https://aclanthology.org/2025.findings-emnlp.787.pdf

1. 논문 개요
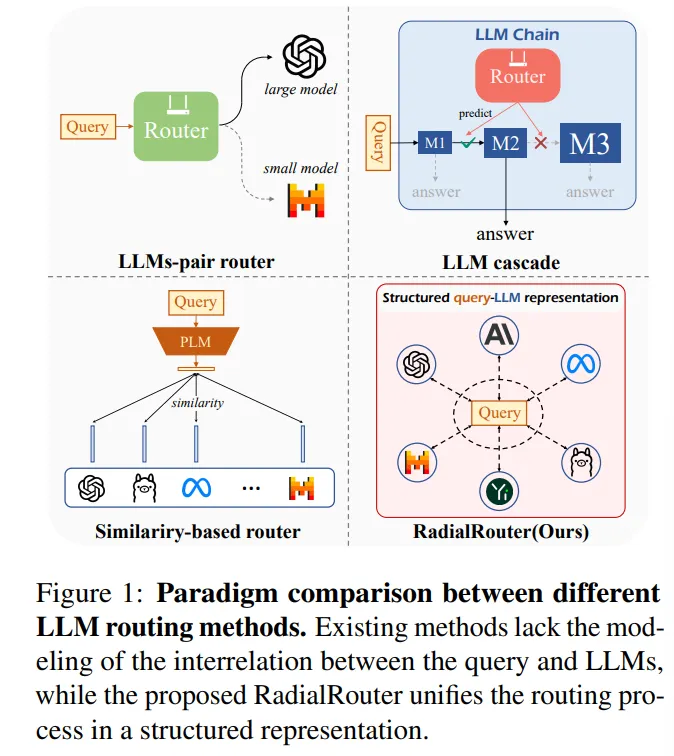
문제 설정
- 여러 개의 LLM(ensemble)을 갖고 있을 때, 각 질의마다 “어떤 LLM을 쓸지” 결정하는 라우팅(router) 문제를 다룸.
- 기존 라우팅 방법의 한계:
- 질의–LLM 사이의 내재적 관계(structured relation) 를 거의 모델링하지 않음 (단순 “이 질의는 큰 모델/작은 모델?” 수준).
- 주로 BERT 류 인코더에서 나온 질의 임베딩만 사용 → LLM 자체 특성 반영이 부족.
- 라우터가 고정된 LLM 풀에서만 동작하도록 설계되어, 나중에 LLM을 추가/삭제하기 어려움.
- 성능–비용 트레이드오프(Performance vs Cost) 를 명시적으로 고려하지 않는 경우가 많음.
제안 방법: RadialRouter
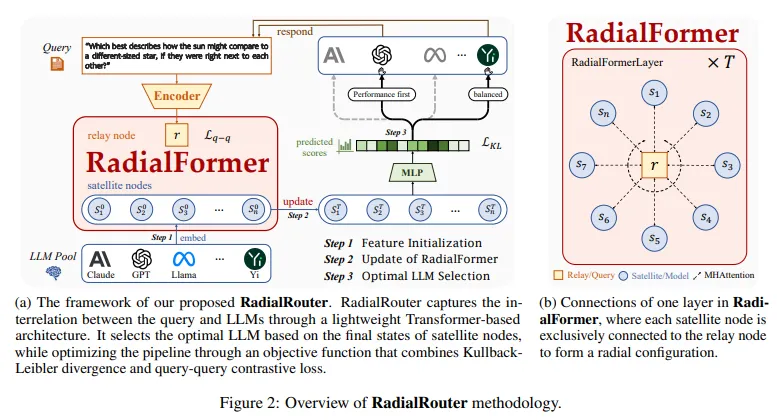
- 질의와 각 LLM 사이의 관계를 하나의 구조화된 표현으로 묶는, 경량 Transformer 백본 RadialFormer 를 제안.
- 노드 구조:
- Relay node: 질의를 나타내는 중심 노드
- Satellite nodes: 각 LLM을 나타내는 주변 노드들
- 이 구조 위에서 multi-head attention으로 질의–LLM 상호작용을 반복 갱신하고, 최종 satellite state로 각 LLM의 “적합도 점수”를 예측.
- 학습 목표:
- KL divergence loss: 라우터가 “성능–비용을 함께 고려한 LLM 점수 분포”를 잘 맞추도록 함.
- Query–Query contrastive loss: 의미적으로 비슷한 질의들의 임베딩이 가깝게, 다른 질의는 멀어지도록 하여 라우팅의 강건성을 높임.
