https://arxiv.org/pdf/2501.13726
요약
RAG(Retrieval-Augmented Generation)는 외부 지식을 활용하는 데 있어 가능성을 보여주었지만 생성 프로세스는 검색된 컨텍스트의 품질과 정확성에 크게 좌우됩니다. 대규모 언어 모델(LLMs)은 내부 암기와 다를 때 외부에서 검색된 비모수적 지식의 정확성을 평가하는 데 어려움을 겪기 때문에 응답 생성 중에 지식 충돌이 발생합니다. 이를 위해 검색 관련성을 기반으로 다중 소스 지식을 적응적으로 활용하기 위한 가볍고 효과적인 정렬 방법인 RPO(Retrieval Preference Optimization)를 도입합니다. 검색 관련성에 대한 암시적 표현이 파생되고 보상 모델에 통합되어 검색 평가 및 응답 생성을 단일 모델로 통합함으로써 이전 방법에서 검색 품질을 평가하기 위해 추가 절차가 필요하다는 문제를 해결합니다. 특히 RPO는 수학적 장애물을 극복하고 교육에서 검색 관련성에 대한 인식을 정량화하는 유일한 RAG 전용 정렬 접근 방식입니다. 4개의 데이터 세트에 대한 실험은 RPO가 추가 구성 요소 없이 정확도에서 RAG를 4-10% 능가한다는 것을 보여주며 강력한 일반화를 보여줍니다.
소개
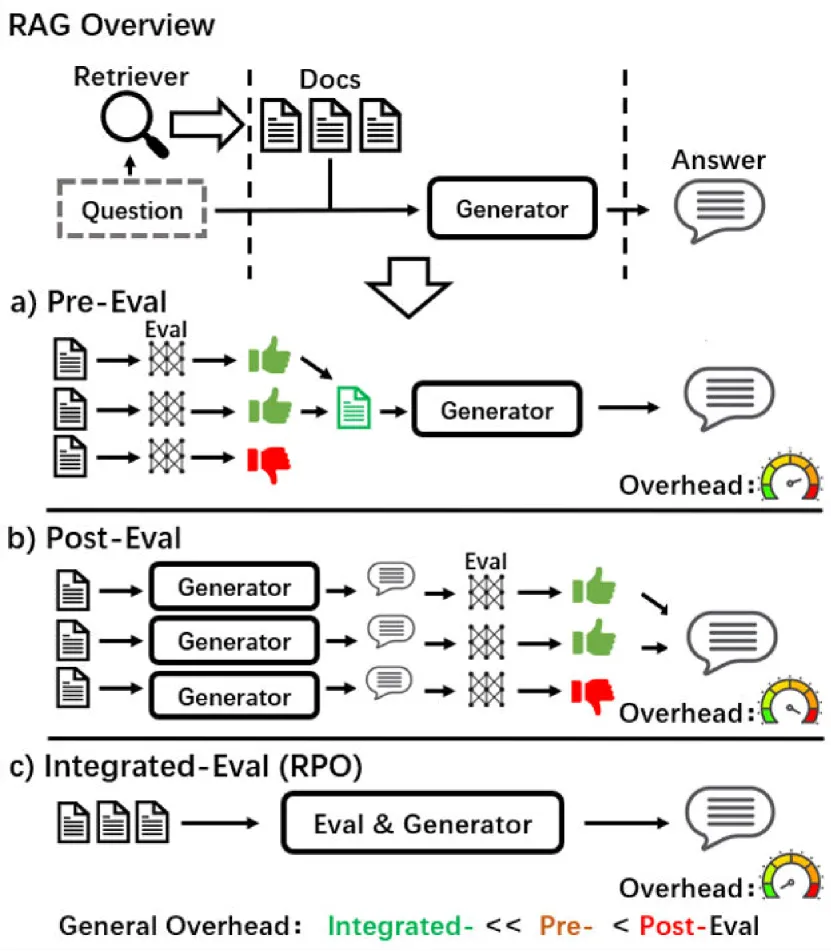
그림 1 : 이 그림은 RAG의 개요와 a) Pre-Eval, b) Post-Eval 및 c) Integrated-Eval 접근 방식을 포함한 적응형 RAG의 세 가지 범주를 보여줍니다. 세 가지 범주의 추정된 계산 오버헤드도 시연되어 추론에서 RPO의 효율성을 보여줍니다.
자연어 처리 작업에 광범위하게 적용됨에도 불구하고 대규모 언어 모델(LLMs)은 여전히 지식 집약적인 작업에 어려움을 겪고 있습니다(Guu et al., 2020; Lewis et al., 2020a)를 참조하십시오. 일반적이고 효과적인 접근 방식으로, 검색 증강 발전(RAG)(Lewis et al., 2020b; Izacard and Grave, 2021)에는 외부 말뭉치에서 입력 쿼리와 관련된 컨텍스트를 검색하고 생성을 위해 통합하는 작업이 포함됩니다.
