https://arxiv.org/pdf/2406.10774
Abstract
긴 문맥을 처리할 수 있는 대형 언어 모델(LLMs)에 대한 수요가 증가함에 따라 최대 128K 또는 1M 토큰을 처리할 수 있는 모델들이 점점 더 많이 등장하고 있습니다. 하지만 긴 문맥 LLM 추론은 시퀀스의 길이가 증가함에 따라 추론 속도가 크게 감소하기 때문에 도전적인 과제입니다. 이러한 속도 저하의 주된 원인은 자가-어텐션 단계에서 큰 KV 캐시(Key-Value Cache)를 불러오는 것 때문입니다. 이전 연구에서는 전체 토큰 중 소수의 중요한 토큰이 어텐션 결과를 지배한다는 것이 밝혀졌지만, 우리는 토큰의 중요성이 쿼리에 크게 의존한다는 것을 관찰했습니다.
이를 해결하기 위해 우리는 쿼리 인식형 KV 캐시 선택 알고리즘인 Quest를 제안합니다. Quest는 KV 캐시 페이지에서 최소 및 최대 Key 값을 추적하고, Query 벡터를 사용하여 주어진 페이지의 중요도를 추정합니다. Quest는 어텐션 단계에서 상위 K개의 중요한 KV 캐시 페이지만 로드하여 효율적으로 성능을 높이면서도 정확성을 유지합니다. 우리는 Quest가 최대 7.03배의 자가-어텐션 속도 향상을 달성할 수 있으며, 이는 추론 지연 시간을 2.23배까지 줄이면서도 긴 의존성을 가진 작업에서도 정확도 손실이 거의 없음을 보여줍니다. 코드는 다음 링크에서 확인할 수 있습니다: https://github.com/mit-han-lab/Quest.
1. Introduction
대형 언어 모델(LLMs)의 빠른 발전은 우리의 일상에 큰 영향을 미치고 있습니다. 여러 차례에 걸친 대화나 긴 문서 쿼리에 대한 수요가 증가함에 따라 LLM의 최대 문맥 길이는 2K에서 1M까지 크게 늘어났습니다(Liu et al., 2024a; Peng et al., 2023; Tworkowski et al., 2023). 128K 문맥 길이의 GPT-4 모델은 이미 대규모 서비스에 도입되었으며 이는 300페이지에 해당하는 텍스트 분량입니다(OpenAI, 2023).
하지만 긴 문맥 요청을 처리하는 것은 매우 어려운 일입니다. LLM의 자동 회귀 특성으로 인해 하나의 토큰을 생성하려면 전체 KV 캐시를 읽어야 합니다. 예를 들어 Llama 7B 모델(Touvron et al., 2023)이 32K 문맥 길이를 처리할 때, KV 캐시는 16GB의 공간을 차지하며 이를 읽는 데 최소 11ms가 소요됩니다. 이는 추론 지연 시간의 50% 이상을 차지하여 전체 처리량에 큰 제한을 가합니다.
이러한 커다란 KV 캐시의 크기에도 불구하고 이전 연구들은 전체 토큰 중 일부만이 토큰 생성 정확도에 중요한 영향을 미친다는 것을 보여주었습니다(Zhang et al., 2023b; Ge et al., 2024). 따라서 우리는 중요한 토큰만 로드함으로써 추론 지연 시간을 크게 줄일 수 있습니다. 중요한 KV 캐시 부분을 식별하는 것이 중요합니다.
Quest 제안
본 연구에서 우리는 토큰의 중요도가 쿼리 토큰에 따라 변할 수 있음을 추가적으로 관찰했습니다. 그림 2에 나와 있듯이, 중요한 토큰은 쿼리에 따라 크게 달라집니다. 따라서 우리는 KV 캐시의 어느 부분을 어텐션에 포함시켜야 할지를 동적으로 결정할 수 있는 효율적인 접근법이 필요합니다. 이를 위해 우리는 Quest라는 쿼리 인식형 중요도 추정 알고리즘을 제안합니다. 이는 긴 문맥 LLM 추론을 위해 효율적이고 효과적으로 중요한 KV 캐시 토큰을 식별하고, 선택된 토큰에 대해 자가-어텐션을 수행합니다(그림 1 참조).
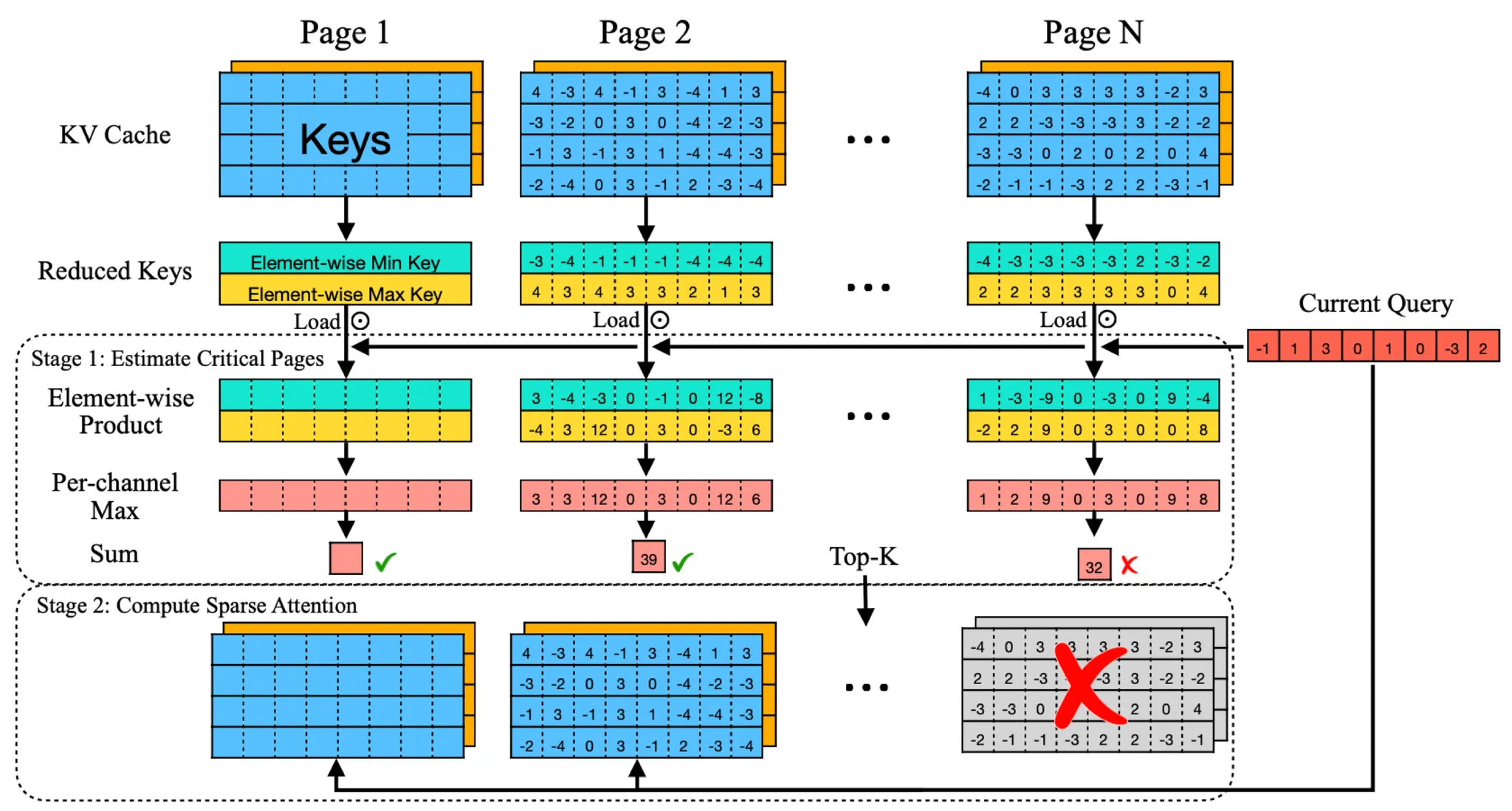
KV 캐시의 중요도 추정에 대한 오버헤드를 줄이기 위해, Quest는 KV 캐시를 페이지 단위로 관리합니다(Kwon et al., 2023). 각 페이지에 대해 Quest는 Key 벡터의 각 차원의 최대값과 최소값을 메타데이터로 사용하여 토큰 정보를 나타냅니다. 추론 중에 Quest는 쿼리 벡터와 메타데이터를 모두 고려하여 각 페이지의 중요도를 추정합니다. 모든 페이지의 중요도 점수를 기반으로 Quest는 상위 K개의 페이지를 선택하여 근사적 자가-어텐션을 수행합니다. 이렇게 함으로써 전체 KV 캐시를 로드하는 대신 메타데이터와 상수 K 페이지만 로드하여 추론 속도를 크게 향상시킵니다.
