https://arxiv.org/pdf/2505.23841

1. 서론 (Introduction)
1.1 배경: LLM, 환각, 그리고 KG-RAG
대형 언어모델(LLM)은 다양한 과제에서 매우 뛰어난 성능을 보여주지만, 최신 지식이나 도메인 특화 지식이 부족해 환각(hallucination)을 자주 일으킨다는 문제가 있다. 이를 완화하기 위해 최근에는 LLM이 외부 지식을 검색해서 가져와 활용하는 Retrieval-Augmented Generation (RAG) 방식이 널리 사용된다.
특히, 많은 방법들이 외부의 Knowledge Graph(KG)를 지식 베이스로 사용하고, 질의와 관련된 그래프의 triple들을 검색해서 LLM에 컨텍스트로 넣어주는 KG-RAG 구조를 사용한다. RAG에서 KG의 각 triple (\tau = (h, r, t))은 하나의 지식 컨텍스트 단위가 되며, 질의 (q)와의 의미·구조적 관련성에 따라 점수 (s)를 부여받는다. 이렇게 점수가 매겨진 triple들 중 상위 (K)개를 선택해 하나의 컨텍스트로 이어 붙인 뒤, LLM에게 함께 입력해 답변을 생성하게 한다. 예를 들어 SubgraphRAG는 각 triple에 대해 경량 MLP scorer (R)을 학습해 점수 (W={s_1,\dots,s_K})를 매기고, 상위 triple들을 이어 붙여 LLM에 제공하여 SOTA 성능을 얻는다.
문제는, LLM이 오토리그레시브 토큰 생성을 하기 때문에, 추론 비용이 입력·출력 토큰 수에 거의 비례한다는 점이다. KG-RAG는 환각을 줄이고 성능을 향상시키지만, 동시에 검색한 컨텍스트가 많아지면서 입력 토큰 수가 폭증한다. 예를 들어, CWQ 데이터셋에서 질의를 LLM에게 직접 물어볼 경우 질문당 62개의 토큰만 입력하면 되지만, SubgraphRAG 방식으로 triple 100개를 검색해 붙이면 질문당 1873개의 토큰이 되어, 입력 토큰이 30배 이상 증가한다. 이는 실제 서비스 환경에서 LLM을 적용하는 데 큰 장애가 된다.
1.2 LLM 라우팅과 기존 한계
이처럼 LLM 추론 비용이 크다는 문제를 줄이기 위해, 최근에는 LLM 라우팅(LLM routing) 연구가 활발하다. 기본 아이디어는 쉬운 질의는 작은 LLM으로, 어려운 질의는 큰 LLM으로 보내서 성능과 비용을 균형 있게 맞추는 것이다.
모델 크기에 따른 성능 향상은 점점 수확 체감(diminishing returns)을 보이는 경향이 있다. 예를 들어 Qwen2.5-14B-Instruct는 Qwen2.5-7B-Instruct보다 추론 비용은 2배가 안 되지만, 성능은 7.45% 정도 향상된다. 반면 Qwen2.5-72B-Instruct는 Qwen2.5-14B보다 비용은 약 7배지만 성능 향상은 2.12%에 불과하다.
하지만 지금까지 제안된 라우팅 방법들은 직접 QA 설정(direct LLM QA)에 초점이 맞춰져 있고, RAG/KG-RAG 환경으로 그대로 확장하기 어렵다. 논문은 그 이유를 두 가지로 정리한다.
-
학습 기반 라우터의 데이터 비용 문제
대부분의 기존 방법은 “어떤 질의는 어느 모델로 보내야 최적인가”를 예측하는 분류기(classifier)를 학습한다. 이를 위해서는
- 각 질의에 대해 “어떤 LLM이 가장 적합한가”라는 레이블이 필요하고,
- 이 레이블은 전문가 어노테이션이나 다수의 LLM 실험으로 얻어야 하며,
- 따라서 고품질 레이블을 대량으로 준비하는 비용이 매우 크고, 새 데이터셋이나 새 LLM에 대해서는 다시 라우터를 학습해야 한다.
