https://arxiv.org/pdf/2407.16833
초록(Abstract)
Retrieval Augmented Generation (RAG)은 과도하게 긴 컨텍스트를 효율적으로 처리하기 위해 대형 언어 모델(LLMs)에 강력한 도구로 사용되어 왔습니다. 하지만 최근 LLM인 Gemini1.5와 GPT-4는 긴 컨텍스트를 직접 이해하는 데 뛰어난 능력을 보여주고 있습니다. 우리는 RAG와 긴 컨텍스트(LC) LLM을 종합적으로 비교하여 둘의 강점을 모두 활용하려고 합니다. 우리는 다양한 공개 데이터셋을 사용하여 RAG와 LC를 최신 LLM 3개를 대상으로 비교했습니다. 결과적으로 충분한 리소스를 사용하면 LC가 평균적인 성능 면에서 항상 RAG보다 우수하다는 것을 발견했습니다. 하지만 RAG의 매우 낮은 비용은 여전히 분명한 장점입니다. 이러한 관찰을 기반으로 우리는 SELF-ROUTE라는 간단하지만 효과적인 방법을 제안하며, 이는 모델의 자체 평가에 기반해 쿼리를 RAG 또는 LC로 라우팅하는 방식입니다. SELF-ROUTE는 비용을 크게 줄이면서 LC와 유사한 성능을 유지합니다. 우리의 결과는 RAG와 LC를 사용하는 LLM의 긴 컨텍스트 응용 분야에 대한 가이드를 제공합니다.
1. 소개(Introduction)
Retrieval Augmented Generation (RAG)은 대형 언어 모델(LLMs)이 외부 지식을 활용하는 효과적이고 효율적인 접근 방식으로 알려져 있습니다. RAG는 쿼리에 기반하여 관련 정보를 검색한 후, 검색된 정보의 컨텍스트 내에서 LLM이 응답을 생성하도록 합니다. 이 접근 방식은 최소한의 비용으로 LLM이 방대한 양의 정보를 활용할 수 있도록 합니다.
그러나 최근의 LLM인 Gemini 및 GPT-4는 긴 컨텍스트를 직접 이해하는 데 있어 뛰어난 능력을 보여주고 있습니다. 예를 들어, Gemini 1.5는 최대 100만 개의 토큰을 처리할 수 있습니다(Reid et al., 2024). 이는 RAG와 긴 컨텍스트(LC) LLM 간의 체계적인 비교가 필요함을 시사합니다.
한편으로 RAG는 개념적으로 사전 지식을 제공하고 LLM의 주의를 검색된 부분에 집중시켜 불필요한 정보를 피하고 불필요한 계산을 줄입니다. 반면, 대규모 사전 학습은 LLM이 더욱 강력한 긴 컨텍스트 처리 능력을 개발할 수 있게 합니다. 따라서 우리는 RAG와 LC를 비교하고 이들의 성능과 효율성을 평가하고자 합니다.
이 연구에서 우리는 다양한 공개 데이터셋을 활용하여 RAG와 LC를 체계적으로 비교하고, 그 장단점을 종합적으로 파악하여 이 둘을 결합하여 최상의 결과를 얻는 방법을 제시합니다. 이전 연구(Xu et al., 2023)와는 달리, 우리는 충분한 리소스를 사용할 때 LC가 거의 모든 설정에서 RAG보다 일관되게 우수하다는 것을 발견했습니다. 이는 최근 LLM이 긴 컨텍스트를 이해하는 데 있어 탁월한 진보를 이뤘음을 보여줍니다.
최적의 성능이 아니더라도, RAG는 그 비용 효율성으로 인해 여전히 중요합니다. LC와 비교하여 RAG는 LLM의 입력 길이를 상당히 줄여 비용을 절감할 수 있습니다. LLM API 가격 책정은 일반적으로 입력 토큰 수에 기반하기 때문입니다(Google, 2024; OpenAI, 2024b). 더 나아가, 우리의 분석 결과 LC와 RAG의 예측이 60% 이상의 쿼리에서 동일하다는 것을 발견했습니다. 이러한 쿼리의 경우 RAG는 성능을 희생하지 않고 비용을 줄일 수 있습니다.