평가 결과
우리는 Quest의 정확성과 효율성을 평가했습니다. Quest는 토큰의 중요도를 동적으로 결정하기 때문에 PG19 데이터셋(Rae et al., 2019), passkey retrieval task(Peng et al., 2023), LongBench(Bai et al., 2023)에서 256에서 4K 토큰 범위로 다른 방법보다 더 나은 정확도를 달성했습니다. 32K 문맥 길이에서 Quest는 FlashInfer(Ye et al., 2024) 대비 7.03배의 자가-어텐션 지연 시간 감소를 달성했습니다. 우리의 종단 간 프레임워크는 4비트 가중치 양자화를 통해 FlashInfer(Ye et al., 2024) 대비 2.23배의 추론 속도 향상을 보여줬습니다.
주요 기여:
- 쿼리 인식형 희소성의 중요성을 파악한 자가-어텐션 메커니즘 분석
- 쿼리 인식형 희소성을 활용하여 효율적이고 정확한 KV 캐시 가속 알고리즘 Quest 개발
- 종합적인 Quest 평가를 통해 최대 7.03배의 자가-어텐션 지연 시간 감소 및 2.23배의 종단 간 지연 시간 향상 달성
2장: 관련 연구
2.1 Long-context 모델
긴 문맥을 처리해야 하는 수요가 늘어나면서, 많은 연구가 LLMs의 문맥 창을 확장하는 데 초점을 맞추고 있습니다. 현재 많은 모델들이 RoPE (Rotary Position Embeddings, 회전 위치 임베딩) (Su et al., 2023)을 활용하고 있으며, RoPE의 다양한 스케일링 방법과 미세 조정을 통해 원래 4k 문맥 창을 가지고 있던 Llama-2 모델의 창 크기를 32k로 늘린 LongChat (Li et al., 2023)과 128k로 확장한 Yarn-Llama-2 (Peng et al., 2023) 등의 모델이 등장했습니다. 길이 외삽을 통해 모델의 문맥 창 크기는 1M을 넘어섰습니다 (Liu et al., 2024b). 오픈소스 모델을 넘어, GPT-4 Turbo는 최대 128k, Claude-2는 최대 200k까지 지원합니다 (OpenAI, 2024; Anthropic, 2024). 모델이 점점 긴 입력을 처리할 수 있게 되면서 추론 효율성에 대한 도전이 대두되고 있습니다. Quest는 이러한 긴 문맥 추론을 개선하기 위해 쿼리 인식적 KV 캐시 희소성을 활용하는 방법을 제안합니다.
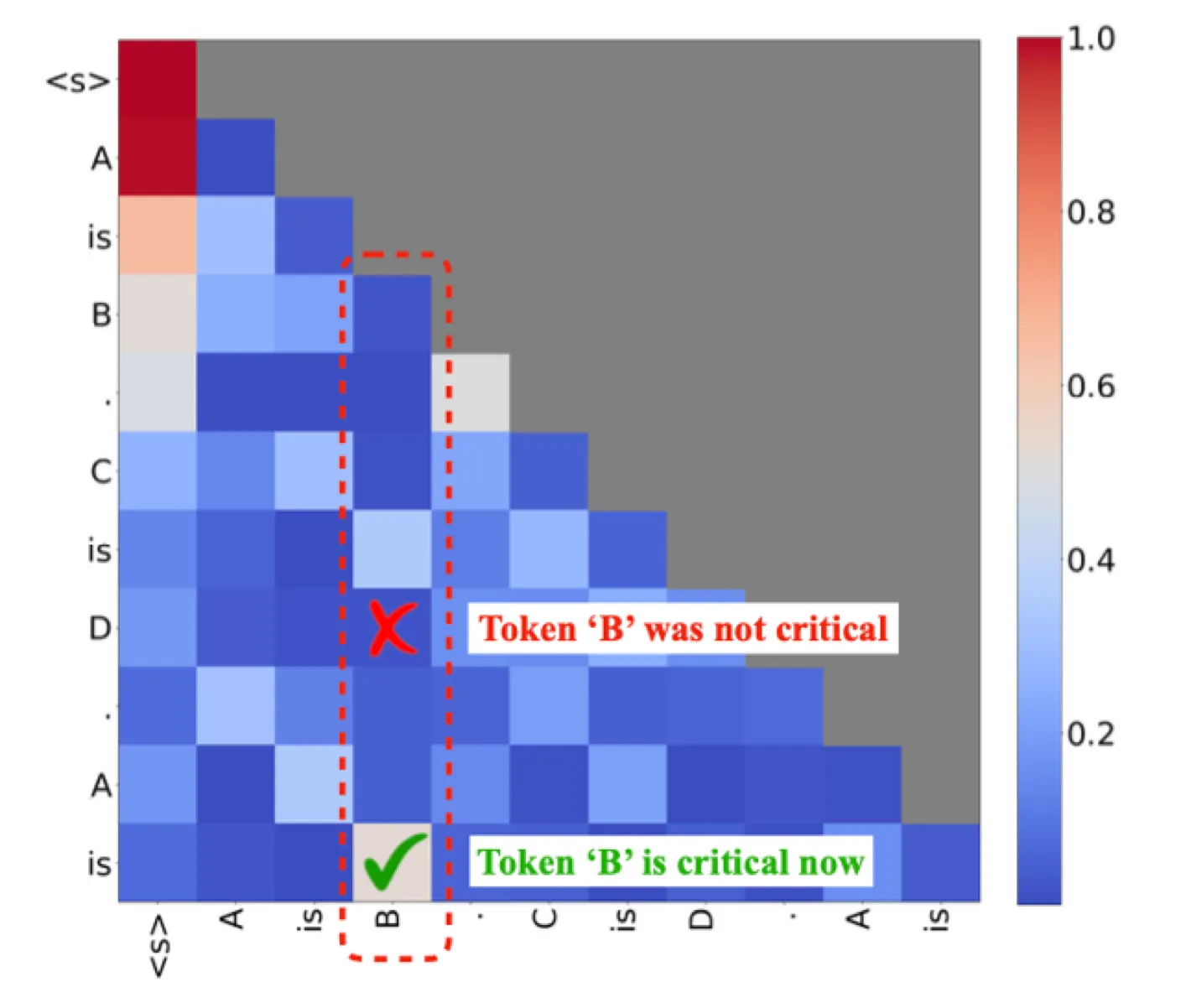
그림 2는 "A is B. C is D. A is"라는 프롬프트의 주의(attention) 맵을 보여줍니다. 각 행은 왼쪽에 있는 토큰에 의해 쿼리된 이전 토큰들의 주의(attention) 점수를 나타냅니다. "D"로 쿼리할 때 토큰 "B"는 낮은 주의 점수를 보이며, 이는 "B"가 생성에 중요하지 않음을 나타냅니다. 그러나 "is"는 "B"에 강하게 주의를 기울입니다. 따라서 토큰의 중요성은 현재의 쿼리 토큰과 밀접한 상관관계가 있습니다.
