https://export.arxiv.org/pdf/2401.13979v3.pdf
1. 소개 (Introduction)
- Routoo 개요:
- Routoo는 비용과 품질 간의 균형을 최적화하며 LLM(대규모 언어 모델) 사용을 효과적으로 조율하는 시스템입니다.
성능 예측기(Performance Predictor)와비용 인지 선택기(Cost-Aware Selector)로 구성됩니다.- 비용 절감과 고품질 추론 간의 적절한 균형을 제공합니다.
2. 관련 연구 (Related Work)
- 기존 MoE(Mixture of Experts) 및 모델 선택 접근 방식과 비교.
- MoE는 단일 고급 장비에 모든 전문가 모델을 로드해야 하는 제약이 있음.
- Routoo는 각 전문가 모델을 독립적으로 실행 가능하며 분산 호스팅이 가능.
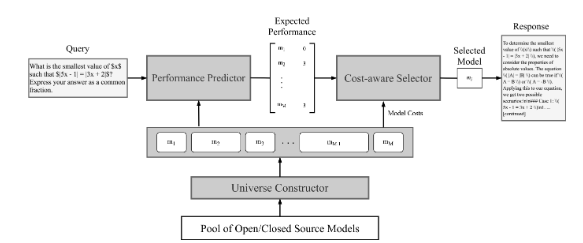
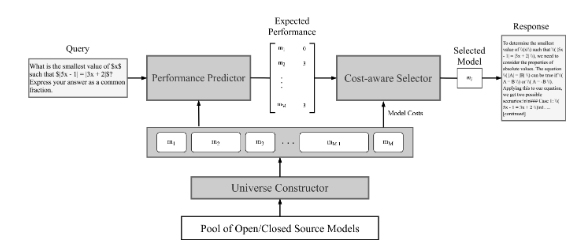
3. 구조 (Architecture)
3.1 문제 정의 (Problem Formulation)
- 목표:
- 주어진 예산 제약 내에서 정확도를 최대화.
- 각 질문에 대해 가장 비용 효율적인 모델을 할당.
- 수식:
- 정확도 점수와 비용을 수식으로 표현하여 최적화를 목표로 함.
3.2 성능 예측기 (Performance Predictor)
- 역할:
- 특정 질문에 대해 LLM의 성능을 예측.
- 실제 모델 실행 없이 성능을 추정하여 비용 절감.
- 방법:
- 입력 질문을 인코딩(Enc)하여 표현 벡터(hqj) 생성.
- 모델별 임베딩(hmi) 생성.
- 성능 점수는 선형 투영(Linear Projection)으로 계산.
3.3 비용 인지 선택기 (Cost-Aware Selector)
- 역할:
- 예측된 성능 점수를 기반으로 모델 선택.
- 비용 효율성과 정확도 간의 균형을 맞춤.
- 방법:
- 성능 대 비용 비율 계산.
- 예산 초과 시 대체 모델로 전환.
3.4 유니버스 생성기 (Universe Constructor)
- 역할:
- 사용할 모델 집합을 최적화하여 성능 최대화.
- 방법:
- 서브모듈러 함수 최적화를 위한 탐욕 알고리즘 사용.
4. 결과 및 논의 (Results and Discussion)
4.1 주요 결과
- Routoo(Open-source):
- Mixtral 8x7b와 동일한 비용으로 5% 더 높은 성능.
- GPT-4와 유사한 성능을 절반의 비용으로 달성.
- Routoo(Mix):
- GPT-3.5보다 14.9% 더 높은 성능.
- GPT-4보다 낮은 비용으로 더 높은 성능.
4.2 도메인 별 성능 분석
- 수학 및 컴퓨터 과학과 같은 STEM 분야에서 뛰어난 성능.
4.3 라우팅 분포
- 작은 모델(예: 7B)의 빈도를 전략적으로 늘려 비용 대비 성능 효율성 향상.
5. 결론 및 향후 작업 (Conclusion and Future Work)
- Routoo는 비용 효율적이고 고성능의 언어 모델링을 가능하게 함.
- 향후 도메인별 전문가 개발 및 추가 최적화 기준 통합이 필요.
Routoo 구조 및 작동 방법
Routoo의 구조와 작동 방식을 세부적으로 정리하여 각 구성 요소와 주요 알고리즘을 설명합니다.
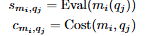
1. Routoo의 전체 구조
Routoo는 세 가지 주요 컴포넌트로 구성됩니다:
- 성능 예측기(Performance Predictor)
- 비용 인지 선택기(Cost-Aware Selector)
- 유니버스 생성기(Universe Constructor)
1.1 성능 예측기 (Performance Predictor)
1.1.1 역할
- 특정 질문에 대해 각 전문가 모델(독립 LLM)의 성능을 사전 평가합니다.
