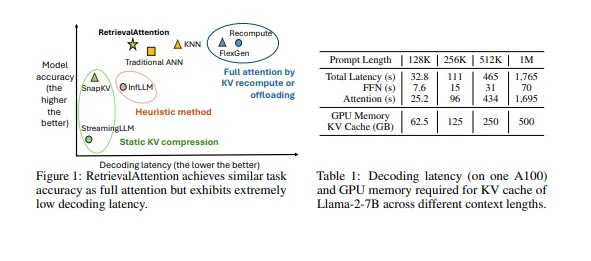
RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval
long context
이 논문은 RetrievalAttention이라는 방법을 제안하여, 긴 컨텍스트를 처리하는 대형 언어 모델(LLM)의 추론 효율성을 높이기 위한 새로운 접근 방식을 설명합니다. 아래는 논문의 주요 내용을 요약한 것입니다:
1. 문제 배경
대형 언어 모델은 긴 문맥을 처리할 때 주의(attention) 계산의 이차적 복잡성 때문에 계산 비용이 매우 커집니다. 특히, 과거의 키-값 벡터(KV)를 캐싱하고 재사용하는 방식이 자주 사용되지만, 이는 GPU 메모리 소모와 추론 지연을 크게 증가시키는 문제를 가지고 있습니다.
2. 핵심 아이디어: RetrievalAttention
논문은 이를 해결하기 위해 RetrievalAttention이라는 방법을 제안합니다. 이 방법은 다음과 같은 아이디어에 기반합니다:
- 주의 메커니즘의 동적 희소성을 활용하여, 쿼리 벡터와 상호작용하는 중요한 키-값 벡터만 선택적으로 사용합니다.
- 기존의 Approximate Nearest Neighbor Search(ANNS) 인덱스를 활용하여 CPU 메모리에서 KV 벡터를 검색하고, GPU 메모리의 부하를 줄입니다.
- 쿼리와 키 벡터 간의 분포 불일치(out-of-distribution, OOD) 문제를 해결하기 위해, 주의 인식 벡터 검색(Attention-aware Vector Search) 알고리즘을 도입합니다. 이는 쿼리 벡터의 분포에 맞춰 적합한 키 벡터를 선택하는 방식입니다.
3. 주요 기법
- 근사화된 주의(Approximated Attention): 주의 계산에서 중요한 토큰만 선택적으로 사용하여 전체 계산량을 줄입니다.
- 주의 인식 벡터 검색(Attention-aware Vector Search): CPU와 GPU 간에 키-값 벡터를 나누어 처리하고, GPU에서 예측 가능한 토큰을 캐시하여 성능을 향상시킵니다.
- CPU-GPU 공동 실행(Co-Execution): CPU에서 검색된 중요한 토큰과 GPU에서 처리된 부분 결과를 결합하여 주의 결과를 도출합니다.
4. 실험 결과
- 정확도: 긴 컨텍스트에서 RetrievalAttention은 완전한 주의(Fully Attention)와 비슷한 성능을 보였습니다. 다른 기존 방법들에 비해 중요한 토큰을 더 효율적으로 검색할 수 있어 성능 저하가 거의 없었습니다.
- 지연 시간: RetrievalAttention은 128K 토큰 컨텍스트에서 기존 KNN 및 ANNS 방법보다 4.9배 및 1.98배 빠른 디코딩 속도를 달성했습니다.
5. 결론
RetrievalAttention은 대부분의 키-값 벡터를 CPU 메모리로 오프로드하고, 벡터 검색을 활용하여 중요한 토큰을 동적으로 선택함으로써 추론 비용을 최소화하는 방법입니다. 이 방법은 GPU 메모리 소비를 줄이면서도 모델 성능을 거의 저하시키지 않고, RTX 4090 GPU에서 128K 토큰을 처리할 수 있는 첫 번째 시스템입니다.
이 논문은 긴 컨텍스트를 효율적으로 처리할 수 있는 새로운 방법을 제시하며, 특히 GPU 메모리가 제한된 상황에서도 성능과 정확도를 유지하는 방법을 강조합니다.