2.2 KV 캐시 제거 알고리즘
긴 문맥의 LLM 추론 및 서비스 시나리오에서, 거대한 크기의 KV 캐시는 상당한 시간과 공간 오버헤드를 초래합니다. 이전에 많은 노력이 KV 캐시의 크기를 압축하고 주의(attention) 속도를 높이며 메모리 사용을 줄이기 위해 이뤄졌습니다. H2O (Zhang et al., 2023b)는 과거의 주의(attention) 점수의 합계에 기반하여 중요한 KV 캐시의 일부를 제한된 예산 내에서 유지합니다. FastGen (Ge et al., 2024)은 토큰의 유형을 더욱 세분화하고, KV 캐시를 선택하는 더 정교한 전략을 적용합니다. TOVA (Oren et al., 2024)는 현재 쿼리에 기반하여 어떤 토큰을 영구적으로 버릴지 결정하는 간소화된 정책을 제공합니다. StreamingLLM (Xiao et al., 2023)은 주의 sinks와 유한한 KV 캐시를 사용하여 무한히 긴 텍스트를 처리합니다. 이러한 방법들은 과거 정보나 현재 상태에 기반하여 KV 캐시의 어느 부분을 버릴지 결정하지만, 버려진 토큰이 이후 토큰에 대해 중요할 수 있어서 중요한 정보의 손실을 초래할 수 있습니다. 이를 완화하기 위해 SparQ (Ribar et al., 2023)는 채널 가지치기를 통해 근사적인 주의 점수를 계산하고 이를 통해 중요한 토큰을 선택합니다. 그러나 이 접근 방식은 긴 종속성이 있는 작업에 대해 널리 검증되지 않았으며, 채널 수준의 희소성은 실제 가속화에 도전 과제가 될 수 있습니다. 따라서 우리는 정확도 저하 없이 긴 문맥의 자기 주의를 가속화하기 위해 현재 쿼리에 기반하여 KV 캐시의 일부를 선택하는 Quest를 제안합니다.
이전 방법의 한계
- 이전에는 주의력을 가속화하고 메모리 사용량을 줄이기 위해 KV 캐시의 크기를 압축하는 데 많은 노력이 기울여졌습니다.
- 이러한 방법은 과거 정보나 현재 상태를 기반으로 KV 캐시의 어떤 부분을 삭제할지 결정하지만, 삭제된 토큰은 미래의 토큰에 중요할 수 있으며 , 이로 인해 중요한 정보가 손실될 수 있습니다.
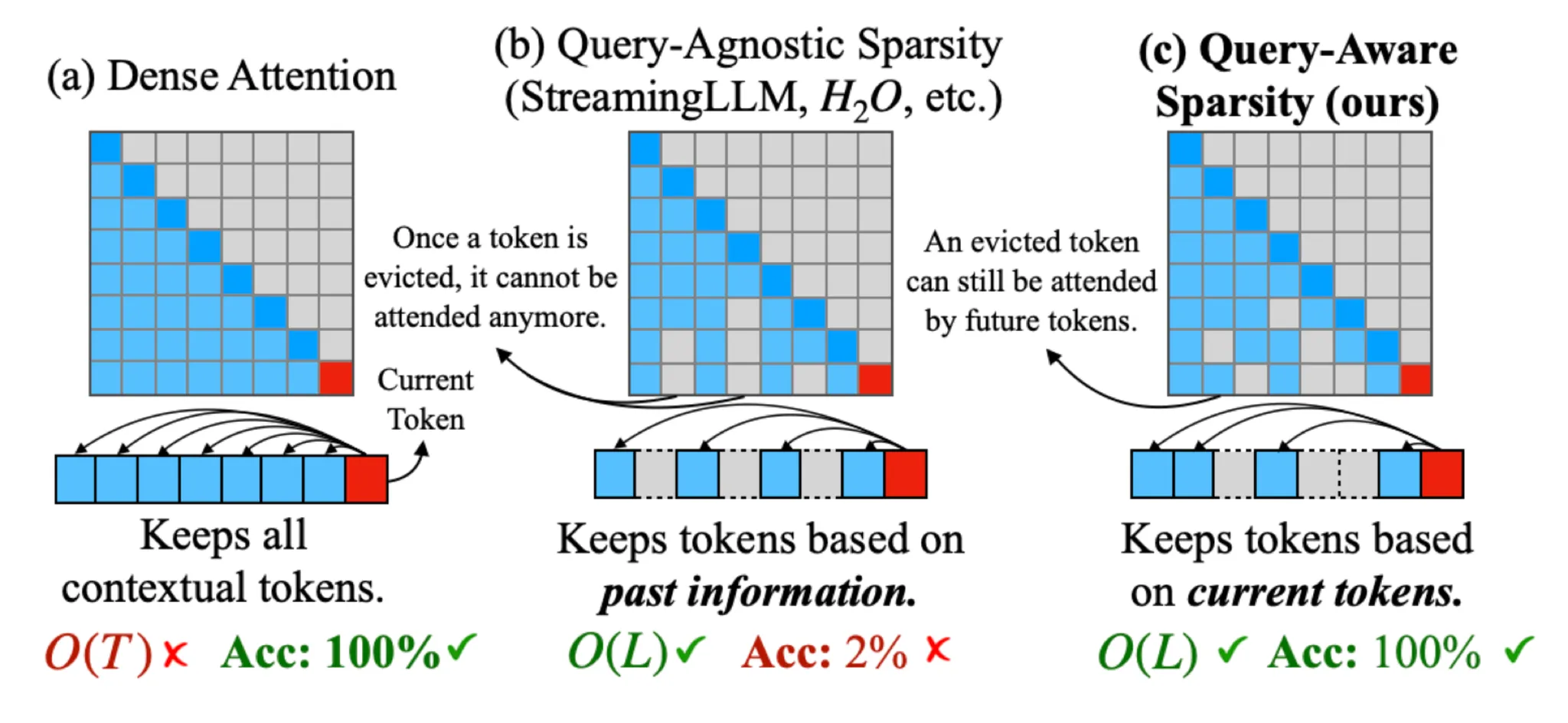
- 토큰의 중요성은 동적벡터 Q에 따라 크게 달라집니다
- 예: 토큰 'B'는 현재 쿼리 'is'에 중요합니다. 따라서 주의 점수가 높습니다. 그러나 최종 토큰 'is' 이전에 'B'는 이전 쿼리에 중요하지 않으며 주의 점수가 매우 낮습니다.
주의에서 쿼리 인식 희소성 사용
핵심 아이디어: 모든 KV 캐시를 보존하고 , 전체 KV 캐시에서 선택된 상수 K 페이지로의 메모리 이동을 줄임으로써 추론을 크게 가속화합니다.
- 우리의 통찰력은 중요한 토큰을 놓치지 않기 위해서는 가장 높은 주의 가중치를 가진 토큰이 포함된 페이지를 선택 해야 한다는 것입니다 .
- 그러나 효율적인 페이지 선택을 위해서는 이러한 통찰력에 따라 대략적인 주의 점수를 계산 해야 합니다 .
- 우리는 페이지 내의 상위 주의 가중치가 해당 페이지에서 가장 높은 주의에 근접하는 데 사용될 수 있다는 것을 발견했습니다 .
3. 방법론 (Methodology)
이 섹션에서는 먼저 Quest의 필요성을 보여주기 위해 추론 비용 분해 및 자기-어텐션 특성을 분석합니다. 이후 Quest의 설계에 대해 설명하고 그 이점을 논의합니다.
3.1 긴 문맥 추론의 비용이 많이 든다
LLM 추론은 두 가지 단계로 이루어져 있습니다. 즉, Prefill 단계와 Decode 단계입니다.
- Prefill 단계에서는 모든 입력 토큰이 임베딩으로 변환되고, Key (K), Query (Q), 그리고 Value (V) 벡터를 생성합니다. 이때 K와 V 벡터는 추후 사용을 위해 KV 캐시에 저장됩니다. Prefill 단계의 나머지 부분에서는 자기-어텐션과 피드포워드 네트워크(FFN) 레이어를 거쳐 첫 번째 응답 토큰을 생성합니다.
- Decode 단계에서는 이전에 생성된 마지막 토큰을 사용하여 해당 토큰의 K, Q, V를 계산합니다. 그리고 Q 벡터는 이전 모든 토큰의 K와 곱해져 어텐션 가중치를 생성합니다. 이 가중치들은 softmax를 통해 정규화되며, 각 값 는 현재 토큰과 이전 i번째 토큰 간의 어텐션 점수를 나타냅니다. 자기-어텐션 레이어는 를 계산하여 FFN으로 전달합니다.