-
지식 소스의 변화로 인한 라우팅 목표 변화
기존 “직접 LLM QA”에서는 라우터가 각 LLM의 내부 지식 차이(pretraining·파라미터 수 등)에 의존해 “어느 모델이 이 질문을 잘 아는가?”를 기준으로 라우팅한다.
반면 RAG/KG-RAG에서는 지식이 외부(검색된 컨텍스트)에 실려 있기 때문에, 모델 간 지식 차이보다 “외부 지식을 어떻게 잘 추론하는가”가 더 중요해진다. 즉, 라우팅의 초점이 ‘내부 지식’에서 ‘외부 지식 위에서의 추론 능력’으로 이동한다. 이 때문에 기존 라우팅 방법을 RAG에 그대로 가져오면 목표가 안 맞는다.
이 두 점 때문에, RAG 시나리오에서 효과적인 LLM 라우팅을 구축하는 데 큰 어려움이 있다. 그래서 논문은 다음과 같은 질문을 던진다.
“외부 지식(검색된 컨텍스트)에 대한 추론 난이도에 초점을 맞추어, 훈련 없이 동작하는 RAG 특화 라우팅 방법을 만들 수 있을까?”
1.3 점수 분포 스큐니스와 질의 난이도
저자들은 KG-RAG에서 retriever가 triple들에 부여한 점수 분포를 분석해 보았고, 질의마다 점수 분포의 모양이 크게 달라진다는 사실을 발견했다.
- 어떤 질의에서는 상위 몇 개 컨텍스트가 매우 높은 점수를 차지하고, 나머지는 긴 꼬리(long tail)의 낮은 점수로 이어지는 강하게 치우친(skewed) 파워 법칙(power-law) 분포를 보인다.
- 다른 질의에서는 비교적 많은 컨텍스트가 비슷하게 높은 점수를 받아, 전체적으로 스큐니스가 낮은(flat한) 분포를 보인다.
직관적으로 보면,
- 스큐니스가 높을 때는 “진짜로 중요한 triple 몇 개만 있으면 답이 나오는 질의”에 가깝고,
- 스큐니스가 낮을 때는 “여러 개의 triple을 합쳐서 multi-hop reasoning을 해야 답이 나오는 복잡한 질의”에 가깝다.
즉, retriever 점수의 “스큐니스(skewness)”가 질의 난이도와 강하게 상관되어 있으며, 이를 이용하면 질의 난이도를 추정해서 라우팅에 사용할 수 있다는 것이 저자들의 핵심 관찰이다.
1.4 SkewRoute의 아이디어와 기여
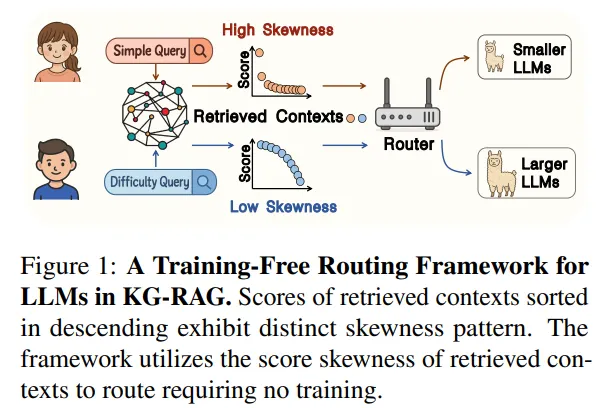
이 관찰을 바탕으로, 논문은 KG-RAG에 특화된, 완전 “training-free” 라우팅 프레임워크인 SkewRoute를 제안한다. 프레임워크의 흐름은 Figure 1에 요약되어 있다. 질의 (q)에 대해
- 기존 KG-RAG 파이프라인대로 triple을 검색하고 점수 ()를 얻은 뒤,
- 이 점수 분포의 스큐니스를 계산하여 질의 난이도를 추정하고,
- “쉬운 질의 → 작은 LLM (F_S)”, “어려운 질의 → 큰 LLM (F_L)”로 보낸다.
이때 SkewRoute는 어떤 스큐니스 지표든 플러그인처럼 끼워 넣을 수 있는 일반적인 라우팅 함수 ()로 정의된다. Formal하게는 다음과 같이 쓴다.
- 큰 LLM:
- 작은 LLM:
- 라우터:
- 최종 답:
여기서 ()는 라우팅 기준이 되는 스칼라 threshold이다.
