[논문 리뷰] EfficientViT: Memory Efficient Vision Transformer With Cascaded Group Attention
논문 리뷰

오늘은 CVPR 2023에 게재된 EfficientViT: Memory Efficient Vision Transformer With Cascaded Group Attention라는 논문에 대해 리뷰해보려고 한다.
사실 지금까지 노션에 정리를 해왔는데 노션 창에 번역보고 정리하고 하려니까 번거롭기도 하고 여기서 한번에 정리된 것만 보는게 좋을 것같아서 적는다!😊
Abstraction
최근 좋은 성능을 보이고 있는 Vision Transformer에 대해서는 많이들 알고 있을 것이다.
그러나 기존 Transformer 모델의 속도가 일반적으로 메모리 비효율적 연산으로 인해 실시간 애플리케이션에는 적합하지 않아 이와 관련된 여러 연구가 최근 활발하게 진행되고 있다.
그 중에서도 해당 논문에서는 Cascaded Group Attention module을 제시하여 계산 비용을 절약하고 Attention 다양성을 제공한다.
1. Introduction
ViT는 높은 성능으로 주목받았지만, 모델의 크기가 크고 계산 비용으로 인해 실시간 애플리케이션에 적합하지 않다.
이를 개선하기 위해 진행된 연구들은 대부분 추론 처리량을 반영하지 않은 모델 매개변수와 Flops를 줄이는 것을 목표로 수행되었다. 대표적으로 DeiT나 Swin이 있다. 이 둘은 해당 목표는 달성했지만 처리 속도 측면에서 큰 향상이 없어서 널리 채택되지 않았다.
Flops(Floating Point Operations Per Second): 초당 부동 소수점 연산 횟수를 나타내는 지표
이에 해당 논문에서는 아래의 3가지 주요 요소를 분석하여 개선한다.
- 메모리 액세스
- 기존 transformer는 메모리에 따라 속도가 크게 영향
- 계산 중복성
- 기존 transformer의 일부 attention head가 유사한 linear projections을 학습하는 경향이 있어 attention map에서 중복성 발생
- 매개변수 사용
그 결과로 해당 논문에서는 EfficientViT를 제안한다.
본문에서 구체적으로 소개할테니 간단한 구조만 보면 아래와 같다.
- Sandwich 레이아웃
- FFN 레이어 사이에 단일 메모리 바운드 MHSA 레이어 적용
- 계단식 그룹 attention(CGA) 모듈
- 중요도에 따른 매개변수 재할당을 통해 효율성 증진
이러한 구조적 변환을 통해 아래와 같은 2가지의 기여를 한다.
- vision transformers의 추론 속도에 영향을 미치는 요소에 대한 체계적인 분석을 제시
- 효율성(efficiency)과 정확성(accuracy) 사이에서 좋은 균형을 이루는 새로운 비전 트랜스포머 모델를 설계
2. Going Faster with Vision Transformers
위에서 언급했던 메모리 액세스, 계산 중복성, 매개변수 총 3가지 관점에서 접근 방법을 보여준다.
2.1 메모리 효율성
Transformer model에서 빈번한 reshaping, normalization 등의 연산은 메모리 접근에 있어서 비효율적이고 모델 속도를 저하시킨다.
기존에 이러한 문제를 해결하기 위해 제안되었던 Sparse attention이나 low-rank approximation과 같은 방법들은 정확도 저하와 제한된 가속 효과를 가져올 수 있음이 밝혀졌고, 이에 해당 논문에서는 메모리 비효율적인 작업을 수행하는 계층을 줄여 메모리 접근 비용을 절감하는 방식을 제안한다.
최근 연구에 따르면 FFN계층이 아닌 MHSA 계층에서 주로 메모리 비효율적인 작업이 수행된다고 한다.
기존 Transformer에서는 FFN 계층과 MHSA 계층을 같은 개수로 사용하여 최적의 효율을 보이지 못했다.
해당 논문에서는 MHSA 계층을 갖는 여러 작은 하위 네트워크를 생성하는 방법을 제안했다. 그 결과 MHSA 계층 비율이 20~40%인 하위 네트워크가 일반적인 ViT 모델에서 50%의 MHSA 계층을 사용하는 것보다 높은 정확도를 보였다.
