게 줄어듭니다. 이렇게 단위 크기를 증가시킴으로써 검색기에서 필요한 총 단위 수를 줄이고, 단 몇 개의 상위 단위(8개 미만)를 사용하여 강력한 검색 성능을 달성합니다. 전통적인 RAG와 비교했을 때, 수백 개의 짧은 단위가 필요한 것과 달리 우리의 접근 방식은 검색 단계에서 잘못된 부정적인 결과를 최소화하고 각 단위의 의미적 무결성을 유지합니다. 그런 다음, 이 검색된 단위(약 3만 토큰)를 기존의 긴 문맥 LLM에 입력하여 제로샷 방식으로 답을 생성합니다. 추가 훈련 없이 LongRAG는 NQ에서 62.7%, HotpotQA에서 64.3%의 EM(정확도)를 달성하여 기존의 최첨단(SoTA) 모델과 견줄만한 성능을 보여줍니다.
1. 서론 (Introduction)
검색 보강 생성(Retrieval-Augmented Generation, 이하 RAG) 방식은 외부 지식 기반을 검색하고, 이를 대규모 언어 모델(LLM)의 답변 생성 과정에 활용하여 성능을 개선하는 방법입니다. 기존 RAG의 검색 방식은 일반적으로 매우 짧은 단위의 텍스트에 의존합니다. 예를 들어, 기존의 DPR(Dense Passage Retriever)은 Wikipedia의 약 100단어로 구성된 짧은 문단을 검색합니다. 이 방식에서는 검색기(retriever)가 방대한 말뭉치에서 매우 짧은 "바늘" 같은 정보를 찾아내야 합니다. 이에 반해 생성기(reader)는 이 짧은 단위에서 답을 생성해야 합니다.
이처럼, 검색기와 생성기의 역할이 서로 불균형하게 설계되어 있을 경우 최적화되지 않은 성능으로 이어질 수 있습니다. 특히 짧은 문맥 정보가 손실되는 상황에서는 검색 과정에서 잘못된 부정적인 결과(hard negatives)가 발생할 가능성이 커집니다. 또한, 최근 대형 언어 모델(LLM)의 발전에도 불구하고, 생성기가 짧은 단위에서만 정보를 얻기 때문에 대형 언어 모델이 충분한 성능을 발휘하지 못하는 경우도 많습니다.
이러한 문제를 해결하기 위해, 우리는 LongRAG이라는 새로운 프레임워크를 제안합니다. LongRAG는 '긴 검색기(long retriever)'와 '긴 생성기(long reader)'로 구성되어 있습니다. 이 프레임워크는 검색 과정에서 매우 짧은 단위 대신 긴 문서 전체 또는 문서 그룹을 검색함으로써 검색기의 부담을 줄이고, 생성기가 긴 문맥을 다루는 능력을 최적화할 수 있습니다.
두 개의 Wikipedia 기반 데이터셋(NQ와 HotpotQA)에서 LongRAG는 관련 문서들을 그룹화하여 단위의 길이를 기존보다 30배 늘린 4,000 토큰 단위로 처리합니다. 이를 통해 Wikipedia 말뭉치의 총 단위 수를 약 2,200만 개에서 60만 개로 줄일 수 있었습니다. 이렇게 단위 크기를 늘림으로써 검색기는 적은 수의 상위 단위(8개 이하)만으로도 강력한 성능을 낼 수 있으며, 검색 단위 내의 의미적 무결성을 유지할 수 있습니다. 또한, 검색된 긴 문맥(약 30,000 토큰)은 기존의 긴 문맥을 처리할 수 있는 LLM에 입력되어 답을 생성하는 데 사용됩니다.
LongRAG는 추가적인 훈련 없이도 NQ에서 62.7%, HotpotQA에서 64.3%의 EM(정확 일치, Exact Match) 점수를 기록하였습니다. 이는 기존 최첨단(SoTA) 모델과 유사한 성능을 달성한 것입니다.