요약 (Abstract)
Transformer 기반의 대형 언어 모델(LLM)은 점점 더 중요해지고 있습니다. 하지만 주목할 점은, 주의(attention) 계산의 이차적 시간 복잡도 때문에 LLM을 더 긴 컨텍스트로 확장하는 것은 매우 느린 추론 속도와 높은 GPU 메모리 소비를 유발한다는 것입니다. 이 논문은 KV(키-값) 벡터의 캐시 문제를 해결하고 GPU 메모리 소비를 줄이기 위해 계산을 가속화하는 동시에 메모리 절약을 할 수 있는 RetrievalAttention이라는 학습 프리 접근 방식을 제안합니다. RetrievalAttention은 주의 메커니즘의 희소성(sparsity)을 활용하여, CPU 메모리에서 근사 최근접 이웃 탐색(ANNS) 인덱스를 사용해 KV 벡터를 검색하고, 생성 중에 가장 관련성 높은 벡터를 검색하는 방식입니다. 하지만 실험 결과, 오프 더 셸프(off-the-shelf) ANNS 인덱스는 종종 쿼리 벡터와 주의 메커니즘의 키 벡터 간의 분포 차이로 인해 배포 범위 밖(Out-of-Distribution, OOD)의 작업에서 비효율적임을 발견했습니다. RetrievalAttention은 이 OOD 문제를 해결하기 위해 쿼리 벡터의 분포에 적응할 수 있는 주의 인식 벡터 검색 알고리즘을 설계했습니다. 우리의 평가에서는, RetrievalAttention이 모델 정확도를 유지하면서도 데이터의 1-3%만 접근해도 충분히 동작하는 것을 확인했습니다. 이는 긴 컨텍스트 LLM의 추론 비용을 크게 줄이며, GPU 메모리의 소모량도 줄어들게 합니다. 특히, RetrievalAttention은 8B 파라미터를 가진 LLM에서 128K 토큰을 서비스하기 위해 NVIDIA RTX4090(24GB) 하나만 필요하며, 0.188초 만에 하나의 토큰을 생성할 수 있음을 보여주었습니다.
1. 서론 (Introduction)
최근 Transformer 기반 대형 언어 모델은 긴 컨텍스트를 처리하는 데 있어서 놀라운 성능을 보여주었습니다. 예를 들어, Gemini 1.5 Pro는 최대 1천만 개의 토큰을 지원할 수 있습니다. 이는 매우 긴 컨텍스트 창을 분석하는 데 유망하지만, 창의 크기를 확장하면 주의 계산의 이차적 복잡성 때문에 추론 효율성에 문제가 생깁니다. 이 문제를 해결하기 위해, 주의의 효율성(효과성)을 높이고 KV 캐싱(키-값 캐싱) 기법을 사용하는 것이 널리 채택되었습니다. KV 캐싱은 계산 중복을 방지하기 위해 사용되지만, 긴 컨텍스트의 경우 몇 가지 주요 문제가 있습니다. 첫째, 긴 컨텍스트의 경우 상당한 GPU 메모리 요구 사항이 발생하며, LLaMA-2 7B 모델은 FP16 형식으로 작동할 때 약 500GB의 메모리가 필요합니다. 둘째, 컨텍스트 크기가 커짐에 따라 추론 지연이 크게 늘어나며, 이는 GPU 등의 장치에서 저장된 키-값 벡터에 접근하는 데 필요한 시간 때문입니다.
이 문제를 해결하기 위해, 이 논문은 주의 메커니즘에서 각 쿼리 벡터가 전체 키 벡터의 일부만 접근하도록 함으로써 효율성을 극대화하는 방법을 제안합니다. RetrievalAttention은 KV 벡터의 희소성에 기초하여 작동하며, 이를 통해 LLM의 긴 컨텍스트를 처리하는 데 필요한 GPU 메모리 소모를 크게 줄이고 효율성을 향상시킵니다.