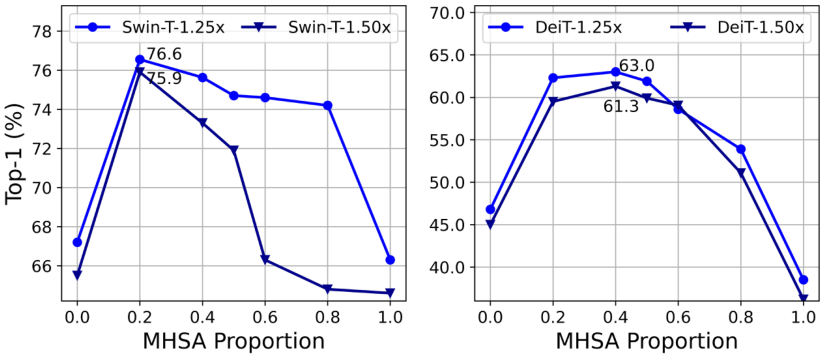
결론적으로 MHSA 계층 사용률을 적절히 줄여 모델 성능을 개선하는 동시에 메모리 효율성을 높일 수 있음을 입증하였다.⭐
2.2 계산 효율성
MHSA는 입력 시퀀스를 여러 head로 나누어 각각의 attention map을 계산한다. 그러나 attention map은 계산 비용이 많이 들고, 타 연구에 따르면 그 중 다수가 중요하지 않은 것으로 밝혀졌다.
이에 해당 논문에서는 계산 비용을 절약하기 위해 중복된 attention을 줄이는 방법을 탐구했다.
탐구 과정은 다음과 같다.
축소된 Swin-T와 Deit-T 모델을 훈련하고 각 Head와 각 block내의 나머지 head의 최대 cos 유사도를 측정한다.
그 결과는 아래와 같고,
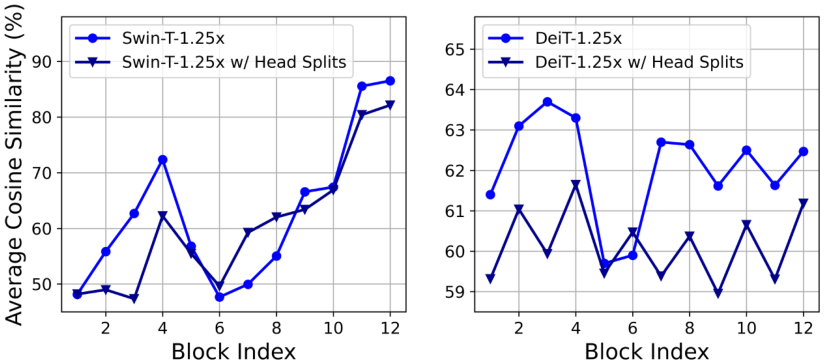
특히 마지막 블록에서 유사도가 높게 도출되었으며, 이 결과는 뒤로 갈수록 계산 중복성이 증가한다는 사실을 입증한다.
이에 해당 논문에서는 계산 중복성을 줄이기 위해 각 헤드가 처리하는 정보의 일부를 다르게 하여 효율성을 높이는 방법을 제안⭐하였다.
2.3 매개변수 효율성
전형적인 ViT는 NLP Transformer의 구조를 대부분 그대로 가져와서, 가벼운 모델에서 비효율적일 수 있다. NLP Transformer의 경우 대규모 데이터셋을 기준으로 설계되었기 때문에 구조를 그대로 가져오게 된다면 채널 수, 헤드 수가 비효율적으로 증가하게 될 수 있고, FFN의 확장 비율도 NLP에서는 4로 설정되는데 그렇게 되면 내부적으로 많은 수의 뉴런이 필요하게 된다고 한다.
작은 모델에서는 이러한 큰 확장 비율이나 채널수, 헤드 수가 오히려 메모리/계산 자원 낭비로 이어질 수 있다.
따라서 해당 논문에서는 Taylor의 구조적 가지치기를 채택하였다.
가지치기는 특정 resource 제약 하에서 중요하지 않은 채널을 제거하고 가장 중요한 채널을 유지하여 정확도를 보존할 수 있게 해준다.