저자들은 이 프레임워크가 기존 SOTA 라우터들보다 3배 이상 높은 routing effectiveness를 내면서도, 라우팅 단계의 runtime을 0.001배 수준으로 줄인다고 보고한다.
3. 방법론 (Methodology)
구성은 다음과 같다.
- 3.1 검색된 컨텍스트 점수의 스큐니스
- 3.2 스큐니스와 질의 난이도의 상관관계
- 3.3 스큐니스를 이용한 라우팅
- 누적 임계값 기반 라우팅
- 엔트로피 기반 라우팅
- 지니 계수 기반 라우팅
3.1 검색된 컨텍스트 점수의 스큐니스
KG-RAG에서는 보통 scorer (R)가 질의 (q)와 triple (\tau)의 관련도를 보고, 관련성이 높을수록 큰 점수, 낮을수록 작은 점수를 준다. 이 점수에 따라 상위 (K)개의 triple을 선택해 LLM에 넣기 때문에, 이 점수 분포의 모양 자체가 최종 성능에 큰 영향을 준다.
현실적으로, 질의는 “단일 hop의 간단한 질의”부터 “여러 triple을 거쳐야 하는 multi-hop 질의”까지 난이도가 다양하다. 이에 대해 저자들은 각 질의에 대해 상위 100개 triple의 점수를 시각화했는데, 다음과 같은 특징을 발견한다.
- 고 스큐니스(high skewness) 예시 (Figure 3a, 3c)
- log-log 스케일에서 거의 직선 형태의 파워 법칙 분포에 가깝다.
- 상위 소수의 컨텍스트만 높은 점수를 갖고, 나머지 대부분은 0.1 아래의 매우 낮은 점수를 갖는다.
- 이는 “실제로 답변에 유효한 triple이 몇 개만 있고, 나머지는 거의 노이즈”라는 상황이다.
- 저 스큐니스(low skewness) 예시 (Figure 3b, 3d)
- 많은 컨텍스트가 비교적 높은 점수를 갖는다.
- 예시에서는 전체 100개 triple 모두가 점수 0.1 이상이다.
- 이는 “여러 triple이 골고루 중요하고, 그 중 여러 개를 같이 써야 답이 나오는” multi-hop 질문에 대응한다.
직관적으로,
- 스큐니스가 높을수록 → “소수의 triple만 잘 찾으면 되는 단순 질의”
- 스큐니스가 낮을수록 → “여러 triple을 종합해서 추론해야 하는 복잡 질의” 에 해당하므로, 스큐니스는 질의 난이도의 좋은 신호가 될 수 있다.
3.2 스큐니스와 질의 난이도의 상관관계
(1) 스큐니스 정량화: 면적 기반 지표
먼저, 저자들은 스큐니스를 정량화하기 위해 “min-max 정규화된 점수 곡선 아래 면적(area)”을 사용한다.
- 점수 (s_i)를 순위에 따라 정렬한다 (보통 내림차순).
- 각 점수를 ([0,1]) 범위로 min-max 정규화한다.
- 정규화된 점수들을 순위에 따른 곡선으로 보고, 그 아래 면적을 적분(혹은 합산)하여 값 하나로 표현한다.
- 면적이 작을수록 → 상위 몇 개만 크고 나머지는 급격히 떨어지는 high skewness
- 면적이 클수록 → 많은 점수가 고르게 큰 low skewness
예시로, Figure 3c(고 스큐니스)의 면적은 1.07, Figure 3d(저 스큐니스)의 면적은 65.65이다.
(2) 질의 난이도 정의: “정답 triple의 순위”
문제는 “질의 난이도”에 대한 명시적인 레이블이 없다는 점이다. 또한 RAG에서는 “retrieval 결과가 잘 나오면 질의가 쉬워지고, retrieval이 애매하면 질의가 어려워진다”고 볼 수 있다.
그래서 저자들은 질의 난이도를 retrieval 결과만으로 근사한다. 아이디어는 다음과 같다.
- 극단적으로 쉬운 경우
- 상위 1위 triple이 이미 정답을 포함하고 있다.
- 이 경우, 질의는 “KG에서 단일 fact만 잘 찾으면 되는” simple question에 가깝다.