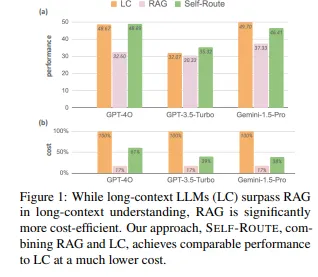
이러한 관찰을 기반으로, 우리는 SELF-ROUTE라는 간단하지만 효과적인 방법을 제안합니다. SELF-ROUTE는 모델의 자체 평가에 기반해 쿼리를 RAG 또는 LC로 라우팅합니다. SELF-ROUTE를 통해 우리는 비용을 크게 줄이면서 LC와 유사한 전체적인 성능을 달성할 수 있습니다. 예를 들어, Gemini-1.5-Pro의 경우 비용이 65%, GPT-4O의 경우 39% 줄어듭니다. 그림 1은 GPT-4O, GPT-3.5-Turbo 및 Gemini-1.5-Pro의 세 가지 최신 LLM을 사용하여 LC, RAG 및 SELF-ROUTE를 비교한 결과를 보여줍니다. 정량적 평가에 더해, 우리는 RAG와 LC를 비교하는 종합적인 분석, RAG의 일반적인 실패 패턴, 비용과 성능 간의 균형, 추가적인 인공 데이터셋에 대한 결과 등을 제공합니다. 우리의 분석은 RAG의 향후 개선에 영감을 주고, RAG와 LC를 사용하는 긴 컨텍스트 응용 프로그램 구축을 위한 실증적인 가이드가 됩니다.
2. 관련 연구(Related Work)
긴 컨텍스트 LLMs(Long-context LLMs): LLM이 긴 컨텍스트를 처리할 수 있게 하는 연구는 오래전부터 진행되어 왔습니다(Guo et al., 2022; Beltagy et al., 2020; Chen et al., 2023b). 최근 LLM인 Gemini-1.5 (Reid et al., 2024), GPT-4 (Achiam et al., 2023), Claude3 (Anthropic, 2024)는 컨텍스트 창 크기가 크게 증가했지만, 긴 컨텍스트 프롬프트는 여전히 입력 토큰 수에 대한 변환기(Transformer)의 이차 비용으로 인해 비용이 많이 듭니다. 최근 연구에서는 프롬프트 압축(Jiang et al., 2023), 모델 증류(Hsieh et al., 2023), LLM 연쇄(Cascading) (Chen et al., 2023a)와 같은 방법을 제안하여 비용을 줄이려고 합니다.
RAG(Retrieval-Augmented Generation): RAG는 LLM을 다양한 소스로부터 검색된 관련 정보로 보강하는 방식으로, 외부 지식을 보완하는 데 성공적인 방법입니다(Lewis et al., 2020). RAG는 언어 모델링(Khandelwal et al., 2019; Shi et al., 2023) 및 QA(Guu et al., 2020; Izacard and Grave, 2020) 등 다양한 작업에서 좋은 성능을 보여주며, 매우 낮은 계산 비용으로 수행됩니다(Borgeaud et al., 2022). 최근에는 RAG에 오류 수정(Yan et al., 2024), 비판(Asai et al., 2023), 검증(Li et al., 2023)을 추가하여 지식 집약적인 작업에서 검색 품질을 향상하려는 연구가 진행되고 있습니다.
긴 컨텍스트 평가(Long-context evaluation): 긴 컨텍스트 모델을 평가하는 것은 긴 텍스트를 수집하고 분석하는 어려움 때문에 도전적인 과제입니다. 최근 연구자들은 Needle-in-a-haystack (Greg Kamradt, 2023), Ruler (Hsieh et al., 2024), Counting Stars (Song et al., 2024)와 같은 인공 테스트와 LongBench (Bai et al., 2023), ∞Bench (Zhang et al., 2024), L-Eval (An et al., 2023) 등의 실제 데이터셋을 제안했습니다. 이 데이터셋을 사용하여 최근 연구들은 다양한 컨텍스트 길이에 따른 성능 저하를 연구하고(Levy et al., 2024; Hsieh et al., 2024), 중앙에 놓친 현상(Lost-in-the-middle phenomenon)을 탐구하며(Liu et al., 2024), 이를 해결할 방법을 찾고 있습니다(Kuratov et al., 2024). 이와 관련하여 Xu et al. (2023)은 RAG와 긴 컨텍스트 프롬프트를 비교하여 긴 컨텍스트 모델이 여전히 RAG에 뒤처진다는 결과를 보고했는데, 이는 우리가 더 강력한 LLM과 더 긴 컨텍스트를 고려했기 때문에 우리의 결과와 다릅니다.