2. 관련 연구 (Related Work)
2.1 검색 보강 생성 (Retrieval-Augmented Generation)
RAG는 정보 검색과 대형 언어 모델(LLM)을 결합하여 질문 응답, 요약, 번역 등의 작업에서 성능을 향상시키는 방법입니다. 기존의 RAG 모델은 대규모 외부 지식 기반(예: Wikipedia)에서 관련 문서를 검색한 후, 이를 바탕으로 답변을 생성합니다. 이러한 방식은 기존의 언어 모델이 보유한 지식 기반을 넘어서는 답변을 생성할 수 있도록 도와줍니다.

하지만 기존 RAG는 보통 검색 단위가 매우 짧습니다. 예를 들어, 검색 모델인 DPR은 Wikipedia에서 100단어 정도의 문단을 검색합니다. 이처럼 짧은 검색 단위는 검색기가 방대한 말뭉치에서 필요한 정보를 찾는 과정에서 부정확한 부정 예시(hard negatives)가 발생할 가능성을 높입니다. 검색기의 부정확성이 높아질수록 생성 모델이 정확한 답변을 생성하는 데 필요한 정보가 부족해질 수 있습니다.
2.2 긴 문맥 처리
기존의 RAG 모델은 짧은 문맥에서 매우 효과적이지만, 긴 문맥을 처리할 때는 한계가 명확합니다. 최근에는 더 긴 문맥을 처리할 수 있는 대형 언어 모델(LLMs)이 등장했으며, 이들은 한 번에 수천 개의 토큰을 다룰 수 있는 능력을 갖추고 있습니다. 하지만 기존 RAG 구조에서는 이러한 긴 문맥 처리 능력을 충분히 활용하지 못합니다.
기존의 연구들은 주로 긴 문맥 처리의 중요성을 강조하며, 긴 문맥을 더 효율적으로 다룰 수 있는 방법을 모색하고 있습니다. Longformer, BigBird, Transformer-XL 등의 연구는 더 긴 문맥을 다루기 위한 구조적 변화를 제안한 바 있습니다..
3. LongRAG: 긴 문맥을 처리하는 새로운 프레임워크 (LongRAG: A New Framework for Long Context Processing)
LongRAG는 기존의 RAG 구조에서 긴 문맥을 처리하는 능력을 향상시키기 위해 설계된 새로운 프레임워크입니다. 긴 문맥을 처리하기 위한 두 가지 주요 구성 요소는 긴 문서를 검색할 수 있는 긴 검색기(long retriever)와 긴 문맥을 다루는 긴 생성기(long reader)입니다.
3.1 긴 검색기 (Long Retriever)
기존 RAG에서 검색기는 보통 매우 짧은 텍스트 단위, 예를 들어 100단어 정도의 짧은 문단을 검색합니다. 하지만 이는 긴 문맥을 요구하는 질문에 충분한 정보를 제공하기 어렵습니다. LongRAG는 이러한 문제를 해결하기 위해, 기존의 짧은 검색 단위 대신 긴 단위의 문서나 문서 그룹을 검색하여 훨씬 많은 정보를 검색할 수 있습니다.
우리는 긴 검색기를 통해 단위당 약 4,000개의 토큰을 포함하는 긴 문서를 검색할 수 있습니다. 이렇게 검색 단위의 크기를 확장함으로써 검색기가 적은 수의 문서만으로도 더 많은 정보를 제공할 수 있게 됩니다. 기존에는 수백 개의 짧은 문단을 검색해야 했지만, 이제는 8개 이하의 긴 문서만으로도 충분한 검색 결과를 얻을 수 있습니다.
긴 검색 단위를 활용하면 검색기의 작업 부담이 크게 줄어들고, 검색 과정에서 발생할 수 있는 잘못된 부정적인 결과(hard negatives)도 감소시킬 수 있습니다. 또한, 각 검색 단위 내에서 의미적 일관성을 유지할 수 있어, 더 정확한 문맥 정보를 생성 모델에 제공할 수 있습니다.
3.2 긴 생성기 (Long Reader)
긴 검색기에서 검색된 문서들은 긴 생성기에 전달되어 답변을 생성합니다. 기존의 생성 모델은 짧은 문맥을 기반으로 답변을 생성했지만, 긴 생성기는 수천 개의 토큰을 한 번에 처리할 수 있습니다. 이를 통해 더 많은 문맥 정보를 바탕으로 정확하고 일관된 답변을 생성할 수 있습니다.