한 요청에 대해 Prefill 단계는 단 한 번만 수행되지만, Decode 단계는 응답의 각 토큰마다 반복적으로 수행됩니다. 따라서 Decode 단계는 전체 추론 시간에 큰 영향을 미치게 됩니다. 예를 들어, 16k 토큰 프롬프트와 512 토큰의 응답을 사용하는 경우, 전체 시간의 86% 이상이 Decode 단계에 소비됩니다. 그렇기 때문에 Decode 단계의 성능이 전체 추론 지연 시간에 매우 중요합니다.
또한 긴 문맥을 다루는 경우 Decode 단계의 속도는 크게 느려집니다. 각 Decode 단계마다 기존 토큰들의 K와 V 벡터를 모두 로드해야 하는데, 이는 Llama-7b 모델의 32k 컨텍스트에서는 16GB의 메모리를 차지할 수 있습니다. 이 메모리 로드 작업은 Decode 단계의 53%에 해당하는 시간을 차지할 수 있습니다. 따라서 자기-어텐션 최적화는 긴 문맥 추론을 효율적으로 수행하는 데 필수적입니다.
3.2 자기-어텐션 작업에서의 높은 희소성
다행히도 기존 연구(Zhang et al., 2023b; Ge et al., 2024)는 자기-어텐션에서 본질적인 희소성이 존재한다는 것을 밝혔습니다. 자기-어텐션의 희소성은 KV 캐시에 있는 일부 토큰들, 즉 "중요 토큰"만이 중요한 토큰 간의 관계를 포착하기 위해 높은 어텐션 점수를 차지한다는 것을 의미합니다.
예를 들어, 그림 3을 보면 첫 두 레이어를 제외하면, 대부분의 경우 10% 미만의 토큰만으로도 거의 동일한 정확도를 유지할 수 있습니다. 이는 나머지 토큰에 대한 어텐션이 불필요하다는 것을 보여줍니다. 따라서 토큰의 중요도를 추정할 수 있다면, 중요한 KV 캐시 토큰에 대해서만 어텐션을 계산함으로써 메모리 이동을 줄여 효율성을 크게 높일 수 있습니다.
3.3 토큰의 중요도는 Query에 따라 달라진다
그러나 토큰의 중요도는 동적이며 Query 벡터 ( Q )에 크게 의존합니다. 예를 들어, 프롬프트가 "A is B. C is D. A is"일 때, 그림 2에서 Llama-2-7b 모델의 16번째 레이어의 특정 헤드에 대한 어텐션 맵을 보면, 현재 쿼리 "is"에 대한 답이 "B"이므로, 토큰 "B"가 매우 중요해집니다. 그러나 그 이전의 쿼리에서는 "B"가 중요한 토큰이 아니었습니다. 이처럼 토큰의 중요성은 쿼리 토큰에 밀접하게 관련되어 있습니다.
이 효과를 정량화하기 위해, 우리는 텍스트 생성 중 상위 10개의 어텐션 점수를 가진 토큰의 평균 recall rate를 측정했습니다. 원래의 어텐션은 100%의 recall rate를 유지할 수 있지만, 이전 정보 기반으로 토큰을 제거하는 KV 캐시 제거 알고리즘인 H2O(Zhang et al., 2023b)는 이전에 중요한 토큰을 제거하기 때문에 낮은 recall rate를 보여줍니다. 그림 4에 따르면, Quest는 현재 쿼리 기반으로 토큰의 중요성을 추정하기 때문에 거의 완벽한 recall rate를 유지합니다. 이로 인해 토큰의 중요성을 미리 결정하는 것은 어려우며, 이는 쿼리 기반 희소성에 대한 동기부여가 됩니다.
3.4 동적으로 토큰 중요도 추정하기
토큰의 중요도를 효율적이고 정확하게 추정하기 위해 Quest라는 알고리즘을 제안합니다. Quest는 쿼리 기반의 문맥 희소성을 활용하여 현재 쿼리에 대해 가장 잠재적으로 중요한 KV 캐시 페이지를 대략적으로 선택합니다. 그림 5는 Quest의 워크플로를 보여줍니다.
Quest는 오버헤드를 관리하기 위해 PageAttention(Kwon et al., 2023)을 채택하고, 페이지 단위로 KV 캐시 페이지를 선택합니다.
중요도 추정 방법:
- Quest는 어텐션 가중치의 근사 계산을 통해 페이지의 중요도를 추정합니다. 여기서 핵심은 페이지 내의 가장 높은 어텐션 가중치를 갖는 토큰을 포함하는 페이지를 선택하는 것입니다.
- 페이지 내의 Key 벡터의 채널별 최소값 와 최대값 를 사용하여 어텐션 가중치의 상한값을 계산합니다.
- Quest는 이 상한값을 사용해 토큰이 존재하는 페이지의 중요도를 추정하고, 상위 K개의 페이지를 중요한 페이지로 선택합니다.
알고리즘 1에서는 실제로 Quest가 어떻게 작동하는지 보여줍니다.
Quest는 이러한 추정을 바탕으로 실제 자기-어텐션을 수행할 때 선택된 페이지에서만 연산을 수행하여 메모리 이동을 크게 줄입니다. 이는 페이지의 토큰 수를 "토큰 예산(Token Budget)"으로 정의합니다.
그림 3에 따르면 첫 두 레이어에서 희소성이 낮기 때문에, 정확도를 유지하기 위해 Quest 및 모든 베이스라인은 첫 두 레이어 이후에만 적용됩니다.
3.5 Quest는 자기-어텐션의 메모리 이동을 줄인다
Quest는 쿼리 기반 희소성을 활용하여 전체 KV 캐시를 로드하지 않고 일부 데이터만 로드합니다. 예를 들어, 각 K 또는 V 벡터가 M 바이트이고 KV 캐시가 L 토큰을 포함하며 각 페이지에 S개의 KV 쌍이 있다면:
- Quest는 각 페이지의 최대 및 최소 벡터를 로드하는 데 바이트를 사용합니다.
- Quest는 상위 K개의 페이지에서만 정상적인 자기-어텐션을 수행하기 때문에 추가적으로 ( 2M \times K \times S ) 바이트를 로드합니다.
- 전체 KV 캐시의 크기가 바이트임을 고려할 때, Quest는 전체 KV 캐시의 만 로드합니다.
예를 들어, 16개의 KV 쌍을 포함하는 페이지 크기, 64K 컨텍스트 길이, 상위 4K 페이지를 선택하는 경우 Quest는 메모리 로드를 8배 줄일 수 있습니다. 이러한 메모리 로드 감소는 모든 모델에 적용 가능하며 기존의 양자화 메커니즘(Zhao et al., 2024)과도 호환됩니다.
실험
4.1 설정
우리는 Quest를 언어 모델링 데이터셋 PG19 (Rae et al., 2019), 패스키 검색 작업 (Peng et al., 2023), 그리고 LongBench (Bai et al., 2023)의 여섯 개의 데이터셋에서 평가합니다: NarrativeQA (Kociský et al., 2018), HotpotQA (Yang et al., 2018), Qasper (Dasigi et al., 2021), TriviaQA (Joshi et al., 2017), GovReport (Huang et al., 2021), MultifieldQA (Bai et al., 2023). 우리는 평가를 위해 두 가지 널리 사용되는 장문 컨텍스트 모델을 선택했습니다: LongChat-v1.5-7b-32k (Li et al., 2023)와 Yarn-Llama-2-7b-128k (Peng et al., 2023). 우리의 방법을 KV 캐시 제거 알고리즘인 H2O (Zhang et al., 2023b), TOVA (Oren et al., 2024), 그리고 StreamingLLM (Xiao et al., 2023)과 비교합니다. 우리는 3.4절에서의 분석이 이러한 레이어에서 낮은 희소성 비율을 나타내기 때문에, 모델의 첫 두 레이어에 Quest와 다른 베이스라인 알고리즘을 적용하지 않았습니다.
