https://arxiv.org/pdf/2308.11601
간단 요약
논문 "Tryage: Real-time, Intelligent Routing of User Prompts to Large Language Models"는 사용자 입력 프롬프트를 다양한 대형 언어 모델(LLM) 라이브러리로 동적으로 라우팅하기 위한 지능형 시스템 Tryage를 소개합니다. 다음은 논문의 주요 내용과 방법론 요약입니다.
1. 연구 배경 및 필요성
- LLM 생태계는 모델 아키텍처, 크기, 학습 데이터 및 패러다임에 따라 성능이 상이합니다.
- Hugging Face와 같은 플랫폼에는 26만 개 이상의 모델이 존재하지만, 사용자에게 적합한 모델을 선택하는 것은 어렵고 비용이 많이 드는 작업입니다.
- 기존의 모델 선택 방식은 리더보드 기반이나 정적 모델 카드 분석에 의존하며, 다수의 도메인이나 작업에 대한 동적 라우팅을 효과적으로 지원하지 못합니다.
- Tryage는 이러한 문제를 해결하고 사용자 프롬프트에 따라 최적의 모델을 동적으로 선택하는 라우팅 시스템을 제안합니다.
2. 주요 기여
- Tryage 라우팅 아키텍처:
- 인간 두뇌의 시상(thalamus) 라우팅 구조에서 영감을 받아 설계된 라우팅 시스템.
- 사용자 프롬프트와 플래그(예: 모델 크기, 최신성 등)를 기반으로 모델을 선택.
- 예측 기반 라우팅(Predictive Routing):
- 프롬프트와 작업에 대해 각 모델의 예상 손실을 Q-함수를 통해 예측하여 라우팅 결정.
- Pareto 최적화 지원:
- 정확도와 모델 크기, 처리 지연 등의 사용자의 목표 및 제약 조건을 통합한 최적화.
- 다양한 작업에서 성능과 비용 간의 균형점을 제공합니다.
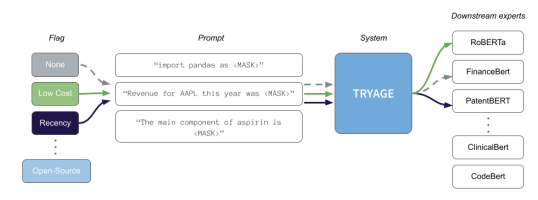
3. Tryage 아키텍처
(1) Oracle Router
- 이론적으로 최적의 라우터는 모든 모델에 대해 모든 프롬프트의 성능(Q 값)을 미리 알고 있으며, 이를 기반으로 모델을 선택합니다.
- 수학적으로 다음과 같은 최적화 문제를 해결:
- : 모델 의 프롬프트 z 에 대한 손실.
- : 모델 크기, 최신성 등 제약 조건.
- : 각 제약 조건의 중요도를 조정하는 가중치.
(2) Predictive Router
- 모든 프롬프트에 대해 Q 테이블을 생성하는 대신, Q-함수를 학습하여 각 모델의 성능을 동적으로 예측.
- Q-함수는 프롬프트와 모델 입력을 받아 예측된 손실 값을 출력:
- : 라우터 모델, : 학습된 가중치.
(3) End-to-End 학습
- 라우터와 하위 모델(전문가 모델)을 통합적으로 학습하여 각 전문가 모델이 라우터로부터 할당된 프롬프트에 대해 최적 성능을 달성하도록 최적화.
4. 실험 결과
- 라우팅 정확도:
- Tryage는 최적 모델을 50.8% 정확도로 선택, GPT 3.5 Turbo(23.6%)와 Gorilla(10.8%)를 능가.
- 도메인 적합성:
- Tryage는 프롬프트의 도메인에 따라 적절한 전문가 모델(예: GitHub 데이터 → 코드 모델)로 정확히 라우팅.
- Pareto 최적화:
- 모델 크기 제약( )을 추가하여 정확도 감소를 최소화하며 컴퓨팅 비용 절감.
- λ 값 조정을 통해 대규모 모델에서 소규모 모델로의 할당 변화를 유도.
5. 결론 및 향후 연구 방향
- Tryage는 동적 모델 라우팅의 새로운 패러다임을 제시하며, 정확성과 비용 간의 균형을 최적화할 수 있는 가능성을 보여줍니다.
- 향후 연구는 라우팅 시스템의 학습 효율성 개선 및 더 많은 사용자 제약 조건 통합을 목표로 합니다.