그러나 RAG는 검색에 과도하게 의존할 가능성이 있는 것으로 밝혀졌으며, 특히 비모수적 지식이라고도 하는 검색된 정보가 그 안에 LLMs 포함된 모수적 지식과 충돌할 때 무의식적으로 환각으로 이어질 수 있습니다(Longpre et al., 2021; Xu et al., 2024)을 참조하십시오. 특히, RAG는 갈등이 발생할 때 내부 지식보다 검색된 외부 맥락을 우선시하는 경향이 있습니다(Zou et al. (2024). Xiang 외 . (2024); Yan 외 . (2024). 따라서 RAG의 성능은 검색 프로세스의 정확성에 크게 좌우되며, 부정확한 검색은 관련이 없거나 심지어 유해한 정보를 도입하여 생성된 텍스트의 품질에 영향을 미칠 수 있습니다(Shi et al., 2023; Rony et al., 2022)를 참조하십시오. 이 문제를 해결하기 위해 이전 연구에서는 생성 전(평가 전) 또는 생성 후(평가 후)의 검색 품질을 평가했습니다. 그러나 그림 1에서 볼 수 있듯이 적응형 RAG라고 하는 이러한 접근 방식은 여러 API 또는 LLM 호출을 통해 검색 가치를 평가하기 위해 추가 처리가 필요하므로 막대한 컴퓨팅 오버헤드가 발생합니다. 한편, 평가자가 평가한 부정적 컨텍스트의 일부를 제거하면 생성을 위해 제공되는 정보가 줄어듭니다. 이는 생성기를 평가자에 더 의존하게 만들어 최종 성능에도 영향을 미칩니다.
위와 같은 문제점을 고려하여, 본 논문에서는 강화학습(reinforcementlearning)을 통해 생성 시 검색 평가를 통합함으로써 다중 소스 지식에 LLM 대한 견고성을 향상시키는 것을 목표로 하는 R etrieval Preference Optimization 알고리즘인 RPO를 제안한다. 이전 선호도 최적화 알고리즘의 기술적 한계를 강조하기 위해 먼저 포괄적인 이론적 분석을 수행합니다(Ouyang et al., 2022; Rafailov 외 , 2023; Zhang et al., 2024)을 RAG 시나리오의 맥락에서 볼 수 있습니다. 우리는 검색 전후에 정답을 선택하는 적응형 RAG의 목표를 위반하는 이전 방법의 한계를 수학적으로 증명합니다. 파라메트릭 지식과 비파라메트릭 지식 사이에 갈등이 관련되어 있을 때, 검색된 지식에 대한 과잉 경향은 생성 중에 여전히 쉽게 발생합니다. 이 이론을 바탕으로 RPO 조정 방법은 검색 관련성에 대한 인식을 보상 모델에 통합하여 검색에 대한 과도한 의존도를 완화하도록 설계되었습니다. 충돌 완화 기능을 강화하기 위해 RPO는 지식 충돌을 시뮬레이션하고 우선 순위를 지정할 지식 유형에 LLM 대한 식별을 수정합니다. 먼저, 우리는 검색이 있는 경우와 없는 경우를 각각 찾아내도록 지시하고, 모순되는 사례를 지식 충돌로 필터링하도록 지시 LLM 했습니다. 그 동안, 검색된 컨텍스트의 관련성은 정량화되고 암시적으로 표현됩니다. 궁극적으로, 계산된 관련성은 검색의 품질에 따라 모순된 쌍의 긍정적인 대답을 적응적으로 보상하기 위해 정렬을 위한 보상 모델에 통합됩니다.
그림 1에서 볼 수 있듯이 RPO(Integrated-eval)는 추가 오버헤드 없이 검색 품질 평가를 생성과 통합하여 상당한 효율성을 보여주었습니다. 한편, PopQA(Mallen et al., 2023), Natural Questions(Kwiatkowski et al., 2019), TriviaQA(Joshi et al., 2017) 및 RGB(Chen et al., 2024)의 4개 데이터 세트에 대한 결과는 RPO가 이전 접근 방식에 비해 RAG의 성능을 크게 향상시킬 수 있음을 보여주며 다양한 벤치마크에서 일관된 발전을 보여줍니다.
요약하면, 이 논문에서 우리가 기여하는 바는 세 가지입니다: 1) 우리는 검색된 컨텍스트를 동기적으로 평가하고 응답 생성 중 명시적인 처리 없이 비파라메트릭 지식을 선택적으로 활용하도록 장려 LLMs 하는 것을 목표로 하는 RPO라는 최적화 전략을 제안합니다. 2) RAG 기반 시나리오에서 직접 적용하기 위한 기존 선호도 최적화 전략의 부적절성을 강조하는 수학적 증거를 제공하고, 이러한 한계를 해결하기 위한 훈련을 위한 데이터 수집 방법과 보다 효율적인 알고리즘을 제안합니다. 3) 여러 LLMs 벤치마크를 포함한 실험을 통해 제안된 RPO 알고리즘의 효과를 검증하고 일관된 성능 향상을 보여줍니다.
2 관련 작품
적응형 RAG
기존 RAG(Lewis et al., 2020b) 애플리케이션에서는 비모수적 지식이라고 하는 검색된 컨텍스트가 에 저장된 파라메트릭 지식과 충돌할 수 있습니다LLMs. 이전 연구에서는 검색 품질 평가와 충돌 해결을 위한 비모수적 지식의 적응적 사용을 탐구했으며, 이는 일반적으로 평가 전 접근 방식과 평가 후 접근 방식으로 분류할 수 있습니다. 사전 평가 방법(Yoran et al., 2024; Yan 외 , 2024; Wang et al., 2024)에는 특수 분류 언어 모델(LM)을 사용하거나 검색 품질을 평가 LLMs 하도록 지시하는 것이 포함됩니다. 이에 반해 평가후방법(Asai et al., 2023; Xiang et al., 2024)은 검색된 다양한 문서를 기반으로 여러 응답을 독립적으로 생성하고 최상의 답변을 최종 응답으로 선택하는 것을 수반합니다. 그러나 한편으로는 두 접근 방식 모두 계산이 까다롭고 구조적으로 복잡하여 추론 효율성이 떨어집니다. 반면에 정보의 일부는 평가자에 의해 제거되므로 생성기는 평가자의 성능에 더 의존하게 되어 최종 성능에도 영향을 미칩니다.