- 실제 모델 실행 없이 성능을 추정하여 비용과 시간을 절감합니다.
1.1.2 작동 원리

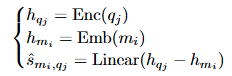
-
입력 데이터의 인코딩:
- 입력 질문 은 Decoder-Only LLM을 사용하여 임베딩 벡터 로 변환합니다.
- 입력의 마지막 토큰 임베딩을 질문의 표현으로 사용합니다.
-
모델 임베딩:
- 각 전문가 모델 는 고유한 임베딩 을 가집니다.
- 모델별 특성을 임베딩 벡터로 표현합니다.
-
성능 점수 계산:
- 질문 임베딩과 모델 임베딩 간의 차이를 선형 변환(Linear Projection)하여 성능 점수 로 변환:
- 이 점수는 모델이 특정 질문에 대해 얼마나 적합한지를 나타냅니다.
-
학습:
- 크로스 엔트로피 손실(Cross-Entropy Loss)을 통해 과 실제 점수 간의 차이를 최소화:
1.2 비용 인지 선택기 (Cost-Aware Selector)
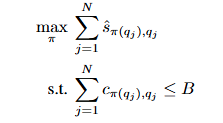
1.2.1 역할
- 예측된 성능 점수를 기반으로 각 질문에 가장 적합하면서도 비용 효율적인 모델을 선택합니다.
- 주어진 예산 B 안에서 정확도를 최대화합니다.
1.2.2 작동 원리
-
성능 대비 비용 비율 계산:
- 각 모델 와 질문 에 대해 성능 대비 비용 비율 계산:
여기서 는 모델 실행 비용, 는 비용 중요도를 조절하는 파라미터입니다.
-
정렬 및 할당:
- 각 질문에 대해 성능 대비 비용 비율이 가장 높은 모델부터 선택합니다.
- 선택 시, 예산을 초과하지 않도록 관리합니다.
-
예산 관리:
- 선택된 모델의 누적 비용을 추적하며, 예산 초과 시 대체 모델로 전환합니다.
1.3 유니버스 생성기 (Universe Constructor)
1.3.1 역할
- 사용할 모델의 서브셋을 구성하여 최적화된 조합을 제공합니다.
- 모델 풀(전체 사용 가능한 모델)에서 성능과 상호 보완성이 높은 모델들만 선택합니다.
1.3.2 작동 원리
-
목표 함수 정의:
- 선택된 모델 집합 U 가 전체 질문 Q 에 대해 최대 성능을 내도록 최적화:
여기서 L 은 질문 수, 는 모델 가 질문 에 대해 얻은 성능 점수입니다.
-
탐욕 알고리즘 사용:
- 한 번에 하나씩 모델을 추가하며 를 최대화합니다.
- 예산 또는 성능 개선이 멈추면 종료합니다.
2. Routoo의 작동 방법
2.1 데이터 흐름
- 입력 질문이 성능 예측기에 전달됩니다.
- 성능 예측기는 각 모델에 대한 점수를 추정합니다.
- 비용 인지 선택기가 주어진 예산 안에서 가장 적합한 모델을 선택합니다.
- 유니버스 생성기는 최적의 모델 서브셋을 사전에 구성하여 선택 범위를 제한합니다.
2.2 주요 알고리즘
- 성능 점수 계산:
- 선택 최적화:
가장 높은 을 가진 모델 선택.
- 유니버스 최적화:
- 서브모듈러 최적화로 상호 보완적인 모델 집합 생성.
3. 주요 장점
- 비용 효율성: 모델 실행 없이 성능을 예측하여 추론 비용 절감.
- 확장성: 분산 호스팅 가능한 전문가 모델 활용으로 대규모 시스템 구현 가능.
- 유연성: 다양한 도메인 및 작업에 적합한 모델 선택 가능.
4. 추가적인 활용 및 발전 방향
- 도메인 전문가 모델 강화: 특정 도메인에 최적화된 모델 추가.
- 프라이버시 또는 속도 중심 최적화: 추가적인 최적화 기준 적용 가능.
아래는 Routoo 논문의 한국어 번역입니다.
