https://arxiv.org/pdf/2412.12170
PickLLM: Context-Aware RL-Assisted Large Language Model Routing
전체 내용 간단 요약
초록 (Abstract)
최근 다양한 오픈소스 대형 언어 모델(LLM)이 등장함에 따라, 이를 활용한 애플리케이션 구축이 활발해지고 있습니다. 그러나 LLM을 실제 환경에서 최적화하여 운영 비용(요금 구조, 서비스로서의 LLM 비용)과 효율성, 그리고 정확도, 편향성, 유해성 등 구체적인 지표를 모두 고려하기는 어렵습니다. 기존의 LLM 라우팅 솔루션들은 주로 비용 절감을 중심으로 이루어지며, 일반화되지 않은 지도 학습 데이터에 의존하거나 모든 LLM 후보를 평가하기 위한 비효율적인 연산이 필요합니다.
이 논문에서는 특정 쿼리에 대해 사용자 맞춤형 목적에 따라 최적의 LLM을 선택하는 문제를 해결하고자 합니다. 이를 위해 Reinforcement Learning(강화 학습, RL)을 기반으로 쿼리마다 동적으로 LLM을 선택하는 경량 프레임워크인 PickLLM을 제안합니다. PickLLM은 쿼리당 비용, 추론 지연 시간, 모델 응답 정확도를 고려하는 가중 보상 함수를 활용합니다.
학습 알고리즘으로는 두 가지 방식을 탐구합니다:
- Gradient Ascent Learning (기울기 상승 학습): 특정 LLM을 선택하기 위해 기울기 상승 기반으로 학습하는 강화 학습 기법.
- Stateless Q-Learning (무상태 Q-러닝): 여러 LLM을 탐색하고 전략을 사용하여 최적의 LLM을 선택.
평가를 위해 네 개의 LLM과 다양한 프롬프트-응답 데이터셋을 사용하여 비교했습니다. 모델 선택 기준으로 쿼리당 비용, 응답 시간, 정확도를 평가하였으며, 다양한 학습 속도에 따른 수렴성과 최적의 LLM 선택 능력을 실험적으로 증명했습니다.
1. 도입 (Introduction)
최근 대형 언어 모델(LLM)은 요약, 감정 분석, 질의응답 등 다양한 NLP 과제를 해결하는 데 중요한 도구로 자리 잡고 있습니다. LLM의 크기와 성능이 증가하면서 더 깊은 문맥 이해 및 정확한 응답이 가능해졌습니다. 그러나 이러한 모델의 다양성과 증가하는 크기는 사용자가 적합한 모델을 선택하고 효율적으로 활용하는 것을 어렵게 합니다.
특히, 다양한 오픈소스 및 상업용 LLM이 혼재하면서 사용자는 모델의 정확도, 비용, 추론 지연 시간 등을 고려해 최적의 모델을 선택해야 합니다. 일부 사용자는 고성능 모델을 과도하게 사용하는 경우가 많으며, 오히려 단순한 작업에도 고성능 모델을 사용하는 것은 비효율적입니다.
따라서, LLM의 비용-성능-추론 시간을 종합적으로 고려하여 특정 작업에 최적화된 모델을 자동으로 선택하는 경량화된 프레임워크가 필요합니다.
2. 관련 연구 (Related Work)
기존의 LLM 라우팅 솔루션들은 크게 다음과 같은 접근 방식을 사용했습니다:
- 순차적 라우팅: DistilBERT와 같은 경량 모델을 먼저 사용하고, 이후 복잡한 질문에만 고성능 LLM을 사용하는 방식.
- AutoMix: 소형 LLM으로 여러 후보 출력을 생성하고, 결과의 정확성을 기반으로 최종 출력을 선택.
- 정적 순위 기반 모델 선택: 여러 LLM의 성능을 미리 평가하고 고정된 순서로 선택하는 방식.
이러한 기존 방식들은 일반적으로 비용이나 정확도 중 하나에만 집중하거나, 미리 학습된 정적 모델을 사용하기 때문에 새로운 데이터에 동적으로 적응하지 못하는 한계가 있습니다.
