
오늘은 ICIP 2023에 Accept된 논문 Machine-Attention-based Video Coding for Machines을 리뷰해보려 한다!
VCM관련 논문 찾다가 ICIP에서 발견한건데 VCM 관련해서 ICIP와 VCIP에 다양한 논문들이 많이 게재되어 있으니까 관심있는 사람들에게 강추한다!👍
-CVPR에서 찾다가 잘 안나와서 고생했던 사람🫠🫠🫠-
Abstract
최근에 video가 인터넷 트래픽의 많은 부분을 차지하고 있다.
또한 neural network의 발전으로 기계가 처리하는 비디오 데이터의 양도 함께 급증하고 있다.
이에 해당 논문에서는 machine-attention-based video coding 방법을 제안한다.
큰 로직은 아래와 같다.
- 객체 탐지 네트워크에서 machine vision 성능에 민감하게 영향을 미치는 attention regions를 추출한다.
- 이후 MAP(Maximum-A-Posterior)기반 비트 할당 방법을 적용하여 attention regions에 더 많은 비트를 할당해준다.
이 방법은 bitrate를 줄이면서도 높은 machine vision 성능을 유지할 수 있게 해준다.
MAP(Maximum A Posterior): 주어진 데이터와 사전 지식을 바탕으로 가장 가능성이 높은 매개변수 값을 찾는 통계적 추정 방법; 영상 압축에서는 MAP를 사용하여 attention regions에 더 많은 비트를 할당함으로써 압축 효율을 높인다.
1. Introduction
Abstract에서 언급했듯이 5G의 발전과 무인 감시 시스템과 같은 비디오 기반의 서비스로 인해 비디오 데이터가 차지하는 비율이 매우 커지고 있다.
또한, 딥러닝 기반 응용 분야(객체 감지, 분할, 추적)의 확장으로 인해 많은 비디오 데이터가 분석을 위해 신경망에 의해 소비되고 있다.
이 두가지가 요구하는 바가 다르다.
데이터를 저장하는 곳은 저장하는 데이터의 크기를 줄이길 바랄 것이고,
시스템에서는 높은 Accuracy를 요구할 것이다.
이러한 요구사항을 만족할 효율적인 비디오 코딩 방법을 해당 논문에서 제시한다.
논문에서는 아래와 같은 문장을 사용하여 목표를 정의하였다.
VCM의 주요 목표는 효율적인 비디오 및 특징 압축 기술을 표준화하여, 더 작은 데이터 크기로 기계 비전 작업을 효율적이고 정확하게 수행할 수 있는 능력을 갖추는 것입니다.
Abstract에서 제안한 방법에 대해 한 번 더 구체적으로 언급한다.
-
Faster R-CNN의 지역 제안 네트워크(RPN)을 기반으로 기계 비전 성능에 민감하게 영향을 주는 Attention regions를 추출하여 Machine Vision 성능 유지를 돕는다.
-
그 후 MAP(최대 사후 확률) 기반 bit allocation 방법을 적용하여 attention이 높은 영역에 더 많은 비트를 할당한다.
2. Related Works
전통적인 Video Codec에서는 특정 양자화 매개변수(QP)에서 최상의 품질을 제공하도록 RDO(Rate-Distortion Opimization)를 통해 전체 비디오 영역을 최적화한다.
그러나 이 방법은 HVS 즉 인간 시각 시스템의 특성을 고려하지 못할 수 있다.
이에 제안된 방식이 Saliency-driven coding 기술이다.
-
전통적인 관심 영역(ROI)추출 방법 또는 Neural network을 사용하여 Saliency areas를 추출한다.
-
압축 과정에서 코딩 트리 유닛(CTU) 또는 코딩 유닛(CU) 내의 각 주목도 영역에 서로 다른 비트를 할당한다.
이러한 방식은 전통적인 Video Codec에 비해 HVS에 적합하다.
이와 같이 Machine vision task에 대해 관심이 커짐에 따라 Image coding methods for machine이 연구되었다.
대부분의 응용프로그램이 video 데이터를 요구하지만, 이전까지는 주로 이미지 압축 결과를 주로 보였다.
이에 해당 논문에서는 단순이 이미지 데이터셋 뿐만 아니라, 비디오 데이터셋에 대한 압축도 수행하였다.
3. Proposed Methods
이제 제안한 네트워크에 대해서 구체적으로 알아보자.
크게 아래와 같은 두 부분으로 구성된다.