4.2 정확도 평가
4.2.1 PG19에서의 언어 모델링
우리는 먼저 평균 길이 70k 토큰의 100권의 책으로 구성된 PG19 테스트 세트에서 언어 모델링 퍼플렉시티를 평가합니다. LongChat-7b-v1.5-32k 모델을 사용하여 PG19에서 32k 토큰을 테스트합니다. 모델에 다양한 수의 토큰을 입력하고 생성된 토큰의 퍼플렉시티를 평가합니다. H2O, TOVA, 그리고 Quest를 총 토큰 길이의 약 1/8인 4096의 토큰 예산으로 평가합니다. 그림 6의 퍼플렉시티 결과에서 알 수 있듯이, Quest의 정확도는 풀 KV 캐시를 사용하는 오라클 베이스라인과 거의 일치합니다.
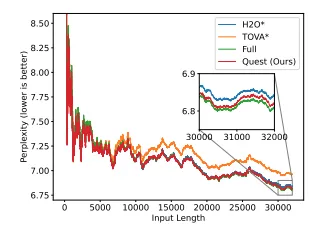
그림 6. PG19 데이터셋에서 Quest의 언어 모델링 평가. 우리는 모델에 PG19 테스트 세트에서 0부터 32,000까지의 토큰을 프롬프트로 제공하고 출력 토큰의 퍼플렉시티를 측정합니다. H2O와 TOVA는 모델의 첫 두 레이어에 대해서는 이러한 알고리즘을 적용하지 않아, 3.4절에서 분석한 바와 같이 모델 성능을 더 잘 유지합니다. Quest 또한 모델의 첫 두 레이어에서는 전체 캐시를 사용합니다. Quest는 전체 캐시 모델의 성능과 거의 일치할 수 있습니다.
4.2.2 장문 패스키 검색 작업의 결과
언어 모델링 평가가 로컬 종속성만 포함하기 때문에, 모델은 최근 토큰에 집중하여 우수한 성능을 달성할 수 있습니다. 그러나 장거리 종속성을 처리하는 능력은 긴 텍스트 추론에서 중요합니다. H2O와 TOVA와 같은 KV 캐시 제거 알고리즘의 경우, 미래 토큰에 중요한 KV 캐시의 일부가 폐기될 수 있어 모델이 올바른 답을 얻는 것을 방해할 수 있습니다. 모델이 장거리 종속성 작업을 처리하는 능력을 유지하는 데 Quest가 도움이 된다는 것을 보여주기 위해, 우리는 Yarn (Peng et al., 2023)의 패스키 검색 작업에서 그것을 평가합니다. 이 작업은 모델이 많은 양의 의미 없는 텍스트에서 간단한 패스키를 검색하는 능력을 측정합니다. 우리는 텍스트의 다양한 깊이 비율에 답을 넣고, 모델이 다른 KV 캐시 토큰 예산으로 올바른 답을 검색할 수 있는지 평가합니다. LongChat-7b-v1.5-32k를 10k 토큰 테스트에서, Yarn-Llama-2-7b-128k를 100k 토큰 테스트에서 평가합니다.
H2O (Zhang et al., 2023b)는 KV 캐시 정리를 위해 역사적 어텐션 점수를 계산해야 하기 때문에, 전체 O(n2) 어텐션 맵을 계산해야 하며, 따라서 장문 컨텍스트 추론을 위해 Flash-Attention (Dao et al., 2022)을 사용할 수 없습니다. 따라서 장문 컨텍스트 평가에서 H2O를 가능하게 하기 위해, 우리는 100k 시퀀스 길이 패스키 검색 테스트에서 컨텍스트 단계에서 Flash-Attention을 사용하고, 디코딩 단계에서 H2O를 위한 역사적 어텐션 점수를 수집하기 시작합니다. TOVA (Oren et al., 2024)와 StreamingLLM (Xiao et al., 2023)의 경우, 10k와 100k 시퀀스 길이에서 평가했습니다.
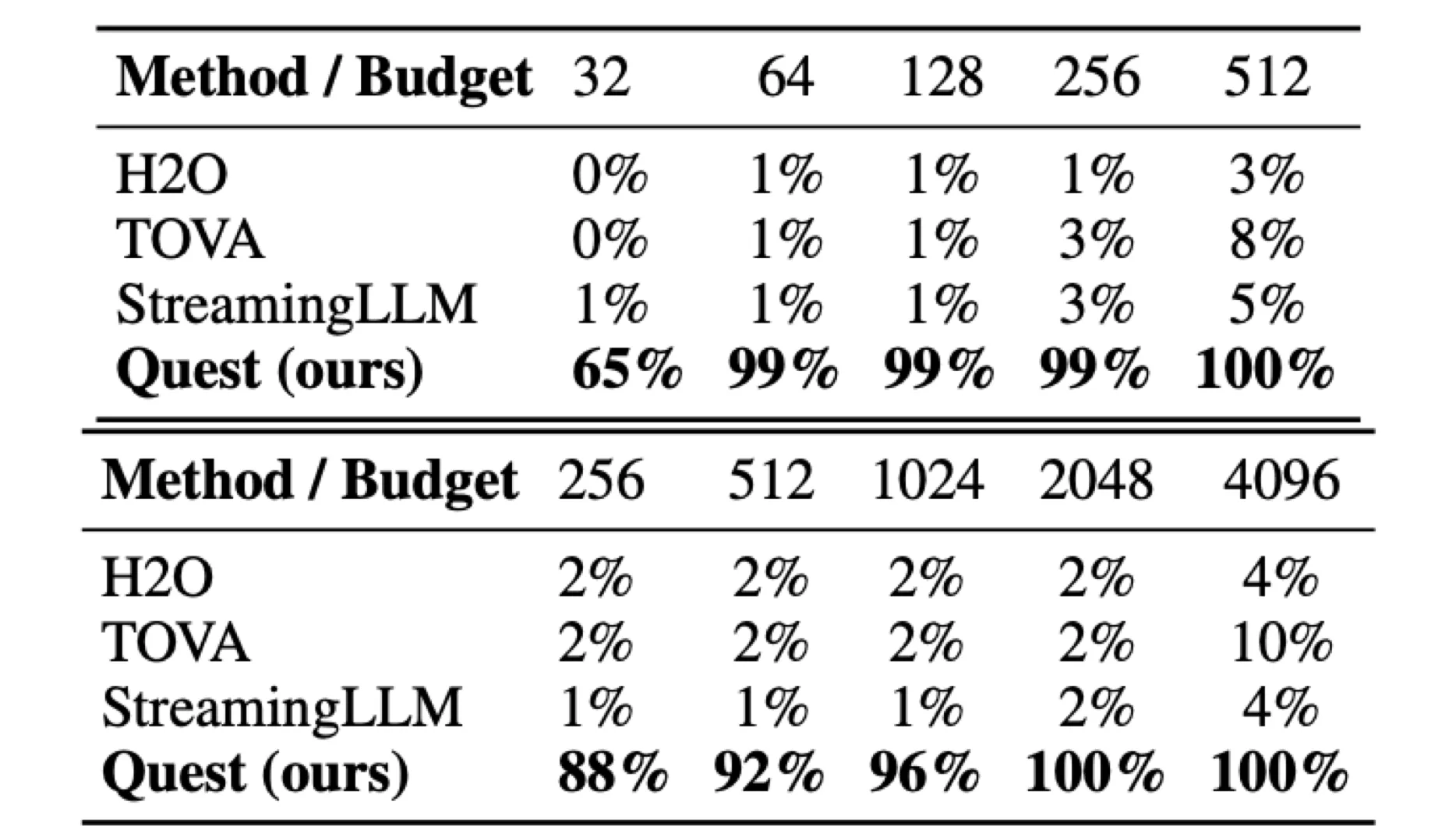
패스키 검색 테스트의 경우, 패스키와 텍스트를 포함한 입력 텍스트를 모델에 직접 사전 채우기(prefill)합니다. 그러나 실제 시나리오에서 모델의 장거리 종속성 정보를 처리하는 능력에 대한 다양한 방법의 영향을 평가하기 위해, 작업의 질문과 지시를 모델에 토큰 단위로 공급하여 디코딩을 시뮬레이션합니다. 이 경우, H2O와 TOVA는 나중에 쿼리될 패스키와 같은 미래 토큰에 중요한 토큰을 실수로 폐기할 수 있습니다. 마찬가지로, StreamingLLM은 가장 최근의 텍스트 창에만 집중할 수 있으며, 패스키가 이 창 밖에 나타나면 올바른 답을 제공할 수 없습니다. 따라서 H2O, TOVA, 그리고 StreamingLLM은 10k 및 100k 길이의 패스키 검색 테스트에서 이상적인 정확도를 달성할 수 없습니다. 그러나 Quest는 KV 캐시를 폐기하지 않고, 대신 쿼리-인식 접근법을 사용하여 중요한 토큰을 식별합니다. 표 1에서 보이듯이, Quest는 10k와 100k 시퀀스 길이 테스트 모두에서 최소한의 예산으로 거의 완벽한 정확도를 달성할 수 있습니다.