3. PickLLM 프레임워크 (PickLLM Framework)
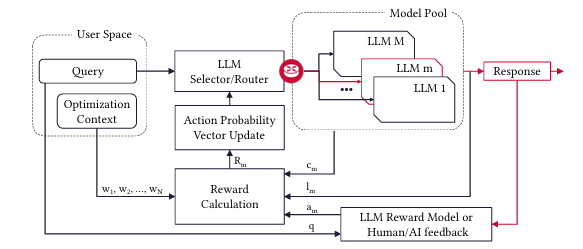
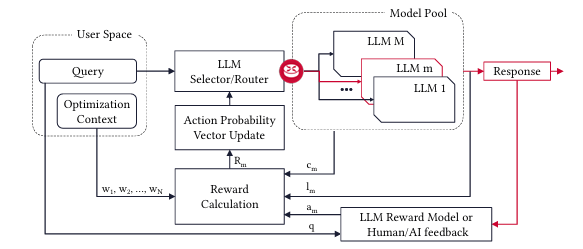
3.1 전반적 프레임워크 설명 (Overall Framework)
PickLLM은 사용자가 정의한 성능 지표(비용, 정확도, 추론 시간)를 기반으로 특정 쿼리에 가장 적합한 LLM을 자동으로 선택하는 프레임워크입니다. 사용자가 정의한 최적화 목적에 맞춰 쿼리당 적절한 모델을 선택할 수 있습니다.
3.2 보상 함수 정의 (Reward Function Formulation)
각 LLM의 성능을 측정하기 위해 PickLLM은 세 가지 주요 지표를 포함하는 보상 함수를 정의합니다:
- : 모델의 쿼리당 비용
- : 추론 지연 시간
- : 모델의 응답 정확도 (정답률)
보상 함수는 다음과 같이 정의됩니다:
여기서 은 각각 정확도, 비용, 지연 시간에 대한 가중치를 의미합니다.
3.3 Gradient Ascent Learning (기울기 상승 학습)
PickLLM은 기울기 상승 학습(Gradient Ascent Learning) 방식을 사용하여 쿼리마다 최적의 LLM을 선택하는 메커니즘을 학습합니다. 모델 선택 확률은 다음과 같이 업데이트됩니다:
여기서 는 학습률을 나타내며, 은 특정 모델을 선택할 확률을 의미합니다.
3.4 Stateless Q-Learning (무상태 Q-러닝)
무상태 Q-러닝은 각 LLM에 대해 Q-값을 유지하고, -greedy 전략을 사용하여 탐색과 활용을 조절합니다. 이 방식은 기울기 상승 학습보다 더 안정적으로 수렴할 수 있습니다.
4. 결론 (Conclusion)
PickLLM은 사용자가 정의한 성능 지표에 따라 최적의 LLM을 동적으로 선택하는 경량 프레임워크입니다. 강화 학습 기반의 두 가지 학습 알고리즘(기울기 상승 학습, 무상태 Q-러닝)을 적용하여 쿼리당 비용, 추론 시간, 정확도에 기반한 최적의 LLM을 선택하는 성능을 입증했습니다.
Q-러닝 업데이트 규칙 (Q-Learning Update Rule)
PickLLM은 Q-러닝을 활용하여 쿼리당 적합한 LLM을 선택하는 방식을 학습합니다. 각 LLM 선택에 대한 유틸리티를 로 표현하며, 이는 특정 모델 m을 선택했을 때의 예상 보상을 나타냅니다.
Q-러닝의 업데이트 규칙은 다음과 같이 정의됩니다:
- 는 학습률로, 업데이트 크기를 조정하는 역할을 합니다.
- LLM 선택은ϵ greedy 전략을 사용하여, 다음과 같은 방식으로 이루어집니다:
이 방식은 탐색과 활용 사이의 균형을 맞추며, 이 증가할수록 탐색을 더 자주 수행합니다.
4. 성능 평가 (Performance Evaluation)
4.1 실험 설정 (Experimental Setup)
- PickLLM은 로컬 서버와 원격 LLM API를 활용하여 실험을 진행했습니다.
- CPU: 2.4 GHz 8코어, RAM: 32GB의 환경에서 실행되었습니다.
- Mistral-7B, WizardLM-70B, LLaMA 2-13B 등 다양한 모델을 사용했습니다.
- HC3 데이터셋을 사용했으며, 여러 주제의 질문과 정답을 포함하는 벤치마크 데이터셋입니다.