- Machine-Attention Region Extraction⭐
- MAP 기반 QP 할당⭐
3.1 Machine-Attention Region Extraction
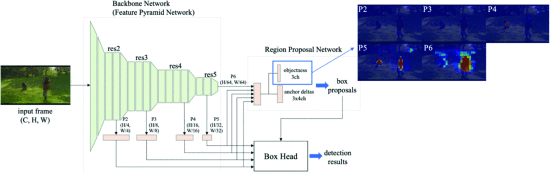
우선 해당 논문에서는 Faster R-CNN 중 하나인 RPN을 채택하여 Machine-Attention Regions을 추출하였다.
RPN(Region Proposal Netwrok)는 고품질의 regions proposal을 생성하고 네트워크가 주목해야 할 위치를 알려주는 attention 메커니즘을 사용한다.
또한 여기서 사용되는 FPN(Feature Pyramid Network)라는 것은 조금 더 아래의 사진을 보면 알겠지만 피라미드 형태의 네트워크로 다양한 크기의 객체를 인식하면서도 더 적은 컴퓨팅 자원을 소모한다.
글로 설명이 되게 많은데 내가 종이에 쉽게(?) 그려놨다.

비디오 V
프레임 N개
I 번째 프레임 VI
k번째 프레임에 r개 이상의 객체가 있다고 할 때 r번째 예측된 경계 상자는 Akr, obj로 표현
그림 2의 Objectness map에서 객체 탐지를 위한 후보는 Akr, obn로 표현
FPN은 각 P레이어에서 다양한 수용 영역을 가진 Multi-scale의 featuer maps를 추출한다.
최종적으로 각 프레임 VK들은 Faster R-CNN에 입력되어 Attention Regions가 추출되고, r번째 프레임 k의 machine-attention region은 다음과 같이 표현된다.
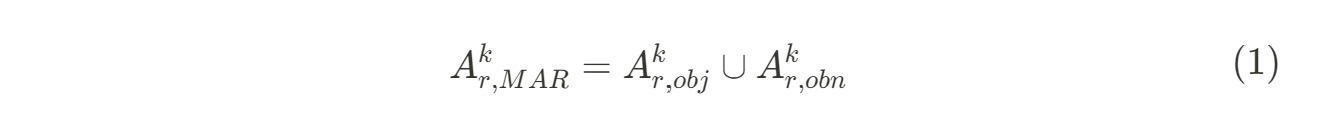
전체적인 네트워크의 구조는 아래와 같다.
이는 특정 프레임의 MAR을 뽑아내는 과정이었는데,
비디오 데이터의 특성상 객체가 순간이동을 하지 않는 이상 현재 프레임의 객체가 다음 프레임에서 유사한 위치에 있을 가능성이 매우 높다.
따라서 같은 객체에 대한 시간적 일관성을 유지하기 위해 같은 객체를 GOP(Group of Picture)단위로 묶어 최종 attention region을 얻는다.
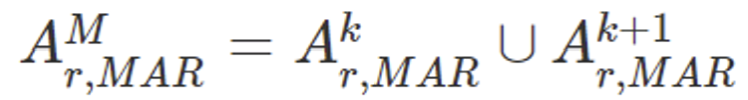
현재 프레임과 다음 프레임의 객체 ID가 같고 IoU가 0.5를 초과하면, 두 attention region은 아래와 같이 결합된다.
이때 M은 GOP단위를 나타낸다.
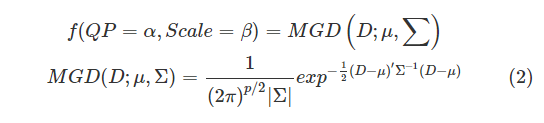
3.2 MAP-based Bit Allocation
제안된 bit allocation 단계는 Object detection network와 Compression 간의 관계를 기반으로 한다.
해당 논문에서는 탐지 성능이 3가지 매개변수 D=(area, confidence, overlap)에 따라 Scale과 QP(Quantization Parameter)가 어떻게 변하는지 조사하였다.
각 매개변수에 대한 설명은 아래와 같다.
- area: 객체의 바운딩 박스 영역의 크기/전체 이미지 크기
- overlap: 객체의 겹친 영역의 크기/목표 객체 영역
- confidence: 신뢰도
이에 대해 MGD(Multivariate Gaussian Distribution)은 아래와 같이 선언된다.