아래 표는 가지치기 하기 전후에 남은 출력채널과 입력채널의 비율이 표시되어 있다.
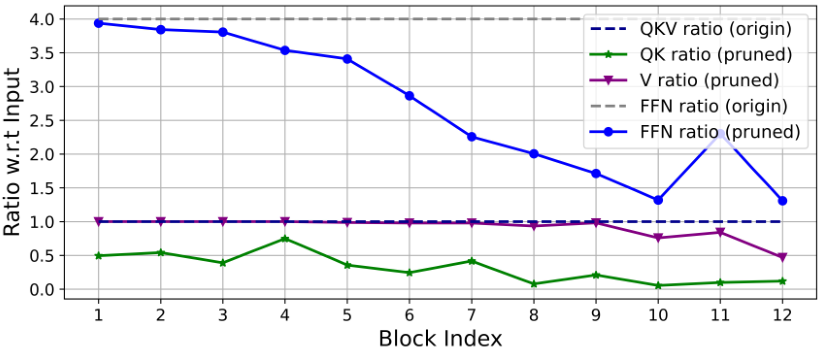
이 표를 분석해보면 다음과 같은 정보를 얻을 수 있다.
- 마지막 단계에서는 차원이 훨씬 적게 보존된다.
- Q, K, FFN의 차원이 크게 다듬어지는 반면 V 차원은 거의 보존되고 마지막 몇 블록에서만 감소한다.
이러한 정보를 통해 또 아래와 같은 정보를 얻을 수 있다.
1. 일반적인 채널 구성은 마지막 몇 블록에서 상당한 중복성을 생성한다.
2. 차원이 같을 때, Q, K의 중복성은 V보다 훨씬 크다.
[용어 정리]
MHSA(Multi-Head Self-Attention): 여러 개의 self-attention을 동시에 수행하는 것을 의미
FFN(Feed-Forward Network): 데이터가 입력에서 출력으로 이동하는 동안 여러 단계의 계산을 수행하는 네트워크
3. Efficient Vision Transformer
새로운 Vision Transformer 모델 Efficient ViT를 소개한다.
크게 아래의 3가지 전략을 제안했다.
- Memory-Efficient Sandwich layout
- Cascaded group attention module
- Parameter reallocation strategy
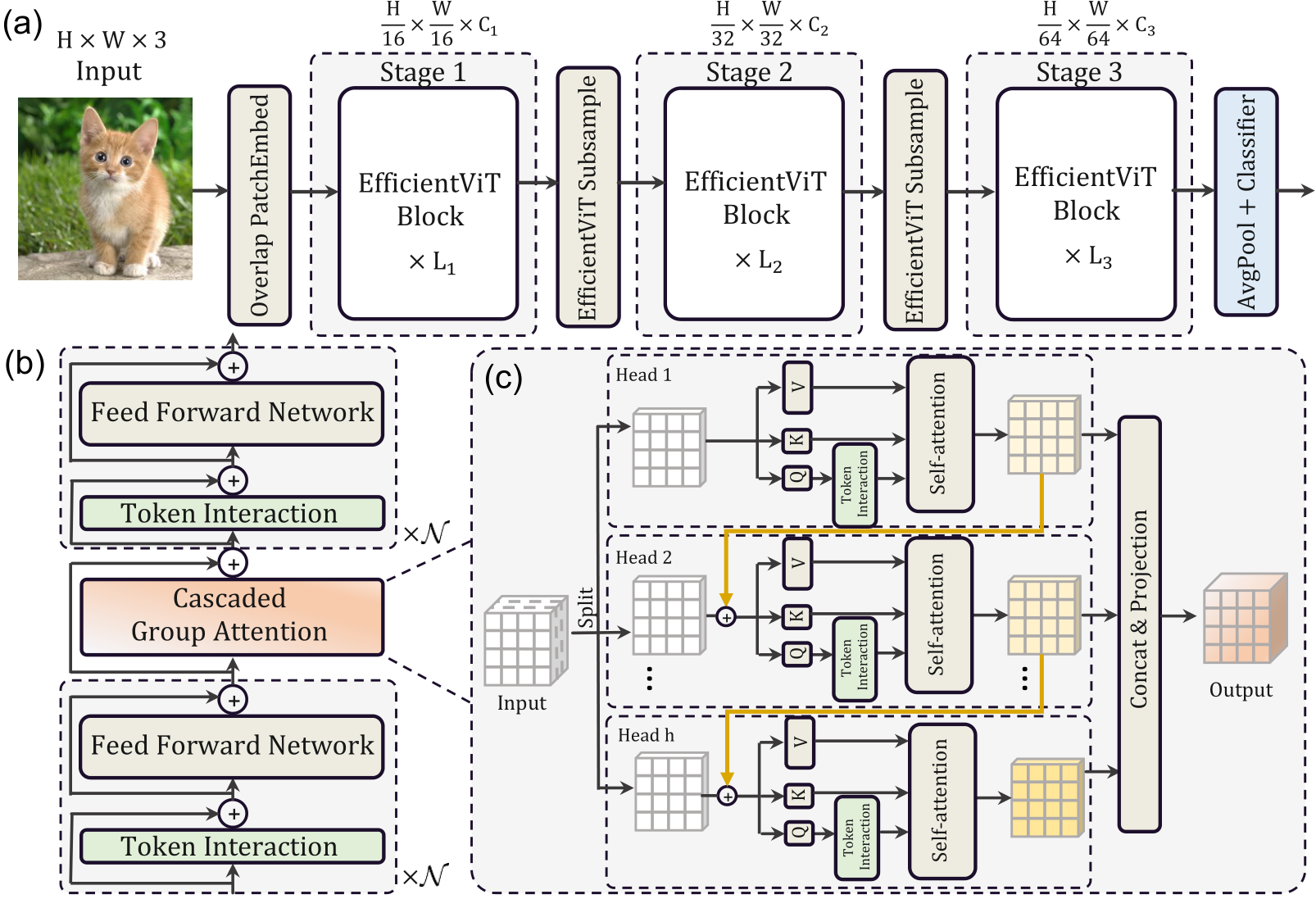
3.1 EfficientViT Building Blocks
Sandwich Layout⭐
기존에 ViT의 메모리 사용량을 개선하고자 도입된 개념이다.
해당 방법은 Self-attention layer를 덜 사용하고 메모리 효율적인 FFN 레이어를 더 사용한다.
구체적으로는 FFN 레이어 여러 개 사이에 Self-attention layer를 1개만 사용한다.