표 1. (i) LongChat-7b-v1.5-32k에서 10k 길이 패스키 검색 테스트 결과. (ii) Yarn-Llama-2-7b-128k에서 100k 길이 패스키 검색 테스트 결과.
(i) 10k 길이 테스트 결과:
| 방법 / 예산 | 32 | 64 | 128 | 256 | 512 |
|---|---|---|---|---|---|
| H2O | 0% | 1% | 1% | 1% | 3% |
| TOVA | 0% | 1% | 1% | 3% | 8% |
| StreamingLLM | 1% | 1% | 1% | 3% | 5% |
| Quest (ours) | 65% | 99% | 99% | 99% | 100% |
(ii) 100k 길이 테스트 결과:
| 방법 / 예산 | 256 | 512 | 1024 | 2048 | 4096 |
|---|---|---|---|---|---|
| H2O | 2% | 2% | 2% | 2% | 4% |
| TOVA | 2% | 2% | 2% | 2% | 10% |
| StreamingLLM | 1% | 1% | 1% | 2% | 4% |
| Quest (ours) | 88% | 92% | 96% | 100% | 100% |
‡Top-K 연산자는 무시할 수 있는 메모리 로딩 및 실행 시간을 소요합니다 (5-10 μs). 따라서, 우리는 효율성 분석에 그것을 포함하지 않습니다.
Quest는 총 시퀀스 길이의 약 1%인 64 및 1024 토큰 KV 캐시 예산으로 거의 완벽한 정확도를 달성할 수 있으며, 이는 Quest가 장거리 종속성 작업을 처리하는 모델의 능력을 효과적으로 유지할 수 있음을 보여줍니다. 그러나 H2O, TOVA, 그리고 StreamingLLM과 같은 KV 캐시 제거 알고리즘은 질문을 받기 전에 답변의 KV 캐시를 잘못 폐기하여 이상적인 정확도를 달성하지 못합니다.
4.2.3 LongBench에서의 결과
Quest가 일반적인 장문 컨텍스트 데이터셋에서 베이스라인보다 우수하다는 것을 검증하기 위해, LongBench의 여섯 개의 데이터셋에서 우리의 방법과 베이스라인을 평가합니다. LongChat-7b-v1.5-32k에서 NarrativeQA, Qasper, MultifieldQA 등의 단일 문서 QA, HotpotQA와 같은 다중 문서 QA, GovReport 등의 요약, TriviaQA와 같은 소수 샘플 학습 등 다양한 장문 컨텍스트 데이터셋을 평가합니다. H2O, TOVA, StreamingLLM, 그리고 Quest를 다양한 KV 캐시 예산으로 평가합니다. 모든 데이터셋에 대해, 입력을 자료와 질문/지시로 분할합니다. 자료 부분에 대해서는 Flash-Attention (Dao et al., 2022)과 전체 KV 캐시를 사용하여 추론을 수행합니다. 질문 부분에 대해서는, 토큰 단위로 모델에 공급하여 디코딩을 시뮬레이션합니다. 패스키 검색 테스트와 마찬가지로, H2O가 Flash-Attention을 사용할 수 있도록, 컨텍스트 단계에서 H2O의 역사적 어텐션 점수를 수집할 수 없었기 때문에 디코딩 단계부터 시작합니다.
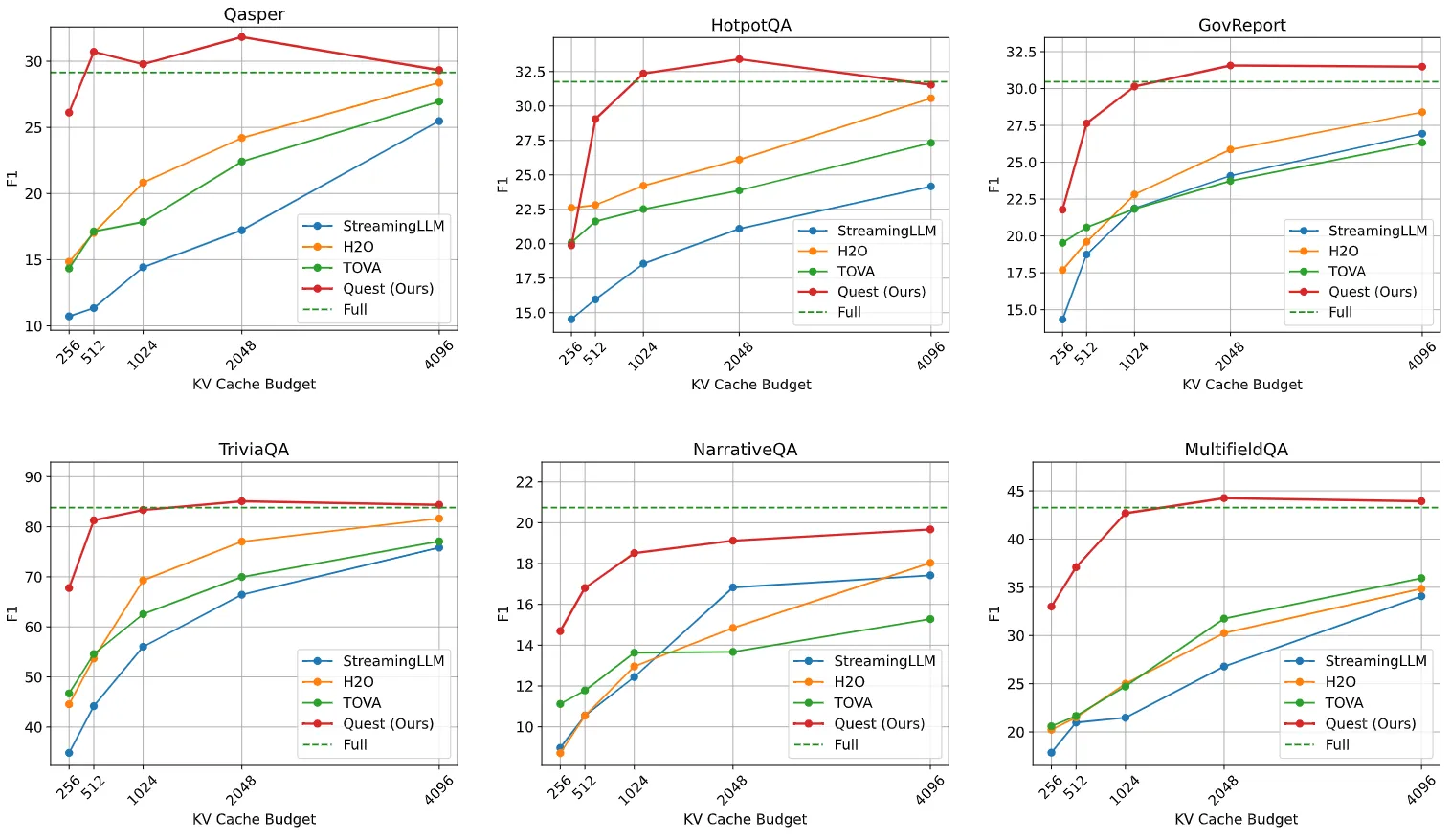
그림 7에서 보이듯이, Quest는 다양한 KV 캐시 예산과 여섯 개의 장문 컨텍스트 데이터셋 전반에서 모든 베이스라인을 지속적으로 능가합니다. Quest는 1K 토큰의 예산으로 전체 KV 캐시를 가진 모델과 비교할 만한 성능을 달성할 수 있으며, 다른 베이스라인은 더 큰 예산으로도 여전히 전체 캐시 성능과 상당한 격차를 보입니다. 첫 두 레이어에서 전체 캐시를 사용한 것을 고려하면, Quest는 Qasper, HotpotQA, GovReport, TriviaQA, NarrativeQA, 그리고 MultifieldQA에서 각각 KV 캐시 희소성이 1/6, 1/6, 1/5, 1/10, 1/5, 1/6으로 무손실 성능을 달성할 수 있습니다. 이는 Quest가 모델이 잘못된 KV 캐시 폐기로 인해 잘못된 답변을 생성하지 않도록, 다양한 유형의 장문 컨텍스트 작업에서 모델의 능력을 유지할 수 있음을 보여줍니다.