- scorer는 정답 triple에 매우 높은 점수를 주고, 그 triple이 1등에 위치한다.
- 어려운 경우
- 정답 triple이 순위 리스트의 아래쪽에 위치한다.
- 이 경우, 여러 semantically 관련 있으나 직접적으로 정답을 포함하지 않는 triple들이 상위에 오고, 정답 triple은 뒤에 숨어 있다.
- 이는 multi-hop reasoning이나 복잡한 연쇄 추론이 필요한 상황에 해당한다.
따라서, “정답 triple이 등장하는 순위(rank)”를 질의 난이도의 proxy로 사용한다.
- 순위가 낮을수록 (숫자가 작을수록) → 쉬운 질의
- 순위가 높을수록 (숫자가 클수록) → 어려운 질의
(3) 스큐니스 vs 질의 난이도: 실증 결과
이제, 위의 면적 기반 스큐니스와 정답 triple의 순위로 정의한 난이도를 이용해 상관관계를 본다.
- 먼저, 모든 질의를 면적 값 기준으로 3개 구간(작음/중간/큼)으로 나눈다.
- 면적이 작을수록 스큐니스가 높은 그룹.
- 각 그룹에 대해 “정답 triple이 평균적으로 몇 번째에 위치하는지”를 계산한다.
Figure 4의 결과를 보면, WebQSP와 CWQ 모두에서
- 스큐니스가 높을수록(면적 작음) → 정답 triple의 평균 순위가 앞쪽(숫자가 작음)
- 스큐니스가 낮을수록(면적 큼) → 정답 triple의 평균 순위가 뒤쪽(숫자가 큼)
즉, 높은 스큐니스 ↔ 낮은 질의 난이도, 낮은 스큐니스 ↔ 높은 질의 난이도라는 강한 상관관계가 확인된다.
이 결과를 통해, 저자들은 “점수 분포의 스큐니스만으로 질의를 ‘simple vs difficult’로 나눌 수 있고, 이것을 기반으로 LLM 규모를 선택할 수 있다”는 근거를 확보한다.
3.3 스큐니스를 이용한 라우팅 (Skewness-based Routing)
(0) SkewRoute 전체 흐름: 알고리즘 1
SkewRoute의 전체 라우팅 절차는 Algorithm 1에 요약되어 있다.
- 입력:
- 데이터셋 (D) (모든 질의 (q)들의 집합)
- threshold () (스큐니스 지표용 임계값; 어떤 지표를 쓰느냐에 따라 () 등으로 구체화됨)
- 과정:
-
답변 리스트 (A)를 빈 리스트로 초기화
-
각 질의 (q\in D)에 대해
- 질의 (q)에 대해 triple을 retrieval 하여 점수 ()를 얻는다.
- 스큐니스 측정 함수 ()를 계산한다.
- 답변 (a)를 리스트 (A)에 추가
-
최종적으로 (A)를 반환
-
여기서 핵심은 ()가 “스큐니스의 정도와 threshold의 차이”를 나타내는 scalar 함수라는 점이다. 스큐니스가 “simple query 영역”이면 ()이 되도록 threshold를 잡아, 작은 LLM으로 라우팅한다.
(1) Area 기반의 한계와 새로운 스큐니스 지표들
앞에서 사용했던 면적 기반 스큐니스 지표는 직관적이지만, 다음과 같은 두 가지 한계가 있다.
- min-max 정규화에 매우 민감함
- 질의마다 원래 점수의 범위가 다를 수 있는데, min-max 정규화 후 면적을 비교하면, 이런 차이가 왜곡된 방식으로 반영될 수 있다.
- 따라서 서로 다른 질의 간 면적을 안정적으로 비교하기 어렵다.
- 분포의 모양 정보를 많이 버림
- 모든 점수를 하나의 scalar(면적)로 압축해서,
- 서로 매우 다른 분포가 비슷한 면적 값을 가지는 경우가 생긴다.
- 즉, “어디서 급격히 떨어지는가”, “꼬리가 얼마나 긴가” 같은 상세한 shape 정보가 사라진다.
이 한계를 해결하기 위해, 논문은 새로운 스큐니스 지표 세 가지를 도입한다.