비용 및 지연 시간 설정 (Cost and Latency Configuration)
- 모델별 쿼리당 비용: = [0.4, 0.8, 0.7, 0.3]
- Mistral-7B, WizardLM-70B, LLaMA2-70B 등의 모델 사용.
- 지연 시간: 사용자 쿼리에서 응답까지의 총 시간(ms 단위).
- 응답 품질: OpenAI의
gpt-3.5-turbo와deberta-v3-large-v2기반의 LLM-Blender 평가 기준 사용.
4.2 평가 결과 및 분석 (Evaluation and Discussion)
- 학습률 가 증가함에 따라, PickLLM은 더 낮은 보상을 제공하는 모델로 수렴하는 경향을 보임.
- SLA 기반 학습률: , Q-러닝 학습률: . = 0.7
- PickLLM은 무작위 모델 선택 대비 52%의 지연 시간 감소를 달성.
- 비용 효율적이면서도 성능을 유지하는 결과를 보여줌.
표 1: PickLLM과 기존 모델 성능 비교
| Sub Dataset | PickLLM SLA (GPT3) | PickLLM Q-Learning | Mistral | LLaMA2-70B |
|---|---|---|---|---|
| reddit_e15 | 0.79 (GPT3) | 0.80 (LLM-Blender) | 0.88 | 0.89 |
| open_qa | 0.95 | 0.93 | 0.62 | 0.65 |
| wiki_csai | 0.91 | 0.93 | 0.99 | 0.90 |
| medical | 0.92 | 0.90 | 0.49 | 0.59 |
| finance | 0.85 | 0.88 | 0.44 | 0.48 |
5. 미래 연구 방향 (Future Work)
- PickLLM을 모델 기반 강화 학습(RL)로 확장할 계획.
- 신경망 및 다중 무장 밴딧(Contextual Multi-Armed Bandit) 활용 가능성 탐구.
- GPU 메모리, 환경적 영향, 라이선스 등 다양한 최적화 지표 포함 가능.
6. 결론 (Conclusion)
- PickLLM은 사용자가 정의한 성능 기준에 따라 LLM을 자동으로 선택하는 경량화된 프레임워크를 제안함.
- 강화를 위한 Q-러닝 및 기울기 상승 학습 기반으로 설계됨.
- 평균적으로 52%의 지연 시간 절감과 최대 60%의 세션 비용 감소를 달성함.
PickLLM: 컨텍스트 인식 RL 기반 대형 언어 모델 라우팅
초록
최근, 오픈소스로 제공되는 대형 언어 모델(LLM)의 수가 폭발적으로 증가했습니다. 이는 모델 제공 방식(예: 로컬 하드웨어에서의 추론 vs. 원격 LLM API)과 모델의 이질성 측면에서 다양한 상황을 만들었습니다. 그러나 이러한 옵션을 효율적으로 최적화하기는 어렵습니다. 그 이유는 비용 구조(고가의 서비스형 LLM, 대량 쿼리 처리 비용 등), 성능, 심지어 특정 사용 사례에 대한 응답 정확도, 편향성, 독성 문제와 같은 요소가 존재하기 때문입니다. 기존의 LLM 라우팅 솔루션은 주로 비용 절감에 중점을 두거나, 비일반화 가능한 지도 학습 및 앙상블 접근 방식을 사용하여 매번 고려되는 LLM 후보에 대해 높은 계산 비용을 발생시킵니다.
이 연구에서 우리는 주어진 사용자 정의 목적에 따라 특정 쿼리에 최적의 LLM 후보를 선택하는 문제를 해결합니다. 이를 위해 Reinforcement Learning (RL, 강화 학습)을 기반으로 한 경량 프레임워크인 PickLLM을 제안합니다. PickLLM은 쿼리를 다양한 모델에 라우팅합니다. 이 과정에서 쿼리당 비용, 추론 지연 시간, 응답 정확도와 같은 요소를 고려하는 가중 보상 함수를 도입합니다.
학습 알고리즘과 관련하여 우리는 두 가지 대안을 탐구합니다. 첫 번째는 PickLLM 라우터가 특정 LLM을 선택하도록 기울기 기반 정책을 학습하는 학습 자동화 역할을 하는 것입니다. 두 번째는 상태 기반 Q-러닝을 활용하여 LLM 집합을 선택하고 -탐욕적 접근법을 통해 검색을 수행하는 것입니다. 알고리즘은 나머지 세션 쿼리에 대해 단일 LLM으로 수렴합니다.