그림 7. 우리는 다양한 토큰 예산으로 여섯 개의 장문 컨텍스트 데이터셋에서 Quest와 베이스라인을 평가합니다. Quest는 모든 데이터셋과 모든 토큰 예산에서 모든 베이스라인을 지속적으로 능가합니다. 대부분의 데이터셋에서, Quest는 1K 토큰 예산으로 비교 가능한 정확도에 도달합니다. 모델의 장거리 종속성 정보를 검색하는 능력에 대한 다양한 방법의 영향을 평가하기 위해, 우리는 작업의 질문을 토큰 단위로 모델에 공급하여 디코딩을 시뮬레이션합니다.
4.3 효율성 평가
Quest의 실행 가능성을 보여주기 위해, FlashInfer (Ye et al., 2024)에 기반한 CUDA 커널로 전체 프레임워크를 구현했습니다. 먼저 Llama2-7B 구성에서 커널 수준 효율성을 평가합니다 (섹션 4.3.1). 또한 텍스트 생성의 엔드 투 엔드 속도를 보여줍니다 (섹션 4.3.2). FlashInfer의 일반 어텐션 구현과 Quest를 비교합니다. 개선 사항을 보여주기 위해, 동일한 정확도 하에서 Quest와 베이스라인의 효율성을 정성적으로 비교합니다 (섹션 4.3.3). 긴 컨텍스트 길이를 위한 엔드 투 엔드 평가에서는 Ada 6000 GPU (NVIDIA, 2023)를 사용합니다.
4.3.1 커널 평가
LLM 추론의 메모리 제한 특성 때문에, Quest의 속도 향상은 희소성 비율에 비례합니다 (이는 메모리 이동 감소와 동일합니다). 그림 8에서 이 효과를 정량화합니다. NVIDIA의 벤치마크 도구 NVBench (NVIDIA, 2024)를 사용하여 각 커널의 성능을 평가합니다.
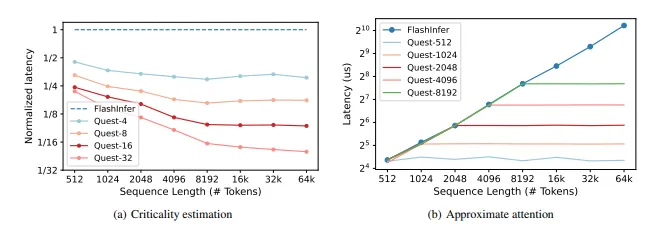
그림 8. Quest의 각 커널의 지연 시간을 측정합니다. (a) 시퀀스 길이가 증가함에 따라, 상대적인 중요도 추정 지연 시간은 FlashInfer의 1/페이지 크기로 감소합니다. (b) 토큰 예산 K를 가진 근사 어텐션은 전체 시퀀스 길이와 무관하게 일정한 시간을 소비하며, 시퀀스 길이 K에서 FlashInfer와 유사한 성능에 도달합니다.
중요도 추정
시퀀스 길이와 페이지 크기에서 Quest의 중요도 추정의 지연 시간을 평가합니다. 짧은 시퀀스 길이에서는 총 메모리 로드 크기가 GPU 메모리 대역폭을 완전히 활용하기에 충분하지 않기 때문에, 추정의 메모리 대역폭 활용률은 FlashInfer보다 작습니다. 시퀀스 길이가 증가함에 따라, 상대적인 성능은 개선되고 페이지 크기의 역수인 1/Page Size에 접근합니다. 이는 추정이 페이지당 하나의 토큰만 소비하기 때문입니다. 양자화 또는 더 큰 페이지 크기와 같은 기술은 추가 메모리 사용을 더욱 줄일 수 있습니다.
Top-K 필터링
RAFT (Zhang et al., 2023a)의 배치된 Top-K CUDA 연산자를 사용하여 Quest에서 Top-K 필터링을 활성화합니다. 시퀀스 길이와 토큰 예산에서 Top-K 필터링의 지연 시간을 테스트합니다. 중요도 추정이 전체 토큰을 하나의 중요도 점수로 줄이기 때문에, Top-K 필터링은 다른 연산자에 비해 제한된 메모리 이동을 가지며, 따라서 128k 이하의 시퀀스 길이에서 5-10μs의 낮은 지연 시간 오버헤드를 가집니다.
근사 어텐션
Quest는 PageAttention과 호환되므로, 근사 어텐션은 Top-K 페이지 인덱스를 희소 로딩 인덱스로 제공함으로써 쉽게 구현할 수 있습니다. 16의 페이지 크기로 시퀀스 길이와 토큰 예산에서 Quest의 근사 어텐션을 FlashInfer의 원래 어텐션과 비교합니다. 주어진 토큰 예산 B에서, 근사 어텐션의 지연 시간은 시퀀스 길이와 상관없이 상수입니다. 근사 어텐션은 최소한의 오버헤드를 도입하기 때문에, 시퀀스 길이 B에서 FlashInfer와 유사한 지연 시간을 가집니다.
우리는 또한 Quest의 어텐션 메커니즘을 평가합니다. 이는 Llama2-7B 모델에서 중요도 추정, Top-K 필터링, 근사 어텐션을 결합합니다. PyTorch 프로파일러를 사용하여 다양한 시퀀스 길이에서 Quest의 시간 분해를 그림 9에 보여줍니다. Quest는 2048의 토큰 예산으로 32K 시퀀스 길이에서 FlashInfer 대비 7.03배의 self-attention 속도 향상을 달성합니다.
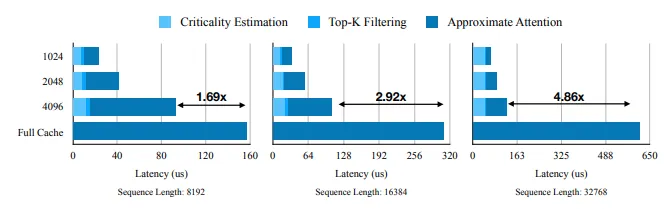
그림 9. FlashInfer와 비교한 Quest의 self-attention 시간 분해. 모든 시퀀스 길이에서, Quest는 FlashInfer를 크게 능가하며, 메모리 이동이 감소합니다. 시퀀스 길이 32K에서 토큰 예산 2048로 Quest는 self-attention을 7.03배 속도 향상합니다.
4.3.2 엔드 투 엔드 평가
Quest의 실용적인 속도 향상을 보여주기 위해, 프레임워크를 실제 단일 배치 시나리오에 배포했습니다. 디코딩 단계에서 다양한 시퀀스 길이와 토큰 예산에서 하나의 토큰을 생성하는 평균 지연 시간을 측정합니다. 샘플링 과정을 측정하지 않는데, 이는 실행 시간이 더 작고 설정에 따라 달라지기 때문입니다. FlashInfer로 구현된 전체 KV 캐시 베이스라인과 Quest를 비교합니다. 그림 10에서 보이듯이, Quest는 모든 시퀀스 길이에서 FlashInfer를 능가합니다. 시퀀스 길이가 증가함에 따라, Quest의 지연 시간은 크게 증가하지 않는데, 이는 Quest가 유사한 토큰 예산을 유지하기 때문입니다. 시퀀스 길이 32K와 토큰 예산 2048에서, Quest는 FP16 가중치로 추론 속도를 1.74배, 4비트 양자화 가중치로 2.23배 향상시킵니다.