모델 정렬
RLHF(Reinforcement Learning from Human Feedback) (Ouyang et al., 2022) 파이프라인을 검토할 때 SFT(supervised fine-tuning), 보상 모델 학습 및 RL 최적화의 세 가지 주요 단계가 포함됩니다. 사전 훈련된 LM을 미세 조정한 후 한 쌍의 답변이 샘플링되고 (y1,y2)∼πSFT(y∣x) 크라우드 워커는 로 표시된 쌍 중에서 선호하는 답변에 주석을 추가합니다 yw≻yl∣x . 잠재 보상 모델을 도입하고 나중에 학습하여 선호도를 정량화합니다. 궁극적으로 PPO(Proximal Policy Optimization) (Schulman et al., 2017) 알고리즘이 RL 최적화의 목표로 채택됩니다. 그 후, 가장 인기 있는 정렬 전략 중 하나인 DPO (Rafailov et al., 2023)는 외부 보상 모델을 폐쇄형 표현으로 대체하는 것을 포함합니다. 명시적인 보상 모델을 학습하는 대신, DPO는 최적의 정책과 함께 폐쇄형 표현식을 사용하여 보상 함수를 r 다시 매개변수화합니다. 계산이 용이한 접근 방식은 직접 RL 최적화의 필요성을 크게 없애고 기존 방법보다 성능이 뛰어납니다.
3작업 정의
3.1RAG 포뮬레이션
를 𝐃 LLM π 사용하여 데이터 세트의 질문에 x 답변하려면 RAG는 응답을 생성하기 전에 검색된 컨텍스트 R 를 보충 자료로 필요로 합니다. 대부분의 경우 시스템의 첫 번째 단계는 액세스 가능한 말뭉 ℂ 치에서 여러 관련 문서를 Dr={D1r,…DKr} 검색한 다음 생성에 대한 쿼리에 대한 추가 입력 역할을 하는 LLM 것입니다. 따라서 RAG 작업은 다음과 같이 단순화할 수 있습니다.
| (1) |
|---|
여기서 yn+p 는 검색된 결과, 즉 검색된 모든 컨텍스트 Dr 에 액세스할 수 있는 질문에 q 대한 답변을 의미합니다. LLMs 응답 생성을 위해 파라메트릭 또는 비파라미터 지식을 자율적으로 선택합니다.
3.2지식 충돌
검색된 정보를 통합하는 응답 외에도 π 실제로는 매개 변수에 기억된 지식과 함께 고유한 잠재적인 답변이 있습니다. 다음과 같이 표현 π 되는 답변을 생성하도록 직접 지시하여 활성화할 수 있습니다.
| (2) |
|---|
여기서 yp 는 검색된 컨텍스트가 없는 답, 즉 위의 방정식에 설정된 null을 의미하며, 에 대한 q 파라메트릭 지식이 있는 응답을 나타냅니다. 파라메트릭 지식과 검색된 비파라메트릭 지식이 다른 경우, 즉 지식 충돌이 발생하는 경우 RAG의 생성기는 참조할 지식을 결정해야 합니다. 검색된 컨텍스트의 지식이 채택되면 대답은 다양합니다 yp . 이 상황을 기반으로 비모수적 답변을 yn 필터링했습니다. yn+p 궁극적으로, 우리는 다음을 통해 지식 충돌을 감지하고 비모수적 답변을 필터링할 수 있습니다.
| (3) |
|---|
여기서 yn∈yn+p , 정답은 Acc(y)=1 로 공식화할 수 있으며, 오답은 Acc(y)=0 를 만족합니다. 따라서 Equ. (3)은 답 쌍 중 하나만 옳다는 것을 나타냅니다.
4 DPO가 RAG에 적용되도록 제한되는 이유
DPO(Rafailov et al., 2023)는 지식 충돌의 작업 요구 사항을 충족하는 선호도 쌍에서 선택된 항목 LLMs 과 정렬하여 세분화된 최적화에서 뛰어난 성능을 보여주었습니다. 그러나 RAG 기반 작업에 DPO를 적용하는 것과 관련하여 몇 가지 우려 사항이 있습니다.
첫째, RLHF와 DPO의 최적화 목표가 RAG의 충돌 완화 목표와 일치하지 않습니다.
RAG에 적용될 때 입력에서 통합된 검색된 컨텍스트를 고려할 때 RLHF 및 DPO의 궁극적인 최적화 목표는 다음과 같이 공식화할 수 있습니다.
| $maxπθ𝔼x∼𝐃,y∼πθ(y∣x)r(x,Dr,y)−β𝔻KL[πθ(y∣x,Dr) | πref(y∣x,Dr)],$ |
|---|
여기서 β 는 제어 하이퍼 매개 변수입니다. πθ trainable 정책과 reference 정책을 πref 각각 나타내며, 둘 다 πSFT 로 초기화되는 동안 πref 고정됩니다. 공식화의 마지막 항은 추가 제약 조건으로 채택되며, 이는 모델이 원래 분포에서 멀리 벗어나는 것을 방지하는 데 중요합니다. 그러나 RAG 응용 프로그램에서는 검색된 컨텍스트에 대한 과도한 경향으로부터 분포를 개선하기 위해 상당한 매개변수 조정이 LLMs 필요합니다. 예를 들어, 모수적 답이 선호되는 답인 경우 이상적인 분포는 와 정렬 πref(y∣x) 되어야 하고, 비모수적 답은 선호되며 목표 분포는 와 정렬 πref(y∣x,Dr) 되어야 합니다. 이전 최적화 전략의 제약 조건은 훈련 방법의 효율성과 성능에 영향을 미치며, 비모수적 답변에 대한 편향은 남습니다.