- 누적 임계값 기반 (Cumulative Threshold-based)
- 엔트로피 기반 (Entropy-based)
- 지니 계수 기반 (Gini coefficient-based)
이들은 분포의 형태를 더 잘 보존하면서, simple/difficult 질의를 더 안정적으로 구분할 수 있다고 주장한다.
3.3.1 누적 임계값 기반 라우팅 (Cumulative Threshold-based Routing)
확률·통계에서, 누적분포함수(CDF)는 랜덤 변수 (X)가 값 (x) 이하일 확률 )를 나타내며, 분포 전체의 모양을 직관적으로 보여주는 도구다. SkewRoute에서는 점수 분포를 일종의 확률분포로 보고, “상위 몇 개 컨텍스트만으로 전체 확률의 몇 %를 커버하는가”를 기준으로 스큐니스를 측정한다.
구체적인 절차는 다음과 같다.
-
점수 벡터 ()를 내림차순 정렬한다.
-
이 점수들을 합으로 나누어 확률분포 (p)로 정규화한다.
[
]
-
상위 (k)개까지의 누적합 (C_k)를 계산한다.
[
]
-
특정 누적 확률 (P) (예: 95%)를 정한다.
-
*()를 만족하는 최소의 (k)**를 찾는다.
- 스큐니스가 높으면 상위 몇 개만으로 대부분의 확률질량을 차지하므로, (k)가 작다.
- 스큐니스가 낮으면 많이 골고루 분포하므로, (k)가 크다.
이때 라우팅 함수는 다음과 같이 정의한다.
[
]
여기서 ()는 하이퍼파라미터(임계 순위)이다.
- *()**이면 ()이므로, 질의는 “simple”로 간주되어 작은 LLM (F_S)로 라우팅된다.
- *()**이면 ()이므로, 질의는 “difficult”로 간주되어 큰 LLM (F_L)로 라우팅된다.
3.3.2 엔트로피 기반 라우팅 (Entropy-based Routing)
엔트로피(Shannon entropy)는 확률분포가 얼마나 균일한지(혹은 불확실한지)를 측정하는 대표적인 지표다.
- 분포가 한두 개 값에 강하게 집중되어 있으면 → 엔트로피가 낮다.
- 분포가 여러 값에 골고루 분포되어 있으면 → 엔트로피가 높다.
SkewRoute의 점수 분포에 적용하면,
- 점수 스큐니스가 낮고(flat하고) 많은 컨텍스트가 비슷한 점수를 갖는 경우 → 엔트로피가 높음 → 난이도가 높은 질의
- 점수 스큐니스가 높고 일부 컨텍스트만 압도적으로 크면 → 엔트로피가 낮음 → 난이도가 낮은 질의
구체적인 정의는 다음과 같다.
-
다시 점수 벡터 ()를 합으로 나누어 확률분포 ()로 만든다.
[
]
-
엔트로피 (H)를
[
]
로 계산한다.
-
라우팅 함수는
[
]
로 정의한다. 여기서 ()는 엔트로피 threshold이다.
- () → () → 질의는 simple → 작은 LLM (F_S)
- () → () → 질의는 difficult → 큰 LLM (F_L)
요약하면, 엔트로피가 낮으면 “상위 몇 컨텍스트에 정보가 집중된 쉬운 질문”, 엔트로피가 높으면 “여러 컨텍스트를 고르게 써야 하는 어려운 질문”으로 간주하는 방식이다.
3.3.3 지니 계수 기반 라우팅 (Gini Coefficient-based Routing)
지니 계수(Gini coefficient)는 원래 소득 불평등 정도를 측정하기 위한 지표지만, SkewRoute에서는 이를 점수 분포의 불균형 정도, 즉 스큐니스의 정도를 측정하는 데 사용한다.
- 지니 계수가 높을수록 → 어떤 항목은 매우 크고, 나머지는 매우 작다는 의미 → 스큐니스가 크다
- 지니 계수가 낮을수록 → 값들이 서로 비슷하다는 의미 → 스큐니스가 작다
점수 벡터 ()에 대해 지니 계수는 다음과 같이 계산한다.
-
점수를 오름차순으로 정렬한다.
