
오늘은 VCIP 2023 논문 Low-complexity Transform Network Architecture for JPEG AI Image Codec을 리뷰해보려 한다!
이번에도 VCM 세미나 준비를 하면서 찾게 된 논문이다!
해당 논문의 일부 방법들은 JPEG AI 검증 모델 소프트웨어에 통합되어 사용되고 있다고 하니 꼼꼼히 읽어보도록 하겠다!😊
Abstract
JPEG AI와 같은 Learning-based image coding방식에서 기존 이미지 압축을 R-D성능 측면에서 크게 끌어올리고 있다.
그러나 이러한 방식들은 고해상도 Decoding complexity 특히 upsampling 및 attention 모듈로 인한 문제로 제한된다.
이에 해당 논문에서는 최적화된 attention 모듈, 간소화된 upsampling 모듈, 축소된 activateion function을 사용하는 단순화된 변환 네트워크 아키텍처를 제시한다.
I. Introduction
기존 JPEG AI 검증 모델(JPEG AI VM)의 주요 문제 중 하나는 Decoder의 변환 네트워크에서 나타나는 높은 복잡성이다.
이에 해당 논문에서는 Transformer Network에 대한 3가지 단순화를 제안한다.
- 수정된 Attention 모듈: 계층적 아키텍처를 갖춘 transformer-based upsampling 모듈 도입
- 새로운 upsampling 모듈: upsampling 방식으로 1x1 convolution을 선행하는 Pixel Shuffle 연산을 사용하는 것을 제안
- 간소화된 Activation function: hyperbolic tangent, subsequent 원소별 연산 생략
II. Revisit JPEG AI Transform Network
해당 섹션에서는 현재 JPEG AI 변환 네트워크를 소개한다.
아래 그림이 JPEG AI 변환 네트워크의 구조이다.
살펴보면 시작 부분에 2개의 잔여 블록(Residual Block(RB))가 있고, 출력 해상도를 높이기 위해 Upsampling stride 2를 가진 4개의 convolution이 연속으로 배치되어 있다.
활성화 함수로는 Residual Attention Unit(ResAU)를 사용하고, 비선형 표현 능력을 향상시키기 위해 Attention 모듈로서 Non-local Attention Module(RNAB)를 사용한다.
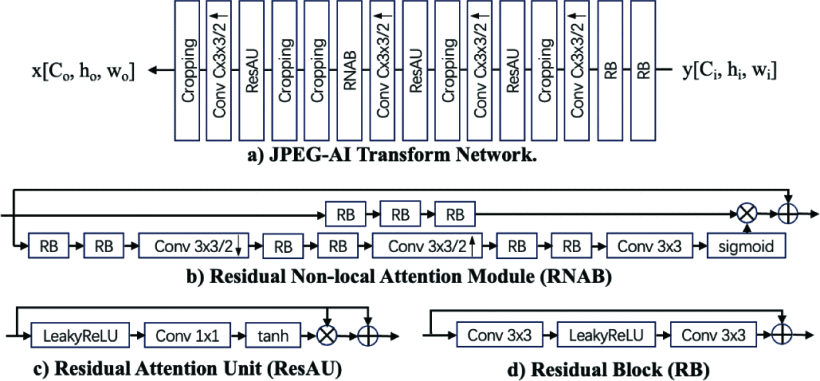
해당 논문에서는 특히 Decoder 부분에 초점을 맞춘다. 이 Decoder의 문제점은 복잡성이다. JPEG AI 는 뛰어난 성능을 가지고 있지만, 디코너 측에 집중적인 계산 복잡성을 가지고 온다. 구체적으로 모든 구성 요소 중에서 RNAB와 Upsampling 모듈이 전체 복잡성의 95%를 차지한다.
이에 해당 논문에서는 이 2가지를 대체하기 위한 Low-complexity transformer-based attention 모듈과 shuffle-based up-sampling module을 설계하였다.