이 논문은 사용자 요구와 데이터 도메인에 따라 LLM을 동적으로 할당함으로써 다중 모델 시스템의 활용을 극대화하려는 중요한 기여를 제공합니다.
요약(Abstract)
트랜스포머 아키텍처와 셀프 어텐션 메커니즘의 도입은 특정 하위 작업과 데이터 도메인에 맞춰 학습된 언어 모델의 폭발적인 생산을 촉진했습니다. Hugging Face 생태계에는 200,000개 이상의 모델이 존재하며, 사용자는 복잡한 워크플로우와 데이터 도메인에 적합한 모델을 선택하고 최적화하는 과정에서 계산 비용, 보안 문제, 최신성 등의 우려를 해결해야 합니다. 사용자가 이 방대한 모델 라이브러리를 효과적으로 활용할 수 있도록 모델 선택과 커스터마이징 부담을 제거하는 머신러닝 프레임워크가 절실히 필요합니다. 이에 본 논문에서는 입력 프롬프트 분석을 기반으로 모델 라이브러리에서 전문가 모델을 최적 선택할 수 있는 컨텍스트 인지 라우팅 시스템 Tryage를 제안합니다.
이 시스템은 뇌의 시상(thalamus) 라우터에서 영감을 얻어, 입력 프롬프트에 대한 다운스트림 모델 성능을 예측하고, 사용자 목표와 제약 조건(예: 모델 크기, 최신성 등)이 포함된 플래그를 통합한 목적 함수를 통해 라우팅 결정을 내리는 지각적 라우터를 활용합니다. Tryage는 사용자가 Pareto 최적화 프론트(Pareto front)를 탐색할 수 있도록 하며, 작업 정확도와 모델 크기 최소화, 최신성, 보안, 가독성 등의 부수적 목표 간의 자동 트레이드오프를 지원합니다. 코드, 텍스트, 임상 데이터, 특허를 포함한 이질적인 데이터 세트 전반에서 Tryage 프레임워크는 Gorilla 및 GPT 3.5 Turbo를 능가하는 동적 모델 선택을 통해 최적 모델을 50.9% 정확도로 식별했습니다(GPT 3.5 Turbo는 23.6%, Gorilla는 10.8%).
개념적으로 Tryage는 라우팅 모델이 다중 모델 LLM 시스템의 동작을 프로그래밍하고 제어하여 확장되고 진화하는 언어 모델 생태계를 효율적으로 사용할 수 있는 방법을 시사합니다.
서론(Introduction)
트랜스포머 아키텍처와 셀프 어텐션 메커니즘의 도입은 자연어 처리(NLP) 및 컴퓨터 비전 분야에서 모델 아키텍처, 크기, 희소성, 학습 패러다임, 데이터 세트의 다양성을 가진 머신러닝 모델의 폭발적 증가를 초래했습니다. 현재 Hugging Face 모델 저장소에는 언어, 비전, 오디오 작업을 위한 약 262,000개의 머신러닝 모델이 포함되어 있으며, 여기에는 마스킹, 디스틸레이션, 명령어 수행, Q&A, PEFT, 희소화(sparsification), 양자화(quantization), 강화학습(RLHF) 작업을 수행하도록 학습된 모델이 포함됩니다.
이 저장소는 LLAMA, Falcon과 같은 대규모 범용 모델과 T5, FlanT5, Bloom, BART-MBPI와 같은 텍스트 변환 모델뿐만 아니라, BERT, RoBERTa, ClinBERT, PatentBERT, CodeBERT와 같은 소규모의 특정 도메인에 최적화된 모델도 포함합니다. 각 모델은 일반적으로 크기(예: tiny, base, large, XnL)별로 제공됩니다.
사용자는 다중 작업과 도메인을 포함하는 특정 워크플로우에 적합한 모델을 선택하고 최적화하는 데 있어서 매우 맥락 의존적인 문제를 직면하고 있습니다. 따라서 사용자의 모델 선택 및 커스터마이징 부담을 제거하고, 사용자가 방대한 모델 라이브러리를 효율적으로 활용할 수 있도록 돕는 머신러닝 프레임워크가 필요합니다.