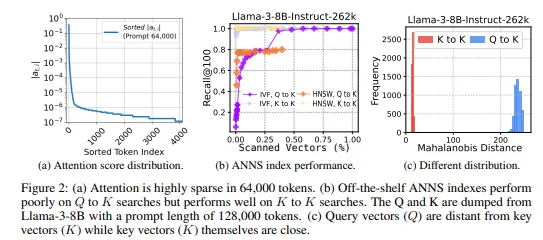
주의 계산의 효율성 향상에 대한 대부분의 연구들은 토큰을 정적으로 또는 경험적으로 식별하는데, 이는 성능 저하로 이어질 수 있는 부정확한 가정을 포함하고 있습니다. 본 연구에서는 근사 최근접 이웃 탐색(ANNS) 인덱스가 이 맥락에서 특히 효과적임을 발견했습니다. 내부 제품(innner product)을 유사성 측정으로 사용할 때, ANNS는 주의 메커니즘과 정확하게 일치하며, 로 표현됩니다. 이를 통해 가장 중요한 키 벡터를 고정밀도로 식별할 수 있으며, 기존의 정적 또는 경험적 방법보다 높은 정확도를 제공합니다.
주의 메커니즘에 ANNS를 활용하는 것은 쿼리 벡터와 키 벡터 간의 분포 불일치(out-of-distribution, OOD) 문제를 야기합니다. 대부분의 ANNS 인덱스는 쿼리와 키 벡터가 동일한 분포에서 도출된다는 가정하에 작동합니다. 그러나 주의 메커니즘에서 쿼리와 키 벡터 간의 투영 가중치가 다르기 때문에 이러한 가정은 종종 통하지 않습니다. 특히, OOD 쿼리의 경우 ANNS의 효과는 크게 감소하며, 실험적으로도 쿼리 벡터를 OOD로 유지하려면 모든 키 벡터의 30%를 스캔해야 하는 것으로 나타났습니다. 이 연구는 ANNS가 주의 계산에서 OOD 문제를 야기한다는 점을 처음으로 지적한 연구입니다.
본 연구에서는 긴 컨텍스트 LLM의 생성 가속화를 위한 RetrievalAttention 기법을 제안합니다. 이 방법은 동적 희소 주의를 활용하여 긴 컨텍스트 데이터를 효율적으로 처리할 수 있습니다. OOD 문제를 해결하기 위해, RetrievalAttention은 주의 메커니즘을 위한 벡터 인덱스를 제안하고, 유사성보다는 쿼리 간의 분포에 초점을 맞춰 가장 중요한 토큰을 식별합니다. 이 접근 방식은 전체 키 벡터의 1-3%만 탐색하여 중요한 토큰을 효과적으로 식별해, 주의 계산과 추론 결과를 개선합니다. RetrievalAttention은 GPU 메모리 소비를 줄이기 위해 정적 패턴을 따르는 KV 벡터의 일부를 GPU 메모리에 유지하면서 대부분의 KV 벡터는 CPU 메모리로 오프로드하는 방식을 사용합니다. 토큰 생성 시에는 CPU에 저장된 인덱스를 사용하여 중요한 토큰을 효율적으로 검색한 후 CPU와 GPU의 부분 결과를 병합하여 계산 효율성을 높입니다. 이 전략을 통해 RetrievalAttention은 GPU 메모리 소모를 줄이면서 주의 계산 성능을 최적화할 수 있습니다.
우리는 RetrievalAttention의 정확성과 효율성을 고성능 GPU(4090) 및 고급 GPU(A100)에서 긴 컨텍스트 LLM을 사용해 평가했습니다. 4090 GPU에서는, RetrievalAttention은 기존 KNN 방법보다 4.9배 빠른 디코딩-레이턴시 속도를 제공하면서도 유사한 정확도를 유지했습니다. 또한, RetrievalAttention은 매우 적은 GPU 메모리 자원을 소모하면서도 단일 NVIDIA RTX4090 (24GB)로 128K 토큰을 생성할 수 있는 성능을 발휘했습니다.