기여 요약
- Transformer 기반의 RadialRouter 프레임워크 제안 – 질의별로 최적 LLM을 동적으로 선택.
- RadialFormer라는 경량 구조를 설계해, 질의–LLM 관계를 효율적으로 표현하고 contrastive loss로 라우팅 강건성을 향상.
- RouterBench에서 기존 라우터들보다 성능–비용 균형을 크게 개선하고, 다양한 trade-off 및 LLM 풀 변화에 잘 적응함.
2. 서론 내용 정리
2.1 배경
- 최근 LLM은 수학, 상식 추론, 코드 생성 등 여러 영역에서 뛰어난 성능을 보이지만, 모델이 커질수록 비용, 지연시간, 배포 복잡도가 크게 증가한다.
- 그래서 하나의 거대 모델 대신 여러 모델을 모아 쓰는 LLM ensemble(다수결, debate, cascade 등)이 등장. 하지만:
- 여러 모델을 동시에 또는 순차적으로 돌리면 비용/지연이 매우 커짐.
- 실서비스에서는 “.
2.2 LLM Routing의 필요성
- LLM routing: “이 질의는 어느 LLM이 가장 적합한가?”를 예측해,
- 쉬운 질의는 작은 모델에 보내고
- 어려운 질의/고품질이 필요한 질의는 큰 모델로 보내어 → 성능은 유지하면서 비용은 줄이는 것이 목표.
- 기존 연구:
- Binary router로 small vs large 결정 (HybridLLM, RouteLLM 등).
- FrugalGPT: cascade 구조에서 어느 단계에서 멈출지 결정.
- RouterDC: 질의–LLM, 질의–질의 contrastive 학습으로 라우팅 개선.
- GraphRouter: 질의/작업/LLM 간 관계를 그래프로 모델링.
- 하지만 이들은 대체로
- 질의–LLM 간 상호작용을 구조적으로 표현하지 못하고,
- BERT류 encoder 하나의 출력만 사용하며,
- dynamic LLM pool과 다양한 성능–비용 요구에 대한 적응이 부족하다고 비판.
2.3 RadialRouter 아이디어
- 질의와 각 LLM을 하나의 작은 “그래프/시퀀스”에 올려놓고,
- 중심에 질의(relay node),
- 주변에 LLM들(satellite nodes)을 두고,
- multi-head attention으로 이 관계를 반복 업데이트.
- 최종 satellite state는 “해당 LLM이 이 질의에 얼마나 잘 대응할 수 있는지”를 요약한 벡터 → 이를 MLP에 넣어 스칼라 점수로 변환, softmax로 확률화하여 라우팅.
- 학습 시에는 각 질의–LLM에 대해 (성능 – α·비용) 형태의 score를 계산하여 “ground-truth 분포 q”로 만들고,
- 라우터의 예측 분포 p와 KL divergence를 최소화.
- 추가로 query–query contrastive loss를 더해, 비슷한 질의들은 비슷한 라우팅 행동을 하도록 유도.
3. 방법론 (수식 중심 정리)
3.1 문제 정의
- 후보 LLM 집합:
- 각 질의 (x)에 대해 라우터는
- 질의를 입력으로 받아,
- 어느 LLM ()를 호출할지 결정: 여기서 ()는 “질의 x에 대해 LLM i를 선택할 확률”.
3.2 RadialFormer 구조
RadialFormer는 하나의 relay node + n개의 satellite node로 구성된 Transformer 변형이다.
- Relay node ():
- 질의 전체를 대표하는 노드 (중심).
- Satellite nodes ), 또는 ():
- 각 LLM i에 대한 상태 벡터.
(1) 초기화
- 질의 인코딩: 여기서 ()는 mDeBERTaV3-base encoder.
- LLM 임베딩:
- 각 LLM마다 학습 가능한 고정 벡터 ().
- 초기 상태:
(2) Satellite node 업데이트
각 층 t에서 위성 노드 ()는
이전 상태 (), 모델 임베딩 (), 을 함께 보는 multi-head attention으로 갱신된다.
-
컨텍스트 구성:
(세 벡터를 concat 한 것)
-
Multi-head attention:
-
비선형 + LayerNorm:
이를 모든 i에 대해 동시에 수행 → ().
(3) Relay node 업데이트
Relay node는 모든 satellite state와 자기 자신을 컨텍스트로 보며 attention.
-
컨텍스트 구성:
-
Attention:
-
비선형 + LayerNorm:
이 과정을 T번 반복하면 최종 상태:
(4) 복잡도
- 일반 Transformer는 길이 (l) 시퀀스에 대해 O((l^2 d)) 복잡도.