현재 모델은 주로 Hugging Face, Dynabench, PapersWithCode와 같은 리더보드에 표시된 요약 통계(예: Squad Q&A, Pile, GLUE)를 기반으로 비교됩니다. 엔지니어는 리더보드에 따라 모델을 선택한 후 시간 소모적인 테스트와 모델 통합 과정을 통해 프로덕션에 배포합니다. 그러나 요약 통계는 다양한 작업과 데이터 도메인을 통합해야 하는 데이터 세트를 프로덕션에 배포하려는 사용자에게는 대략적인 가이드에 불과합니다.
예를 들어, 금융 전문가가 금융 텍스트와 특허 및 법률 데이터를 분석해야 하거나, 의료 기록이 환자의 병력, 사회적 정보, 약물 및 진단 정보, 청구 정보를 포함하는 경우처럼, 데이터 세트는 여러 도메인을 통합할 수 있습니다. 이와 같이, 생산 환경에서 모델은 여러 도메인에서 생성된 프롬프트에 대해 요약, Q&A, 디스틸레이션과 같은 다양한 작업을 수행해야 할 수 있습니다. 또한, 모델 생태계가 계속 진화함에 따라 데이터 세트와 사용자 요구가 변화할 수 있으므로, 리더보드 기반 모델 선택은 프로덕션에서 동적으로 유지하기에 비용이 비쌉니다.
더 나아가, 사용자는 모델 선택 시 모델 크기(계산 비용), 헛소리 생성 확률(hallucination probabilities), 최신성, 보안, 가독성 등의 추가 목표와 제약 조건을 고려해 Pareto 최적화를 수행하고자 할 수 있습니다. 예를 들어, 최종 사용자 작업 정확도가 2%만 감소한다면, 모델 크기를 50% 줄이는 'tiny' 모델을 선택할 수도 있습니다.
이와 같은 문제를 해결하기 위해 본 논문에서는 인간 두뇌의 계산 아키텍처 및 강화 학습의 Q-러닝 패러다임에서 영감을 얻어 Tryage라는 지각적 라우팅 아키텍처를 도입했습니다. Tryage는 사용자 입력 프롬프트를 실시간으로 분석하고, 사용자 플래그(예: 모델 크기, 소스)와 통합하여 동적이고 무작위적(zero-shot) 라우팅을 수행합니다.
실험 결과, Tryage는 개별 프롬프트에서 전문가 수준의 성능을 달성했으며, 특정 도메인에서는 RoBERTa를 최대 17.9% 초과했습니다. 또한, Tryage는 Gorilla 및 GPT 3.5 Turbo를 능가하는 모델 선택 성능을 보여주었습니다. Tryage는 모델 크기, 정확도, 지연 시간 등의 측면에서 Pareto 최적화를 지원하며, 데이터 도메인 간의 해석 가능한 잠재 표현을 학습할 수 있는 시스템입니다.
Tryage 모델 아키텍처 및 수학적 프레임워크
언어 모델은 CommonCrawl과 같은 일반적인 데이터 소스와 Pile 서브셋, 금융 데이터, 임상 데이터와 같은 도메인 특화 데이터에서 샘플링된 데이터를 사용해 학습됩니다. 또한 마스킹 언어 모델링(Masked Language Modelling), 인과 언어 모델링(Causal Language Modelling) 등 다양한 패러다임으로 학습 및 미세 조정됩니다. 이 때문에 기존 언어 모델은 다운스트림 작업과 도메인별 데이터에서 서로 다른 성능을 보입니다.
Figure 2는 여러 주요 트랜스포머 모델이 다양한 데이터 도메인에서 마스킹 언어 모델링 작업에서 보이는 성능을 보여줍니다. 예를 들어, Roberta 모델은 Pile 데이터 세트 전반에서 평균 정확도가 가장 높았지만, GitHub 또는 특허 데이터베이스와 같은 특정 도메인의 입력 데이터에서는 CodeBERT 및 PatentBERT와 같은 전문가 모델이 Roberta를 크게 능가했습니다. 이러한 실험적 결과는 특정 입력에 따라 최적의 모델을 동적으로 선택할 수 있는 다중 모델 아키텍처의 개발을 촉진합니다.
시스템의 목표는 일반적인 높은 정확도를 유지하면서도 특정 데이터 분포에서 생성된 프롬프트나 작업에 대해 전문가 수준의 성능을 확보하는 것입니다.