둘째, 보상 모델 내의 분할 함수는 취소할 수 없습니다.
DPO는 동일한 입력에 대해 높은 확률을 갖기 위해 긍정적 응답과 부정적 응답이 모두 필요로합니다 (즉, (yw,yl)∼πSFT(y∣x) logπSFT(yw∣x),logπSFT(yl∣x)>ϵ 는 정책의 출력 로그 확률 중 다소 높은 값 ϵ 입니다. DPO가 RAG에 직접 적용되는 경우 검색 Dr 의 존재를 고려하여 DPO 최적화 목표의 표현식은 다음과 같이 공식화할 수 있습니다.
| $ℒDPO(πθ;πref)=−𝔼(x,yw,yl)∼𝐃[logσ(βlogπθ(yw | xw)πref(yw | xw)−βlogπθ(yl |
|---|
여기서 xw=x 와 마지막 항은 파라메트릭 답이 양수일 때 양수이고, xw={x,Dr} 와 마지막 항은 비모수적 지식을 가진 답이 양수일 때 음수입니다. 자세한 증거는 부록 A.1에서 찾을 수 있습니다. 분명히 이 손실 함수는 partition 함수의 존재로 인해 계산하기가 복잡하고 비실용적입니다.
셋째, 비모수적 지식에 대한 과도한 경향은 여전히 불가피한데, 이는 모수적 답변이 훈련을 위해 조작되기 때문이다.
partition 함수의 문제로 인해 와 yp 의 yn 입력은 동일해야 하며, 이는 실제 응용 프로그램을 준수하지 않습니다. 이전 연구에서는 파라메트릭 답변을 조작하고 검색된 컨텍스트 (yn,yp)∼πSFT(y∣x,Dr) 로 생성된 것처럼 가장하려고 시도했습니다(Zhang et al., 2024). 그러나 조작된 답변과 원래 답변 간의 잠재적으로 심각한 불일치 가능성은 학습 중 수렴을 LLM 방해하여 차선의 결과로 이어질 수 있습니다. 예를 들어, 추론 단계의 상황은 인스턴스가 만족 (xinf,ypinf≻yninf) 하지만 최적화된 LLM 사람이 여전히 최종 응답으로 차선의 비모수적 답변을 선택하는 경우가 널리 존재합니다.
| (6) |
|---|
에퀴. (6)은 DPO가 훈련을 위해 수행됨에도 불구하고, 초기에 선호되는 답변과 선호되지 않는 답변 사이에 상당한 불일치가 존재하는 한 최적화된 정책이 여전히 선호되지 않는 답변을 응답으로 취하는 경향이 있음을 시사합니다. 자세한 증거는 부록 A.2에서 찾을 수 있습니다.
5 방법론
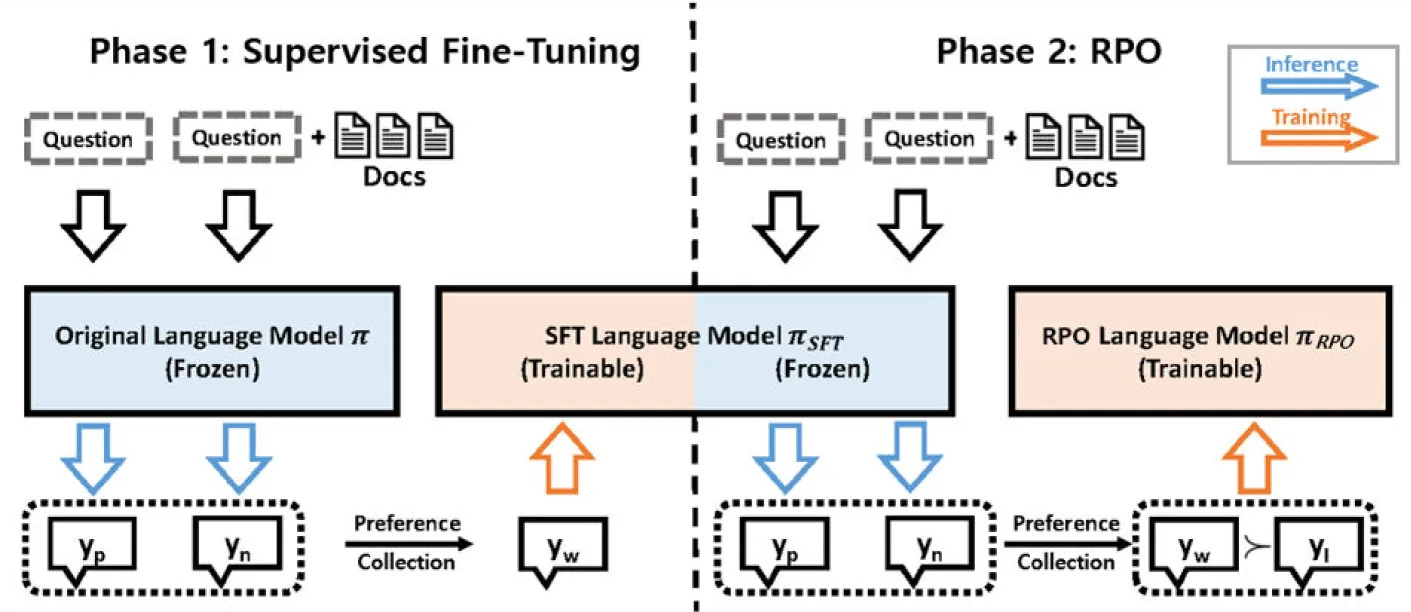
그림 2 : 교육에서의 RPO에 대한 개요입니다. 1단계에서는 질문과 검색된 문서가 주어지면 고정 언어 모델에 π 의해 두 개의 답변 (yp,yn) 이 생성됩니다. 주석이 달린 황금 답변과 비교한 후 지식 충돌과 관련된 인스턴스는 감독된 미세 조정을 위해 필터링됩니다. 2단계에서는 타인 튜닝된 LLM 사용자에게 한 쌍의 답변을 다시 생성하라는 메시지가 표시되고 지식 충돌이 있는 인스턴스는 RPO의 학습 세트로 필터링됩니다.