LongRAG에서 긴 생성기는 제로샷(Zero-shot) 설정에서도 뛰어난 성능을 발휘합니다. 제로샷 설정이란, 모델이 특정 작업에 대해 별도의 추가 학습 없이도 해당 작업을 수행할 수 있는 능력을 의미합니다. 우리는 긴 생성기를 통해 NQ(Natural Questions)와 HotpotQA 데이터셋에서 별도의 훈련 없이도 매우 좋은 성능을 확인할 수 있었습니다.
4. 실험 (Experiments)
우리는 LongRAG의 성능을 검증하기 위해 두 가지 주요 데이터셋을 사용했습니다: Natural Questions(NQ)와 HotpotQA. 이 두 데이터셋은 대규모 질문 응답 작업에 널리 사용되며, 특히 긴 문맥을 처리해야 하는 복잡한 질문들이 포함되어 있습니다.
4.1 데이터셋 (Datasets)
- Natural Questions (NQ): NQ는 Google에서 제공하는 대규모 질문 응답 데이터셋으로, Wikipedia 문서에서 관련 정보를 검색하여 자연어로 답을 생성하는 작업에 사용됩니다. NQ는 정답이 짧은 문장일 수 있지만, 이를 도출하기 위해서는 긴 문맥을 고려해야 하는 경우가 많습니다.
- HotpotQA: HotpotQA는 다수의 문서에서 정보를 통합하여 복잡한 질문에 답을 제공하는 질문 응답 데이터셋입니다. 이 데이터셋에서는 단순히 하나의 문서에서 답을 찾는 것이 아니라, 여러 문서 간의 정보 연결을 요구합니다. 따라서, 긴 문맥을 처리할 수 있는 능력이 매우 중요합니다.
4.2 실험 설정 (Experimental Setup)
우리는 LongRAG의 성능을 평가하기 위해 기본적인 제로샷(Zero-shot) 설정을 사용했습니다. 즉, LongRAG는 추가적인 훈련 없이 두 데이터셋에서 성능을 평가받았습니다. 또한, 우리는 LongRAG가 기존의 RAG 모델과 비교하여 얼마나 더 뛰어난 성능을 발휘하는지 분석했습니다.
4.3 결과 (Results)
- NQ 데이터셋에서 LongRAG는 62.7%의 정확 일치(Exact Match, EM) 점수를 기록했습니다. 이는 기존 최첨단(SoTA) 모델들과 견줄 만한 성능입니다.
- HotpotQA 데이터셋에서도 LongRAG는 64.3%의 EM 점수를 기록하며, 역시 기존 최첨단 모델들과 유사한 성능을 보여주었습니다.
이 실험 결과는 LongRAG가 긴 문맥을 처리하는 데 매우 효과적이며, 기존 모델들의 성능을 향상시킬 수 있음을 보여줍니다.
5. 결론 (Conclusion)
이 논문에서는 검색 보강 생성(RAG) 모델을 개선하기 위해 LongRAG 프레임워크를 제안했습니다. LongRAG는 긴 검색기와 긴 생성기를 활용하여 긴 문맥을 처리할 수 있는 능력을 극대화하였습니다. 이를 통해, 긴 문서나 다수의 문서를 검색하고, 생성 과정에서 문맥 정보의 손실을 줄이며 더 정확한 답변을 생성할 수 있었습니다.
실험 결과, LongRAG는 NQ와 HotpotQA 데이터셋에서 기존 최첨단 모델들과 유사한 성능을 보여주었으며, 별도의 추가 훈련 없이도 우수한 성능을 발휘했습니다.
향후 연구는 LongRAG의 성능을 더욱 향상시키기 위해 다양한 데이터셋과 응용 분야에서 LongRAG를 테스트하는 방향으로 진행될 것입니다. 특히, 긴 문맥을 처리하는 능력이 중요한 분야에서 LongRAG는 매우 유용하게 사용될 수 있을 것으로 기대됩니다.