동적 라우팅 시스템
사용자 프롬프트와 작업을 모델 라이브러리에 동적으로 라우팅하기 위해 Tryage라는 지각적 라우팅 시스템을 설계했습니다. 이 시스템은 다음과 같은 구성 요소로 이루어집니다:
- Tryage 노드: 프롬프트를 수신하여 라우팅 기능을 실행합니다.
- 다운스트림(리프) 노드: 프롬프트에 따라 선택된 하위 모델 라이브러리.
라우팅 함수는 다운스트림 모델의 성능을 결합하고, 사용자가 제공한 제약 조건 또는 목표 플래그와 통합하여 단일 목적 함수를 생성합니다. 이 라우팅 함수는 예측된 정확도와 가중된 제약 조건 간의 트레이드오프를 통해 특정 모델을 선택합니다. 라우팅 손실 함수의 최적화 결과로 모델 선택이 이루어지고, 프롬프트는 선택된 다운스트림 모델로 라우팅됩니다.
수학적 정의 및 기본 표기
- 모델 라이브러리 :
- 각 모델 는 입력 z 를 받아 출력 를 생성합니다.
- 예를 들어, 는 다음 단어 예측 확률이 될 수 있습니다.
- 라우팅 목표:
- 모델 선택/프롬프트 라우팅 전략을 개발하여 라우팅 모델 R 이 사용자 제약 조건을 포함한 최적의 전문가 모델 를 특정 프롬프트에 대해 선택하도록 합니다.
- 단순 전략으로 데이터 세트 레이블을 기반으로 모델을 선택할 수도 있지만, 데이터 스트림은 종종 여러 도메인 정보를 포함하고 데이터 레이블이 없을 수 있으므로 이는 비효율적입니다.
- 강화학습과의 유사성:
- 모델 선택 문제는 강화학습(RL)의 다중 슬롯머신 문제(Multi-Armed Bandit) 및 컨텍스추얼 밴딧(Contextual Bandit) 문제와 개념적으로 유사합니다.
Q 함수 및 라우팅 결정
- 입력 z 와 손실 함수 가 주어졌을 때, Q 함수는 행동 를 보상 로 매핑합니다.
- 구체적으로, 행동은 프롬프트 z 를 가능한 전문가 모델 로 라우팅하는 것을 나타냅니다.
- Q 함수는 다음을 예측합니다:
여기서 Q 함수는 다운스트림 손실 값을 예측하도록 학습된 언어 모델로 구현됩니다.
Q 함수는 예측된 손실 값을 라우팅 함수로 전달하며, 이 함수는 가중된 제약 함수와 결합하여 라우팅 결정을 내립니다.
이론적 모델: Oracle Router
- Oracle Router는 모든 프롬프트에 대해 모든 전문가 모델의 성능(Q 값)을 알고 있다고 가정합니다.
- 라우터는 다음 목적 함수를 최적화하여 모델을 선택합니다:
여기서:
- : 프롬프트 z 에 대한 모델 의 손실.
- : 모델 크기(log(#parameters)), 최신성, 헛소리 생성 확률(hallucination probabilities) 등 제약 조건.
- : 각 제약 조건의 가중치.
Oracle Router는 정확성과 제약 조건 간의 트레이드오프를 허용하여 사용자가 원하는 목표에 부합하는 모델을 선택합니다.
Tryage에서의 사용자 제약 통합
- 사용자 제약은 프롬프트 자체에 통합됩니다. 예를 들어:
- “The capital of California is [blank][Flag: Smallest model]”.
- 두 가지 비용(모델 손실 및 제약 비용)이 결합되어 라우팅 손실 L_R 을 형성하며, 이를 최소화하여 Oracle Router가 예측 모델 \hat{M}_O 를 출력합니다.
다양한 제약 조건의 통합
- 제약 함수 는 최신성, 가독성, 헛소리 생성 확률 등 다양한 요인을 기반으로 모델을 평가할 수 있습니다.
- 사용자는 값을 조정하여 제약 조건의 중요도를 설정하고, 모델 크기부터 성능까지 다양한 요소를 균형 있게 고려할 수 있습니다.
Predictive Router 모델 번역
오라클 전략이 제공된 데이터를 기반으로 다운스트림 모델을 선택할 수 있지만, 모든 프롬프트에 대해 모든 모델 |M| 을 실행하여 Q 테이블을 생성하는 것은 계산 비용이 매우 비효율적입니다. 따라서, 목표는 Q 함수를 학습하여 다운스트림 손실을 추정하고, 이를 통해 개별 입력 프롬프트를 동적으로 분석하여 추정된 손실 값을 반환하는 것입니다.