3. RAG 대 LC 벤치마킹(Benchmarking RAG versus LC)
3.1 데이터셋 및 지표 (Datasets and metrics)
우리는 LongBench(Bai et al., 2023) 및 ∞Bench(Zhang et al., 2024)의 일부 데이터셋을 사용하여 평가했습니다. 이들은 LLM 평가를 위해 최근에 만들어진 다양한 새롭고 기존 데이터셋의 모음이며, 다국어로 된 인공 및 실제 텍스트를 포함합니다. LongBench에는 평균 컨텍스트 길이가 7k 단어인 21개의 데이터셋이 포함되어 있습니다. ∞Bench는 평균 길이가 100k 토큰인 훨씬 더 긴 컨텍스트로 구성됩니다.
데이터셋 중에서, 우리는 주로 다음 조건을 만족하는 데이터셋에 초점을 맞췄습니다: (a) 영어로 작성되었으며, (b) 실제 텍스트이며, (c) 쿼리 기반인 데이터셋
(예: 요약 작업은 검색 관련 정보를 포함하는 쿼리가 없습니다). 이를 통해 LongBench의 NarrativeQA(Kocisky et al., 2018), Qasper(Dasigi et al., 2021), MultiFieldQA(Bai et al., 2023), HotpotQA(Yang et al., 2018), 2WikiMultihopQA(Ho et al., 2020), MuSiQue(Trivedi et al., 2022), QMSum(Zhong et al., 2021) 및 ∞Bench의 En.QA 및 EN.MC를 포함하는 총 9개의 데이터셋을 선정했습니다. 자세한 내용은 부록 A를 참조하세요. 또한, 5.4절에서는 ∞Bench에서의 인공 데이터셋 PassKey에 대한 분해 연구 결과를 제공할 것입니다.
평가 지표로는, 오픈엔드 QA 작업의 F1 점수, 다중 선택 QA 작업의 정확도, 요약 작업의 ROUGE 점수를 보고합니다.
3.2 모델 및 검색기 (Models and Retrievers)
세 개의 최신 LLM을 평가했습니다: Gemini-1.5-Pro(Reid et al., 2024), GPT-4O(OpenAI, 2024a), 및 GPT-3.5-Turbo(OpenAI, 2023). Gemini-1.5-Pro는 Google에서 개발한 최신 장기 컨텍스트 LLM이며, 최대 100만 개의 토큰을 지원합니다. GPT-4O는 OpenAI에서 출시한 새로운 경량이면서 강력한 LLM이며, 128k 토큰을 지원합니다. GPT-3.5-Turbo는 16k 토큰을 지원합니다.
이 연구에서는 두 가지 검색기를 사용했습니다: Contriever(Izacard et al., 2021)과 Dragon(Lin et al., 2023)입니다. Contriever는 BEIR 데이터셋에서 BM25를 능가하는 대조 훈련된 밀도 검색기이며, Dragon은 복잡한 후기 상호 작용 없이도 감독 및 제로샷 설정에서 높은 성능을 발휘하는 최근의 일반화 가능한 밀도 검색기입니다. (Xu et al., 2023)을 따라, 우리는 긴 컨텍스트를 300 단어로 분할하고, 쿼리 임베딩과 청크 임베딩 간의 코사인 유사성을 기반으로 상위 k개의 청크(기본값 k = 5)를 선택했습니다. 청크는 유사도 점수에 따라 정렬되며, 청크 인덱스는 시작 부분에 추가됩니다.