2. 배경 및 동기 (Background and Motivation)
2.1 LLM과 주의 메커니즘의 동작
t번째 토큰을 생성할 때, 주의 메커니즘은 쿼리 벡터 (차원이 d인)와 이전에 생성된 토큰의 키 벡터 ( ) 간의 내적(dot product)을 계산합니다. 이 결과는 )로 스케일 조정되고, 소프트맥스(Softmax) 함수를 통해 정규화되어 주의 점수 \ 가 됩니다. 이 점수는 값 벡터 )에 가중치를 부여하여 최종 출력 를 생성합니다.
LLM 추론에는 두 단계가 있습니다: 사전 채우기(pre-fill) 단계와 디코딩 단계. 사전 채우기 단계는 한 번만 발생하며, 프롬프트의 키와 값을 계산하고 복잡도 로 처리됩니다. 디코딩 단계에서는 새롭게 생성된 토큰이 쿼리가 되고, 모든 이전 키 벡터와 내적 계산을 통해 주의 점수를 계산합니다. 중복 계산을 방지하기 위한 한 가지 최적화 방법은 이전의 KV 상태를 GPU 메모리에 캐시하여 복잡도를 ( 으로 줄이는 것입니다.
2.2 긴 컨텍스트 서비스의 비용 (Expensive Long-Context Serving)
주의 계산의 이차적 시간 복잡성으로 인해, 긴 시퀀스 입력을 처리하는 데 매우 높은 비용이 듭니다. 테이블 1은 KV 캐시 없이 수행되는 추론 지연을 보여줍니다. 프롬프트 길이가 100만 토큰에 도달할 때, 매 토큰을 생성하는 데 약 1,765초가 걸리며, 이 중 96% 이상의 지연이 주의 작업에 소모됩니다. KV 캐시는 디코딩 지연을 줄일 수 있지만, 긴 컨텍스트의 경우 상당한 GPU 메모리 공간이 필요합니다. 테이블 1에 나와 있듯이, 100만 토큰의 컨텍스트 길이를 지원하려면 KV 캐시를 저장하기 위해 500GB의 메모리가 필요하며, 이는 A100 GPU(80GB)의 용량을 훨씬 초과합니다. GPU와 CPU 메모리 간 캐시를 오프로드 및 다시 로딩하는 것은 잠재적인 해결책일 수 있지만, 이는 PCIe를 통한 추가 통신 오버헤드를 발생시켜, 일반 GPU에서의 추론 성능을 저하시킬 수 있습니다.
2.3 동적 및 희소 주의 (Dynamic and Sparse Attention)
긴 컨텍스트의 큰 크기에도 불구하고, 전체 토큰 중 일부만이 주 생성 정확도에 중요한 역할을 합니다. 그림 4는 LLaMA-2 7B 모델의 쿼리 벡터에 대한 의 분포를 보여줍니다. 상위 500개의 토큰이 값의 대부분을 차지하며, 나머지 토큰들은 미미한 기여만을 합니다. 높은 선택성 지수는 특정 키 벡터가 쿼리 벡터와 강하게 상관관계가 있음을 나타냅니다. 따라서 키 벡터의 희소성은 주의 계산을 효율적으로 최적화할 수 있음을 의미합니다. 우리의 새로운 방법에서는 최상위 를 근사하여 시간 복잡도를 줄였습니다.
2.4 오프 더 셀프 벡터 검색의 문제점 (Challenges of Off-the-shelf Vector Search)
ANNS(Approximate Nearest Neighbor Search) 인덱스를 사용하여 가장 유사한 벡터를 찾는 문제는 널리 연구된 문제입니다. 이는 각 쿼리 벡터에 대해 가장 가까운 키 벡터를 찾는 주의(attention)의 목표와 일치합니다. 하지만, 오프 더 셀프 벡터 인덱스를 사용하면 쿼리 벡터와 키 벡터 간의 분포 불일치(out-of-distribution, OOD) 문제가 발생할 수 있습니다.
