MoE
1.Mixtral of Experts
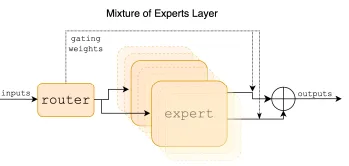
Mixtral 8x7B는 Sparse Mixture of Experts(SMoE) 모델로 이에 대한 설명. 정리 및 번역
2.Mixture of A Million Experts
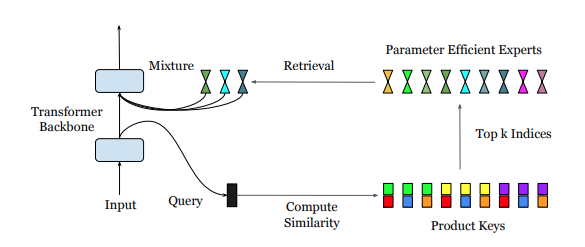
이 논문은 Google DeepMind의 연구로, 'PEER (Parameter Efficient Expert Retrieval)'이라는 새로운 레이어 구조를 제안합니다. 이에 대한 정리 및 번역
3.MoRAL: MoE Augmented LoRA for LLMs’ Lifelong Learning

이 논문에서는 대형 언어 모델(LLM)의 지속적인 학습을 효율적으로 지원하기 위해 MoRAL 방법 제안. 두 가지 핵심 기술인 MoE(전문가 혼합 구조)와 LoRA(저차원 적응)을 결합하여 LLM이 새로운 정보와 기술을 효과적으로 학습하고 기존 지식을 잊지 않도록 함
4.Mixture-of-Experts with Expert Choice Routing
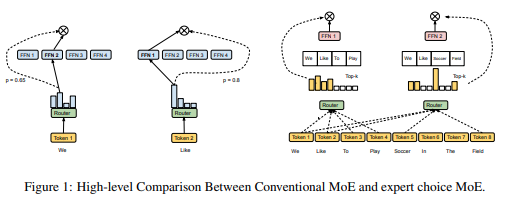
이 논문에서는 Mixture-of-Experts (MoE) 모델의 효율성을 향상시키기 위한 Expert Choice Routing이라는 새로운 라우팅 방식을 제안합니다. 정리 및 번역
5.Yuan 2.0-M32: Mixture of Experts with Attention Router
Yuan 2.0-M32는 Attention Router를 사용하여 MoE(Mixture-of-Experts) 구조에서 전문가들 간의 상관관계를 반영하여 라우팅 성능을 향상시켰습니다.
6.MoEAtt: A Deep Mixture of Experts Model using Attention-based Routing Gate
MoE(Mixture of Experts)와 어텐션 기반의 라우팅 게이트를 결합한 새로운 아키텍처인 MoEAtt를 소개.
7.OLMoE: Open Mixture-of-Experts Language Models
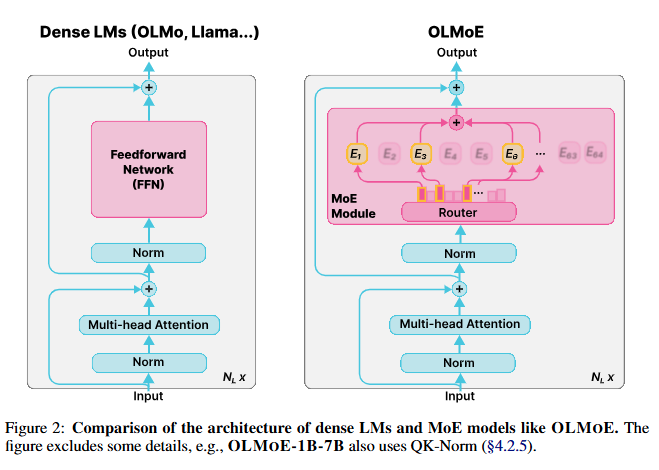
Mixture-of-Experts (MoE) 구조를 사용하는 개방형 언어 모델 OLMoE에 대한 연구를 다룹니다.
8.MONET: Mixture of Monosemantic Experts for Transformers
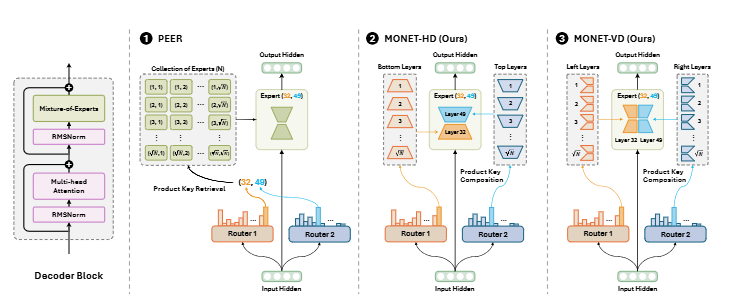
end-to-end 학습이 가능한 Mixture-of-Experts 구조를 통해 다의성을 해결하고, 각 레이어에서 파라미터를 사전적으로 지식에 따라 전담하는 전문가로 구성된 새로운 메커니즘을 도입합니다.
9.Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM
Mixture-of-Experts (MoE) 모델에 다양한 전문 모델(Experts)을 통합하여 모델의 효율성 및 성능을 향상 시키는 방법에 대해 다루고 있습니다. 이 논문의 핵심은 Branch-Train-MiX (BTM)방법론을 통해 여러 전문가 모델들을 결합하는 것
10.LLaMA-MoE: Building Mixture-of-Experts from LLaMA with Continual Pre-Training
이 논문에서는 Mixture-of-Experts (MoE) 모델을 기존의 LLaMA 모델에서 구축하는 방법을 제안한다.
11.DynMoLE: Boosting Mixture of LoRA Experts Fine-Tuning with a Hybrid Routing Mechanism
LLM의 파라미터 효율적 미세조정(PEFT)**을 위한 새로운 방법론인 DYNMOLE을 제안
12.FLEXOLMO
- 서로 **데이터를 공유하지 않고** 각자 자신만의 데이터로 전문가(Expert) 모듈을 **독립적으로 학습**할 수 있음. - 이후에는 각자가 학습한 모듈(Expert)을 **합쳐(MoE, Mixture-of-Experts 구조)** 하나의 모델로 만들 수 있음.
13.DEMIX Layers: Disentangling Domains for Modular Language Modeling
DEMIX Layers는 LLM의 Feedforward 부분을 도메인별로 분리해, 도메인에 맞는 Expert만 선택·조합·추가·제거할 수 있게 하여, 모듈성·적응성·보안성을 크게 높인 새로운 멀티도메인 LLM 구조입니다.
14.SliceMoE:Routing Embedding Slices Instead of Tokens for Fine-Grained and Balanced Transformer Scaling
토큰 단위가 아니라 연속 임베딩 슬라이스 단위 라우팅을 제안.