사전 학습된 LLM이 알 수 없는 데이터셋으로 사전 훈련되었기 때문에, 평가 데이터셋의 유출이 발생할 수 있습니다. 특히, 일부 평가 데이터셋은 Wikipedia를 기반으로 하고 있어, LLM이 이미 사전에 이 데이터를 학습했을 가능성이 높습니다. 때로는 모델이 제공된 컨텍스트에 나타나지 않는 경우에도 정답과 동일한 단어(예: "meticulously")를 사용하여 정확한 답을 예측하는 경우를 발견했습니다. 실험에서 우리는 RAG와 LC 모두 "제공된 텍스트에만 기반하여" 답변을 하도록 모델에 프롬프트를 제공하여 이 문제를 완화하려고 시도했습니다. LLM 평가에서 데이터 유출 문제를 해결하는 것은 여전히 미해결 과제로 남아 있습니다.
3.3 벤치마킹 결과 (Benchmarking results)
우리는 Gemini-1.5-Pro, GPT-4O 및 GPT-3.5-Turbo라는 세 개의 최신 LLM을 사용하여 9개의 데이터셋 전반에서 LC와 RAG의 성능을 벤치마킹했습니다. 표 1은 Contriever 검색기를 사용한 결과를 보여주며, -1 행은 LC의 결과를, -2 행은 RAG의 결과를 나타냅니다. Dragon 검색기를 사용한 결과는 5.3절과 표 2에서 논의됩니다.
표 1에 나타난 바와 같이, LC는 세 모델 모두에서 RAG보다 항상 우수한 성능을 보입니다. 평균적으로 LC는 Gemini-1.5-Pro에서 RAG보다 7.6%, GPT-4O에서 13.1%, 그리고 GPT-3.5-Turbo에서 3.6% 더 뛰어났습니다. 주목할 점은, 더 최근의 모델(GPT-4O 및 Gemini-1.5-Pro)이 이전 모델인 GPT-3.5-Turbo보다 성능 격차가 더 크다는 것입니다. 이는 최신 LLM이 긴 컨텍스트를 이해하는 데 있어 탁월한 능력을 보임을 나타냅니다.
하지만 두 가지 예외가 있습니다. ∞Bench의 두 개의 더 긴 데이터셋(En.QA 및 En.MC)에서는, RAG가 GPT-3.5-Turbo에서 LC보다 더 나은 성능을 보여줍니다. 이 결과는 전체적인 추세와 다르며, 이는 이 데이터셋의 매우 긴 컨텍스트(평균 147k 단어)가 GPT-3.5-Turbo의 제한된 컨텍스트 창(16k)과 비교되었기 때문입니다. 이 발견은 입력 텍스트가 모델의 컨텍스트 창 크기를 상당히 초과할 때 RAG가 효과적일 수 있음을 강조하며, RAG의 특정 사용 사례를 강조합니다.
4. SELF-ROUTE
4.1 동기 (Motivation)
3장에서 보여준 바와 같이, RAG는 긴 컨텍스트 LLM에 비해 성능이 뒤처집니다. 그러나 이러한 성능 격차에도 불구하고 RAG와 LC의 예측 결과가 상당히 유사하다는 것을 알 수 있었습니다. 이는 그림 2에 나타나 있습니다.
그림 2는 RAG의 예측 점수와 LC의 예측 점수 간의 차이 분포를 보여줍니다. RAG와 LC의 예측은 대부분 매우 유사하며, 63%의 쿼리에서는 모델의 예측이 정확히 동일했습니다. 또한, 70%의 쿼리에서 점수 차이는 절대값으로 10 미만이었습니다. 이는 RAG와 LC가 동일한 정확한 예측뿐만 아니라 유사한 오류도 만드는 경향이 있음을 보여줍니다.
이 발견을 통해 대부분의 쿼리에 대해서는 RAG를 활용하고, LC가 특히 뛰어난 소수의 쿼리에만 비용이 많이 드는 LC를 사용하는 방법을 생각해 볼 수 있습니다. 이를 통해 RAG는 전체적인 성능을 희생하지 않고도 계산 비용을 크게 줄일 수 있습니다.
4.2 SELF-ROUTE
위의 동기를 바탕으로, 우리는 SELF-ROUTE라는 간단하지만 효과적인 방법을 제안하며, 이는 RAG와 LC를 결합하여 비용을 줄이면서 LC와 유사한 성능을 유지합니다. SELF-ROUTE는 LLM 자체를 사용하여 자체 평가를 기반으로 쿼리를 라우팅합니다.