전통적인 벡터 검색에서는, 쿼리와 키 벡터가 동일한 분포에서 도출된다고 가정합니다. 그러나 주의 메커니즘의 벡터는 종종 서로 다른 모델 가중치에 의해 생성되므로, 이러한 가정은 해당 시스템에서 성립되지 않을 수 있습니다. 예를 들어, 쿼리 벡터가 가장 유사한 키 벡터를 찾는 데 있어, 널리 사용되는 ANNS 인덱스는 성능이 저하되며, 리콜 비율이 저하됩니다. IVFFlat(전역 탐색 기법)은 30% 이상의 벡터를 스캔해야 하며, HNSW(근접 탐색 기법)는 지역 최적화에 실패할 수 있습니다. 이러한 결과는 높은 리콜 비율을 얻기 위해서는 많은 벡터를 스캔해야 하며, 효율적인 주의 계산을 수행하는 데 어려움을 초래할 수 있음을 보여줍니다.
특히, 쿼리 벡터와 키 벡터 간의 OOD 문제는 마하라노비스 거리(Mahalanobis distance)를 사용해 계량할 수 있습니다. 실험 결과, 쿼리 벡터와 키 벡터 간의 분포 차이가 클수록, ANNS 인덱스의 성능이 크게 저하되는 것을 확인했습니다. 이는 효율적인 검색에서 쿼리와 키가 같은 분포에서 나오는 것이 중요함을 시사합니다.
3. RetrievalAttention 설계 (RetrievalAttention Design)
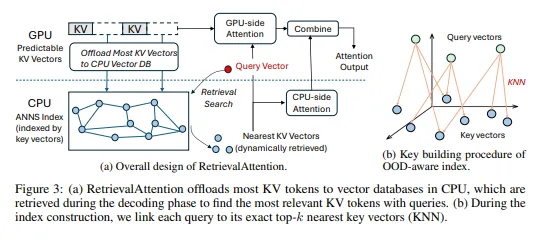
이 섹션에서는 토큰 생성을 가속화하고, 긴 컨텍스트 프롬프트의 사전 채우기(pre-fill) 단계를 다룹니다. RetrievalAttention은 쿼리와 키 벡터의 벡터 검색을 활용하여 CPU-GPU 간의 상호작용을 최적화하는 데 중점을 둡니다. 그림 3a는 이 벡터 검색을 통한 주의 계산을 CPU와 GPU 간에 어떻게 분산시키는지 보여줍니다. RetrievalAttention은 드문 벡터만을 남기고 나머지는 제거하여 효율성을 극대화합니다. 이 기법을 통해 CPU에 저장된 벡터는 최소화되고, 주요 주의 벡터는 GPU에 캐시되며, 이를 병합하여 전체 주의 결과를 도출합니다.
결과적으로, RetrievalAttention은 GPU 메모리를 절약하고, 동적으로 갱신된 키-값 벡터를 유지함으로써 긴 컨텍스트에 대한 효율적인 계산을 가능하게 합니다.
3.1 근사화된 주의 (Approximated Attention)
식 1을 기반으로, RetrievalAttention은 높은 주의 점수(즉,( )와 관련된 KV 벡터만을 선택적으로 사용하여 전체 주의 출력 를 근사화합니다. 구체적으로, 우리는 주의 점수가 특정 임계값을 초과하는 토큰들의 목록을 정의하며, 이를 라고 명명합니다. 그 결과, 드문 벡터만 고려하는 희소 주의 메커니즘은 다음과 같이 정의됩니다.
위 근사를 기반으로, RetrievalAttention은 벡터 인덱스에 의해 검색된 중요한 키-값 벡터만을 고려하도록 설계됩니다.
3.2 주의 인식 벡터 검색 (Attention-aware Vector Search)
각 키 및 값 벡터 쌍에 대해, 우리는 해당 벡터를 CPU 또는 GPU 메모리에 저장할지 먼저 결정합니다(이 결정 방법은 3.3절에서 설명됩니다). CPU 메모리로 오프로드된 KV 벡터는 로 인덱싱되어 가장 관련성 있는 벡터를 찾기 위해 탐색됩니다.