[
]
-
지니 계수는
이때 라우팅 함수는
[
]
로 둔다. 여기서 ()는 지니 계수 threshold이다.
- () → () → 스큐니스가 충분히 크다 → 질의는 simple → 작은 LLM으로 라우팅
- () → () → 스큐니스가 낮다 → 질의는 difficult → 큰 LLM으로 라우팅
즉, 지니 계수는 점수 분포의 불균형 정도를 한 번에 요약해 주는 지표로, high Gini ↔ 고 스큐니스 ↔ 쉬운 질문이라는 대응관계를 이용해서 라우팅 결정을 내린다.
- Q. 임계값(θ_k, θ_H, θ_G)은 어떻게 정하나? 수동인가?
2.1 논문에 나온 수식 상 정의
SkewRoute는 모든 방법에서 “임계값 기반 라우팅”을 사용하고, 이 임계값들을 θ로 표기해요.-
Cumulative Threshold-based Routing
- 점수 W 를 정렬·정규화해서 확률 분포 p로 바꿈: [ pi = \frac{s_i}{\sum{j=1}^K s_j} ]
- 누적합: [ Ck = \sum{i=1}^k p_i ]
- 주어진 누적 확률 P (예: 95%) 에 대해, [ C_k \ge P ] 을 만족하는 가장 작은 k를 찾음.
- 라우팅 스코어: [ L(W, \theta) = k - \theta_k ]
- 규칙:
- (k \le \theta_k) → 기 query는 simple → small LLM
- (k > \theta_k) → difficult → large LLM
- 점수 W 를 정렬·정규화해서 확률 분포 p로 바꿈: [ pi = \frac{s_i}{\sum{j=1}^K s_j} ]
-
Entropy-based Routing
- 동일하게 정규화한 확률 분포 p에 대해: [ H = -\sum_{i=1}^K p_i \log_2 p_i ]
- 라우팅 스코어: [ L(W, \theta) = H - \theta_H ]
- 규칙:
- (H < \theta_H) → skewness 높음(쉽다) → small LLM
- (H \ge \theta_H) → skewness 낮음(어렵다) → large LLM
- 동일하게 정규화한 확률 분포 p에 대해: [ H = -\sum_{i=1}^K p_i \log_2 p_i ]
-
Gini-based Routing
- 점수를 오름차순 정렬한 뒤 Gini 계산:[ \text{Gini} = \frac{1}{K} \left[ K + 1 - 2 \cdot \frac{\sum_{i=1}^K (K-i+1) s'*i}{\sum*{j=1}^K s'_j} \right] ] - 라우팅 스코어: [ L(W, \theta) = \theta_G - \text{Gini} ] - 규칙: - (\text{Gini} > \theta_G) → skewness 높음 → **small LLM** - (\text{Gini} \le \theta_G) → skewness 낮음 → **large LLM**여기서 중요한 점:
θ_k, θ_H, θ_G 모두 “학습으로 최적화된 파라미터”가 아니라 그냥 threshold 하이퍼파라미터로 등장해요.
2.2 논문이 말해주는 “임계값 설정 방식”
-
논문은 SkewRoute를 “training-free routing framework”라고 계속 강조해요.
→ 즉, 별도의 라우터를 학습하거나, θ를 gradient로 학습하는 구조는 아니라는 뜻.
-
본문에서 θ에 대해 “어떻게 구체적으로 설정했는지”에 대한 자세한 절차(예: dev set에서 grid search) 설명은 없어요.
- 다만 cumulative 쪽에서만
- “For a given probability P (e.g., 95%)” 라고 예시를 들고, 부록에서 P = 0.35 / 0.65 / 0.95 등의 값을 실험했다고 언급.
- 다만 cumulative 쪽에서만
-
실험에서 0, 20, 40, 60, 80, 100% call ratio를 맞추려면, 현실적으로는 이렇게 할 수밖에 없음:
- 각 query에 대해 skewness metric(Gini, Entropy, Cumulative에서의 k)을 계산.
- 원하는 large-LLM 비율 r에 대해,
- metric 순으로 query를 정렬해 놓고,
- 상위 r%를 “어렵다”로 보고 large LLM으로 보내도록 θ를 역으로 결정.