위에서 설명한 바와 같이 RAG에 대한 선호도 최적화를 구현할 때 발생하는 문제에 동기를 부여받은 이 연구는 정책 최적화를 위한 RAG별 접근 방식을 제안하는 것을 목표로 합니다. DPO의 강화 학습 목표와 RAG의 요구 사항 간의 불일치를 인정하고, 먼저 검색 품질에 LLM 따라 적응적 보상에 대한 검색 관련성 표현을 통합하여 새로운 강화 학습 목표를 제안합니다. 또한 실습 교육을 위해 지식 충돌을 시뮬레이션하기 위한 데이터 수집 및 필터링 전략을 간략하게 설명합니다.
5.1이론적 분석
보상 모델
Equ. (4)로 공식화된 강화 학습 목표가 RAG에서 충돌 완화 목표와 불일치를 보였기 때문에 RL 목표 표현을 수정하는 것이 가장 중요하고 중요합니다. 이 논문에서 우리는 주로 불일치가 검색 보상의 부재에 기인한다고 생각합니다. 이전의 연구들은 일반적으로 검색된 컨텍스트를 보상 모델을 구축하기 위한 입력의 고정된 부분으로 간주했습니다 (yw;yl)∣x,R . 그러나 전체 RAG 시스템의 관점에서 검색된 컨텍스트는 선호되는 샘플과 선호되지 않는 샘플 간에 일관된 입력 쿼리를 조건으로 하는 중간 변수일 뿐입니다. 따라서 RAG의 보상 모델은 선호하는 답변뿐만 아니라 선호하는 검색, 즉 (yw,Rw;yl,Rl)∣x . 궁극적으로 RL 목표는 다음과 같이 공식화할 수 있습니다.
| $maxπθ𝔼x∼𝐃,y∼πθ(y∣x,R)r(x,y,R)−β𝔻KL[πθ(y,R∣x) | πref(y,R∣x)].$ |
|---|
DPO 전략에서 보상 모델을 파생하는 것과 유사하게, RPO에서 보상 모델 공식을 얻을 수 있습니다.
| (8) |
|---|
여기서 Y(x) 는 partition 함수이며, 보상 모델에 대한 자세한 내용은 부록 A.3에서 확인할 수 있습니다.
길이 정규화
이전 연구에서는 DPO 동안 길이 편향에 의해 영향을 받는 경향 LLMs 을 관찰했습니다. RPO에서는 검색된 컨텍스트가 일반적으로 응답보다 훨씬 길기 때문에 검색된 컨텍스트의 길이가 보상 모델에 큰 영향을 미칠 수 있으며, 이로 인해 길이 편향이 높아질 수 있으며, 검색 인식 항의 과도한 영향을 완화하고 의 길이 편향LLMs을 극복하기 위해 평균 로그 확률을 보상의 일부로 활용했습니다. 보상 모델 표현에서 길이 정규화를 대체하면 궁극적인 RPO 훈련 목표는 다음과 같이 작성할 수 있습니다.
| $ℒRPO=−𝔼[logσ(βlogπθ(yw | x,Dr)πref(yw | x,Dr)⏟(a)preferred generation reward−βlogπθ(yl |
|---|
여기서 첫 번째 및 두 번째 항(Equ. (9a), (9b))은 각각 세대의 선호 및 선호되지 않는 보상을 나타내며, 이는 DPO와 일치합니다. 마지막 항 (Equ. (9c))은 검색된 컨텍스트의 보상을 나타내며, 이는 비모수적 답이 yn 파라메트릭 답에 대해 선호되는 경우 양수이고, 파라메트릭 답 yp 이 선호되는 경우(즉, yn≻yp )인 경우 음수입니다 yp≻yn .
5.2교육 개요
이 섹션에서는 SFT 및 기본 설정 최적화를 위해 데이터를 수집, 필터링 및 공식화하는 방법을 설명합니다. 그림 2와 알고리즘 1은 훈련 시 RPO의 개요를 보여줍니다. 각 예제는 쿼리와 질문에 답할 수 있는 해당 Wikipedia 페이지로 구성되며 실제 답변을 포함하는 주석이 달린 구절에서 하나 이상의 짧은 범위가 있습니다.