토큰 생성 중 벡터 검색을 가속화하기 위해, RetrievalAttention은 기존 쿼리 벡터를 사용하여 키 벡터에 대한 인덱스를 미리 생성하고, 주의 계산 동안 벡터 검색을 가속화합니다. RetrievalAttention은 쿼리 벡터와 키 벡터 간의 분포 차이를 완화하는 명시적인 연결을 구축합니다. 그림 3b에서 설명하듯이, RetrievalAttention은 기존의 KNN(K-Nearest Neighbors) 접근법을 활용하여, 벡터 분포의 불일치를 해결하는 구조를 사용합니다. 이 구조를 통해 디코딩 과정에서 KNN을 사용해, 쿼리 벡터와 가장 가까운 키 벡터를 효율적으로 검색합니다.
KNN 연결은 쿼리 벡터와 키 벡터 간의 거리를 다리처럼 연결하지만, 이 방법만으로는 문제를 완전히 해결할 수 없습니다. 여기에는 여전히 메모리 오버헤드와 높은 계산 비용이 따르기 때문입니다. 오프 더 셀프 ANNS(Approximate Nearest Neighbor Search) 인덱스는 이러한 문제를 해결하지 못합니다. RetrievalAttention은 이러한 문제를 해결하기 위해 검색 중 쿼리와 키 간의 물리적 관계를 정확하게 모델링하고, 관련 있는 키 벡터만 검색하여 필요한 키 벡터 수를 1-3%로 줄임으로써 기존 방법보다 74% 향상된 속도를 보여줍니다.
3.3 CPU-GPU 공동 실행 (CPU-GPU Co-Execution)
GPU 병렬 처리를 활용하고 주의 계산을 가속화하기 위해, RetrievalAttention은 주의 계산을 두 가지 주요 집합으로 분할합니다: GPU에서 처리 가능한 예측 가능한 KV 벡터와 CPU에서 처리되는 동적 KV 벡터입니다. 이 두 결과를 결합하여 최종 출력을 만듭니다.
프리필(pre-fill) 단계에서 관찰된 패턴을 사용하여, 우리가 현재 진행 중인 토큰 생성 중에 일관되게 필요한 KV 벡터를 예측합니다. 이는 StreamingLLM과 유사하게, 초기 토큰을 고정된 패턴으로 처리하고 나머지 토큰들은 동적으로 처리하는 방식입니다. RetrievalAttention은 낮은 지연 속도와 높은 정확도를 유지하면서, 새롭게 생성된 KV 벡터를 동적으로 적응시켜 처리할 수 있습니다. 이를 통해 PCIe 전송 시간을 단축시키고, CPU와 GPU 모두에서 동시에 처리됩니다. 이 최적화는 FastAttention을 기반으로 하며, RetrievalAttention의 전반적인 작업 흐름을 도식화한 그림이 B 섹션에 설명되어 있습니다.
4. 평가 (Evaluation)
이 섹션에서는, RetrievalAttention이 긴 컨텍스트 LLM 추론 성능에 미치는 영향을 평가합니다. 우리는 다음과 같은 두 가지 주요 질문을 탐구합니다:
- RetrievalAttention이 모델의 정확도에 어떤 영향을 미치는가?
- 다양한 다운스트림 태스크에서 RetrievalAttention과 다른 방법들의 생성 정확도를 평가합니다.
- RetrievalAttention이 긴 컨텍스트 LLM 추론의 토큰 생성 지연을 효과적으로 줄일 수 있는가?
- RetrievalAttention과 다른 기법들의 종단간 디코딩 지연 시간을 비교합니다.