D, QP, Scale 사이의 관계가 MGD를 따르지 않을 수도 있지만, 실제 확률 분포를 얻기 어렵고 일반 통계에서 수집된 데이터의 분포를 근사하는 데 자주 사용된다.
따라서, 신뢰도 점수(Confidence score), 겹침(overlap), 앞 장의 Machine-attention Extraction에서 얻은 AMr, obj를 얻을 후, 각 객체는 가장 높은 확률 밀도를 가진 MGD를 사용하여 QP와 Scale에 맞춰 압축한다.
예를 들어, QP가 32, Scale이 75%인 경우, 이는 객체 크기가 원래 크기의 75%로 줄어들어도 QP 32에서 충분히 감지될 수 있음을 의미한다.
3.3 Frame Recomposition
저자들은 더 높은 압축 효율을 위해 여러 Recomposition을 시도하였다.
먼저 이미지의 중요한 attention area와 background area를 분리하여 background area를 원본보다 25%작게 줄인다.
줄인 background area를 원본 이미지의 왼쪽 하단 모서리 외부에 붙인 후, 전체 이미지를 압축한다.
여기까지의 과정이 아래의 그림에서 나오는 Encoding Video Construction 부분이다.
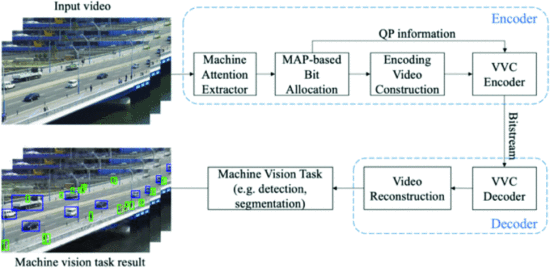
다시 원본이미지로 복구할 때도 마찬가지로, 압축이 해제된 두 부분을 사용하여 원본 이미지를 재구성하는 추가 과정을 거친다.
전체적으로 보았을 때, 중요한 부분의 정보는 데이터를 잘 보존하고, 덜 중요한 배경은 압축률을 높이기 위해 줄인다는 점을 알 수 있다.
(Codec의 핵심!✨)
4. Experimental Result
4.1 Experimental Setup
- Video
- SFU Video Dataset
- GT 포함
- 17개의 비디오 시퀀스와 5개의 클래스
- Faster R-CNN X101-FPN
- 6개의 QP: 22, 27, 32, 37, 42, 47
- 평가 지표: mAP@[0.5:0.95]
- Image
- TVD-image Dataset
- GT 포함
- 1920x1080 이미지 166개
- Faster R-CNN X101-FPN과 Mask R-CNN X101-FPN
- 6개의 QP: 22, 27, 32, 37, 42, 47
- 평가 지표: mAP@[0.5]
4.2 Compression Results on the Video Datset
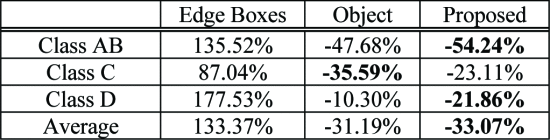
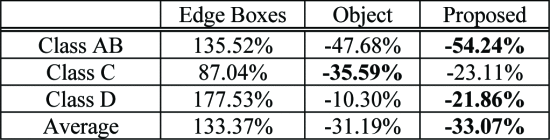
아래의 표에서 3가지의 서로 다른 region proposal method를 사용한 압축 결과를 보여준다.
Edge boxes는 전통적인 object proposal algorithm으로 경계선 즉 edge로부터 직접 분류되지 않은 object-bounding box proposal을 생성한다.
다음은 Object라고 적혀있는데 이것은 예측된 Object detection result를 Attention regions로 사용하는 방법이다.
Edge Boxes방법은 edge 정보를 기반으로 분류되지 않은 객체까지 탐지할 수 있지만, region proposal의 부정확성으로 machine vision performance가 크게 감소해서 BD-rate가 133%를 넘는다.
Object 방식 즉 객체 정보를 사용할 경우 BD-rate가 -31.19%로 나타나며, 이는 높은 압축 효율성을 보인다.
그러나 해당 논문에서 제안한 방식(Proposed)은 BD-rate가 평균적으로 보았을 때 -33.07%로 가장 높은 압축 효율성을 보이는 것을 확인할 수 있다.
이 표를 통해 해당 논문에서 제안한 machine-attention extraction method가 object detection 성능을 유지하면서도 신경망의 reception field를 효율적으로 수용함을 보여준다.