프롬프트를 로컬에서 분석하는 한 가지 방법은 프롬프트와 전문가 모델의 손실 데이터 세트를 기반으로 라우팅 모델을 지도 학습 패러다임에서 학습하여 Q 테이블을 예측하는 것입니다.
지도 학습 기반 라우터 학습
-
함수 정의:
- R : 프롬프트 z 를 입력으로 받아 모델 에 대한 추정 손실 값을 반환하는 함수.
- W : 함수의 학습된 가중치(모델 매개변수).
- R 은 W 에 대해 미분 가능해야 하며, 기존 언어 모델을 기반 아키텍처로 사용해 구현합니다.
- 예: Bert-tiny 기반으로 구현하여 손실 예측 정확도를 개선.
-
학습 손실 함수 정의:
- 손실 함수:
- : 와 실제 손실 간의 발산(Divergence).
- : 데이터 분포에서 추출된 프롬프트. -
학습 방법:
- 확률적 경사 하강법(SGD)으로 학습.
- 미니배치 크기 m 에 대해:
- 평균적으로 실제 손실에 대해 내외의 정확도로 근사 가능.
라우터 및 전문가 모델의 통합 학습
- 전체 아키텍처(라우터 + 다운스트림 모델)를 엔드투엔드(end-to-end)로 학습 가능.
- 라우팅 결정:
- : 프롬프트 z 에 대한 모델 의 성능 예측.
- : 모델 크기, 최신성 등 제약 조건.
- : 제약 조건의 가중치.
- 전문가 모델 업데이트:
-
선택된 모델 *의 가중치 를 프롬프트 z 에 대해 최적화:
*
-
Tryage 실험
- 아키텍처 평가:
- Hugging Face 생태계에서 가져온 11개의 자연어 모델 라이브러리를 사용하여 모델 선택 작업 수행.
- 평가 데이터: Pile 데이터 세트.
- 성능 비교:
- Tryage는 Gorilla 및 GPT 3.5 Turbo를 능가하는 정확도를 달성:
- Tryage: 50.8% 정확도.
- GPT 3.5 Turbo: 23.6%.
- Gorilla: 10.8%.
- Tryage는 Gorilla 및 GPT 3.5 Turbo를 능가하는 정확도를 달성:
- Emergent Capabilities:
- Tryage는 도메인 간 데이터의 자율적(latent) 표현을 학습.
- 기존 모델(GPT2)보다 더 자연스럽고 해석 가능한 데이터 표현 생성.
- 제약 기반 라우팅:
- 모델 크기와 정확도 간의 글로벌 최적화를 위한 Pareto 프론트 계산.
- 사용자는 제약 조건의 가중치를 조정하여 효율성과 성능 간의 균형점을 설정할 수 있음.
요약
Predictive Router는 Q-함수를 학습하여 프롬프트에 대해 각 모델의 예상 성능을 계산하고, 이를 기반으로 동적 라우팅 결정을 내립니다. 또한 라우터와 전문가 모델을 엔드투엔드로 학습하여 각 모델이 특정 도메인에서 최적의 성능을 발휘하도록 만듭니다. Tryage는 기존 접근법 대비 우수한 성능과 적응성을 입증하며, 모델 크기와 성능 간의 최적화도 지원합니다.
Tryage 모델 성능 평가 번역
Tryage는 Pile 데이터 세트에서의 MLM 작업에서 Gorilla를 능가
Tryage 시스템은 Pile 데이터 세트를 사용하여 마스킹 언어 모델링(Masked Language Modeling, MLM) 작업을 수행하도록 훈련되었으며, 최신의 지각적 모델 선택 시스템과 성능을 비교하였습니다. MLM은 다음과 같은 이유로 벤치마크 작업으로 사용되었습니다:
- 객관적으로 평가 가능.
- 다양한 모델 가용성.
- 대규모 기반 모델 학습의 기본 패러다임.
Pile 데이터 세트는 Common Crawl과 같은 일반 텍스트뿐만 아니라 Gutenberg, GitHub, Stack Overflow, USPTO 특허 등 특정 도메인 데이터를 포함하는 다중 도메인의 대규모 텍스트 저장소입니다.
- 라우팅 모델: 초기 실험 결과, 더 큰 모델이 성능을 크게 개선하지 않는다는 점에서 BERT-small이 선택되었습니다.