4.1 실험 설정 (Experimental Setup)
테스트 환경, 모델 및 구성:
우리는 NVIDIA RTX 4090 GPU(24GB 메모리)와 Intel i9-10900X CPU(20코어 및 128GB RAM)로 구성된 서버에서 실험을 수행했습니다. NVIDIA A100 GPU도 실험에 사용되었습니다. 실험에서는 Llama-3B-Instruct-26k, LLaMA-7B, 및 다른 최신 LLM을 포함하여 RetrievalAttention을 적용했습니다. CPU 메모리 소비가 DRAM의 용량을 넘지 않도록 하기 위해, 이전 연구들을 참고하여 실제 환경에서 싱글 배치 시나리오로 벤치마크를 실행했습니다.
기준선: 우리는 RetrievalAttention을 다음의 학습 기준선과 비교했습니다:
- KV 캐시가 없는 전체 주의 모델 및 LLM에서 캐시를 사용하는 버전.
- StreamingLLM: GPU 메모리에서 긴 컨텍스트 토큰을 유지하면서 매번 블록 단위로 처리.
- SnapKV: 디코딩 중 긴 창의 키-값 벡터를 CPU에 캐싱.
- InLLM: 키-값 벡터를 연속적인 토큰 시퀀스로 분리.
이 외에도, 우리는 전통적인 벡터 검색 방법(Faiss)을 포함한 여러 벡터 검색 방법을 도입하여 비교했습니다.
벤치마크:
- BeIR 벤치마크: 18개의 다양한 검색 태스크로 구성된 벤치마크.
- RULER: QA 및 요약 태스크에서 성능을 평가하기 위한 벤치마크.
- NeRd: 작은 데이터 내 "바늘 찾기" 문제를 정확하게 해결하는 테스트.
Table 2: 다양한 방법과 모델이 oc-Bench에서 보인 성능(%)을 나타냅니다. 정적 패턴의 크기는 항상 640(초기 128개의 토큰 + 로컬 윈도우에 있는 512개의 토큰)입니다. Flat, IVF 및 RetrievalAttention은 기본적으로 상위 100개의 키 벡터를 검색하며, KV Retrieval 작업에서는 상위 2000개의 키 벡터를 검색한 결과도 포함됩니다.
| Methods | Tokens | Retr-KV | RetR-KV | Cod-D | Mahfl-P | Fm-QA | Em-MC | Avg. |
|---|---|---|---|---|---|---|---|---|
| FullAttention | 128k | 100.0 | 100.0 | 100.0 | 100.0 | 98.7 | 100.0 | 99.8 |
| StreamingLLM | 128k | 50.0 | 40.3 | 85.0 | 50.0 | 45.0 | 48.3 | 53.9 |
| InLLM | 128k | 80.0 | 60.0 | 95.0 | 90.0 | 85.0 | 90.0 | 83.6 |
| SnapKV | 128k | 70.0 | 50.0 | 90.0 | 70.0 | 65.0 | 67.3 | 70.3 |
| IVF | 640+100*2K | 95.0 | 80.0 | 99.0 | 98.5 | 95.0 | 98.2 | 94.2 |
| RetrievalAttention | 640+100*2K | 99.0 | 90.0 | 99.5 | 99.0 | 97.5 | 98.9 | 97.3 |
4.2 긴 컨텍스트 작업에서의 정확도 (Accuracy on Long Context Tasks)
oc-Bench에서 Table 2에 나타난 것처럼, RetrievalAttention은 중요한 토큰의 동적 검색을 통해 Full Attention과 유사한 성능을 보였습니다. StreamingLLM과 SnapKV와 같은 정적 방법들은 이러한 기능이 부족하여 정확도가 떨어졌습니다. InLLM은 거의 0%에 가까운 성능을 보였습니다. 하지만 RetrievalAttention은 전체 키 벡터의 1-3%만 검색하면서도 거의 동일한 정확도를 유지하였으며, 이는 복잡한 동적 작업에서 성능을 입증한 것입니다.
RULER 벤치마크(Table 3)는 다양한 컨텍스트 길이에 걸쳐 RetrievalAttention이 안정적인 성능을 보였음을 보여줍니다. 특히 128K 이상의 긴 컨텍스트에서 모델은 높은 정확도를 유지했습니다.