성능을 평가하기 위해 우리는 서로 다른 컨텍스트를 가진 4개의 LLM 풀과 벤치마크 프롬프트-응답 데이터셋을 사용했습니다. 별도의 채점 함수는 실험 중 응답 정확도를 평가합니다. 성능을 평가하는 데 있어, 다양한 학습률과 정보 공유 전략에 따라 컨버전스 속도, 쿼리당 비용, 전체 응답 지연 시간과 같은 지표를 비교했습니다.
1. 서론
최근 대형 언어 모델(LLM)의 등장으로 텍스트 분류, 요약, 텍스트 완성, 코딩과 같은 다양한 자연어 처리 작업에서 명확한 기준이 세워졌습니다. 게다가, LLM은 다양한 문제를 해결하는 데 점점 더 많이 사용되고 있습니다. 그러나 이러한 강력한 기능에도 불구하고, 대형 언어 모델의 복잡성과 비용 때문에, 다양한 애플리케이션과 산업 도메인에서 새로운 LLM의 등장과 함께 다양한 선택지가 생겨났습니다. 이로 인해 학계 및 산업 전반에서 (예: Meta의 Llama 2 및 OpenAI의 GPT 모델) 무료 오픈 소스 LLM과 상업적 서비스 기반 LLM이 혼재하게 되었습니다.
오픈소스 및 상용 LLM의 급증으로 인해 실무자와 신기술 수용자들에게 다양한 선택지가 주어졌지만, 특정 LLM을 선택하는 명확한 기준은 없습니다. 실제로 오픈소스 LLM은 아키텍처, 훈련 데이터 입력, 하이퍼파라미터 튜닝 방식의 차이로 인해 약점과 강점, 이질성을 드러냅니다.
결과적으로 많은 사용자가 자신의 LLM을 맞춤화하기 위해 미세 조정(Fine-Tuning)이나 처음부터 새로 학습시키는 방식을 채택합니다. 그러나 이 방식은 계산 비용이 많이 들고 대규모 데이터 수집 및 희소한 GPU 자원으로 인해 어려움을 겪습니다.
미세 조정은 자원 친화적인 방식이지만, 상당한 전문가 지식과 엔지니어링이 필요합니다. 게다가 대부분의 LLM은 사용자 정의 최적화를 제한하고 블랙박스 API로만 제공됩니다.
이런 이유로, 더 많은 사용자들이 LLM을 활용하여 애플리케이션을 구축하고 있지만, 비용 절감, 추론 지연 시간, 응답 정확도와 같은 현실적인 측면이 주요 관심사가 되었습니다. 예를 들어 최신 LLM은 수십억 개의 매개변수를 포함하고 있어 높은 전력 소모와 계산량을 요구합니다. 특히 대규모 데이터 처리에서 인공지능의 발전은 비용 부담을 증가시켰으며, OpenAI의 GPT-4의 경우 8K 컨텍스트에서 32K 토큰 처리 시, 4K 컨텍스트 처리 비용의 약 20배에 달합니다. 또한, OpenAI의 커스터마이징 지원 서비스 비용은 연간 $21K에 이를 수 있습니다.
2 관련 연구
기존의 LLM 선택 최적화 솔루션은 주로 비용, 응답 정확도 중 하나에만 중점을 두었으며, 여러 다른 성능 지표는 고려하지 않았습니다. [3]에서는 점진적으로 점점 더 복잡해지는 LLM을 순차적으로 사용하는 방식을 제안했습니다. 이를 위해 미세한 모델에서 점진적으로 더 크고 복잡한 모델로 계단식으로 전환하는 방식입니다(특히 DistilBERT를 활용). 비슷하게, AutoMix [14]는 더 작은 LLM을 사용하여 출력을 사전 검사하고 이후 더 큰 LLM으로 쿼리를 라우팅합니다.
LLM 캐스케이딩 기법은 [11]에서도 사용되었습니다. 여기서 저자들은 "응답 일관성" [24]이라는 개념을 도입하여, 약한 LLM의 응답이 쿼리 난이도를 반영하여 더 강력하고 더 비싼 LLM으로 라우팅할지 결정하는 방식입니다.