BD-rate(Bjontegaard Delta Rate): 한 압축 기술이 다른 기술에 비해 얼마나 더 적은 비트로 동일한 품질을 유지할 수 있는지 나타내는 것.
만약 BD-rate가 -20%라면 해당 방법이 다른 방법보다 약 20% 더 적은 데이터로 동일한 영상 품질을 유지할 수 있다는 뜻.
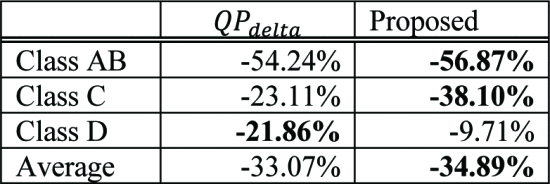
다음으로는 QPdealta값으로 비교하였다.
QP delta는 attention regions과 다른 region에 대해 delta 크기에 따라 QP값을 다르게 할당하는 간단한 방법이다.
여기서는 QPdelta값을 10으로 주고 수행하였으며, 제안된 방법은 QPdelta와 비교하였을 때, 평균 1.82%의 BD-rate 감소를 보여준다.
특히 해상도가 높은 A, B, C 클래스에서 큰 성능 개선을 보였다.
4.3 Compression Results on the Image Dataset
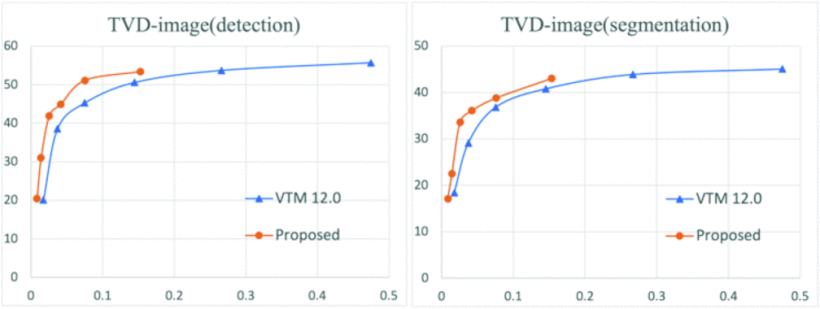
다음으로는 이미지 데이터셋에서의 실험 결과이다.
아래 표의 x축은 bpp, y축은 mAP값을 의미한다.
즉 우리가 주로 확인할 수 있는 R-D 그래프와 비슷한 의미를 가지는 그래프인 것같다!
이 결과를 통해 제안된 방법(주황)이 VTM12.0(파랑)과 비교하여 동일한 mAP에서 더 낮은 BPP값을 가지고 있음을 확인할 수 있다.
객체 탐지(Detection)에서는 BD-rate가 -44.70%, 객체 분할(Segmentation)에서는 -397%로 나타나 제안된 방법이 VVC앵커와 비교하여 더 뛰어난 성능을 보이는 것을 확인할 수 있다.
5. Conclusion
해당 논문에서는 새로운 machine-attention based video coding method를 제안한다.
간략하게 정리하면 추출된 attention regions를 통해서 각각 다른 QP를 할당해줌으로써 machine vision task의 performance를 유지하면서도 압축 성능을 크게 개선하는 것을 보여주었다.
뿐만 아니라, 해당 method는 비디오 데이터뿐만 아니라 이미지 데이터에서도 우수한 성능을 보이는 것을 확인할 수 있었다.
해당 논문은 QP값 즉 Quantization Parameter값을 주요 매개변수로 선정하여 압축 성능을 향상시키고, Machine Vision Task를 수행하는 VCM의 정석적인 논문인 것같다.
내가 연구하고 있는 주제랑 매우 유사하여서 더 흥미가 갔다.
근데 최근 2024년도 IEEE에서 publish된 Adaptive Image Downscaling for Rate-Accuracy-Latency Optimization of Task-Target Image Compression 논문에서 QP값으로만 데이터 압축을 하였을 때의 데이터 전송 시간같은 Latency까지 추가하여 Latency-Rate-Accuracy 3가지 trade-off를 모두 고려하였을 때 크게 기여하지 못한다는 점이 또 언급되었었다.
그래서 해당 논문에서 언급했듯이 자율주행, 무인 감시 카메라와 같은 실시간으로 처리해야 하는 프로그램의 경우 Latency, Vision Task Accuracy, Compression 이 3가지 요소를 모두 고려해주어서 개선된 연구가 추가적으로 더 진행되면 좋을 것같다는 생각이 들었다!