Preference Pairs 컬렉션
먼저 SFT(Supervised Micro-Tuning) 및 RPO에 채택된 기본 설정 쌍을 구성하여 검색된 비모수적 지식을 적응적으로 활용하기 위해 모델의 인식을 향상시키는 것을 목표로 합니다. 데이터 세트 (x,y)∈𝐃 의 인스턴스가 주어지면 섹션 3.2에 설명된 (yn+p,yp) 대로 검색 기능이 있거나 없는 응답을 생성하도록 모델에 각각 지시합니다. 에서 샘플링된 두 개의 하위 집합 𝐃 은 기본 설정 쌍을 수집하기 위해 구성됩니다. 첫 번째 하위 집합 𝐃1 에서 우리의 목표는 검색된 컨텍스트를 읽고 이해하는 모델의 능력을 지속적으로 향상시키는 것입니다. 모델이 질문에 직접 답변하지 못하는 경우, 검색을 통해 응답을 올바르게 생성하는 경우(예: Acc(yn+p)>Acc(yp) )가 샘플링됩니다. 검색된 지식을 참조한다는 yn+p 것을 추가로 확인하기 위해, 즉 yn+p=yn 검색된 컨텍스트에 기본 진리가 포함된 샘플만 선택합니다. 두 번째 하위 집합 𝐃2 은 검색된 지식에 대한 모델의 과도한 의존을 완화하는 데 중점을 둡니다. 검색된 지식의 영향을 받고 잘못된 답변을 생성하는 동안 모델이 올바르게 응답할 수 있었던 경우를 선택합니다 Acc(yp)>Acc(yn+p) . 부정확성으로 인한 간섭은 도입 된 비 매개 변수 지식에 의해 발생하며 yn+p 대략적으로 비 매개 변수 답변 yn 으로 간주 될 수 있습니다. 이는 모델이 생성하기 전에 비모수적 지식을 활용할지 여부와 시기를 재고하는 데 도움이 됩니다. 궁극적으로 두 하위 집합을 결합하여 지식 충돌과 관련된 샘플로 구성된 학습 세트를 𝐃train=𝐃1∪𝐃2 얻습니다.
Supervised Fine-Tuning
이 단계에서는 섹션 5.2의 방법으로 수집된 인스턴스를 사용하여 SFT를 수행하여 하위 집합을 𝐃SFT 얻습니다. SFT 단계에서는 선호도 쌍이 필요하지 않음에도 불구하고 하위 집합은 지식 충돌을 수집하기 위해서만 구성됩니다. 인스턴스의 파라메트릭 소스와 비파라메트릭 소스 중 하나에만 올바른 지식이 𝐃SFT 포함되어 있기 때문에 모델은 의존할 지식을 결정해야 합니다. 따라서 SFT는 모델이 결정을 지원하기 위해 검색 품질 평가에 대한 인식을 사전에 높이는 데 도움이 됩니다.
검색 기본 설정 최적화(Retrieval Preference Optimization)
앞의 그림에서 알 수 있듯이, LLMs 일반적으로 파라메트릭 지식과 다른 정보가 포함된 컨텍스트에 액세스할 때 혼란과 환각을 보입니다. 이 문제를 해결하기 위해 RPO(Retrieval Preference Optimization) 교육 전략을 제안하여 응답 생성 중에 검색된 컨텍스트에 집중 LLMs 하는 인식을 향상시킵니다. 세부적으로, 섹션 5.2에 설명된 유사한 데이터 필터링 처리가 미세 조정된 정책을 πSFT 사용하여 데이터 세트에 다시 채택됩니다. 한편, (yp,yn+p) 쌍 내의 답변 중 어느 것이 선호되는지는 정확성에 따라 주석이 추가됩니다. 후속 교육에 사용되는 SFT 정책을 통해 선택한 데이터 세트는 다음과 같이 표시됩니다. 𝐃RPO 결국, 우리는 Equ. (9)에서 보여준 손실을 줄임으로써 RPO 전략을 수행합니다. 이 접근 방식에서는 로 표시되는 πRPO 최종 정책을 얻으며, 이는 세대 내 검색에 대한 통합 평가를 암시적으로 수행합니다.
6 실험
표 1:4개의 데이터 세트로 구성된 테스트 세트에 대한 전체 평가 결과입니다. 결과는 세대LLMs에 따라 구분됩니다. Column Adaptive Category(적응형 범주)는 분석법이 적응형 RAG에 속하는 경우 분석법의 범주를 나타냅니다. # API/LM 호출은 추론 중에 API 또는 LM이 호출되는 횟수를 의미합니다. 굵은 숫자는 모든 방법 중에서 최상의 성능을 나타내고 LLMs. *는 논문에서 직접 인용된 결과를 나타내며, 그렇지 않으면 일관된 검색 결과로 당사에서 결과를 복제합니다.
| 적응 | 팝QA | NQ | 여담QA | RGB | ||
|---|---|---|---|---|---|---|
| 메서드 | 범주 | #API/LM 호출 | (정확도) | (정확도) | (정확도) | (정확도) |
| 다른 | ||||||
| RAG-챗GPT | - | 1 | 50.8 | - | 65.7 | - |
| 기민한 RAG | 사전 평가 | 2-4 | 42.1 | 51.5 | 47.6 | 94.6 |
| LLaMA2-7B | ||||||
| RAG | - | 1 | 48.8 | 22.0 | 52.5 | 91.6 |
| 자체 RAG | 평가 후 | 2-11 | 54.9 | 42.4 | 68.9 | 92.6 |
| RPO | 통합 평가 | 1 | 55.8 | 45.3 | 57.6 | 97.3 |
| LLaMA3-8B-지시 | ||||||
| RAG | - | 1 | 59.0 | 41.3 | 65.8 | 96.3 |
| 지시RAG | - | 1 | 65.0 | 46.7 | 65.1 | - |
| 셀프 래그* | 평가 후 | 2-11 | 55.8 | 42.8 | 71.4 | - |
| RPO | 통합 평가 | 1 | 65.4 | 51.9 | 74.4 | 100.0 |
우리는 RPO의 발전과 RAG 기반 접근 방식에 대한 적응력, 그리고 다양한 작업에 걸친 일반화 가능성을 광범위하게 입증하기 위해 실험을 수행했습니다.