Routoo: 대형 언어 모델을 효과적으로 라우팅하는 학습 방법
Alireza Mohammadshahi, Arshad Rafiq Shaikh, Majid Yazdani
Leroo
{alireza, arshad, my}@leeroo.com
초록 (Abstract)
고성능 대형 언어 모델(LLM)은 일반적으로 더 높은 추론 비용을 수반하며, 이를 실제 환경에 배포하는 데 비용이 많이 들고 복잡합니다. 또한, LLM을 처음부터 개발하는 것은 자원 소모가 크고 비효율적입니다. 이러한 품질과 비용의 균형 문제를 해결하기 위해, 우리는 Routoo라는 아키텍처를 소개합니다. Routoo는 성능, 비용, 효율성을 기준으로 특정 프롬프트에 대해 최적의 LLM을 선택하도록 설계되었습니다.
Routoo는 성능 예측기(Performance Predictor)와 비용 인식 선택기(Cost-aware Selector)라는 두 가지 주요 구성 요소로 구성됩니다. 성능 예측기는 특정 LLM의 성능을 예측하며, 비용 인식 선택기는 예상 비용과 품질 기준에 따라 최적의 LLM을 선택합니다.
우리는 45개의 도메인을 포함하는 MMLU 벤치마크에서 Routoo를 평가했으며, 오픈소스 모델들과의 비교에서 우수한 성능을 보였습니다. 특히, 비용을 조금 증가시켰을 때 Mistral의 성능을 5% 향상시켰고, GPT-4를 절반의 비용으로 능가했으며, 비용을 25% 절감한 상태에서도 경쟁력 있는 성능을 보였습니다.
1. 서론 (Introduction)
LLM은 자연어 처리 분야에서 뛰어난 성능을 보여주고 있습니다. 그러나 고성능 모델은 일반적으로 더 높은 비용과 계산 자원을 필요로 합니다. 대규모 모델을 학습하고 운영하는 것은 막대한 컴퓨팅 리소스와 비용 문제를 초래합니다.
예를 들어, OpenAI의 GPT-4는 MMLU 벤치마크에서 86.4%의 정확도를 기록하고 있으며, Mistral-7B는 70% 정확도를 기록하고 있습니다. 그러나 오픈소스 모델을 지능적으로 결합하면 고성능을 유지하면서도 추론 비용을 크게 절감할 수 있습니다.
2. Routoo 아키텍처 소개 (Routoo Architecture)
우리는 이러한 문제를 해결하기 위해 Routoo를 제안합니다. Routoo는 특정 프롬프트에 대해 LLM을 선택할 때 성능, 비용, 효율성을 고려하는 경량 아키텍처입니다.
Routoo는 다음 두 가지 주요 구성 요소로 이루어집니다:
- 성능 예측기 (Performance Predictor)
- 가벼운 LLM을 사용하여 여러 하위 LLM의 예상 성능을 예측합니다.
- 비용 인식 선택기 (Cost-aware Selector)
- 추론 비용과 성능을 고려하여 최적의 LLM을 선택합니다.
2. 관련 연구 (Related Work)
Mixture-of-Experts (MoE)
Mixture-of-Experts (MoE) 아키텍처는 각 레이어에 여러 전문가 서브 네트워크를 통합하는 게이팅 메커니즘을 포함하여, 다음 토큰을 예측하는 방식입니다 (Shazeer et al., 2017). 이 접근 방식은 다음과 같은 최신 LLM들에서 사용됩니다:
- Mistral 8x7B (Jiang et al., 2024)
- LLaMA 2 70B (Touvron et al., 2023)
MoE의 핵심 한계는 전문가 모델을 단일 거대 네트워크에 로딩해야 하며, 모델 크기가 너무 커지면서 확장성과 유연성에 문제가 발생하는 것입니다.
Model Selection (모델 선택)
기존 연구들은 최적의 LLM을 선택하는 다양한 접근 방식을 제안했습니다.
- 정적 모델 선택: 특정 작업에 대한 미리 정의된 성능 기반으로 모델을 선택.
- 탐색적 디코딩 (Speculative Decoding): 더 가벼운 모델을 먼저 사용하고, "쉬운" 쿼리만 처리한 후, 복잡한 쿼리에는 고성능 모델을 사용하는 방식.
- LLM-BLENDER: 여러 모델의 출력을 결합하는 방식 (Jiang et al., 2023).
- ZOOFILTER: 전문가 모델의 랭킹을 사용하여 특정 쿼리에 맞춰 최적의 LLM을 선택하는 방식.
3. 아키텍처 (Architecture)
3.1 문제 정의 (Problem Formulation)
주어진 LLM 모델 M과 쿼리 Q가 있을 때, 각 쿼리 에 대해 정확하고 비용 효율적으로 응답할 수 있는 최적의 모델을 선택하는 것이 목표입니다.
정확도 및 비용 점수는 다음과 같이 정의됩니다:
- 정확도:
- 비용:
목표는 예산 B 내에서 정확도 점수의 총합을 최대화하는 것입니다:
여기서 는 쿼리 q_j에 대해 선택된 모델을 의미합니다.