이러한 디자인은 모델의 self-attention 계층으로 인해 발생하는 메모리 소모를 줄이고 더 많은 FFN 계층을 적용하여 서로 다른 기능 채널 간의 효율적인 통신을 허용한다.
Cascaded Group Attention⭐
기존의 Multi-head self-attention(MHSA)방식은 많은 계산을 필요로 하고, 비효율적일 수 있다.
이에 도입된 개념이 계단식 그룹 어텐션이다.
이 모듈은 입력 특성을 여러 개의 그룹으로 나누어 각 그룹에 대해 self-attention을 수행한다.
이 과정이 논문상에서 수학공식으로 엄첨 나와있는데,,,
사실 이건 해석을 못하겠다ㅠㅋㅋ😅
결론적으로 얻을 수 있는 이점은 아래와 같았다.
-
각 head에 다른 기능 분할을 공급하면 Attention map의 다양성을 개선할 수 있다. (2.2 참고)
-
Attention head를 계단식으로 배치하면 네트워크 깊이를 늘릴 수 있으므로 추가 매개변수를 도입하지 않고 모델 용량을 더욱 높일 수 있다.
Parameter Reallocation⭐
2.3에서 일반적인 채널 구성에서 마지막 블록들에 중복성이 주로 발견되고, 차원이 같은 경우에 대해 Q,K의 중복성이 V에 비해 크게 발생하는 것을 발견하였다.
이러한 연구 결과들에 의해 각 헤드의 Q, K를 작은 채널 차원으로 설정하였고 V는 입력 임베딩과 동일한 차원을 갖도록 하였다.
또한 FFN의 확장 비율도 줄여주었다.
(가지치기했을 때 FFN의 비율이 크게 다듬어지는 것을 2.3의 표에서 확인했기 때문)
이러한 전략을 통해서 중요 모듈이 고차원 공간에서 학습할 수 있는 채널 수가 더 많아져 Feature 정보 손실을 방지할 수 있고,
중요하지 않은 모듈의 중복적인 매개변수는 제거하여 추론 속도를 높이고 모델 효율성을 높일 수 있다.