- RadialFormer는 “relay ↔ 각 satellite”만 연결되는 별(radial) 구조라,
- 전체 길이 ()일 때 복잡도가 O(ld) 로 줄어든다고 주장.
3.3 최적 LLM 선택 (RadialRouter Head)
RadialFormer로부터 얻은 최종 satellite state ()를 MLP에 넣어, LLM i의 “raw score”를 예측한다.
-
예측 점수
-
라우팅 확률
-
선택된 LLM
3.4 Ground-truth score와 KL Loss
각 질의–LLM에 대해 “성능–비용 균형을 고려한 score”를 미리 계산하여 레이블 분포로 사용한다.
(1) 성능–비용 기반 score 정의
질의 (x_j)에 대해 LLM i가 낸 응답의 성능과 비용을 사용해:
- (): LLM i가 ()에 대해 얻은 정확도(정답/오답, 혹은 평균 정확도의 근사).
- (): LLM i의 1M 토큰당 가격을 이용해 계산된 평균 비용.
- (): 성능–비용 trade-off를 조절하는 하이퍼파라미터
- Performance First: ( = 0)
- Balance: ( = 0.02)
- Cost First: ( = 0.1)
질의 (x) 하나에 대해 score 벡터를
라고 두고, 이를 softmax:
→ 라우팅 분포의 “정답” q 로 사용.
(2) KL divergence loss
라우터의 예측 분포 (p)가 이 정답 분포 (q)를 따라가도록 KL divergence를 최소화:
여기서 ()는 encoder, RadialFormer, MLP, LLM 임베딩 전부 포함한 파라미터 집합.
3.5 Query–Query contrastive loss
질의 임베딩끼리 contrastive loss를 걸어, 의미가 비슷한 질의는 가까이, 다른 질의는 멀어지게 학습.
- 전체 학습 쿼리에 대해:
- pre-trained encoder로 얻은 임베딩들을 t-SNE로 저차원 맵핑.
- 그 위에서 k-means로 N개의 클러스터 () 생성 (semantic 그룹).
- 한 질의 (x)에 대해:
- 같은 클러스터 안에서 하나를 양성 예시 (x^+),
- 다른 클러스터에서 H개를 음성 예시 (x_t^-) 로 샘플.
- cosine similarity () 를 사용하여 InfoNCE 형태의 loss:
여기서 (E(\cdot))는 라우터가 공동 학습하는 language encoder.
3.6 최종 학습 목표
최종적으로 라우터 파라미터 (\theta)는 아래 목적함수를 최소화하도록 학습:
- (): contrastive loss 가중치 (실험에서는 () 가 best).
학습 절차(Alg. 2) 요약:
- RouterBench 데이터의 각 (질의, 정답)에 대해 모든 LLM을 돌려 score_{ij} 계산.
- 위 score로부터 정답 분포 q 생성.
- 질의 임베딩으로 클러스터링 → query 그룹 (K_1, \dots, K_N) 구축.
- 미니배치마다
- 질의 x를 encoder로 임베딩 → RadialFormer 업데이트 → (S^T) → MLP로 p 계산.
- KL loss + query–query contrastive loss 계산 후 AdamW로 업데이트.
- 추론 시에는 p만 계산해서 (\arg\max_i p_i) LLM을 호출.
4. 실험 세팅 요약
4.1 벤치마크 & LLM 풀
- RouterBench 사용: 4개 task domain, 6개 데이터셋.
- Commonsense: Hellaswag, Winogrande, ARC-Challenge
- Knowledge: MMLU
- Math: GSM8K
- Coding: MBPP
- 후보 LLM 11개 (open-source + proprietary):
- WizardLM-13B, Mistral-7B, Mixtral-8x7B, Yi-34B, Code LLaMA-34B, LLaMA-2-70B
- GPT-3.5-turbo, GPT-4, Claude-instant, Claude-v1, Claude-v2
- 각 LLM의 평균 성능/비용은 RouterBench에서 제공된 통계를 사용 (표 7).
4.2 비교 방법
- Random: LLM을 랜덤으로 선택 (50회 평균).
- Best candidate: 각 시나리오(α 값)에서 score가 가장 높은 LLM 하나를 항상 사용.
- CosineClassifier: 질의 임베딩에 대해 cosine classifier로 multi-class 분류.
- HybridLLM: small vs large 이진 분류 라우터 (Mistral-7B ↔ GPT-4).
- FrugalGPT: cascade 기반.
- RouterDC: dual contrastive 학습 기반 router.
- GraphRouter: GNN 기반.