III. Proposed Low-complexity Decoding Transform Network
A. Transformer-based Attention Module
해당 논문에서는 아래의 2가지 방식을 채택하였다
- 성능 유지를 위해 전역 정보를 포착하는 Transformer-based Attention Module
- 낮은 복잡성을 달성하기 위해 Hierarchical Attention Architecture
Transformer는 전역 정보를 포착할 수 있지만 메모리 사용량이 매우 크고, 특히 고해상도 이미지에서는 더 심한 것을 확인할 수 있다.
이러한 문제를 해결하기 위해 논문에서는 Restormer block이라는 모듈을 제안하였다.⭐
Restormer block은 공간 차원 대신 채널 차원에서 self-attention을 적용하여, key-query dot-product의 시간 및 메모리 복잡성이 입력의 공간 해상도에 따라 선형적으로 증가한다.
이 말이 나한텐 좀 어렵게 느껴졌는데,
기존의 self-attention은 이미지의 공간적 차원, 즉 각 픽셀들 간의 관계를 학습했었다.
여기서 채널 차원에서 self-attention을 적용한다는 것은 feature map의 서로 다른 채널 간의 관계를 학습할 수 있다는 의미이다.
예를 들어서 쉽게 설명을 해보자면(feat.ChatGPT)
파란 하늘 위에 빨간 풍선이 떠있는 이미지가 있다고 할 때,
공간 차원에서 self-attention을 수행하면 모든 픽셀과 하늘의 모든 픽셀 간의 관계를 살펴보면서 풍선과 하늘이 어디에 위치해 있는지 이해하려고 할 것이다.
반면에 채널 차원에서 self-attention을 수행하면 각각의 픽셀에서 빨간색과 파란색의 강도간의 관계를 이해하려고 할 것이다. 이를 통해 풍선이 하늘과 어떻게 대비되는지 이해할 수 있을 것이다.
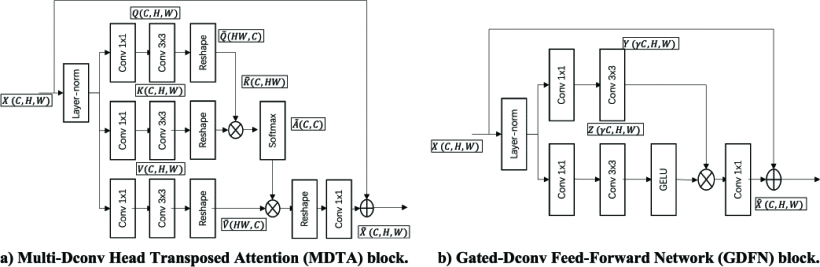
Multi-Dconv Head Transposed Attention(MDTA) Block
MDTA Block은 전역 attention map을 생성하는 데 사용된다.
해당 블록의 형태는 위의 그림에서 확인할 수 있다.
실행 순서를 살펴보면 아래와 같다.
- Global Attention Map 생성: 이미지의 전체적인 정보 한 눈에 파악
- Layer 정규화: 데이터 정돈
- Query, Key, Value 생성
3.1 1x1 Convolution: 채널 간의 상호작용을 도움
3.2 2x2 Convolution: 이미지 내에서 더 복잡한 패턴을 인식 - 채널별 공간 Context 인코딩: 각각의 색상 채널에서 공간적으로 어떤 정보가 중요한지 파악
- Transposed-Attention Map 생성: Query와 Key의 dot-product(유사도) 계산
Gated-Dconv Feed-Forward Network(GDFN) Block
GDFN Block은 특성 채널을 확장하여 입력 차원과 동일하게 만든다.
주요 작업은 아래와 같다.
- Channel-splitting: 세 번째 convolution 이후, 출력을 channel 단위로 두 부분으로 나누고, 이를 각각 2개의 Restormer 블록에 전달
- Spatial-down-sampling: 출력이 ℝ^(C×H×W)형태라면 transformer 블록에 전달하기 전에 X를 downscaling하여 중간 출력의 크기가 C×(H/2)×(W/2)가 되도록 한다. 그 후 출력에 upscaling하여 해상도를 유지한다.