다른 연구들은 매우 계산 집약적인 사전 훈련된 대규모 모델이나 사용자 맞춤형 데이터가 없는 일반 데이터세트의 사전 훈련 모델을 활용하는 방식을 사용했습니다. 이는 다양한 사용자 사례에 대한 일반화 성능을 제공하지 못합니다. [21]에서는 언어 모델의 기존 예제와 관련된 쿼리를 활용하여 회귀 모델을 사용하는 방식을 사용했습니다. [22]에서는 수백 개의 데이터셋으로 LLM을 훈련한 후, 분류 태스크를 평가하였습니다.
[15]에서는 쿼리-응답 단위로 모델 랭킹을 수행하여 더 약한 LLM을 비교하여 전문가 경험을 통합하는 방식을 사용했습니다. 이 과정에서 표준화된 보상 값이 라우팅 기능 학습에 사용됩니다.
마지막으로 [10]의 연구는 LLM이 제공하는 모든 가능한 출력을 평가한 후 최적의 LLM을 선택하는 방식을 사용합니다. [20]에서는 순위 측정과 스코어링을 통해 후보 모델을 평가하는 방식입니다. [10]에서는 쿼리 응답에 대해 후보 모델 출력을 비교하는 쌍별 비교(pairwise comparison)를 사용하였습니다.
최근에는 LLM 라우팅 문제를 해결하기 위해 RL(강화 학습) 기반 접근 방식도 제안되었습니다 [19]. 이 방법은 더 강력한 모델과 더 약한 모델을 라우팅하여 비용을 최소화하면서 성능을 확보하는 전략입니다.
3 PickLLM
3.1 전체 프레임워크
PickLLM은 주어진 쿼리에 대해 특정 LLM을 선택하고 라우팅하는 문제를 다룹니다. 사용자는 LLM 모델 풀(pool)을 사용할 수 있으며, 다양한 성능과 비용을 가진 모델로 구성됩니다. 각 라운드에서 PickLLM은 쿼리를 특정 모델에 라우팅하고, 여러 메트릭을 기준으로 응답 품질을 평가합니다.
3.2 보상 함수 공식화
보상 함수는 사용자의 경험과 만족도를 반영하는 몇 가지 주요 성능 지표를 기반으로 정의됩니다. 각 모델 m에 대해 다음과 같은 메트릭이 정의됩니다:
- : 쿼리당 비용
- : 추론 지연 시간
- : 응답 정확도 (인간 피드백 혹은 자동 채점에 기반)
이 보상 함수는 다음과 같이 정의됩니다:
여기서 는 비용, 지연 시간, 정확도에 할당된 가중치입니다.
3.3 경사 상승 학습 (Gradient Ascent Learning)
첫 번째 학습 방법은 PickLLM이 SLA (Stochastic Learning Automaton)로 동작하는 방식입니다. 학습자는 반복적으로 보상 값을 업데이트하며, 선택 확률을 조정합니다. 선택 확률 벡터 는 각 라운드에서 특정 LLM을 선택할 확률을 나타냅니다.
각 학습 라운드에서 선택된 LLM m에 대한 업데이트 공식은 다음과 같습니다:
여기서 는 학습률을 나타내며, 다른 LLM 에 대한 확률은 다음과 같이 업데이트됩니다:
3.4 상태 없는 Q-러닝 (Stateless Q-learning)
두 번째 학습 방법은 상태 없는 Q-러닝 기반입니다. 각 라운드에서 특정 LLM을 선택하고, 보상을 통해 업데이트합니다. PickLLM은 보상 값의 기록을 통해 다음 쿼리에서 더욱 최적의 선택을 하도록 학습합니다.
[Figure 1. SLA 기반 PickLLM 프레임워크]
도표에서 사용자가 쿼리를 입력하면, PickLLM 라우터가 각 모델의 성능을 평가하여 특정 LLM을 선택하고, 결과를 반환합니다. 학습 과정은 강화 학습 피드백을 기반으로 모델 선택 확률을 조정하는 방식으로 진행됩니다.