4.3 지표
- Performance: 6개 데이터셋 평균 정확도.
- Cost: 각 질의에 대해 실제로 사용된 LLM들의 평균 비용(달러).
- Score: [ \text{Score} = \text{Performance} - \alpha \cdot \text{Cost} ]
- α = 0 (Performance First), 0.02 (Balance), 0.1 (Cost First).
5. 메인 결과 & 실험 요약
5.1 Baseline 비교 (Table 1)
RouterBench 전체 평균 기준 (6개 데이터셋 평균).
| 시나리오 | RadialRouter Score | 가장 강한 baseline Score (대략) | 향상폭 |
|---|---|---|---|
| Performance First (α=0) | 0.816 | RouterDC 0.815 | 거의 동일 최고 |
| Balance (α=0.02) | 0.757 | GraphRouter 0.693, RouterDC 0.690 | +9.2%p 이상 |
| Cost First (α=0.1) | 0.715 | RouterDC 0.676, Best cand. 0.660 | +5.8%p 이상 |
- Performance First에서는 모두 GPT-4로 수렴해서 라우터 간 차이가 크지 않지만,
- 비용을 고려하는 Balance/Cost First에서는 → RadialRouter가 기존 라우팅보다 성능–비용 균형을 크게 개선.
- Oracle(항상 최적 LLM 선택) 대비 RadialRouter는 최소 82.66% 정도의 Score를 달성한다고 서술.
5.2 Ablation: RadialFormer & Loss (Table 2, 3)
(1) 구조 교체 실험 (Table 2)
- RadialFormer 대신
- Star-Transformer, 표준 Transformer, 단순 MLP로 대체.
- 결과:
- 세 구조 모두 Score가 떨어짐 (특히 Balance/Cost First).
- Time(ms) 기준:
- RadialRouter: 10.7ms
- Star-Transformer: 13.5ms
- Transformer: 15.8ms
- MLP: 4.6ms (가장 빠르지만 성능 가장 나쁨)
- 즉, RadialFormer가 가볍고(빠르고), 성능도 가장 좋음.
(2) Loss ablation
- KL loss 제거(w/o L_KL): Score가 PF 0.548, Balance 0.442, CF 0.017로 완전히 붕괴.
- q–q contrastive 제거(w/o L_q-q): PF/CF에서는 비슷하지만, Balance에서 0.757→0.749 정도로 하락.
- Fig. 3 t-SNE:
- contrastive 없음: 데이터셋 간 질의 임베딩이 섞여 있음.
- contrastive 있음: 데이터셋별 클러스터가 잘 분리 → 라우팅에 더 유리.
(3) Loss 종류 비교 (Table 3)
- KL vs Cross-Entropy vs Query–LLM contrastive.
- CE loss (단일 최적 LLM에만 1, 나머지 0): Score ~0.53 수준으로 크게 떨어짐.
- Query–LLM contrastive: KL보다는 낮음.
- KL이 세 시나리오 모두에서 최고 Score → 라우팅을 확률분포 맞추기 문제로 보는 것이 효과적이라는 결론.
5.3 Performance–Cost trade-off 곡선 (Fig. 4)
- α를 0, 0.01, 0.02, 0.05, 0.1로 바꿔가며 Score 측정.
- Fig. 4(a): 모든 α에 대해 RadialRouter 곡선이 다른 라우터들보다 위에 위치.
- Fig. 4(b): Performance–Cost plane에서 RadialRouter는
- 비슷한 비용에서 더 높은 성능,
- 비슷한 성능에서 더 낮은 비용을 달성하는 지점들로 구성 → trade-off 상 우월한 Pareto 위치.
5.4 Dynamic LLM pool (Table 4 & Fig. 5)
- LLM을 1개(WizardLM-13B)에서 시작해서 하나씩 추가(최종 11개, GPT-4까지)하면서 RadialRouter로 라우팅.
- Balance 시나리오에서
- #LLM=1일 때 Score ≈ 0.530
- #LLM=11일 때 Score ≈ 0.757
- LLM이 늘어날수록 성능과 Score가 꾸준히 상승 → RadialRouter가 새로운 LLM이 추가되어도 효과적으로 활용할 수 있음을 보임.
5.5 λ (contrastive weight) 민감도 (Table 6 & Fig. 6)
- Balance 시나리오에서 λ를 0 ~ 10까지 바꿔 측정.
- λ=0.5일 때 Score 최고 (0.757).
- λ ∈ [0.25, 5] 구간에서는 Score 변화가 크지 않아,
- λ 선택에 크게 민감하지 않고 robust 하다고 주장.