B. Low-complexity Upsampling Module
해당 논문에서는 Pixel Shuffle이라는 연산을 사용하였다.
Pixel Shuffle: 이미지를 upscaling할 때 사용하는 기술로, 주어진 입력 데이터가 있을 때, 이 연산을 통해 이미지의 해상도는 키우면서 깊이(채널)를 줄일 수 있게 해준다.
즉 이미지의 해상도는 키우면서 계산 복잡도를 줄일 수 있다.
채널이 C = n ∗ r²이고 해상도가 H x W인 경우,
채널은 C = n, 해상도를 rH x rW인 새로운 Feature map을 형성한다.
이와 같이 Pixel Shuffle 연산은 본질적으로 텐서의 요소를 재배열하여 텐서의 공간 해상도(높이와 너비)가 증가하는 반면, 깊이(채널 수)는 감소하도록 한다.
C. Low-complexity Activation Function Module
기존의 활성화 함수 ResAU(Residual Attention Unit) 내부에는 LeakyReLU, 1x1 convolution layer, tanh 함수 등 여러 하위 모듈로 구성되어 있다.
여기서는 tanh와 요소별 연산을 제거하여 복잡성을 줄였다.
IV. Evaluation Results
A. Setups
아래의 2가지를 중심으로 평가하였으니 참고하자!
BD-rate(Bjøntegaard Delta-Rate): 압축 비율(bit rate)과 품질(PSNR, SSIM) 사이의 관계를 정량적으로 표현하는 방법; 낮을 수록 동일한 품질을 유지하면서도 더 낮은 bit rate를 사용한다는 것을 의미한다. 즉 낮을 수록 압축 효율성이 좋은 것
kMACs/pixel (Thousand Multiply-Accumulate Operations per Pixel): 이미지 처리 알고리즘의 복잡성을 나타내는 지표; 이미지의 각 픽셀을 처리하는 데 필요한 연산량을 측정하는 지표로 낮을 수록 더 적은 연산으로 효율적으로 작동하는 것을 의미한다.
먼저 이미지 압축 품질을 평가하기 위해 7가지 매트릭(MS-SSIM, FSIM, NLPD, IW-SSIM, VMAF, VIFP, PSNR-HVS-M)의 평균 BD-rate를 주요 왜곡 메트릭으로 평가하였다.
이 매트릭들이 의미하는 바를 몰라서 GPT에게 물어봤다 ㅎ
- MS-SSIM: 인간이 이미지를 여러 해상도에서 어떻게 인식하는지를 반영하는 지각적 이미지 품질.
- VIFP: 처리된 이미지에서 원래의 시각 정보를 얼마나 잘 보존했는지를 평가
- FSIM: 세부 사항과 전체적인 특징 유사성을 유지하는 것이 중요한 이미지 평가에 사용
- NLPD: 이미지의 해상도에 따라 다양한 레벨에서 세부 사항을 유지하는 시각적 왜곡
- IW-SSIM: 시각적으로 더 중요한 영역에 초점을 맞춘 지각적 품질; 이미지의 특정 영역이 다른 영역보다 더 중요한 경우(예: 초상화에서의 얼굴)에 유용
- VMAF: 샤프니스, 세부 사항, 노이즈 등을 고려한 전반적인 지각 품질
- PSNR-HVS: 인간의 시각적 품질을 더 정확하게 평가하려는 이미지 압축에서 사용
그렇다고 한다..!
모델의 복잡성을 평가하는 데에는 ptflops 라이브러리를 채택하여 kMACs/pixel을 계산하였다.