구체적으로, 이 방법은 두 단계로 구성됩니다. 첫 번째 단계에서는 쿼리와 검색된 청크를 LLM에 제공하고, 쿼리가 응답 가능한지 예측하고, 그렇다면 답변을 생성하도록 요청합니다. 이는 일반적인 RAG와 비슷하지만 한 가지 차이점은 LLM이 "제공된 텍스트를 기반으로 답변할 수 없는 경우, '답변 불가'라고 작성하십시오"라는 프롬프트를 사용하여 답변을 거부할 수 있다는 것입니다.
답변이 가능하다고 판단된 경우, 우리는 RAG 예측을 최종 답변으로 받아들입니다. 답변이 불가능하다고 판단된 경우, 우리는 전체 컨텍스트를 긴 컨텍스트 LLM에 제공하여 최종 예측을 얻습니다.
결과적으로, 대부분의 쿼리는 첫 번째 RAG 및 라우팅 단계에서 해결될 수 있으며, 적은 부분만 긴 컨텍스트 예측 단계가 필요합니다. 첫 번째 단계에서는 검색된 청크만 입력으로 사용되므로, 전체 컨텍스트(예: 10k - 100k 토큰)보다 훨씬 짧아져서 전체 계산 비용이 크게 줄어듭니다.
4.3 결과 (Results)
표 1의 -3에서 -5 행에 우리 방법의 결과가 나타나 있습니다. -3 행은 성능을 보고합니다. -4 행은 RAG 및 라우팅 단계에서 답변 가능한 쿼리의 백분율을 보여줍니다. *-5 행은 우리 방법이 LC에 비해 사용한 토큰의 백분율을 나타냅니다.
성능 측면에서(*-3 행), SELF-ROUTE는 RAG보다 훨씬 우수한 성능을 보여주며, LC와 비슷한 결과를 달성했습니다. 모든 세 모델에서 SELF-ROUTE는 RAG보다 5% 이상 뛰어났습니다. LC와 비교하면(GPT-4O의 경우 -0.2%, Gemini-1.5-Pro의 경우 -2.2% 약간의 성능 저하가 있었으나, GPT-3.5-Turbo의 경우 +1.7%의 성능 향상이 있었습니다.
세 LLM 모두 쿼리의 절반 이상을 RAG로 라우팅합니다. Gemini-1.5-Pro의 경우, 라우팅 단계에서 답변 가능한 백분율이 81.74%에 이르렀습니다(행 1-4). 이는 대부분의 쿼리를 LC 없이도 RAG가 답변할 수 있음을 나타내며, 초기 동기를 확인시켜줍니다.
높은 답변 가능성 때문에, 사용된 토큰 수는 크게 줄어듭니다(행 *-5). 예를 들어, GPT-4O는 LC의 토큰의 61%만을 사용하면서도 LC와 비교 가능한 성능(46.83)을 달성했습니다. Gemini-1.5-Pro의 경우 토큰의 38.6%만 사용했습니다. 변환기 기반 LLM의 계산 비용이 토큰 수에 대해 이차적이며, 대부분의 LLM API가 토큰 수에 따라 비용을 부과하므로(OpenAI, 2024b; Google, 2024), 이 낮은 토큰 수는 상당한 비용 절감으로 이어집니다.
더 긴 데이터셋에서는 우리의 방법의 이점이 OpenAI 모델에서 더 뚜렷하게 나타났으며, Gemini에서는 덜 명확했습니다. 예를 들어, GPT-4O의 경우 SELF-ROUTE가 EN.QA 및 EN.MC에서 LC보다 각각 2.3%와 7.4% 우수한 성능을 보였습니다. GPT-3.5-Turbo에서는 이 격차가 더욱 컸습니다. 그러나 Gemini-1.5-Pro의 경우, LC보다 낮은 성능을 보였습니다. 이러한 차이는 LLM 정렬의 차이 때문일 수 있습니다. OpenAI 모델은 RAG를 사용하여 답변하는 것을 더 자주 거부하기 때문에 더 낮은 답변 가능성을 보이지만 높은 정확도를 달성하며, Gemini-1.5-Pro와 비교했을 때 다른 성능-비용 균형을 만들어냅니다.