3.2 EfficientViT Network Architectures
EfficientViT이 주요 구조에 대해서만 요약해보자.
- 16x16 패치 임베딩을 사용하여 저수준 시각적 표현 학습
- BatchNorm대신 LayerNorm을 사용
- 6가지 폭과 깊이 스케일로 모델 패밀리 구축하여 후기로 갈수록 더 작은 폭으로 확장하여 모델의 중복성 완화
4. Experiments
여기서부터는 저자가 실험해본 결과를 정리한 것이다.
4.1 Implementation Details
실험의 조건
- 총 배치 크기 2048
- 입력 이미지 크기 224x224
- 초기 학습률 0.001
- 가중치 감쇠 0.025
4.2 Results on ImageNet
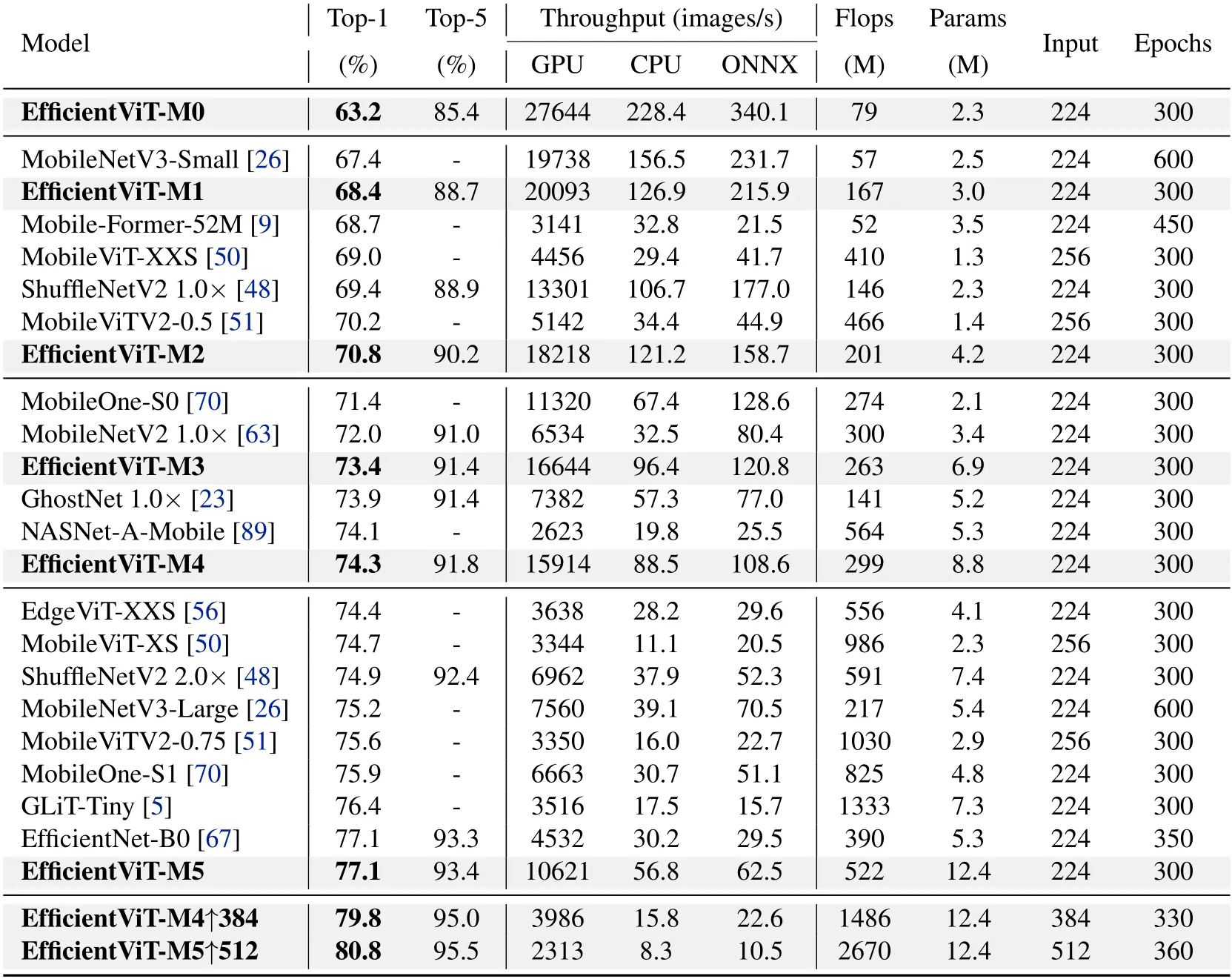
Comparisons with efficient CNNs(MobileNet, EfficientNet)😯
- 일반적으로 EfficientViT가 더 높고 더 빠른 속도로 실행된다.