3.2 성능 예측기 (Performance Predictor)
성능 예측기는 가벼운 LLM으로, 특정 쿼리에 대해 LLM의 성능을 예측하는 역할을 합니다. 예측 공식은 다음과 같습니다:
- Enc: 쿼리의 임베딩을 추출하는 인코더.
- Emb: 모델의 임베딩 벡터.
- Linear: 임베딩 차원 축소를 위한 선형 변환.
3.3 비용 인식 선택기 (Cost-aware Selector)
비용 인식 선택기는 성능 예측기의 예측 점수와 모델별 비용을 종합적으로 고려하여 최적의 LLM을 선택합니다. 이 과정은 다음과 같이 수식화됩니다:
3.4 탐욕적 알고리즘 (Greedy Algorithm)
Routoo는 탐욕적 알고리즘을 사용하여 모델 선택을 최적화합니다:
-
각 쿼리에 대해 모델의 성능 대 비용 비율을 계산:
-
모델을 비율 기준으로 정렬.
-
예산 B를 초과하지 않는 한에서 가장 높은 비율의 모델을 선택.
4. 성능 평가 (Performance Evaluation)
MMLU 벤치마크에서 Routoo를 평가했으며, 다양한 모델을 비교한 결과는 다음과 같습니다:
| 모델 | 정확도(%) | 비용 ($/M token) |
|---|---|---|
| LLaMA2 7B | 45.3 | 0.2 |
| Mistral 7B | 64.2 | 0.4 |
| LLaMA2 13B | 54.8 | 0.6 |
| Mistral 8x7B | 70.6 | 0.6 |
| LLaMA2 70B | 69.9 | 1.0 |
| Routoo (open) | 75.87 | 0.6 |
| GPT-3 | 86.4 | 20.0 |
| GPT-4 turbo | 84.9 | 10.2 |
- Mistral 대비 5% 높은 성능
- GPT-4 대비 절반의 비용으로 유사한 성능 달성
3.4 유니버스 생성기 (Universe Constructor)
여러 모델을 동시에 호스팅하는 것이 어렵기 때문에, Routoo는 유니버스 생성기(Universe Constructor)라는 최적화 접근 방식을 도입하여 상호 보완적으로 성능을 극대화할 수 있는 모델 서브셋을 선택합니다.
공식적으로, 모델 집합 와 쿼리 집합 가 주어졌을 때, 해당 쿼리에 대한 각 모델의 정확도 점수 를 고려하여 최적의 모델 서브셋 U를 선택하는 것이 목표입니다. 최적화 수식은 다음과 같습니다:
- M은 선택할 모델의 최대 수를 나타냅니다.
- S(U)는 선택한 모델 집합 U가 제공하는 성능을 나타내는 함수입니다.
이 최적화 문제는 계산량이 많기 때문에, 탐욕적 알고리즘 (Greedy Algorithm)을 사용하여 근사 최적 해를 찾습니다.
4. 결과 및 논의 (Results and Discussion)
4.1 실험 설정 (Experiment Setting)
평가 데이터셋:
- MMLU 벤치마크 (57개의 다양한 도메인 포함)
- HC3, ARC, OBQA 등 다중 선택 QA 데이터셋
- 모델: LLaMA 7B, 13B, 70B, Mistral 7B, 8x7B, GPT-4
비교 기준:
- 정확도 (Accuracy)
- 비용 (Cost per Token)
4.2 데이터 준비 (Data Preparation)
- 데이터 필터링: 다양한 QA 데이터셋을 수집하여 난이도별로 필터링
- GPT-4 생성 데이터: 20,000개의 추가 합성 쿼리를 생성하여 데이터 다양성 증가
- 최종 데이터셋: 약 75,000개의 질문 사용
4.3 주요 결과 (Main Results)
- Routoo (open-source): Mistral 7B보다 5% 높은 정확도 달성
- Routoo (mix): GPT-4와 유사한 정확도 유지, 비용 25% 감소
- 비용 인식 선택기 (Cost-Aware Selector): 비용과 성능의 균형 유지
5. 결론 및 향후 연구 방향 (Conclusion and Future Work)
이 논문에서는 Routoo라는 경량 LLM 기반 아키텍처를 소개했습니다. Routoo는 다음과 같은 성과를 달성했습니다:
- MMLU 벤치마크에서 Mistral 8x7B보다 5% 높은 성능
- GPT-4 성능과 유사하지만, 비용 25% 절감
향후 연구 방향:
- Routoo의 학습을 위한 대규모 데이터셋 확장
- 비용, 속도, 개인정보 보호 등 추가적인 최적화 지표 통합