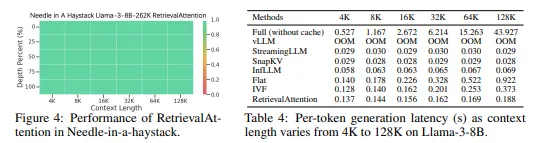
Needle-in-a-Haystack 벤치마크에서는, RetrievalAttention이 다양한 상황에서 효과적으로 정보를 검색한 반면, StreamingLLM은 특정 임계 토큰 길이에서 성능이 크게 저하되었습니다.
4.3 지연 시간 평가 (Latency Evaluation)
긴 컨텍스트에서의 지연 시간은 주의 계산의 이차적 복잡성으로 인해 크게 증가합니다. KV 캐시가 없는 경우, StreamingLLM, SnapKV, InLLM은 높은 메모리 오버헤드를 겪고 있으며, RetrievalAttention은 더 적은 키 벡터로도 이러한 문제를 해결할 수 있었습니다.
Table 3: RULER 벤치마크에서 다양한 방법 및 모델의 성능(%)을 나타냅니다.
| Methods | Act. Tokens | Claimed | Effective | 4K | 8K | 16K | 32K | 64K | 128K | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|
| FullAttention | 128K | 262K | 262K | 95.6 | 90.8 | 88.6 | 86.4 | 84.9 | 83.4 | 88.3 |
| StreamingLLM | 640 | 128K | 128K | 81.9 | 75.6 | 69.8 | 66.1 | 64.7 | 62.5 | 70.1 |
| SnapKV | 640 | 128K | 128K | 85.1 | 82.4 | 78.3 | 73.5 | 68.6 | 63.5 | 75.2 |
| InLLM | 128K | 128K | 128K | 92.4 | 88.6 | 85.3 | 80.1 | 76.5 | 74.9 | 82.9 |
| IVF | 640+100 | 262K | 128K | 90.7 | 85.9 | 82.4 | 79.2 | 74.6 | 70.1 | 80.5 |
| RetrievalAttention | 640+100 | 262K | 128K | 93.0 | 87.5 | 86.0 | 82.9 | 80.1 | 77.9 | 84.6 |
5. 관련 연구 (Related Works)
긴 컨텍스트 LLM 추론을 가속화하기 위해, 몇몇 연구들은 주의 희소성을 활용하여 KV 캐시의 크기를 줄이려 시도했습니다. 하지만 이러한 방법들은 주의 희소성의 동적 특성 때문에 상당한 성능 저하를 겪습니다. FlexGen과 Lamina는 KV 캐시를 CPU 메모리로 오프로드하지만, 이는 느리고 비용이 많이 드는 전체 주의 계산을 동반합니다.
최근 연구들은 중요한 KV 벡터를 식별하여 필요한 경우만 검색함으로써 성능을 개선하려 했습니다. Quest는 쿼리 벡터에 따라 다른 부분의 KV 벡터를 캐싱하여 모델 속도를 개선했으며, IVF는 재사용 가능한 검색 시스템을 도입했습니다. RetrievalAttention은 이러한 연구들을 기반으로 하여, 중요한 토큰만을 효율적으로 검색함으로써 LLM 추론을 가속화하는 접근 방식을 제안합니다.
6. 결론 (Conclusion)
우리는 대부분의 KV 벡터를 CPU 메모리로 오프로드하고, 동적 희소 주의를 활용하여 추론 비용을 최소화하는 RetrievalAttention을 제안합니다. RetrievalAttention은 쿼리와 키 벡터 간의 분포 차이를 식별하고, 주의-인식 벡터 검색 방식을 사용하여 중요한 토큰을 효율적으로 찾아냅니다. 실험 결과, RetrievalAttention은 128K 토큰의 컨텍스트에서 기존 KNN 및 ANNS 방법보다 4.9배 및 1.98배 빠른 디코딩 속도를 달성했습니다. 또한, 이 시스템은 24GB의 RTX4090 GPU에서 8B 레벨 LLM을 128K 토큰으로 실행하는 첫 번째 시스템입니다.