6.1작업, 데이터셋 및 메트릭Tasks, Datasets and Metrics
RPO는 PopQA Mallen et al. (2023), NQ Kwiatkowski et al. (2019), RGB Chen et al. (2024), TriviaQA Joshi et al. (2017)을 포함한 4개의 데이터 세트에서 평가되었습니다. 이전 작업에 이어 정확도가 벤치마크의 평가 지표로 채택되었습니다. 한편으로는, 우리가 제안한 방법이 이전 연구와 비교할 수 있기 때문에 동일한 지표가 사용됩니다. 반면에 정확도 메트릭은 생성된 응답 내에서 지식의 정확도를 객관적으로 측정하며, 이는 지식 집약적 작업에서 방법의 성능을 적절하게 나타냅니다.
6.2기준선
우리는 주로 RPO를 이전 RAG 기반 기준과 비교했으며, 이는 기본 모델에 따라 다음과 같은 세 가지 범주로 나눌 수 있습니다.
LLaMA2-7B 접근법은 응답 생성을 위해 바닐라 또는 명령어 조정 LLaMA2-7B 모델을 활용했습니다. GPT-4에 의해 레이블이 지정된 여러 세트의 반사 토큰을 포함하는 명령어 튜닝 데이터에서 LLaMA2를 튜닝한 Self-RAGE(Asai et al., 2023).
LLaMA3-8B-Instruct 접근법은 LLaMA3-8B-Instruct로 응답을 생성했습니다. (1) InstructRAG(Wei et al., 2024)는 명령어 튜닝 방법을 제안하는 반면, (2) Self-RAG는 기본 모델을 제외하고 위의 방법과 함께 제공됩니다. 특히, *가 있는 Self-RAG에 대한 결과는 결과가 이전 논문에서 직접 인용되었음을 나타냅니다.
기타는 LLaMA2 및 LLaMA3을 제외하고 생성기로 채택됨을 LLMs 의미합니다. 특히 이번 ChatGPT 실험에서 AstuteRAG를 재현하여 생성 전에 지식을 반복적으로 필터링하고 수정했습니다.
6.3결과
표 1은 4개의 데이터 세트에 대한 결과를 나타냅니다. 표에 나열된 적응형 RAG 기준선의 범주를 간략하게 표시합니다. 추론 단계에서 계산 오버헤드에서 RPO의 효율성을 보여주기 위해 예상 API 호출 또는 LLM 추론 시간도 표시됩니다. 이러한 결과를 통해 다음과 같은 결론을 내릴 수 있습니다.
첫째, 제안된 방법은 적응형 검색과 관련된 이전 기준선을 크게 능가하여 최첨단에 도달했습니다. 구체적으로 말하자면, LLaMA3-8B-instruct 기준에서 RPO는 PopQA 7.4%, NQ 10.6%, TriviaQA 8.6%, RGB 3.7%의 정확도로 RAG를 앞섰으며, LLaMA2-hf-7b 기준 PopQA 7.0%, NQ 23.3%, TriviaQA 5.1%, RGB 5.7%의 차이로 RAG를 앞섰다 . 현재 발전된 적응형 RAG 방법과 비교할 때 RPO는 일반적으로 모든 벤치마크에서 우수한 성능을 보였습니다. 우리 방법의 발전은 선호도 최적화의 효과를 크게 보여주며 지식 충돌 극복의 중요성을 보여줍니다.
둘째, 제안된 방법은 더 큰 계산 효율성을 보여 지식 충돌 완화를 위한 실제 응용 프로그램에서 실용적인 솔루션을 제공했습니다. 사전 평가 또는 사후 평가 접근 방식에는 단일 추론 내에서 API 또는 LM을 여러 번 호출해야 한다는 것을 알 수 있습니다. 이전 적응형 RAG와 비교하여 검색 평가는 생성을 통해 동기식으로 수행됩니다. 한편, 더 나은 결과를 얻을 수 있으며, 이는 RPO의 효율성을 더욱 입증합니다.
6.4절제 연구
표 2:정확도 측면에서 PopQA 데이터 세트에서 검색 인식, 선호도 최적화 및 SFT 단계를 각각 제거하기 위한 절제 연구.
| 팝QA | NQ | 여담QA | RGB | |
|---|---|---|---|---|
| LLaMA2-7B-hf | ||||
| \h대시라인증권 시세 표시기 | 55.8 | 45.3 | 57.6 | 97.3 |
| RPO w̃/o Ra | 53.6 | 43.5 | 51.7 | 96.3 |
| RPO w̃/o PO | 51.3 | 36.0 | 54.3 | 94.6 |
| RPO w̃/o SFT | 52.5 | 34.9 | 50.1 | 90.6 |
훈련 단계에서는 supervised fine-tuning 및 preference optimization을 포함한 두 단계가 채택되었으며 둘 다 검색 인식을 향상시키고 지식 충돌을 극복하는 데 도움이 됩니다. 우리는 RPO에서 각 단계의 기여도를 확인하기 위해 절제 연구를 수행합니다. 미세 조정 및 선호도 최적화 단계는 실험에서 특별히 제거되고 결과는 벤치마크에서 평가됩니다. 표 2의 결과는 두 단계 중 하나를 제거할 때 성능이 저하되었음을 보여주며, 이는 유의성을 드러냅니다.