3.5 상태 없는 Q-러닝 (Stateless Q-Learning)
PickLLM은 Q-러닝 기반의 비상태 학습 방법을 활용하여 특정 LLM을 선택하고, 반복적인 보상 업데이트를 통해 학습합니다. 각 LLM mm에 대한 유틸리티를 로 정의하며, 해당 유틸리티는 주어진 시간 t에서 LLM m을 선택했을 때의 기대 보상을 나타냅니다.
각 라운드에서 선택된 LLM의 보상은 다음의 Q-러닝 업데이트 규칙을 따릅니다:
여기서 은 학습률로, 업데이트 크기를 조절합니다. LLM 선택을 위해 PickLLM은 -탐욕적(e-greedy) 접근 방식을 사용하며, 이 방식은 다음과 같습니다:
- 확률 : 가장 높은 Q값을 가진 LLM 선택
- 확률 : 무작위 LLM 선택
이로 인해 PickLLM은 탐색과 활용을 균형 있게 조정할 수 있습니다.
4 성능 평가 (Performance Evaluation)
4.1 실험 환경 (Experimental Setup)
실험 환경은 로컬 호스팅과 원격 LLM API를 혼합하여 구성되었습니다. 로컬 클라이언트는 Hugging Face의 Llama-2 13B 모델을 사용했으며, 24개 CPU 코어와 32GB RAM 환경에서 실행되었습니다.
사용된 LLM 풀(pool)은 다음과 같습니다:
- Mistral-7B
- WizardLM-70B
- Llama2-70B
이와 함께 HC3 데이터셋의 영어 질문 데이터 (퀴즈 및 오픈형 질문)를 사용했습니다.
비용 관련 시뮬레이션:
- 비용 벡터: (Mistral, WizardLM, Llama2 순서)
- 지연 시간: 사용자 요청 후 모델의 응답까지의 시간(밀리초 단위)
- 응답 품질: OpenAI의
gpt-3.5-turbo기반 평가지표를 활용
4.2 평가 및 논의 (Evaluation and Discussion)
학습률 비교:
학습률 β 값을 다양하게 설정하여 PickLLM의 수렴 속도와 보상 함수를 비교했습니다. 결과적으로 학습률이 증가함에 따라 PickLLM은 더 작은 보상을 제공하는 모델로 수렴하는 경향을 보였으며, 이는 응답 품질의 저하로 이어졌습니다.
- = 0.5에서 수렴 속도와 성능의 균형이 가장 잘 맞음
- ϵ 탐욕적 Q-러닝에서 이 최적
비용 및 지연 시간 조정:
비용 및 지연 시간의 중요도를 변경하여 PickLLM이 특정 쿼리 환경에 얼마나 잘 조정되는지 확인했습니다.
- 보상 가중치 설정
- PickLLM SLA 방식이 최적의 비용을 제공하며, 최소 비용 52% 감소
4.3 LLM 간 비교 (Table 1 및 Figures)
Table 1: PickLLM, GPT-3, Llama2 및 Mixtal 비교 결과
- HC3 데이터셋에서 PickLLM은 GPT-3에 비해 평균적으로 더 낮은 비용과 빠른 지연 시간 제공
Figure 3 (오른쪽): 총 비용 비교
- PickLLM SLA 및 Q-러닝 방식이 다른 모델에 비해 총 비용을 절감함
Figure 4 (오른쪽): 평균 지연 시간
- PickLLM SLA 방식이 52% 더 낮은 지연 시간 제공
5 향후 연구 (Future Work)
PickLLM은 데이터 및 운영 요구사항에 맞춰 LLM 선택을 안내하는 방식으로 확장될 수 있습니다. 이후 연구에서는 강화 학습 모델을 기반으로 한 RL 기법을 확장할 예정입니다.
- 강화 학습 개선: 다중 무장 강도기법(Multi-Armed Bandits) 및 신경망 기반 학습을 적용
- 사용자 맞춤화: 사용자 컨텍스트를 고려한 LLM 추천
- 확장성: GPU 메모리, 환경 영향 및 라이선스 고려
6 결론 (Conclusion)
이 연구에서는 사용자가 최적의 LLM을 선택할 수 있도록 강화 학습 기반 PickLLM 프레임워크를 소개했습니다. PickLLM은 비용, 지연 시간, 응답 품질을 조정하며, 최소 50~60%의 비용 절감을 가능하게 합니다.