- 가장 최신의 MobileNetV3-Large와 비교할 때 GPU, CPU상에서는 EfficientViT-M5가 더 높은 정확도와 속도를 보이지만, ONNX 모델에서는 11.5% 느리다.
ONNX 구현 시에 reshaping이 느려지는 것과 관련이 있을 수 있으며, self attention 계산에서 불가피하다.
ONNX: 다양한 딥러닝 프레임워크 간에 모델을 쉽게 변환하고 공유할 수 있게 하는 오픈 소스 포맷
=> 결론적으로 보았을 때, EfficientViT가 더 많은 매개변수를 사용하지만, 추론 속도에 영향을 미치는 메모리 비효율적인 연산을 줄이며 더 높은 처리량을 달성한다.
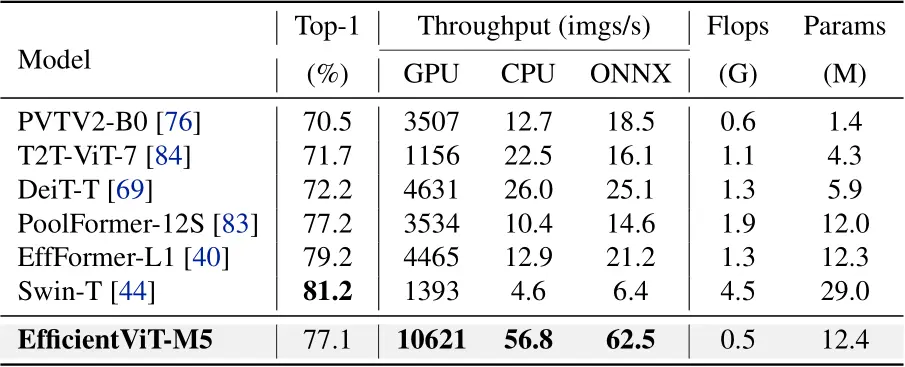
Comparisons with efficient ViTs(MobileViT, EfficientViT)😯
- MobileViTV2와 비교했을 때, 같은 GPU, CPU 상에서 3.4/3.5배 높은 처리량을 보인다.
- Swinf-T와 비교했을 때, Efficient-ViT-M5가 정확도는 더 낮지만, CPU상에서 12.3배나 더 빠르다.
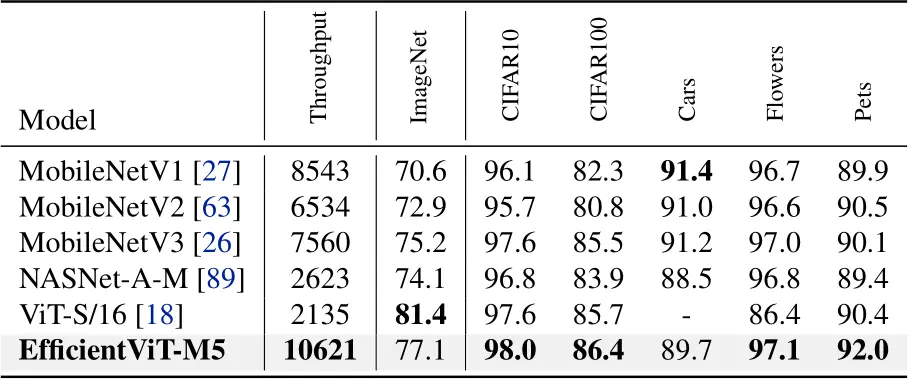
Finetune with higher resolutions😯
해당 연구에서 개발한 가장 큰 모델인 EfficientViT-M5를 더 높은 해상도로 미세 조정하였다.