6.5교육 세트 필터링의 영향
표 3:SFT 단계에서 데이터 필터링을 사용한 경우와 사용하지 않은 RPO 간의 비교 결과.
| 팝QA | NQ | 여담QA | RGB | |
|---|---|---|---|---|
| LLaMA2-7B-hf | 48.8 | 22.0 | 52.5 | 91.6 |
| πSFT 필터링 사용 | 51.3 | 36.0 | 54.3 | 94.6 |
| πSFT 필터링 없음 | 46.9 | 38.2 | 48.8 | 80.0 |
교육 단계의 1단계에서는 예비 교육을 위해 감독된 미세 조정이 도입됩니다. 특히, 학습 세트가 필터링되고 지식 충돌과 관련된 인스턴스만 감독된 미세 조정을 위해 선택됩니다. 우리는 아직 활성화되지는 않았지만 응답을 생성하면서 검색 품질을 평가할 수 있는 고유한 능력을 LLMs 가지고 있다는 가설을 세웠습니다. 따라서 이 작업은 더 많은 지식을 학습하는 것이 아니라 에 대한 LLMs검색 인식을 향상시키기 위한 것입니다. 실제로, 표 3의 실험 결과는 데이터 필터링 LLM 을 사용하지 않고 미세 조정한 것이 튜닝 전의 원본 LLM 보다 훨씬 더 나쁜 성능을 보였다는 것을 보여주며, 이는 우리의 가설을 더욱 입증합니다.
6.6지식 선택 성능
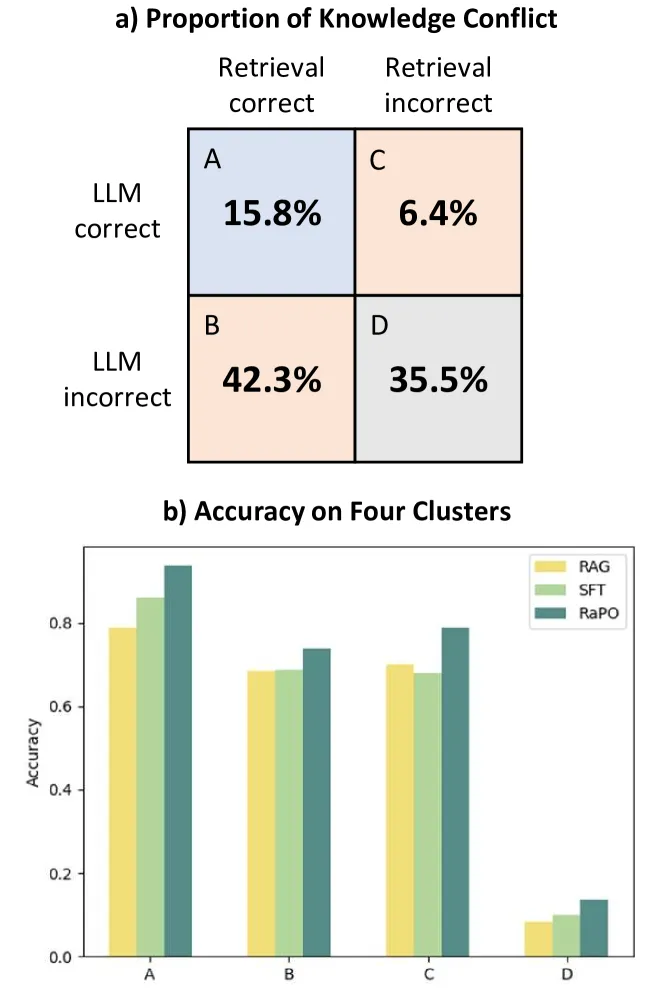
그림 3 : PopQA에서 4개 클러스터의 비율과 LLaMA2-7B의 해당 정확도 점수.
이 섹션에서는 지식 선택 성능 측면에서 RPO를 이전 교육 전략과 비교합니다. 이 문서의 원래 목적은 지식 충돌을 해결하는 것이므로 검색 평가 기능을 활성화하고 보다 정확한 답변에 맞춥니다. RPO 전후의 지식 충돌 문제에 대한 추가 분석을 수행합니다. 그림 3의 결과는 지식을 평가하고 올바른 지식을 자율적으로 선택하기 위해 모든 클러스터에서 일관된 발전을 보여줍니다. 특히 지식 충돌이 수반되는 클러스터 B와 C에서 RPO는 지식 선택에서 상당한 개선을 보여주었습니다.
7 결론
이 논문은 RAG에서 파라메트릭 지식과 검색된 비파라메트릭 지식이 일치하지 않는 지식 충돌 문제를 연구합니다. 이전의 모델 정렬 방법은 RAG 적용의 맥락에서 제한적인 것으로 입증되어 지식 충돌이 관련될 때 부적절성과 편향을 초래했습니다. 따라서 RAG 애플리케이션을 조정하기 위해 Retrieval Preference Optimization이라는 새로운 근접 정책 최적화 알고리즘이 제안됩니다. 검색을 평가 LLMs 할 수 있는 기능은 RPO를 통해 생성에 통합되어 이전의 적응형 RAG 접근 방식에 비해 효율성을 크게 향상시킵니다. 실험은 다양한 벤치 마크에서 그 발전과 일반화 가능성을 광범위하게 보여줍니다. 향후 작업에서는 RAG의 신뢰성과 견고성을 더욱 향상시키기 위해 검색 평가를 위한 보다 통합적이고 암시적인 접근 방식을 지속적으로 모색할 것입니다.