- 다운스트림 전문가 모델: Hugging Face에서 제공되는 ClinicalBERT, SECBERT, FinancialBERT, PatentBERT, CodeBERT와 Roberta 및 기타 BERT 변형 모델 11개를 선택하였습니다.
훈련 설정
- 훈련 환경:
- ADAM 옵티마이저를 사용하며, 가중치 감소(1e-5) 및 지수적으로 감소하는 학습률(5e-5)을 적용.
- 입력 데이터는 최대 512 토큰으로 제한하여 처리.
- 배치 크기: GPU당 24.
- 하드웨어: 80GB RAM을 가진 A100 GPU.
- 조기 중단 조건: 에포크당 4회 검증 손실을 측정하며, 16번 연속으로 성능 개선이 없으면 중단.
- 최적의 검증 손실 모델을 모델 체크포인트로 사용하여 테스트 진행.
- 훈련 프레임워크:
- PyTorch Lightning을 활용하여 효율적으로 모델 훈련.
평가 결과
훈련 후, Pile 데이터의 테스트 데이터를 사용하여 성능을 평가한 결과:
- Tryage는 전문가 모델 수준의 성능을 달성하며, Gorilla 및 GPT 3.5 Turbo와 같은 최신 접근 방식을 능가.
- 프롬프트를 이상적인 모델로 라우팅할 정확도:
- Tryage: 50.8%.
- GPT 3.5 Turbo: 23.6%.
- Gorilla: 10.8%.
GPT와 Gorilla 결과는 과대 추정된 값으로, "최적 모델의 일부 증거"를 포함한 출력만 확인한 기준입니다.
Gorilla의 한계
- Gorilla가 생성한 코드의 컴파일 성공률은 23%에 불과하며, 요청된 결과는 전혀 생성되지 않음.
- 출력 중 약 10%는 인간이 사용할 수 있지만, 대량의 후처리가 필요함.
- Gorilla 결과를 기반으로 선택된 모델의 MLM 평균 정확도는 61%로, Roberta-base나 Tryage보다 낮음.
Tryage의 데이터 라우팅 성능
훈련 후, 프롬프트를 도메인 기반 다운스트림 전문가 모델로 라우팅하는 성능을 분석한 결과:
- Tryage는 정확히 도메인에 적합한 모델로 프롬프트를 전송:
- GitHub: 코드 모델로 78% 전송.
- DM Mathematics: C++ 모델로 98% 전송.
- USPTO 특허: 특허 모델로 98.5% 전송.
도메인별 데이터 세트 성능
Tryage는 코드, 수학, 특허 데이터 세트에서 최대 17.9%까지 성능 향상을 기록하며, RoBERTa를 능가:
- GitHub: 17.9%.
- Freelaw: 7.7%.
- Stackexchange: 6.5%.
- DM Mathematics: 10%.
- BookCorpus2: 12.3%.
- USPTO Backgrounds: 5.02%.
잠재 표현(Latent Representation) 생성
Tryage는 감독 없이 도메인 간 데이터의 잠재 표현을 생성하며, 다음과 같은 장점이 있습니다:
- 데이터 도메인(GitHub, CommonCrawl, Arxiv, StackExchange, PubMed 등) 간의 명확한 클러스터링.
- GPT-2와 비교해 더 나은 잠재 공간 분리.
- UMAP(차원 축소 시각화)을 통해 데이터 도메인 간의 구분 학습 확인.
Pareto 프론트 기반 최적화
- 제약 기반 라우팅:
- 선형 모델 크기 패널티 를 추가하여 모델 크기와 정확도 간 트레이드오프 생성.
- λ 값을 하이퍼파라미터로 설정하여 λ 범위에서 검색.
- 성능 및 계산 비용 감소:
- 정확도 5% 감소로 50% 이상 계산 비용 절약.
- λ 값 증가에 따라 대형 모델에서 점진적으로 소형 모델로 전환(Figures 5b, 5c, 5d).
결론
Tryage는 Pile 데이터 세트에서의 마스킹 언어 모델링 작업에서 기존 SOTA(SOTA) 접근 방식을 능가하며, 정확한 라우팅과 도메인 간 해석 가능한 데이터 표현 생성이 가능합니다. Pareto 프론트를 활용한 제약 기반 최적화는 사용자의 요구에 맞춘 효율적이고 비용 효과적인 라우팅을 지원합니다.