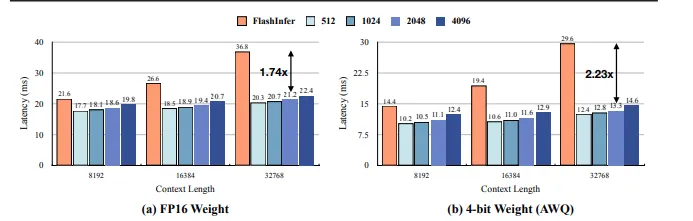
그림 10. Quest의 엔드 투 엔드 지연 시간. 모든 시퀀스 길이에서, Quest는 FlashInfer를 크게 능가합니다. 시퀀스 길이를 늘려도 Quest의 지연 시간은 약간만 증가합니다. 주어진 시퀀스 길이에서, 토큰 예산이 증가함에 따라 Quest의 지연 시간은 약간 증가합니다. 시퀀스 길이 32K, 토큰 예산 2048, 4비트 가중치 양자화로 Quest는 엔드 투 엔드 추론을 2.23배 속도 향상합니다.
4.3.3 베이스라인과의 비교
Quest의 성능 향상을 보여주기 위해, 롱벤치의 여섯 가지 작업에서 무손실 정확도를 달성하기 위해 동일한 정확도 제약 조건 하에서 다양한 어텐션 메커니즘의 효율성을 비교합니다. 그림 11(a)에 베이스라인의 무손실 정확도 목표를 위한 토큰 예산을 보여줍니다. 예를 들어, NarrativeQA는 평균 컨텍스트 길이가 24K 토큰입니다. 무손실 정확도를 달성하기 위해, TOVA는 14K의 토큰 예산이 필요하지만, Quest는 5K 토큰만 필요하여 훨씬 높은 희소성을 이끌어냅니다.
그러나 베이스라인 중 어느 것도 제안한 방법의 커널 구현을 포함하지 않았습니다. 따라서 FlashInfer의 추론 지연 시간을 사용하여 베이스라인의 self-attention 효율성을 정성적으로 분석하며, 다른 런타임 오버헤드(예: TOVA의 히스토리 스코어 계산 필요성)를 무시합니다. 반면, Quest는 모든 연산자를 고려한 실용적인 설정에서 평가됩니다. 그림 11(b)에서 보이듯이, Quest는 높은 쿼리 인식 희소성 덕분에 self-attention 지연 시간 면에서 모든 베이스라인을 크게 능가합니다. GovReport와 TriviaQA의 경우, Quest는 추론을 각각 3.82배, 4.54배 향상시킵니다. 따라서 Quest는 우수한 정확도를 유지하면서 더 높은 효율성을 달성할 수 있습니다.
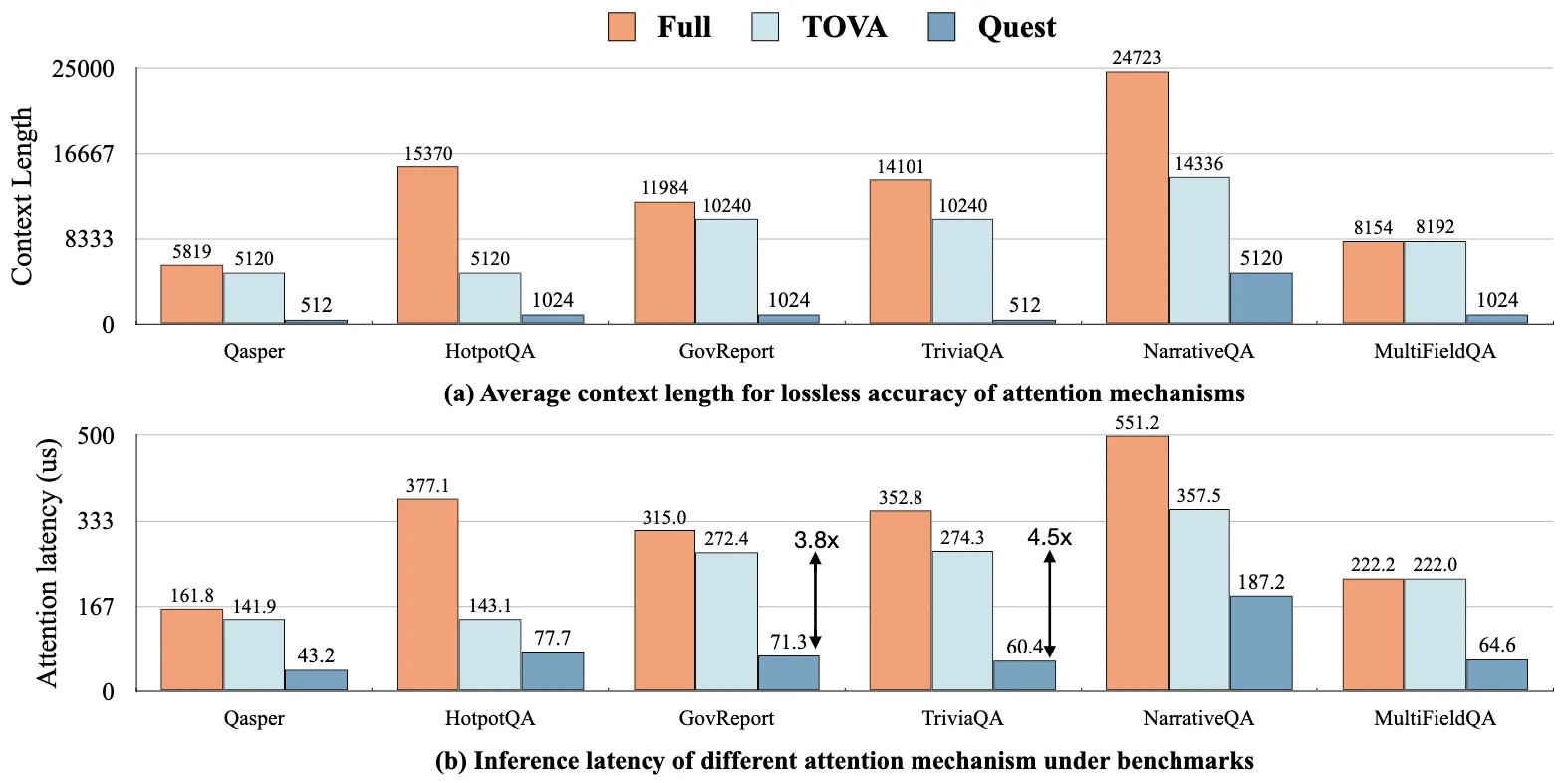
그림 11. 동일한 정확도 제약 조건 하에서 Quest와 베이스라인의 효율성 비교. (a) 다양한 어텐션 메커니즘에 의해 무손실 정확도를 위해 필요한 토큰 예산. Full은 원래의 어텐션을 나타내며, 이는 벤치마크의 평균 컨텍스트 길이를 의미합니다. (b) 벤치마크에서 비교 가능한 정확도에 대한 다양한 어텐션 메커니즘의 추론 지연 시간. Quest는 GovReport에서 TOVA 대비 self-attention 속도를 3.82배 향상시킵니다.
5. 결론
우리는 쿼리 인식 희소성을 활용하는 효율적이고 정확한 KV 캐시 선택 알고리즘인 Quest를 소개합니다. Quest는 페이지별 메타데이터와 현재 쿼리에 기반하여 KV 캐시의 토큰 중요도를 동적으로 추정합니다. 그런 다음 중요한 토큰에만 self-attention을 수행하여 메모리 이동을 크게 줄이고, 미미한 정확도 손실로 높은 희소성을 제공합니다. 종합적인 평가 결과 Quest는 최대 7.03배의 self-attention 속도 향상을 제공하며, 디코드 단계에서 2.23배의 엔드 투 엔드 지연 시간 감소에 기여합니다. 이전 베이스라인과 비교하여, Quest는 장문 컨텍스트 벤치마크에서 동일한 정확도 목표로 최대 4.5배의 self-attention 지연 시간을 줄입니다.