B. Simplified Attention Modules
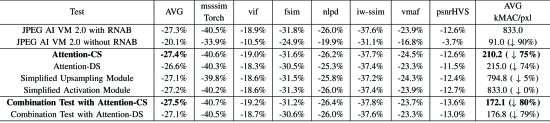
3번째 합성곱 계층 이후에 채널 분할을 사용한 모듈을 Attention-CS, 공간 다운 샘플링을 사용한 모듈을 Attention-DS라고 하여 아래의 표로 정리하였다.
결과를 보면 Attention-CS와 Simplified Attention Module-DS(Attention-DS)는 디코딩 복잡성을 최대 75%까지 줄일 수 있으며, 성능 저하는 미미하다.(0.8%)
또한 Attention-CS는 BD-rate와 디코딩 복잡성 모두에서 Attention-DS를 능가한다.
C. Simplified Upsampling Modules
Simplified Upsampling 모듈은 평균 BD-rate가 0.2% 감소한다.
딥러닝 모델 훈련 시에 BD-rate는 모델의 복잡성과 성능에 영향을 주는 다양한 요소들 때문에 일반적으로 0.5% 이내의 차이가 발생한다고 한다.
따라서 현재 Simplified Upsampling 모듈에서 발생한 0.2%의 감소는 훈련 과정에서 자연스럽게 발생할 수도 있는 오차보다도 작기때문에 이로 인해 발생한 손실은 무시할 수 있는 수준이라고 한다.
=> Simplified Upsampling 접근법은 모델의 압축 효율성을 저해하지 않으면서 상당한 계산 비용 절감을 제공한다.
D. Simplified Activation Function
해당 논문에서 제안한 Simplified Activation Function으로 인해 이미지 압축 성능이 0.1%정도 저하되었으나 이 또한 무시할 수 있는 수준으로 간주하였다.
E. Combination Tests
simplified attention, upsampling, activation의 적용 가능성을 평가하기 위해 combination test를 하였다.
그 결과 kMACs/pixel 측면에서 계산 복잡성이 833에서 172.1로 감소하였고, 0.2% 압축 성능 향상 또한 얻었다.
각 방법들을 성능을 저하시키지 않으면서 더 효율적인 계산 모델에 기여한다.
V. Conclusion
해당 논문에서는 기존의 learning-based image coding 방식에서 내재된 디코딩의 복잡성 부분을 개선하였다.
특히 Attention module, Upsampling module, Activation function에 대한 단순화 작업을 수행하였으며 각각에 대해 아래와 같이 간단하게 정리했다.
-
Attention module: low-complexity hierarchical attention 구조를 활용하여 transformer 기반 모듈을 이용해 더 나은 global 정보를 캡처하고, 메모리 사용을 보장하는 새로운 메모리 최적화 전략을 적용 -
Upsampling module: pixel-shuffle 기술 도입하여 복잡성을 완화하면서 네트워크 안정성을 저해하지 않는다. -
Activation function: 불필요한 연산을 제거하여 필수 구성 요소만을 유지하여 복잡성을 추가로 줄였다.
그 결과로 kMAXs/pixel 지표를 852에서 180까지 줄였으며(계산 복잡도 감소), 계산 효율성이 27.3%에서 27.5%로 상승시켰다.
해당 논문에서는 기존에 JPEG AI Codec에서 decoding할 때 복잡도를 개선하고자 하였다.
지금 진행하고 있는 프로젝트에서 jpeg codec을 사용하고 있어 이를 적용해보면 좋을 것같다는 생각이 들었다.
아직 많이 지식이 부족해서 그런지 왜 계층적 구조를 떠올렸을 것이고, pixel-shuffle 방식을 떠올릴 수 있었던건지 이해가 안되서,,이 내용을 세미나 발표하긴 어려울 것같다. 결과적으로 압축 성능 대비 계산 복잡도를 줄였다는 것까지만 이해가 된다,,,ㅎㅎㅠㅠ
프로젝트 성능이 좋아지고 어느 정도 여유 생겼을 때 도전해봐야겠다!