5. 분석 (Analysis)
5.1 k의 영향 분석(Ablations of k)
RAG와 SELF-ROUTE는 상위 k개의 검색된 텍스트 청크에 의존합니다. k가 클수록 RAG 예측 및 라우팅을 위해 LLM에 더 긴 컨텍스트가 입력되어 비용과 성능에 영향을 미칩니다. 그림 3에서는 다양한 k 값을 사용할 때의 성능과 비용(즉, 입력 토큰 비율)을 보여줍니다.
성능 측면에서는 RAG와 SELF-ROUTE 모두에서 k가 커질수록 성능이 향상됩니다. k가 커질수록 더 많은 청크가 LLM에 입력되므로, 성능이 점차적으로 LC에 가까워집니다. 그림의 곡선에서 볼 수 있듯이, SELF-ROUTE의 이점은 더 작은 k에서 가장 큽니다. 예를 들어, k=1일 때, RAG는 20.24%를 달성한 반면 SELF-ROUTE는 37.9%를 달성했습니다. 그러나 k가 50 이상이 되면 세 가지 방법 모두 유사한 성능을 보입니다.
그러나 SELF-ROUTE의 비용 추세는 단조롭지 않습니다. k=5에서 비용이 최저치에 도달했습니다. 이는 k가 증가함에 따라 RAG(및 라우팅)의 비용이 증가하지만 더 많은 쿼리가 LC에서 RAG로 라우팅되기 때문입니다. k의 적절한 지점은 각 데이터셋마다 다를 수 있습니다. 예를 들어, 평균적으로 k=5가 가장 낮은 비용을 보이지만, 내러티브QA 및 QMSum과 같은 멀티홉 추론이 필요하지 않은 추출형 질문이 포함된 데이터셋에서는 k=1이 최저 비용을 보여줍니다. 이는 k의 최적 값이 작업의 특성 및 성능 요구 사항에 따라 다름을 나타내며, 향후 연구자가 다양한 응용 프로그램에 이 방법을 적용할 때 다른 k 값을 찾아볼 것을 권장합니다.
5.2 왜 RAG가 실패하는가?(Why does RAG fail?)
우리는 RAG가 LC에 비해 뒤처지는 이유를 더 잘 이해하기 위해 RAG로 답변할 수 없는 사례를 분석했습니다. 먼저 우리가 "답변 불가"로 예측한 일부 사례를 수동으로 확인하여 네 가지 일반적인 실패 원인을 요약한 다음, LLM에 모든 사례를 분류하도록 프롬프트했습니다.
이 네 가지 원인은 다음과 같습니다:
(A) 쿼리가 다단계 추론을 필요로 하여 이전 단계의 결과가 이후 단계의 정보 검색에 필요할 때. 예: "노래 XXX의 연주자의 국적은 무엇인가?"
(B) 쿼리가 일반적인 경우, 예: "그룹은 XXX에 대해 어떻게 생각하는가?", 이는 검색기가 좋은 쿼리를 형성하기 어렵게 합니다.
(C) 쿼리가 길고 복잡하여 검색기가 이해하기 어려운 경우입니다. 그러나 이러한 질문을 답변하는 것은 LLM의 장점입니다.
(D) 쿼리가 암시적이며 전체 컨텍스트에 대한 완전한 이해를 요구하는 경우입니다. 예를 들어, 우주 항해에 대한 긴 대화에서 "우주선 뒤에 그림자가 생긴 원인은 무엇인가?"와 같은 질문은 독자가 정보를 연결하고 답을 추론해야 하며 원인이 공개될 때 그림자에 대한 명시적인 언급이 없기 때문입니다.
이러한 이유를 바탕으로 우리는 Gemini-1.5-Pro를 사용하여 우리가 수동으로 주석을 단 몇 가지 예를 제시하고 모든 "답변 불가" 사례를 네 가지 카테고리로 분류했습니다. 그림 4는 LongBench의 7개 데이터셋에 대한 실패 원인의 분포를 보여줍니다. 각 데이터셋은 서로 다른 수의 RAG 실패 사례를 포함하며, 이에 따라 막대의 높이도 다릅니다.