- 즉, threshold θ는 “target call ratio를 맞추기 위해서 설정되는 값”.
-
논문이 이걸 명시적으로 “이렇게 정했다”고 적진 않지만,
- Table 1,2에서 특정 call ratio마다 routing 성능을 측정하는 구조상
- θ는 call ratio를 컨트롤하기 위한 하이퍼파라미터로 보는 게 합리적이에요.정리하면:
✅ 팩트
- θ_k, θ_H, θ_G는 학습(gradient, RL 등으로 최적화된 파라미터가 아니다.
- 논문은 SkewRoute를 “training-free”라고 정의하며, router를 따로 학습하지 않는다.
- 따라서 임계값들은 수동/하이퍼파라미터로 설정되며, call ratio(large LLM 사용 비율)를 맞추기 위해 조정되는 것으로 해석하는 것이 맞다.
- 다만, “dev set에서 grid search했다” 같은 구체적인 기술은 논문에 직접적으로 적혀 있지 않다 → 이 부분은 우리가 합리적으로 추론하는 수준이다.
그래서 질문에 바로 답하면:
Q. “임계값들은 수동으로 정한 건가?”
→ 네, 논문 기준으로는 임계값은 학습된 게 아니라 수동(하이퍼파라미터)로 정해진 것이 맞아요.
- Cumulative에서는 P(누적 확률)와 θ_k를,
- Entropy/Gini에서는 θ_H, θ_G를
- 실험에서 원하는 large 모델 call ratio에 맞추도록 조정하는 식으로 사용했다고 보는 게 자연스럽고,
- 논문에는 이 값들을 학습했다는 내용은 전혀 없습니다.
-
SkewRoute 실험 세팅 & 결과 요약
1.1 실험 환경
- 도메인: Knowledge Graph RAG (KG-RAG)
- 기반 방법: SubgraphRAG 의 scorer를 그대로 사용 (트리플별 점수 W를 SkewRoute가 입력으로 받음).
- 데이터셋: KGQA 벤치마크 2개
- WebQSP: 상대적으로 쉬운 쿼리 (1–2개의 triple로 답 가능)
- CWQ (ComplexWebQuestions): 최대 4-hop까지 가는 복잡한 질의, multi-hop 비율이 높아서 더 어렵다고 명시.
- KG: 둘 다 Freebase를 사용 (1억 2천만 개 이상의 triple).
- 모델 조합
- Qwen 계열:
- Small: Qwen2.5-7B-Instruct
- Large: Qwen2.5-72B-Instruct
- LLaMA 계열:
- Small: Llama3.1-8B-Instruct
- Large: Llama3.1-70B-Instruct
- 추가 실험:
- Qwen7B (small) – Qwen14B (medium) – Qwen72B (large) 3단계 라우팅.
- Cross-family: Qwen7B ↔ Llama70B 라우팅도 테스트.
- Qwen 계열:
- 평가지표
- Hit@1: 가장 상위 예측이 정답인지 여부.
- Average Effectiveness (Avg. Eff.):
- 동일한 large-LLM call ratio(=큰 모델 호출 비율)에서 Random Routing 대비 Hit@1 향상 평균을 의미.
- 즉, “같은 예산(large 모델 호출 비율)에서 랜덤보다 얼마나 이득을 보는가”를 보는 지표.
- 동일한 large-LLM call ratio(=큰 모델 호출 비율)에서 Random Routing 대비 Hit@1 향상 평균을 의미.
- 비교 대상 (Baselines)
- Random Routing: small/large를 무작위로 선택 – 완전 하한선.
- RouteLLM (ICLR’25)
- GraphRouter (ICLR’25)
- 두 router 모두 “학습 기반 + RAG에 바로 맞지 않는다”는 점을 저자들이 비판하고, pre-trained checkpoint를 그대로 사용하는 세팅으로 비교.
1.2 Qwen 7B ↔ Qwen 72B 라우팅 (Table 1)
- 데이터셋: WebQSP, CWQ
- Call ratio: large LLM을 0%, 20%, 40%, 60%, 80%, 100% 비율로 사용할 때의 Hit@1 보고.