해당 모델은 EfficientViT-M5 384와 512로 각각 79.8%, 80.8%의 정확도를 보인다.
4.3 Transfer Learning Results
전이 능력 평가를 위해 다양한 다운 스트림에 적용해본 결과이다.
CIFAR-10, CIFAR-100 등의 이미지 분류 데이터셋에 적용하여 일반화 능력을 테스트했다.
아래의 표에서 보이 듯이 EfficientViT가 다른 모델에 비해 유사하거나 더 나은 정확도를 달성한 것을 확인할 수 있다.
(Car 데이터셋 제외)
4.4 Ablation Study
EfficientViT에서 중요한 설계 요소들을 ImageNet에서 제거하여 평가해보는 과정이다.
결과만 보면 아래와 같다.
- 샌드위치 레이아웃 블록 -> Swin 블록
-> Top-1 정확도 3.0% 감소 - 계단식 그룹 attention(CGA) -> MHSA
-> 정확도 1.1% 감소, ONNX 속도 5.9% 감소 - QKV 채널 차원 재배치+FFN 비율 축소 한 모델 vs 안 한 모델
-> 한 모델이 더 높은 정확도와 처리량을 보여주었다. - 다른 구성 요소
- DWConv 사용, 정규화 레이어 LN, 활성화 함수 ReLU
5. Related Work
CNN들은 합성곱 커널을 적용하였는데, 이는 공간적 지역성이라는 성질로 인해 장거리 의존성을 포착하는 데에 한계가 있었다.
반면에 최근 성공을 거둔 ViT는 성능은 CNN에 비해 우수함에도 불구하고, 추론 속도에서 매우 뒤져쳤다.
이를 개선하기 위해 다양한 접근(efficient self-attnetion, efficient architectue design) 방식이 제안되었는데, 대부분은 Flops와 파라미터를 최소화하는데에 국한되었다.
이 결과로 실제 추론 지연과 낮은 상관 관계를 갖게 되며, 속도 면에서 여전히 CNN보다 뒤쳐진다.
해당 논문에서는 다양한 하드웨어 및 배포 설정에서 처리량을 직접 최적화하여 빠른 추론이 가능한 모델을 탐구하고, 속도와 정확성 간의 좋은 균형을 가진 계층적 모델들을 설계하였다.
6. Conclusion
해당 논문에서는 ViT의 추론 속도에 영향을 미치는 요인들에 대한 분석을 제시하고, 메모리 효율적인 연산과 계단식 그룹 어텐션을 갖춘 새로운 빠른 ViT 계열의 Efficient ViT를 제안하였다.
여러 실험 결과를 통해 메모리 대비 효율성과 높은 처리 속도를 입증하였다.
그러나 이 모델의 한계는 높은 추론 속도에도 불구하고 도입된 샌드위치 레이아웃의 추가 FFN들로 인해 모델 크기가 최첨단 효율적인 CNN에 비해 약간 더 크다는 것이다.
향후 연구에서 모델의 크기를 줄이고 자동 검색 기술을 통합하여 모델 용량과 효율성을 향상시킬 것이라고 한다.
느낀점🤔❓
해당 논문에서는 기존 ViT의 문제점을 제시하였다.
기존에 ViT의 크기가 크고 속도가 느리다는 문제점을 인지하고 있었으나, 그 원인을 어느 정도 구체화할 수 있었던 것같다. 기존 ViT의 MHSA 계층에서 비효율적인 작업이 주로 이루어진다는 점, 중복 Attention을 줄이기 위해 Cosine similarities를 계산하여 제거하여 효율성을 높일 수 있다는 점, Taylor의 구조적 가지치기를 통해 FFN, Q, K의 중복성이 V에 비해 훨씬 크다는 점을 알게 되었다.
이러한 문제점들을 직접 제시해주고 개선한 Efficient ViT 자체에 대해서도 알 수 있어 좋았지만, 최근 논문들을 볼 때 ViT 모델 자체를 최적화하고 경량화하는 내용이 많아 이 부분은 직접 사용해보아야 체감이 가능할 것같다.