데이터셋의 특성에 따라 일관된 분포 패턴을 관찰할 수 있습니다. 예를 들어, Wikipedia 기반의 멀티홉 추론 데이터셋인 HotpotQA, 2WikiMQA, MuSiQue는 다단계 검색 때문에 RAG에게 도전적입니다(파란색으로 표시됨). 내러티브QA는 긴 스토리와 많은 대화를 포함하고 있어, 대부분의 실패 사례가 전체 컨텍스트를 이해해야 하는 암시적 쿼리 때문입니다(초록색으로 표시됨). QMSum은 요약 데이터셋으로서 개방형 질문을 포함하므로 실패 사례는 대부분 일반 쿼리 때문입니다(빨간색으로 표시됨). 우리는 "기타"로 분류된 예를 수동으로 확인했으며, 대부분은 다단계 질문으로, 모호성이 종종 포함되어 있어 답변에 어려움을 겪게 했습니다.
우리는 이 실패 분석이 RAG의 향후 개선에 영감을 주기를 바랍니다. 예를 들어, Chain-of-Thought(Wei et al., 2022)를 RAG에 도입하면 다단계 질문을 해결하는 데 도움이 될 수 있으며, 쿼리 확장(Lv and Zhai, 2009; Zhai and Lafferty, 2001)과 같은 쿼리 이해 기술을 다시 검토하면 일반적인 쿼리와 복잡한 쿼리 처리에 도움이 될 수 있습니다. 최근 이러한 방향으로의 노력을 보게 되어 기쁘게 생각합니다(Chan et al., 2024; Ma et al., 2023).
5.3 다른 검색기 사용 (Different retrievers)
Dragon 검색기를 사용한 Gemini-1.5-Pro의 결과는 표 2에 나와 있습니다. Contriever와 비교하여 LC, RAG, SELF-ROUTE 모두에서 일관된 결과를 보여주며, 우리의 발견이 검색기 전반에 일반화될 수 있음을 확인했습니다.
5.4 인공 데이터에 대한 결과 (Results on synthetic data)
이번 연구에서는 연구자가 인공적으로 생성한 데이터에 내재된 편향 때문에, 인공 데이터보다 실제 데이터에 초점을 맞췄습니다. 예를 들어, ∞Bench의 "PassKey" 데이터셋에 대한 결과를 설명합니다.
이 "PassKey" 데이터셋은 쿼리에서 "패스키가 무엇인가?"라는 질문에 답하도록 하는 테스트로서 강력한 검색 능력을 요구합니다. 이 데이터셋에서 RAG는 Gemini-1.5-Pro를 사용하여 80.34%의 정확도를 달성했으며 LC(65.25%)를 능가했습니다. 그러나 쿼리를 "텍스트 내에 숨겨진 특별한 토큰은 무엇인가?"로 약간 수정하면, RAG의 정확도는 4.58%로 급락했고, LC는 거의 동일한 69.32%를 유지했습니다. 또 다른 예로, 청크에 두 개의 패스키가 포함되어 있고 쿼리가 "어느 패스키가 더 큰가?"라면 RAG는 47.63%의 정확도를 달성했고, LC는 64.24%였습니다.
이러한 예는 평가 결과가 데이터셋 구성에서 발생하는 편향에 크게 의존할 수 있음을 보여주며, 인공 테스트의 한계를 나타냅니다.
6. 결론 (Conclusion)
이 논문은 RAG와 LC를 종합적으로 비교하여 성능과 계산 비용 간의 균형을 강조합니다. LC는 긴 컨텍스트 이해에서 우수한 성능을 보여주지만, RAG는 그 비용 효율성과 모델의 컨텍스트 창 크기를 크게 초과하는 입력이 있을 때의 장점으로 인해 여전히 유효한 선택입니다. 우리가 제안한 방법은 모델 자체 평가를 기반으로 쿼리를 동적으로 라우팅하여, RAG와 LC의 강점을 결합하여 비용을 크게 줄이면서도 LC와 유사한 성능을 달성합니다. 우리는 이 결과가 긴 컨텍스트 LLM의 실제 적용에 대한 귀중한 통찰력을 제공하고, RAG 기술의 최적화를 위한 미래 연구의 방향을 제시한다고 믿습니다.