핵심 결과
- 모든 구간에서:
- Gini 기반, Entropy 기반, Cumulative 기반 SkewRoute가
- RouteLLM과 GraphRouter보다 일관되게 더 높은 Hit@1.
- WebQSP:
- Random 대비 Avg. Eff.:
- RouteLLM: +0.14
- GraphRouter: +0.44
- Ours(Gini): +1.23
- Ours(Entropy): +1.16
- Ours(Cumulative): +1.00
- Random 대비 Avg. Eff.:
- CWQ:
- Random 대비 Avg. Eff.:
- RouteLLM: +0.49
- GraphRouter: +0.47
- Ours(Gini): +1.17
- Ours(Entropy): +1.08
- Ours(Cumulative): +1.19
- Random 대비 Avg. Eff.:
- 논문에서 강조하는 포인트:
- SkewRoute(특히 Gini/Entropy)가
- 큰 모델 호출 비율을 약 40% 줄이면서도 “항상 large 모델만 쓸 때와 거의 동일한 성능”을 낸다고 주장.
- 큰 모델 호출 비율을 약 40% 줄이면서도 “항상 large 모델만 쓸 때와 거의 동일한 성능”을 낸다고 주장.
- SkewRoute(특히 Gini/Entropy)가
1.3 Llama 8B ↔ Llama 70B 라우팅 (Table 2)
- 세팅은 위와 동일한 call ratio grid.
- 결과 요약:
- WebQSP:
- RouteLLM, GraphRouter는 일부 구간에서 Random보다도 낮은 성능 (Avg. Eff.가 음수).
- SkewRoute(세 가지 방법)는 모든 call ratio에서 Random보다 우위.
- Avg. Eff. 기준 약 +0.86 ~ +0.95 정도 향상.
- CWQ:
- GraphRouter는 여전히 거의 도움이 안 됨(또는 negative).
- Gini 기반 SkewRoute가 RouteLLM보다 Avg. Eff. 5배 이상 높다고 서술.
- WebQSP:
1.4 Multi-model (Small–Medium–Large) & Cross-Family
- Small–Medium–Large 라우팅 (Qwen7B / 14B / 72B)
- Medium LLM(Qwen14B)을 추가로 넣어, 3단계 라우팅을 실험.
- 결과:
- Medium을 넣으면 성능–비용 트레이드오프가 크게 개선되고,
- SkewRoute는 여전히 Random보다 우위.
- Cross-family 라우팅 (Qwen7B ↔ Llama70B)
- 서로 다른 family, 다른 아키텍처/데이터로 학습된 모델 사이에서도
- SkewRoute가 잘 작동함을 보여주는 실험.
1.5 Ablation / 분석 (요약)
- 논문 본문 + 부록에서:
- 스코어 skewness와 “정답 triple의 순위” 관계를 분석해서,
- skewness가 높을수록(일부 triple만 높고 나머지는 낮을수록) → 정답 triple이 상위에 위치 → 질의가 “쉬움”.
- skewness가 높을수록(일부 triple만 높고 나머지는 낮을수록) → 정답 triple이 상위에 위치 → 질의가 “쉬움”.
- 스코어 skewness와 “정답 triple의 순위” 관계를 분석해서,
- 부록에서는 (텍스트 기준):
- Cumulative 방식의 P 값(누적 확률 목표) 을 0.35 / 0.65 / 0.95 등으로 바꿔보며 민감도 분석을 수행.
- 전반적으로 P가 바뀌어도 성능이 크게 깨지지 않고 robust 하다고 주장 (부록 A.6 참조 언급).
정리
- 이 논문은 retriever가 뱉는 triple 점수의 “스큐니스”가 질의 난이도와 강하게 연결되어 있다는 관찰에서 출발한다.
- 이를 기반으로, 어떤 학습도 필요 없는(training-free) 라우팅 함수 (L(W,\theta))를 설계하고,
- 누적 확률로부터 필요한 컨텍스트 개수 (k)를 보는 방법,
- 엔트로피 (H)를 보는 방법,
- 지니 계수(Gini)를 보는 방법 을 제안한다.
- 공통적으로 스큐니스가 높은(simple) 질의는 작은 LLM으로 보내고, 스큐니스가 낮은(difficult) 질의는 큰 LLM으로 보내도록 threshold를 세팅한다.
